ApacheCon Asia 2022 精彩回顾 | 如何让更多人从大数据中获益?
点亮 ️ Star · 照亮开源之路
GitHub:https://github.com/apache/dolphinscheduler

在 ApacheCon Asia 2022 Meetup上,有着十余年大数据开发工作经验,来自某银行离线数据工厂开发工具负责人陈卫老师分享了 如何让更多人从大数据中获益 的主题演讲。
感谢志愿者关博将本次演讲整理本文,您对 Apache DolphinScheduler 的贡献是社区不断前进的动力!
本次的分享主要围绕下面四点展开:
一、背景介绍
业务经理希望获得准确的数据,来帮助他们来做业务决策。
终端用户希望在短短的几分钟或者几个小时之内快速获得到自己想要的数据,他们不希望走以前传统的流程,需要向数据部门的同事提需求,从需求变更、开发、上线需要等数周才能拿到数据。
数据研发团队规模比以前越来越壮大,管理越来越复杂。每个数据处理工作的人都希望及时获得业务数据,以帮助他们做出决策。
数据源变得越来越复杂,例如数据库,网页,日志,文件,ERP,外部数据等。
01 用户需求
高级用户希望获得有限的自助服务,通过自助服务能够便捷、分析获取数据。
应用程序开发人员只关心业务逻辑,不关心具体的底层技术,也不希望更深入的去了解平台运维相关的配置。
尽可能的隐藏技术细节,让业务开发人员以及业务用户更专注业务逻辑,实现业务目标。
对系统管理员比较友好,能让系统管理员快捷、方便的有效管理数据平台。

基于以上用户需求,认为 DataOps 是我们努力的方向和目标,DataOps 是在 DevOps 基础之上实现数据敏捷的方式或者方法。

02 什么是 DataOps?
DataOps 是一种协作式数据管理实践,专注于改善组织数据管理员、数据消费者、数据开发人员之间数据流的通信、集成、自动化的方法论。
DataOps 的目标是通过创建可预测的数据、数据模型和相关工件的交付和变更管理,更快地交付价值。
DataOps 使用技术通过适当的治理级别自动执行数据交付的设计、部署和管理,并使用元数据来提高不断变化的环境中数据的可用性和价值。

DataOps 有助于我们实现快速的数据创新,以更快的速度向业务提供见解,并且提供数据质量帮助到数据人员。
2018年,DataOps被纳入到 Data Management 的技术成熟度曲线,标志着 DataOps 正式被业界所接纳并推广起来。DataOps 虽然可以降低数据分析的门槛,但并不会让数据分析变成一项简单的工作。
03 DataOps 关注点

快速创新和实验,以越来越快的速度为客户提供价值。
提供极高的数据质量和极低的错误率。
通过不同的人以及技术和环境进行协作,来提供交互价值。
测量、监控清晰,结果透明。
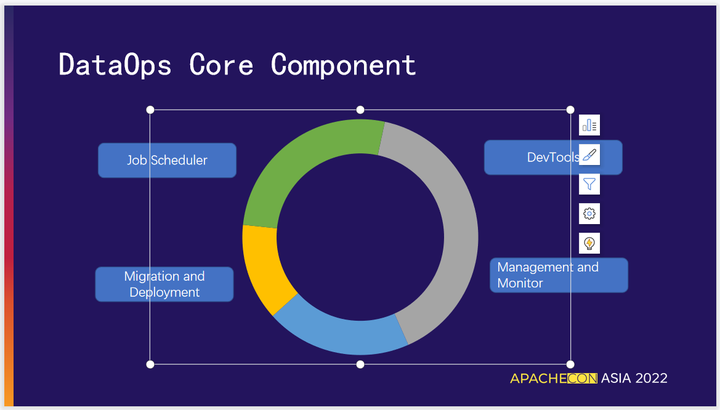
04 DataOps 核心组件
1.Job Scheduler
提供工作流的编排、离线数据研发、有助于数据开发人员专注于业务逻辑的实现,提升开发效率。
2.DevTools
主要提供传统脚本语言sql、python 等开发工具,快速与调度平台集成,方便使用。
3.Migration and Deployment tools
数据迁移和部署管理工具。针对开发、测试环境是网络隔离的行业,需提供有效的导入、导出功能合理的部署到生产环境中。
4.管理与监控工具
对系统管理员友好的离线任务运维相关的管理、监控、告警工具。
二、Job Scheduler
接下来和大家介绍一下调度系统对比
01 主流调度系统优缺点

Oozie
Oozie 是一个基于工作流引擎的开源框架,提供对Hadoop MapReduce、Pig Jobs的任务调度与协调。Oozie 需要部署到 Java Servlet 容器中运行。主要用于定时调度任务,多任务可以按照执行的逻辑顺序调度。
Airflow
Airflow 是一个 Airbnb 的 Workflow 开源项目,使用 Python 编写实现的任务管理、调度、监控工作流平台。Airflow 是基于 DAG(有向无环图)的任务管理系统,可以简单理解为是高级版的 crontab,但是它解决了 crontab 无法解决的任务依赖问题。与 crontab 相比 Airflow 可以方便查看任务的执行状况(执行是否成功、执行时间、执行依 赖等),可追踪任务历史执行情况,任务执行失败时可以收到邮件通知,查看错误日志。
Apache Dolphinscheduler
DolphinScheduler 是一个分布式去中心化,易扩展的可视化 DAG 工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
Control-M
Control-MM 是一个商业版的跨平台的作业调度管理软件,功能强大,可编程性较弱。
Azkaban
Azkaban 是由 Linkedin 公司推出的一个批量工作流任务调度器,用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban 使用 job 配置文件建立任务之间的依赖关系,并提供一个易于使用的 web 用户界面维护和跟踪你的工作流。Azkaban 要求所有节点对等部署,但是某些场景只要支持高可用不需要节点完全对等。
02 调度系统的服务

Timer Service
提供 crontab 表达式的定时服务,按固定的周期执行工作流。
DAG Compution
DAG 计算经常指的是将计算任务在内部分解成为若干个子任务,将这些子任务之间的逻辑关系或顺序构建成 DAG(有向无环图)结构。
Task Execution
任务运行是由调度系统的执行引擎根据任务的类型、参数、环境、引用的数据源等来执行任务。
Environment Manage
针对分布式调度引擎,需要提供节点管理功能,便于任务在不同的节点来执行。从而超越单机限制,实现任务的大规模运行。
Alert Service
当任务执行失败、超时以及在指定的时间未完成的时候,需要通知用户以及系统管理员及时的做出处理。
What’s more?
除以上功能,我们希望调度能提供环境、数据源管理功能。工作流配置环境变量之后,所有任务都能直接引用它。数据源可以根据不同的任务类型,以注入的方式提供给其他任务。
03 Job 的元数据
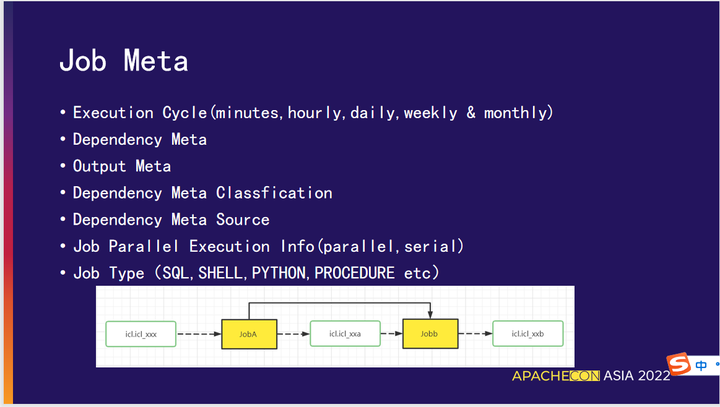
Execution Cycle
(minutes,hourly,daily,weekly & monthly)
任务执行周期(分钟,每小时,每天,每周和每月)。
Dependency Meta
任务依赖的上游元数据信息(文件、表等等)。
Output Meta
任务依赖的下游元数据信息(文件、表等等)。
Dependency Meta Classfication
对依赖的元数据进行分类、区分来源。
Dependency Meta Source
对任务依赖的元数据逆向解析,获取上下游任务,为工作流自动编排以及触发提供合理的依据。
Job Parallel Execution Info(parallel,serial)
控制任务的并行执行状态(并行、串行)。
Job Type
任务类型(SQL、SHELL、PYTHON、PROCEDURE 等等)。
04 Job 开发

Intergration IDE(script language,shell,sql,python etc)
集成IDE开发环境(script language,shell,sql,python 任务等)。
configurable resource file(jar,spark etc)
可配置的资源文件(jar,spark 无法通过文本编辑的任务等)。
custom components
定制化的组件,例如离线数据平台中,将数据同步作为特定的组件,只需要对数据同步做简单的配置就可以实现数据同步的过程。
Third Party Job
第三方作业,由特定的应用系统自定生成脚本,来实现作业目标。
三、第三方作业集成
有两种方式与第三方作业集成,主要用第二种方式处理。
第一种方式:pull
由调度系统提供能被第三方系统可调用的接口。
在系统中开发,在调度程序中配置调度程序。 在第三方系统中配置作业,在调度系统中配置调度,运行作业。
单点作业执行失败瓶颈。
缺点:需多次在第三方系统开发,以及在调度系统中配置调度。

第二种方式:push
调度系统提供可编程的API。
第三方系统开发作业并且把作业推送到调度系统,在调度系统中自动配置、调度任务。
01 任务的执行和通知
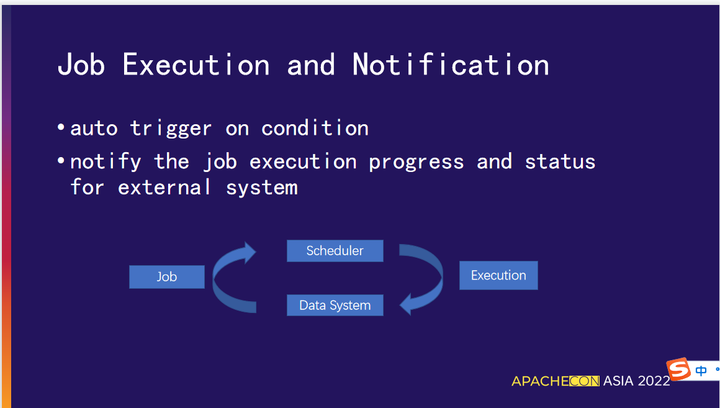
任务执行:自动触发、根据条件、上游任务依赖
任务通知:作业的执行进度和状态以消息推送的方式暴露给第三方系统。
02 数据集成的配置样例

以上列举了第三方系统集成的配置样例。
调度系统提供可编程的接口,实现环境信息的注入功能。在第三方系统中只需要声明不同类型的数据源,不需要配置各数据源的详细信息例如(IP、端口、用户名、密码等),这部分在调度系统配置数据源和环境信息注入给任务。再由任务从参数中解析后访问对应数据源和环境。这样可以简化 ETL 任务数据源的管理功能。
03 作业的编排

传统的作业编排是用户通过拖拉拽连线的方式来实现, 我们的改进点:
把作业的编排纳入到工作流中。
通过作业依赖的元数据信息,实现上下游作业的配置。
ETL 作业中部分表(某些维度表)是不变更的,可以把这些表加入到白名单中。工作流在自动变动、依赖解析时无需查找白名单中对应的表上游的业务逻辑。
视图是影响自动配置工作流程的重要因素。视图没有 ETL 任务,我们需要把视图考虑成一个虚拟的任务,把视图的数据导入到调度平台中 ,这样使得调度系统能够意识到依赖视图的任务本质上是依赖视图中对应基本表的任务。
04 作业的影响分析

由于有元数据信息,作业的影响分析非常简单。
通过元数据上下游的依赖关系来解决任务所依赖的上游任务,避免通过人工配置来降低出错概率。
计算最新的一些影响,比如:作业停止、失败,影响下游那些作业。
05 低代码平台

对于一般的场景,构建模板作业是一个不错的选择,可以重复利用模板作业计算流程来实现大量的作业配置,只需要对核心流程配置一次,对其进行参数化即可。
对特定系统支撑,如指标管理系统,标签系统,数据脱敏系统等。
代码友好性,在必要的时候进行编码。
用户友好性,有些场景下使用系统编码,而不是通过用户编码实现,用户获取想要的数据来组装特定的数据模型,而无需再次编码,例如:用户基于基础标签通过点击配置来组装衍生标签。
我的分享就到这里,谢谢大家,也欢迎大家在私下与我交流沟通。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A"volunteer+wanted"
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
ApacheCon Asia 2022 精彩回顾 | 如何让更多人从大数据中获益?的更多相关文章
- SphereEx 登陆 ApacheCon Asia|依托 ShardingSphere 可插拔架构体系打造数据应用完整生态
2021 年 8 月 8 日,ApacheCon 首次亚洲大会于线上正式闭幕.作为久负盛名的开源盛宴,本届 ApacheCon Asia 受到了海内外众多开源领域人士的关注. 作为 Apache 软件 ...
- 文末福利丨i春秋互联网安全校园行第1站精彩回顾
活动背景 为响应国家完善网络安全人才培养体系.推动网络安全教育的号召,i春秋特此发起“互联网安全校园行”系列活动.旨在通过活动和知识普及提升大学生信息安全意识,并通过线下交流.技能分享.安全小活动以及 ...
- 2021 & 2022年终回顾:山河无恙,烟火寻常
前言 又到了一年一度年终回顾的时候了,回想起去年年底圣诞节的时候由于忙着参加黑客松大赛,一下子就进入了新的一年,失去了年终回顾的动力,所以今年提前两个月开始进行回顾,这样的话今年最后一天就可以顺利发文 ...
- 区块链、云计算、大数据、人工智能、FinTech带来的挑战与机遇,中国技术开放日上海站精彩回顾
区块链.云计算.大数据.人工智能.FinTech带来的挑战与机遇,中国技术开放日上海站精彩回顾 | 作者 韩婷 发布于 2016年12月26日. 估计阅读时间: 不到一分钟 | 欲知区块链.VR.Te ...
- 探索真实事物的虚拟再现——微软亚洲研究院SIGGRAPH Asia 2014精彩入选论文赏析
Asia 2014精彩入选论文赏析" title="探索真实事物的虚拟再现--微软亚洲研究院SIGGRAPH Asia 2014精彩入选论文赏析"> SIGGRAP ...
- 【译】2022 年回顾:Web 性能有哪些新变化?
原文地址:https://www.debugbear.com/blog/2022-in-web-performance 若对文中提到的一些性能参数不太熟悉,可以参考我之前的一篇博文<性能参数和优 ...
- TCP / IP 精彩回顾-必看
TCP/IP 协议出现的原因是互联网世界各个主机作为一个个独立的个体,如何制定统一的规则让他们互相通信是达成万物互联的纽带.基于此,设定了 TCP/IP 协议来规范网络访问行为.TCP/IP 并不是一 ...
- 大数据入门第九天——MapReduce详解(五)mapJoin、GroupingComparator与更多MR实例
一.数据倾斜分析——mapJoin 1.背景 接上一个day的Join算法,我们的解决join的方式是:在reduce端通过pid进行串接,这样的话: --order ,,P0001, ,,P0001 ...
- 分享|2022数字安全产业大数据白皮书(附PDF)
内容摘要: 2021年以来,数字安全赛道的受关注程度达到一个历史新高度.<数据安全法><个人信息保护法><关键信息基础设施安全保护条例>,一个接一个重磅的法规接连出 ...
- Unite洛杉矶峰会精彩回顾:从图形、平台再到VR
产品质量与工作流程 在Unity的研发过程中,保持创新的步伐与稳定性的平衡一直是一个挑战.Unity曾经向所有的用户承诺:Unity将专注于提升产品的质量并保证Unity版本稳定性的决心. 大会伊始, ...
随机推荐
- SM4Utils加解密demo
SM4Utils加解密demo package com.example.core.mydemo.sm4; import cn.org.bjca.utils.SM4Utils; public class ...
- 【已结束】阿珏Blog三周年特别纪念活动
Tips:当你看到这个提示的时候,说明当前的文章是由原emlog博客系统搬迁至此的,文章发布时间已过于久远,编排和内容不一定完整,还请谅解` [已结束]阿珏Blog三周年特别纪念活动 日期:2019- ...
- Spring Boot入门实验
一. 实验目的和要求 1.掌握使用 IDEA 通过 Maven 和 Spring Initializr 的方式创建 Spring Boot 应用程序: 2.掌握 Maven 的工作原理: 3.了解 s ...
- Lru-k在Rust中的实现及源码解析
LRU-K 是一种缓存淘汰算法,旨在改进传统的LRU(Least Recently Used,最近最少使用)算法的性能.将其中高频的数据达到K次访问移入到另一个队列进行保护. 算法思想 LRU-K中的 ...
- 卷积神经网络-AlexNet
AlexNet 一些前置知识 top-1 和top-5错误率 top-1错误率指的是在最后的n哥预测结果中,只有预测概率最大对应的类别是正确答案才算预测正确. top-5错误率指的是在最后的n个预测结 ...
- UIButton选择状态下长按时会变回原始状态
问题大概就像这样 (请无视那红字) 一般而言这是高亮状态的设置有所缺乏.完善代码如下: [_pupilBtn setImage:[UIImage imageNamed:@"a1"] ...
- 算法金 | A - Z,115 个数据科学 机器学习 江湖黑话(全面)
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 机器学习本质上和数据科学一样都是依赖概率统计,今天整整那些听起来让人头大的机器学习江湖 ...
- 使用bootchart 对 高通Android 进行性能分析
使用bootchart 对 高通Android 进行性能分析 Android版本:7.0 适用平台:高通和MTK 参考: https://blog.csdn.net/qq_19923217/artic ...
- UART和RS232、RS485的关系是什么?
串口通讯是电子工程师和嵌入式开发工程师面对的最基本问题,RS232则是其中最简单最常用的通讯方式.但是初学者往往搞不清有关的名词如UART和RS232或RS485之间是什么关系,因为它们经常被放到语句 ...
- “科来杯”第九届山东省大学生网络安全技能大赛决赛部分wp
1.损坏的流量包 wireshark打不开,丢进winhex里,找关键字flag 哎,没找到. 那就仔细看看,在最后发现一串类似base64的密文 base64解密 得到flag 2.签到题 一个 ...