【转帖】MySQL InnoDB存储原理深入剖析与技术分析
一、MySQL记录存储:
MySQL InnoDB的数据由B+树来组织,数据记录存储在B+树数据页(page)中,每个数据页16kb,数据页
包括页头、虚记录、记录堆、自由空间链表、未分配空间、slot区、页尾七部分组成。
所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键码。
- 1
- 2
- 3
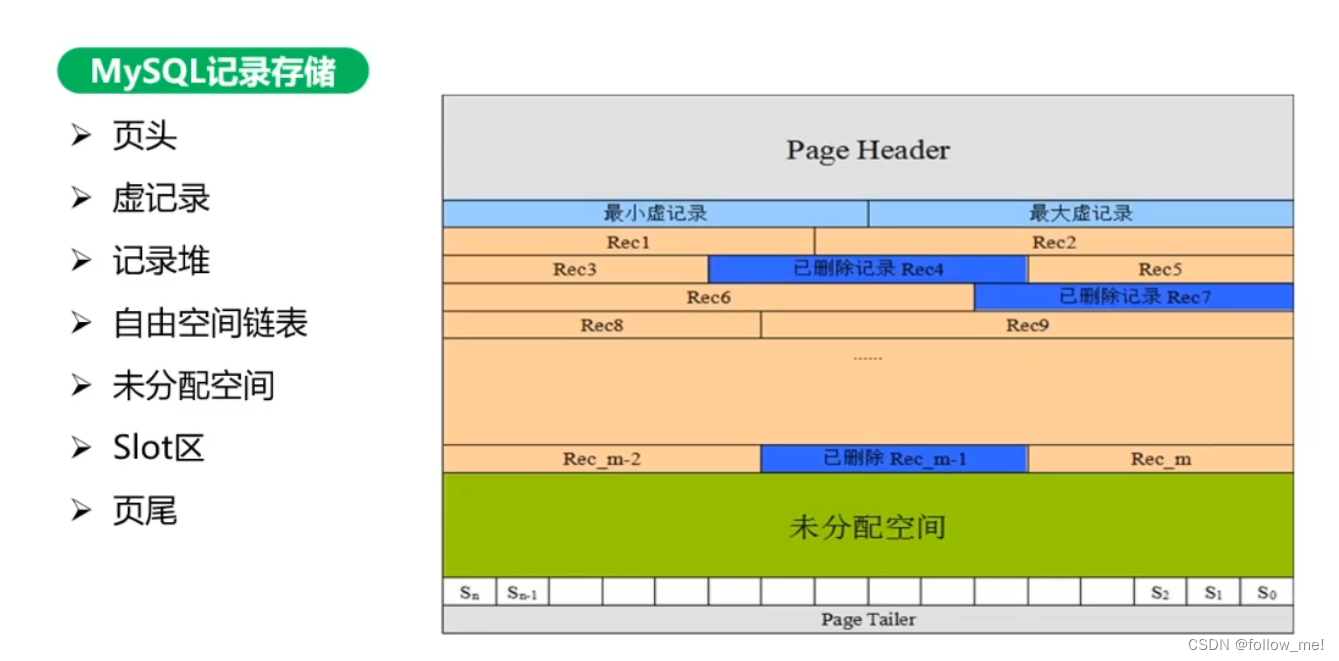
- 页头:
56个字节,记录本页的信息,包括页的左右兄弟页指针(双向链表,可使用此双向链表遍历数据,会比遍历树块),页面使用情况等。 - 虚记录:
包括最小虚记录(比页内最小主键还小)、最大虚记录(比页内最大主键还大),表示本页数据key的范围。 - 记录堆:
本页已存储数据的区域,包括有效记录、已删除记录。 - 自由空间链表:
本页被删除的数据(逻辑删除)会用链表连接,称为自由空间链表,以便后续能再次利用。 - 未分配空间:
本页未被使用的页空间。 - Slot区:
(槽位)用于页内快速查询,Slot区为等值的数组,可进行二分查找。 - 页尾:
8个字节,主要存储本页的检验信息(有无发生过错误)。
二、页内记录维护:
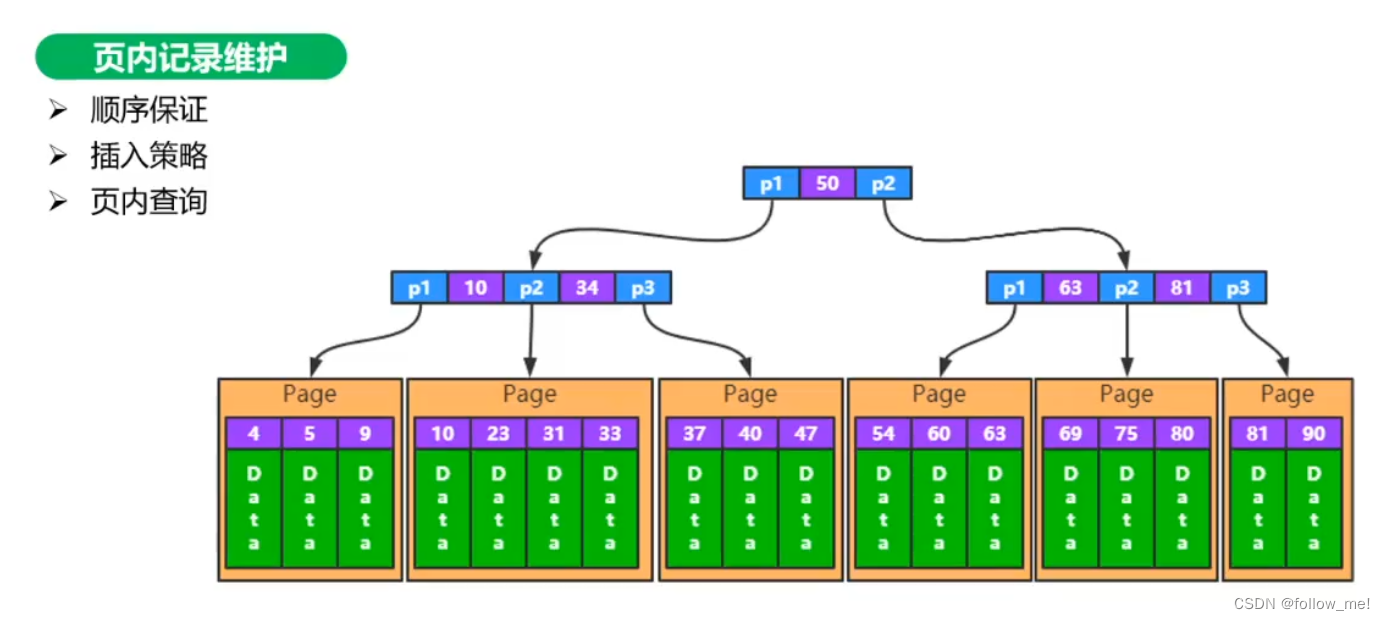
- 页内顺序
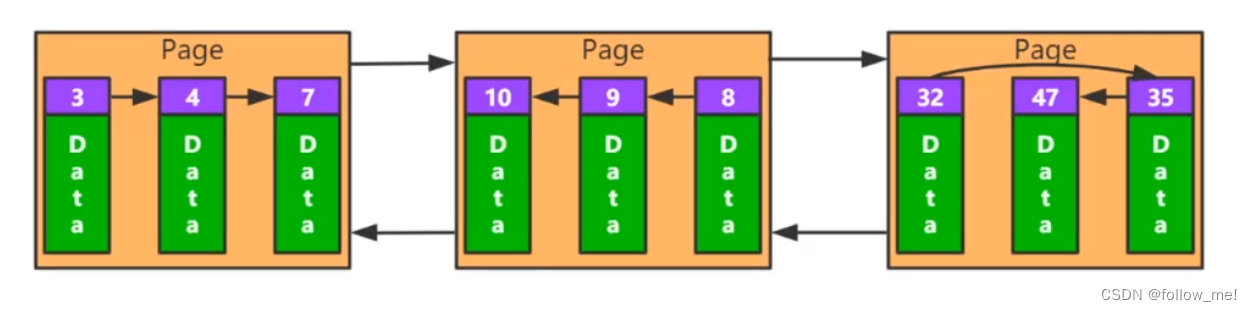
逻辑连续。页之间有双向链表,页内也有链表,双向链表可以供范围查询使用。
采用什么方式存储,主要考量读写性能。物理连续,每次插入可能涉及数据移动,写入性能低,查询
效率也无法像数组一样使用二分查找,数组的数据类型一致,数据长度一致,但记录数据的长度因存在变长字段而不定。
逻辑连续,写入不涉及数据移动性能高,查询需要利用slot区优化,不优化需要遍历整个链表,优化后只需要遍历subList。
- 1
- 2
- 3
- 页内插入
先看自由空间链表能否复用,无法复用使用未分配区 - 页内查询
先基于slot点,二分查找,再遍历对应slot点对应的subList

三、变长数据存储:
 字段:长度+内容,MySQL varchar类型的字段默认给的长度为什么是255而非256,因为255时,长度用1个字节就可以了。
字段:长度+内容,MySQL varchar类型的字段默认给的长度为什么是255而非256,因为255时,长度用1个字节就可以了。
每个PageSize 16kB,每页至少存2条数据,页内单行数据最大8kb,超出8kb后会存在溢出表,超出的部分放到溢出页中(称之为【行溢出】,当某一行数据过大,导致数据页存放不下时,我们把这种情况叫做行溢出,简单的解决方式就是把记录存储在溢出页(磁盘的其它空闲地方)中)
页分裂机制: 页分裂机制

四、MySQL InnoDB索引原理分析:
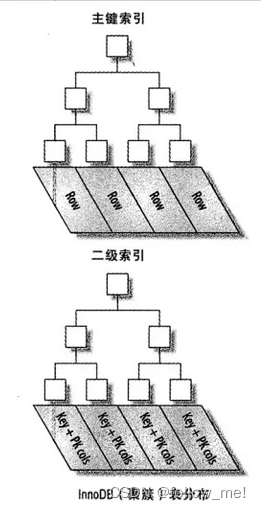
聚簇索引
聚集索引是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序,即使没有创建索引,也会存在。InnoDB通过主键聚集数据,即使没有设置主键,InnoDB也会使用第一个非空唯一列作为主键,如果非空唯一列也不存在,则InnoDB会将RowId作为主键;聚集索引的叶子节点存放是实际数据,数据按主键顺序存储,因此为了插入数据的效率,应采取递增主键。
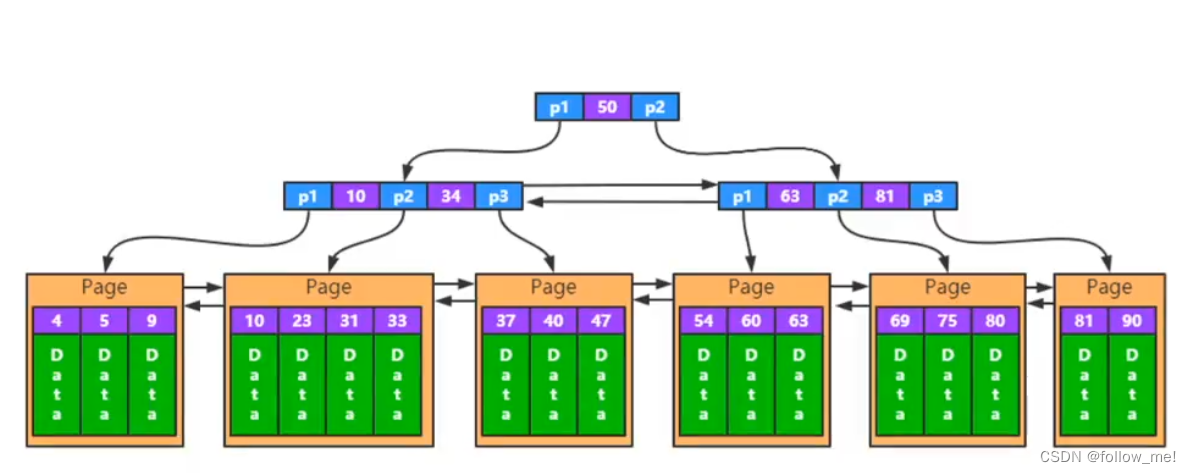
二级索引
除了聚簇索引,其他的索引都可以称为二级索引,包括唯一索引、普通索引、联合索引。二级索引的叶子结点的data存放不是实际的数据,而是数据的主键,通过主键再去聚簇索引上查找数据。因此尽量使用聚簇索引。
一次查询需要走两遍索引(称为回表),主键大小会影响所有索引的大小。
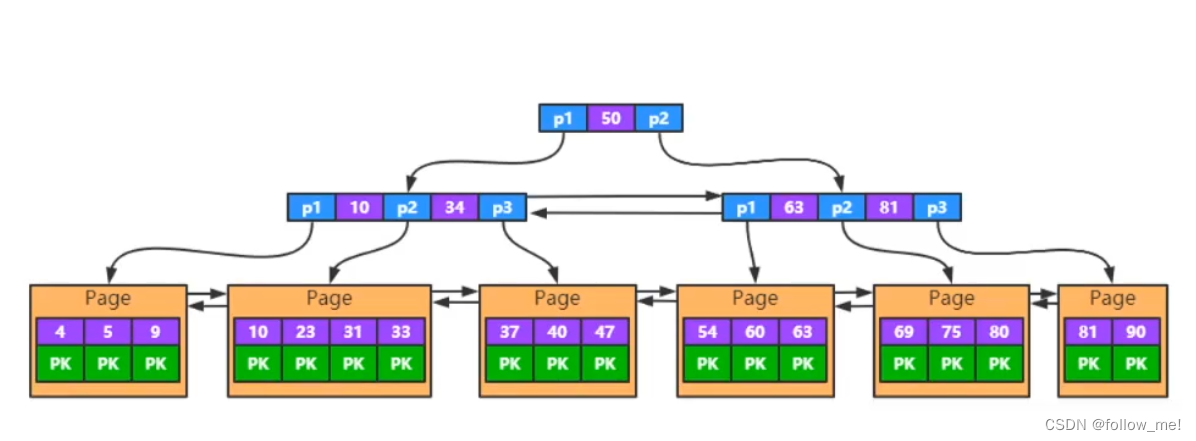
- 联合索引
多列。最左匹配原则
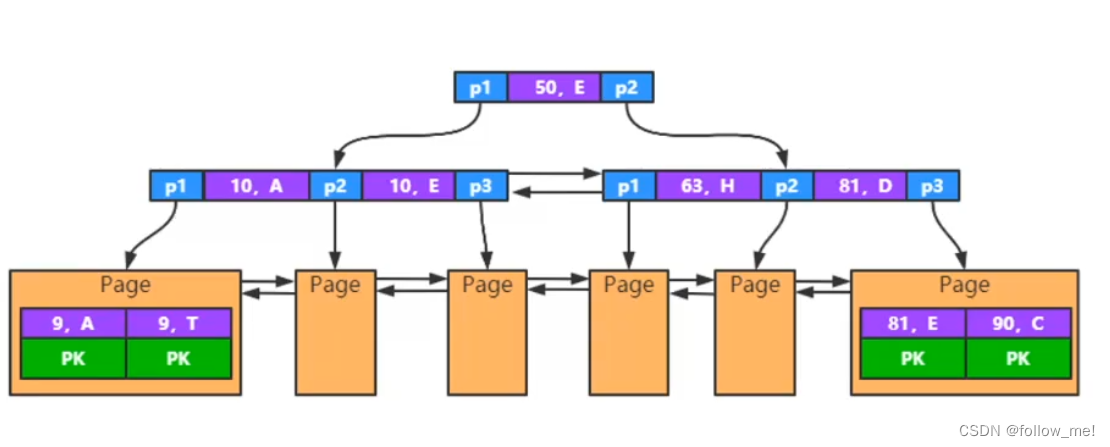

联合索引本质:
当创建(a,b,c)联合索引时,相当于创建了(a)单列索引,(a,b)联合索引以及(a,b,c)联合索引
想要索引生效的话,只能使用 a和a,b和a,b,c三种组合;当然,我们上面测试过,a,c组合也可以,
但实际上只用到了a的索引,c并没有用到!
引擎自动优化:
(A,B,C) 如果查找A=XX,B=XX,C=XX,可以命中,但是A=XX,C=XX,B=XX,也能命中,因为数据引擎
会将sql调整优化为A=XX,B=XX,C=XX。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
五、索引使用优化:
存储空间
索引文件大小。主键(key)大小,主键(key)越小,每页16k存的数据越多,树的层级越小。

主键选择
自增主键:顺序写入,写效率高,步长为1,但是容易暴露商业信息,或者每次查询走二级索引;
随机主键:如UUID,易造成页分裂,写入效率低;
业务主键:如雪花算法,写入、查询的效率都很高,可直接使用一级索引;
联合主键:影响索引大小,不易维护,不建议使用;

雪花算法详解:传送门联合索引使用
按区分度排序:(a,b,c),多的放前面,如果上亿数据,用a就能筛选后得到的数据就很少,那么,后面效率就高了;
覆盖索引:
explain时,如果Extra为Using index则使用了覆盖索引。覆盖索引的解释为,索引中包含要查询的结果(小于等于),不需要回表查询,大数据常用。
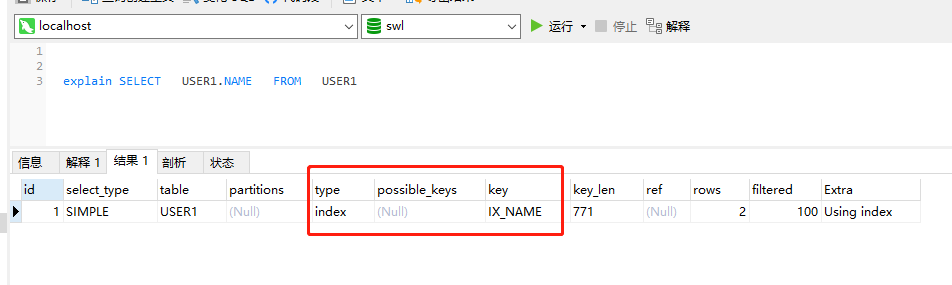
create index UIX_BINFO_CUSERID
ON busi_busi_note(BUSI_INFO_ID,CREATER_USER_ID)
explain select BUSI_BUSI_NOTE_ID,CREATER_USER_DATE from busi_busi_note
where BUSI_INFO_ID='1579296835263004672' and CREATER_USER_ID='1111111207'
explain select * from busi_busi_note where BUSI_INFO_ID =
'1579296835263004672' and CREATER_USER_ID = '1111111207'
explain select BUSI_BUSI_NOTE_ID from busi_busi_note where
BUSI_INFO_ID = '1579296835263004672' and CREATER_USER_ID = '1111111207'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 字符串索引:
设置合理的长度:如果过长,如1024,比1024次才能比出大小,不合适。
不支持%开头的模糊查询: 最左匹配原则。可用如ES这种搜索引擎,ES通过分词进行倒排索引,通过value查key,如小孩(file1id,file2id,file3id)
六、InnoDB存储引擎内存管理:
1.InnoDB会在内存中申请一片内存(内存池),数据是以数据页为最小单位(16k)通过映射关系加载到内存,加载到内存的数据页分为空数据页、冷数据页、热数据页、脏数据页。如果数据页被使用完毕,然后InnoDB会通过LRU、LFU等方式通过映射关系进行数据内外存置换,淘汰冷数据、加载新数据,脏数据固化等
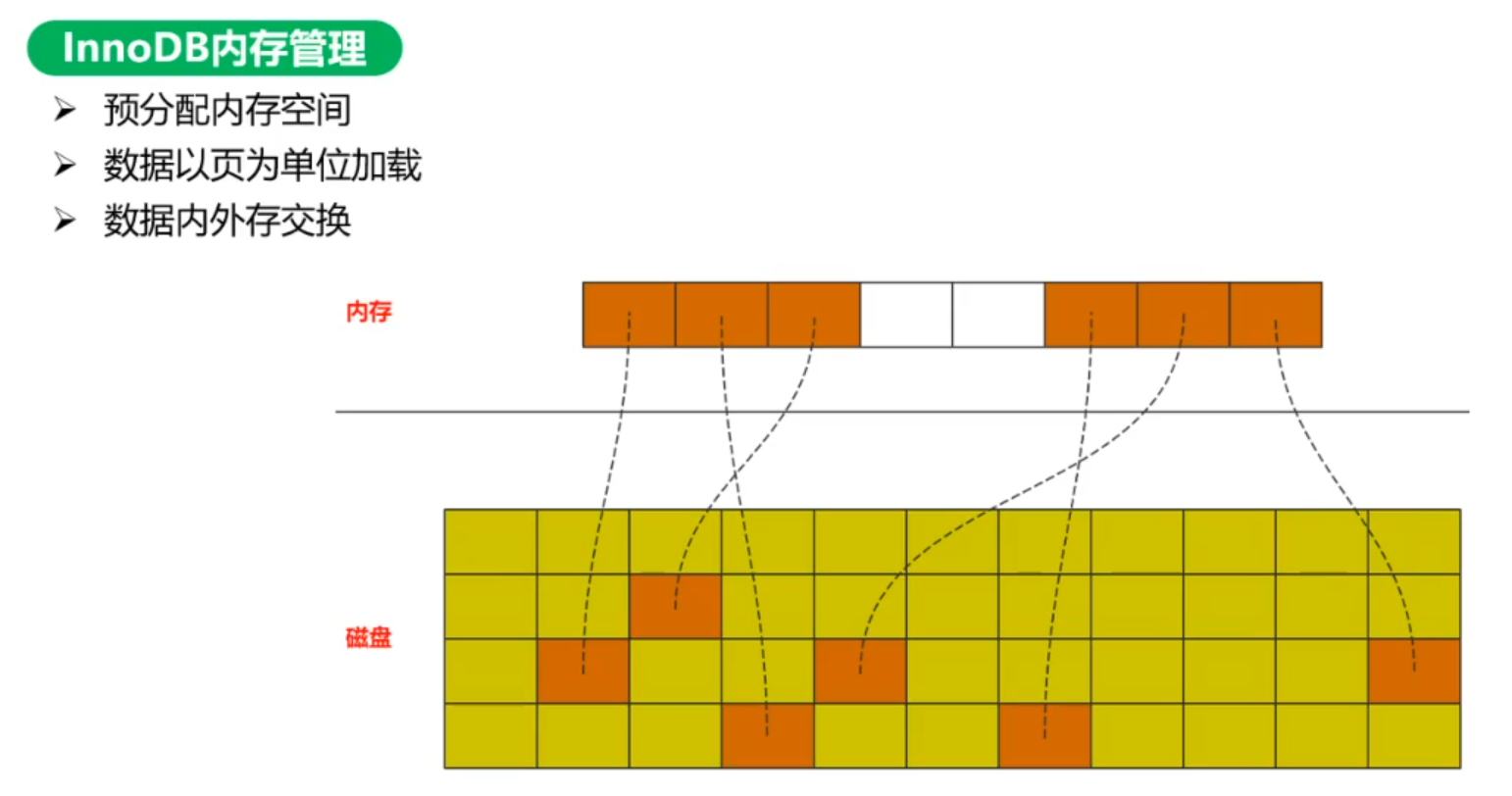

LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。但是LRU全表扫描时,一次性加载大量数据,可能会将内存池完全更新一遍,无论原来内存池中有多少热数据都会被淘汰,所以InnoDB在LRU基础上进行了优化,避免热数据被淘汰。
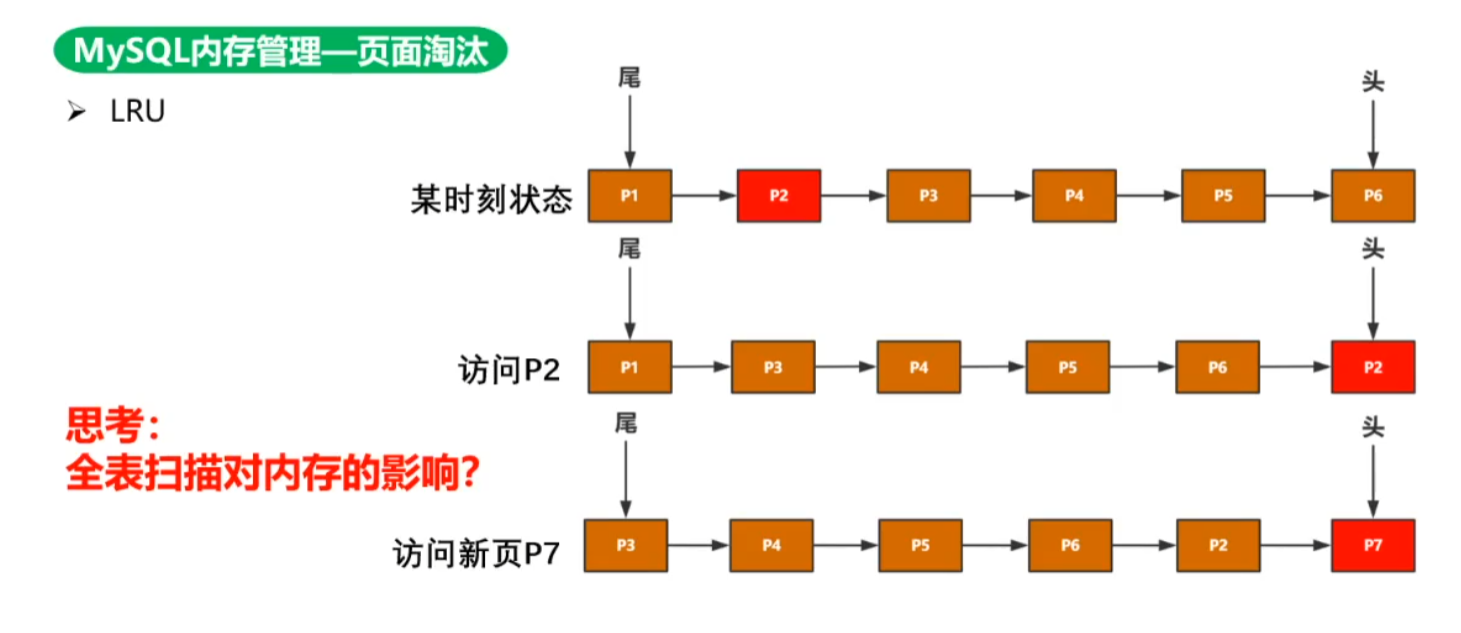
优化:避免热数据被淘汰,(访问时间+频率)、(两个LRU表:一个热数据的LRU表,一个冷数据的LRU表,只淘汰冷数据的LRU表,热数据转冷,冷数据转热);

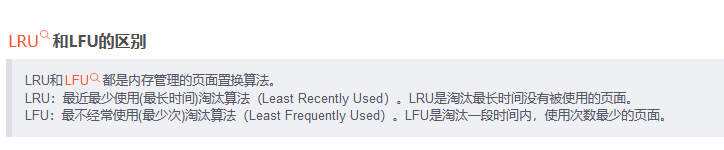
mysql怎么做的?
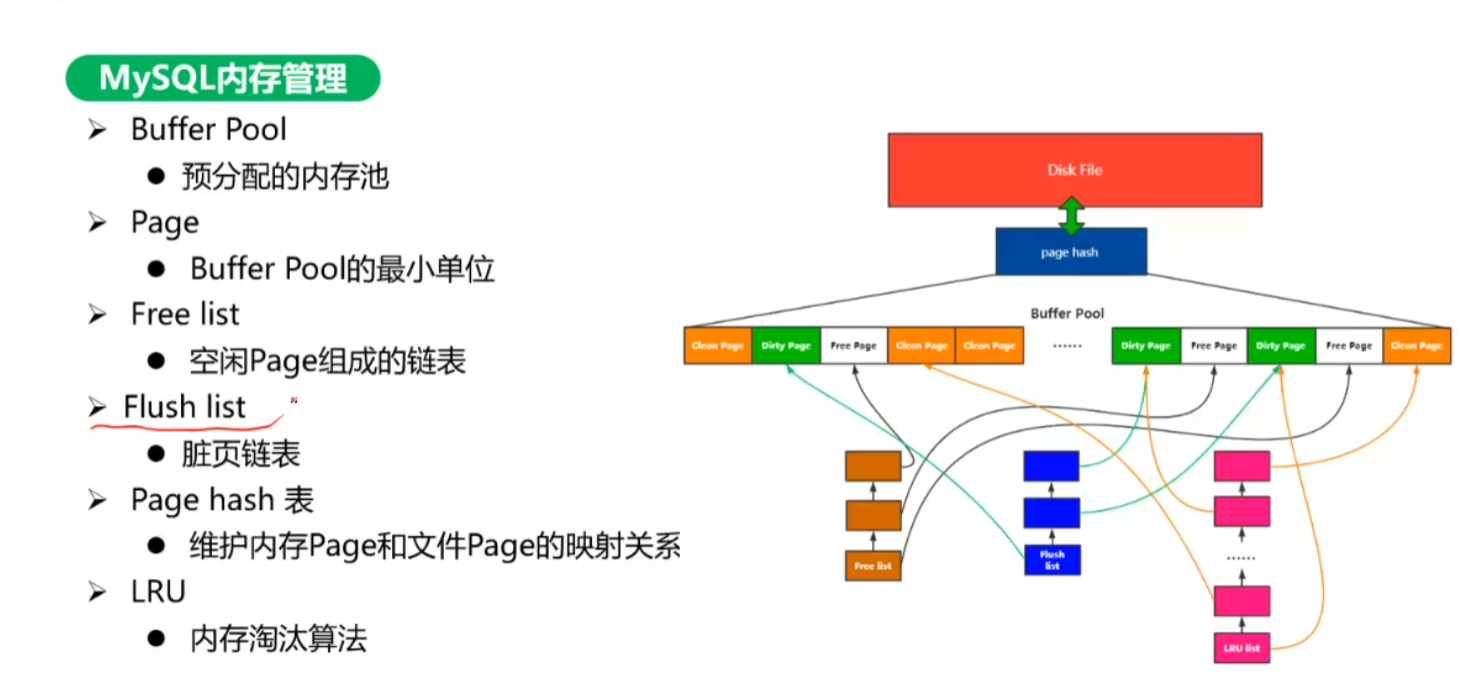
- Buffer Pool:
预分配的内存。 - Page:
16k,Buffer Pool的最小单位。 - Free List:
空闲的Page组成的链表。 - Flush list:
脏数据页,被改动的数据,需要持久化的数据。 - Page hash表:
维护内存Page与文件Page的映射关系。 - LRU:
内存淘汰算法,包括脏数据页、净数据页,净数据分为冷数据表与热数据表,中间用Midpoint,冷数据5/8,热数据3/8,冷热分离

数据装载:
- 页面状态:
磁盘数据到内存,首先从空闲链表取出空闲页,将数据放入,然后将此空闲页(此时已经为非空闲页)连接到LRU的old部分;但是如果没有空闲页的话,就会启动页面淘汰。 - 页面淘汰
首先从LRU的尾部淘汰冷数据,如果数据被锁,淘汰不了,就LRU flush。如果将第一个脏页刷盘【1】,先放到LRU尾部【2】再放到freeList【3】还是直接到freeList?
mysql最早经历123步,后来13,再优秀的产品也是一步一步迭代过来的。
- 位置移动
select * from table 时,如果用LFU算法(使用频率)来LRU,那么select * from table全表扫描时,会将某page加载到内存,然后逐条遍历数据,那么短时间内此page会高频次被使用,那么此页就会称为热数据,当大量的页成为热数据时,原来的热数据就会被误淘汰。
old到new:
LRU_old中的数据被使用就会放到LRU_old表头,如果某数据在LRU_old中存活时间超过某值innodb_old_block_time,就有机会进入L RU_new,放于LRU_new的head。
new到old:
LRU_new的数据再老默认也比LRU_old中的数据新,所以LRU_new中淘汰的数据会放在LRU_old的head;实现方式是,移动Midpoint,保证Midpoint始终指向5/8的位置。 - LRU_new的操作
如果每次使用到的数据页都移动至LRU_new的head,但由于在多线程,存在LOCK,可能会串行移动,效率低。MySql的设计思路是减少移动次数, freed_page_clock: Buffer Pool淘汰的页数,如果总淘汰数a减去当前page上次处于head时的Buffer Pool淘汰的页数b,大于LRU_new的1/4时,开启淘汰。

七、InnoDB存储引擎事务实现原理:
- 事务特性
A:原子性,多条操作要么全部成功、要么全部失败;undo log
C:一致性,通过AID保证
I:隔离性,并行事务之间相互隔离,互不干扰;MVCC
D:持久性,事务提交后,数据一定会被持久化,永久生效;redo log - 并发问题
脏读:隔离性最差,可读到未提交的数据(即未生效的数据,系统外的数据),称之为脏读;
不可重复读:隔离性好点,读已提交的数据(即自己没改,被其他事务改的数据,但事务也未完全隔离开;
幻读:隔离性再严格一点,可重复读数据(无论其他事务提交没提交读的都一样),会造成读取的数据,与实际情况不符,仿佛产生了幻觉一样。select操作后得到的结果无法支撑后续的业务操作;
比如数据库,事务A,T1时刻查询有id为1、2、3的三条数据,T2时刻事务B插入了一条id为4的数据,
此时事务A查询数据还是3条,这时事务A执行插入一条数据,id为4,将出错,但这个时候事务A不知
怎么回事,仿佛出现幻觉一样。
- 1
- 2
- 3
- 隔离级别

RR级别(可重复读级别)解决了幻读,只是解决了特定场景下(两次当前读)的幻读,通过gap锁。
- 1
Next-Key Locks Next-Key Locks是在存储引擎
innodb、事务级别在可重复读的情况下使用的数据库锁,官网上有介绍,Next-Key Locks是行锁和gap锁 的组合。行锁是什么我们都很清楚,这篇文章主要简单分析一下mysql中的gap锁是什么。innodb默认的锁就是Next-Key locks。 GAP锁 gap锁,又称为间隙锁
。存在的主要目的就是为了防止在可重复读的事务级别下,出现幻读 问题。 在可重复读的事务级别下面,普通的select读的是快照,不存在幻读情况,但是如果加上for update的话,读取是已提交事务数据,gap锁
保证for update情况下,不出现幻读。 那么gap锁到底是如何加锁的呢? 假如是for update级别操作,先看看几条总结的何时加锁的规则。 唯一索引 精确等值检索,Next-Key Locks就退化为记录锁,不会加gap锁 范围检索,会锁住where条件中相应的范围,范围中的记录以及间隙,换言之就是加上记录锁和gap 锁(至于区间是多大稍后讨论)。 不走索引检索 ,全表间隙加gap锁、全表记录加记录锁 非唯一索引 精确等值检索,Next-Key Locks会对间隙加gap锁(至于区间是多大稍后讨论),以及对应检索到的记录加记录锁。 范围检索,会锁住where条件中相应的范围,范围中的记录以及间隙,换言之就是加上记录锁和gap 锁(至于区间是多大稍后讨论)。 非索引检索
,全表间隙gap lock,全表记录record lock

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43

1、MySql事务实现原理:
- MVCC:
- 多版本并发控制:
- 解决读写冲突:读当前版本会被锁住,读历史版本不会被锁住,
- 隐藏列:所属事务列,及指向此数据上一版本的指针(用于寻找上一版本数据【实质上旧版本数据是从undo log中读出】)
- 当前读:
存储记录除了普通字段以外还会存事务ID来标注这条记录是那个事务写的;回滚指针指向上一个版本记录快照(可能没有上一版本)。当前读指读当前存储引擎的最新版本,会将最新版本数据加锁(唯一索引定值查询行锁,范围查询Next-key锁;非唯一索引定值查询与范围查询均使用Next-key锁;无索引表锁,但是索引失效时会转化为全表扫描,行锁得会转化为表锁),其他的当前读就不能读了,只能等着
当前读
当前读:读取最新提交的数据,当前读加锁,而快照读不加锁。
例如下面语句都会按最新提交的数据进行操作:
select … for update; (for update加的是互斥锁)
select ... lock in share mode; (lock in share mode加的是共享锁【读锁】)
insert、update、delete;
当前读本质上是基于锁的并发读操作
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
快照读:大多是快照读,读历史指定版本,可重复读某一版本,这就是MVCC实现可重复读,且此版本为历史版本,历史版本不会被锁,解决了读写并发的问题。gap锁,next锁

可见性判断:即使是读快照,但是不能随便读一个版本,所以应该读那个版本应该有个判断。mysql在快照读的时候创建快照(创建快照我的理解是当时的数据状态,实现是创建一个数组),如select时,原则是
不能读创建快照这一刻还未提交的事务、以及创建快照后创建的事务,即第一次读是选取已提交的事务id最大的数据,再次读取的按快照时刻存储的数组查询数据,改的话只能改当前数据。
创建快照举例: session A只需要做一件事:用一个数组,来记录当前活跃的事务ID。
假设session A的事务ID是97,当前还有另外两个事务,事务ID是94、96,所以session A会生成
一个[94,96,97]的数组。
接着,session B执行了update语句,来更新id=1这一行数据,给这一行数据生成一个新的版本,
假设session B的事务ID是98,因此这行数据就有了两个版本:这时候,session A又来select了,
当前版本是session B生成的,那session A是如何找到之前的版本的呢?这时候,session A
一开始生成的事务数组就派上用场了,session A的事务数组是[94,96,97],最小事务ID是94,最大
事务ID是97,所以,当它遇到一行数据时,会先判断这行数据的版本号X:如果X大于97,那么意味着这
行数据,是在session A开始之后,才提交的,应该对session A不可见如果X小于97,那么分两种情
况:如果X在数组里面,比如X是96,那么意味着,当session A开始时,生成这个版本的数据的事务,
还没提交,因此这行数据对Session A不可见,如果X不在数组里面,比如X是95,那么意味着,
当session A开始时,生成这个版本的数据的事务,已经提交,因此这行数据对Session A可见。
现在session A开始遍历id=1这行数据的所有版本:当前版本是98,大于97,所以不可见,继续看上
一个版本;再往上,版本是90,小于94,可见,就它了,所以session A select出来的id=1的数据,c
的值是1。
可见性的原则:
版本未提交,不可见;
版本已提交,但是在快照创建后提交的,不可见;
版本已提交,而且是在快照创建前提交的,可见。
这其实就是可重复读的想要实现的效果。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

- undo log:
 实质上旧版本数据是从undo log中读出
实质上旧版本数据是从undo log中读出
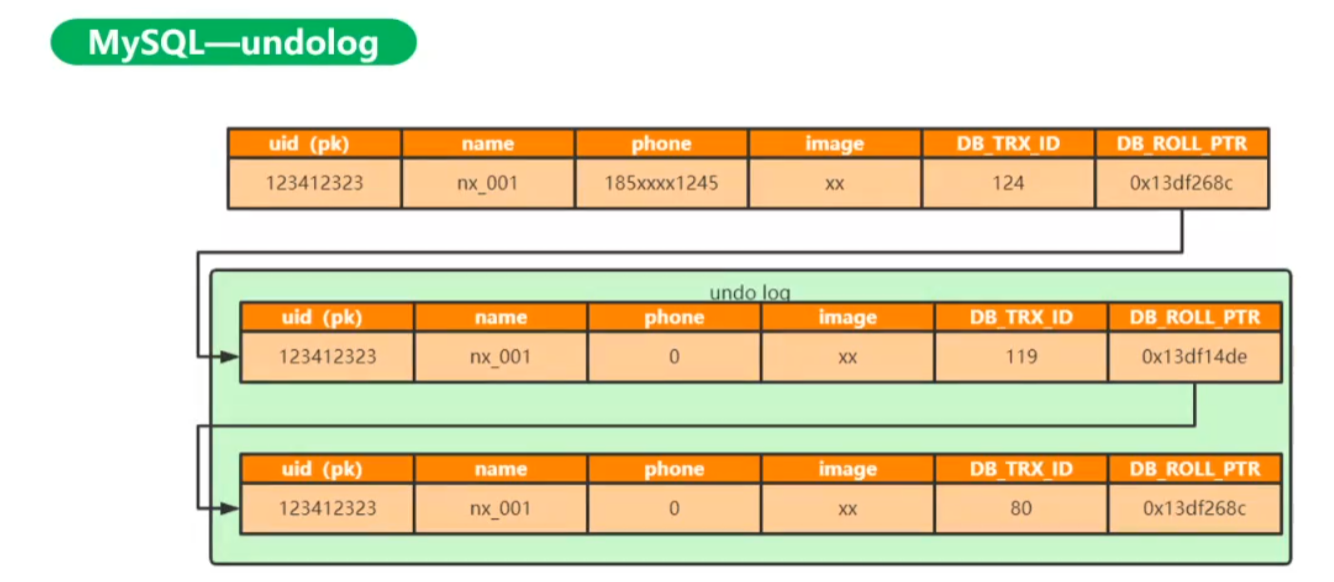 undo log的删除用read view(可见性判断),判断最小活跃事务的可见性,如果最小活跃事务都可以看见,则说明所有事务均已经可见??可以删除。
undo log的删除用read view(可见性判断),判断最小活跃事务的可见性,如果最小活跃事务都可以看见,则说明所有事务均已经可见??可以删除。
问题:为什么mysql没有计数器?
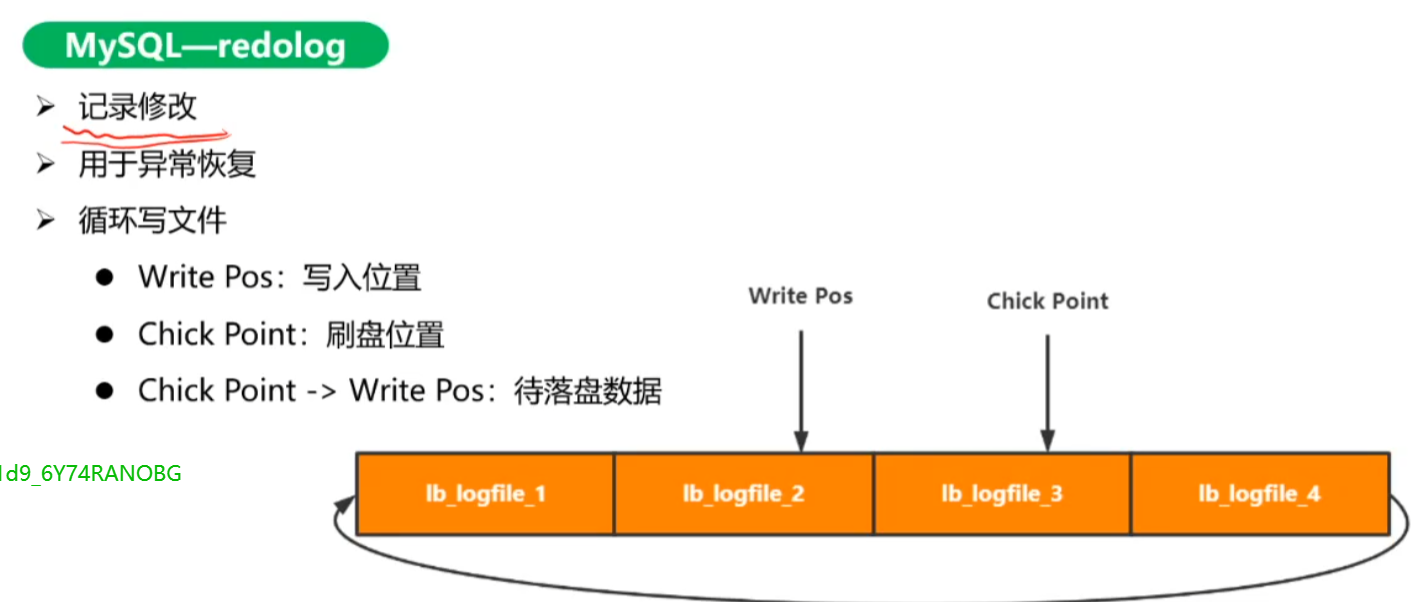
- redo log:
循环写文件,write pos指针写,Chick Point指针刷盘
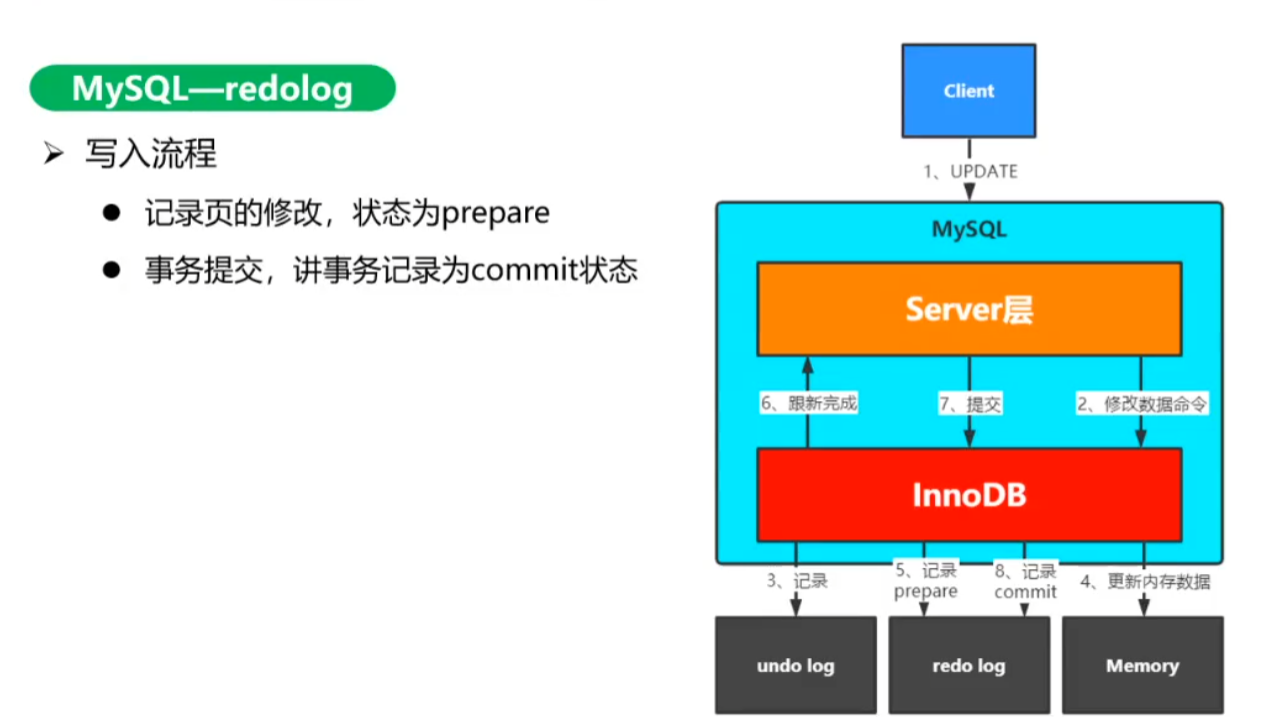
更新数据前先记undo log,记录历史版本,undo log记录完毕后更新数据,
提交事务前,redo log就已经写好了!
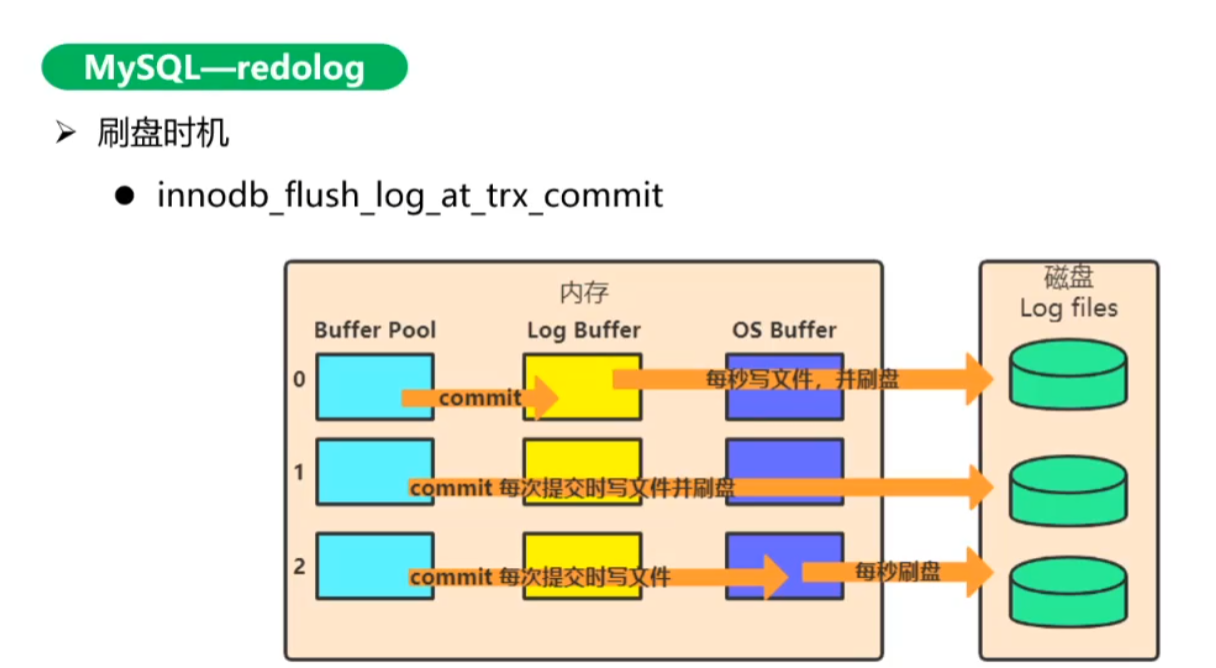
redo log也得刷盘,事务也得刷盘,为什么 redo log就不丢数据呢?
因为事务时整个page的刷盘,16k, 且page位置不固定(随机写),代价大;
redo log只是一条日志,体积小,比page写代价小;且是写文件,追加写,是顺序写;

【转帖】MySQL InnoDB存储原理深入剖析与技术分析的更多相关文章
- 浅析Mysql InnoDB存储引擎事务原理
浅析Mysql InnoDB存储引擎事务原理 大神:http://blog.csdn.net/tangkund3218/article/details/47904021
- MySQL InnoDB存储引擎体系架构 —— 索引高级
转载地址:https://mp.weixin.qq.com/s/HNnzAgUtBoDhhJpsA0fjKQ 世界上只两件东西能震撼人们的心灵:一件是我们心中崇高的道德标准:另一件是我们头顶上灿烂的星 ...
- 深入解读MySQL InnoDB存储引擎Update语句执行过程
参考b站up 戌米的论文笔记 https://www.bilibili.com/video/BV1Tv4y1o7tA/ 书籍<mysql是怎样运行的> 极客时间<mysql实战45讲 ...
- MySQL InnoDB 存储引擎原理浅析
注:本文主要基于MySQL 5.6以后版本编写,多数知识来着书籍<MySQL技术内幕++InnoDB存储引擎>,本文章仅记录个人认为比较重要的部分,有兴趣的可以花点时间读原书. 一.MyS ...
- [转帖]mysql常用存储引擎(InnoDB、MyISAM、MEMORY、MERGE、ARCHIVE)介绍与如何选择
mysql常用存储引擎(InnoDB.MyISAM.MEMORY.MERGE.ARCHIVE)介绍与如何选择原创web洋仔 发布于2018-06-28 15:58:34 阅读数 1063 收藏展开 h ...
- MySQL InnoDB存储引擎undo redo解析
本文介绍MySQL数据库InnoDB存储引擎重做日志漫游 00 – Undo Log Undo Log 为了实现事务原子,在MySQL数据库InnoDB存储引擎,还使用Undo Log(简称:MVCC ...
- MySQL InnoDB 索引原理
本文由 网易云发布. 作者:范鹏程,网易考拉海购 InnoDB是 MySQL最常用的存储引擎,了解InnoDB存储引擎的索引对于日常工作有很大的益处,索引的存在便是为了加速数据库行记录的检索.以下是 ...
- MySQL InnoDB存储引擎事务的ACID特性
1.前言 相信工作了一段时间的同学肯定都用过事务,也都听说过事务的4大特性ACID.ACID表示原子性.一致性.隔离性和持久性.一个很好的事务处理系统,必须具备这些标准特性: 原子性(Atomicit ...
- MySQL InnoDB存储引擎
200 ? "200px" : this.width)!important;} --> 介绍 本篇文章是对Innodb存储引擎的概念进行一个整体的概括,innodb存储引擎的 ...
- mysql innodb存储引擎介绍
innodb存储引擎1.存储:数据目录.有配置参数为“ innodb_data_home_dir ” .“ innodb_data_file_path ” 和 “innodb_log_group_ho ...
随机推荐
- Java 将PPT转为OFD
本文以Java后端程序代码展示如何实现将PPT幻灯片转成OFD格式.下面是具体步骤. 步骤1:安装PPT库-Spire.Presentation for Java 方法一.通过Maven仓库安装.在p ...
- 小熊派:用OpenHarmory3.0点亮LED
摘要:作为一个代表性的完整的开发,本案例可以分成3大部分:代码文件的规划,LED灯的驱动开发,点亮LED的业务开发. 本文分享自华为云社区<在小熊派Micro上用OpenHarmory3.0点亮 ...
- [ERROR] Error executing Maven. [ERROR] 1 problem was encountered while building the effective settings
原因: maven 的配置文件 setting.xml 有错. 比如在配置文件中多了一行: 导致配置文件的格式不正确.
- Solon 的常用配置
一.服务端基本属性 #服务端口(默认为8080) server.port: 8080 #服务的 http 信号端口(默认为 ${server.port}) server.http.port: 8080 ...
- JQuery 弹出模态窗口
index.html <!DOCTYPE html> <html> <head> <!-- Contact Form CSS files --> < ...
- Pytest.mark.parametrize()基本用法
Pytest.mark.parametrize()基本用法 @pytest.mark.parametrize()基本用法 数据驱动:就是把我们测试用例的数据放到excel,yaml,csv,mysql ...
- 初识QT、窗口以及信号槽
1 基本规范: 无论是写什么样的代码,第一步都应该是创建一个程序对象 #include <QApplication> int main(int argc, char *argv[]) { ...
- CO41创建生产订单维护增强字段
一.CO41计划订单中新增增强字段 报表中新增字段,并可维护,当点击转换创建生产订单时,将四个字段的值,维护到生产订单对应的字段中 二.增强结构 在SFC_POCO中新增对应的字段 三.屏幕增强 找到 ...
- Qt 如何配置CLion标准控制台输出?
CMake 相关问题: 即CMakeLists.txt文件中,在add_executable添加了WIN32.即当使用了WIN32标识后,就去掉了控制台,那么自然就没有信息打印出来了. # for e ...
- 技术文档 | 将OpenSCA接入GitHub Action,从软件供应链入口控制风险面
继Jenkins和Gitlab CI之后,GitHub Action的集成也安排上啦~ 若您解锁了其他OpenSCA的用法,也欢迎向项目组来稿,将经验分享给社区的小伙伴们~ 参数说明 参数 是否必须 ...