对于强化学习算法中的AC算法(Actor-Critic算法) 的一些理解
AC算法(Actor-Critic算法)最早是由《Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems》论文提出,不过该论文是出于credit assignment problem设计了actor部分和critic部分,其中critic对actor获得的reward进行credit assignment 处理和学习,然后把处理后获得的新reward传递给actor进行学习,这样结合了critic和actor两部分学习器,得到了一个更优的学习器。
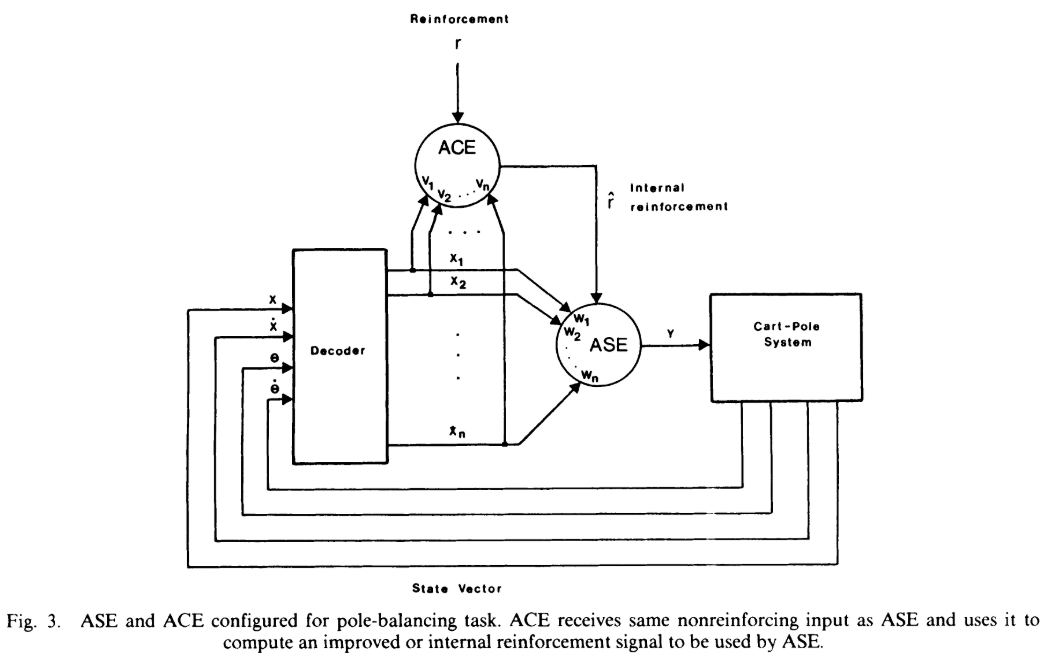
可以看到最初的AC算法只是为了更好解决credit assignment问题,将Actor和Critic两者结合,其中的Critic主要就是为每一步的actor学习给出一个更好的credit assignment的reward。最初的AC算法中critic更多的是在辅助actor来进行学习的,可以看到现在的AC算法除了保留了将两个学习器结合的思想以外已经与最初的AC算法差距较大了,而现在的AC算法形式为论文《Policy Gradient Methods for Reinforcement Learning with Function Approximation》给出的。
因此,本文主要讨论的是对论文《Policy Gradient Methods for Reinforcement Learning with Function Approximation》的一些理解。前几天写过一个该论文的一些基本形式和证明(
论文《policy-gradient-methods-for-reinforcement-learning-with-function-approximation 》的阅读——强化学习中的策略梯度算法基本形式与部分证明
),所以本文算是一个补充版,或是后续版。
---------------------------------------------------------
首先给出论文《Policy Gradient Methods for Reinforcement Learning with Function Approximation》中的定理1:
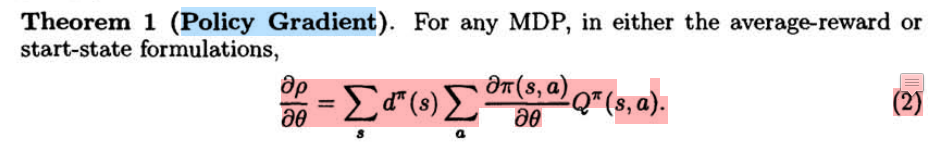
定理1 又被称作是策略梯度定理,可以说强化学习中的策略梯度一类的算法基本都是基于这个定理来进行构建的。由于前文对该定理给出了一些解释,这里就不具体解释了。
本文的重点是讲一下对论文中定理2的一些理解, 下面给出定理2及其前提设定:

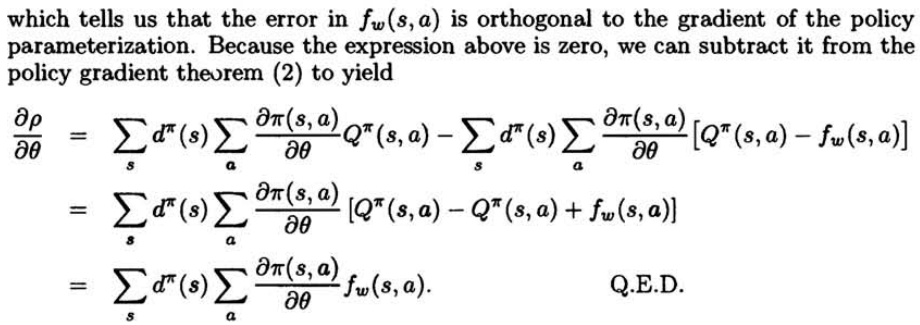
上面的内容比较长,可以说公式(3)和(4)是对定理2的前提设定,也就是说定理2是假设在满足公式(3)和(4)的前提条件下进行推导的。
由公式(3)和(4)我们可以推导出定理2的表现形式,即公式(5)。其中公式(6)及以下为对定理2的表现形式(即公式(5))进行的证明过程。
公式(3)的意思是说,满足公式(3)的话,f(s,a) 对 Q(s,a)的估计为收敛于局部最优,换句话说就是:公式(3)是 f(s,a) 对 Q(s,a)的估计收敛于局部最优的表现形式。假设公式(3)成立则说明 f(s,a) 对 Q(s,a)的估计是假设收敛于局部最优的。
公式(4)则是假设f(s,a)对参数w的微分等于log(pi(s,a)) 对参数theta的微分。
在公式(3)和(4)成立的前提下,才得到定理2 的表现形式(公式5),也就是说定理2是在讲满足公式(3)和(4)的前提下才可以用f(s,a)替代Q(s,a)来对策略的表现求梯度(即定理1)。
刚开始看到定理2的时候感觉多此一举,直接用一个函数来近似表示Q(s,a)不就可以了吗,为什么还要假设满足公式(3)和(4)。研究了些时间才有所了解,如果不满足公式(3),那么f(s,a)对Q(s,a)的估计是没有限定的,也就是说f(s,a)是不能很好的来估计Q(s,a)的,所以我们要加入公式(3)作为前提。或者说只有满足了公式(3)才能说f(s,a)是对Q(s,a)的很好的估计,因为此时的估计函数f(s,a)是收敛于局部最优的。
那么公式(4)又是为何呢,它又起到什么作用呢?
个人理解:
即使满足了公式(3),f(s,a)是对Q(s,a)的一个很好的估计(收敛于局部最优),也不能说f(s,a)就一定可以替换定理1中的Q(s,a)。因为毕竟f(s,a)并不正在等于Q(s,a),只能说在(s,a) 这个(状态,动作 对)分布的情况下,f(s,a)与Q(s,a)的差值平方在(s,a)分布的情况下的期望对参数w的导数为0,因为毕竟 f(s,a) 对Q(s,a)的估计还是难免会存在误差的。
在不考虑公式(4)的情况下,我们只能说下面的公式是成立的:

但是对于公式(6),即下面公式,是难以使其成立的。

也或者说下面公式是难以成立的:
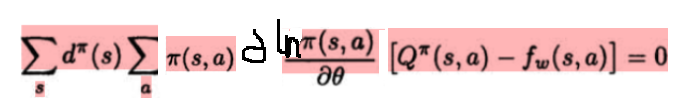
----------------------------------------------
以上对公式(3)和(4)的一个理解就是,如果只满足了公式(3)只能说明f(s,a)对Q(s,a)的估计收敛于局部最优,而只有同时满足公式(4)的收敛于局部最优的f(s,a)才能很好的替换定理1中的Q(s,a)。
当然,在实际应用中公式(3)和公式(4)都是难以满足的,或者说论文中的定理1和定理2是纯理论假设推导,是在一种很理想化的情况下才会成立。
公式(3)的表现形式我们可以假设策略固定不变,然后在固定策略的前提下一直训练f(s,a)使其对Q(s,a)的估计收敛于局部最优,而此时所得到的f(s,a)并不一定会满足公式(4)。而只有满足公式(4)的收敛于局部最优的f(s,a)才满足定理2,才可以替换定理1中的Q(s,a)。
现在的常用函数一般为深度神经网络,也就是说f(s,a)和pi(s,a)一般也是用深度神经网络来表示的,现在常用的对f(s,a)进行更新的方法一般可以较好的使f(s,a)对Q(s,a)的估计收敛,至于能否收敛于局部最优就难以保证了,而对于公式(4)中的限定现在也是基本没有见过哪个具体算法对其进行限定的。
可以说对公式(3)基本可以实现部分满足(使其收敛,不保证收敛于局部最优),而对于公式(4)的限定实际算法一般不做处理。
----------------------------------------------------
对于强化学习算法中的AC算法(Actor-Critic算法) 的一些理解的更多相关文章
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 基于深度强化学习(DQN)的迷宫寻路算法
QLearning方法有着明显的局限性,当状态和动作空间是离散的且维数不高时可使用Q-Table存储每个状态动作的Q值,而当状态和动作时高维连续时,该方法便不太适用.可以将Q-Table的更新问题变成 ...
- 强化学习-学习笔记14 | 策略梯度中的 Baseline
本篇笔记记录学习在 策略学习 中使用 Baseline,这样可以降低方差,让收敛更快. 14. 策略学习中的 Baseline 14.1 Baseline 推导 在策略学习中,我们使用策略网络 \(\ ...
- 在 Prim 算法中使用 pb_ds 堆优化
在 Prim 算法中使用 pb_ds 堆优化 Prim 算法用于求最小生成树(Minimum Spanning Tree,简称 MST),其本质是一种贪心的加点法.对于一个各点相互连通的无向图而言,P ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 谷歌重磅开源强化学习框架Dopamine吊打OpenAI
谷歌重磅开源强化学习框架Dopamine吊打OpenAI 近日OpenAI在Dota 2上的表现,让强化学习又火了一把,但是 OpenAI 的强化学习训练环境 OpenAI Gym 却屡遭抱怨,比如不 ...
- 强化学习论文(Scalable agent alignment via reward modeling: a research direction)
原文地址: https://arxiv.org/pdf/1811.07871.pdf ======================================================== ...
- 谷歌推出新型强化学习框架Dopamine
今日,谷歌发布博客介绍其最新推出的强化学习新框架 Dopamine,该框架基于 TensorFlow,可提供灵活性.稳定性.复现性,以及快速的基准测试. GitHub repo:https://git ...
随机推荐
- Python使用.NET开发的类库来提高你的程序执行效率
Python由于本身的特性原因,执行程序期间可能效率并不是很理想.在某些需要自己提高一些代码的执行效率的时候,可以考虑使用C#.C++.Rust等语言开发的库来提高python本身的执行效率.接下来, ...
- Jmeter自动录制脚本
1.Jmeter配置 1.1新增一个线程组 1.2Jmeter中添加HTTP代理 1.3配置HTTP代理服务器 修改端口 修改Target Cintroller(目标控制器) 修改Grouping(分 ...
- [代码]C语言进行md5,SHA256,SHA512加密
前言 原本在学puppet,它的user资源需要设置hash后的散列值,结果-我把加密算法,shadow文件,密码破解搞了个遍- 环境 CentOS7 gcc编译器 /etc/shadow文件解析 文 ...
- SpringBoot动态数据源配置
SpringBoot动态数据源配置 序:数据源动态切换流程图如下: 1:pom.xml文件依赖声明 <dependency> <groupId>org.springfram ...
- Linux设备模型:2、基本对象 Kobject、Kset、Ktype
原文:http://www.wowotech.net/device_model/kobject.html 作者:wowo 发布于:2014-3-7 0:25 分类:统一设备模型 前言 Kobject是 ...
- AT24C02、04、08、16 操作说明
我们这里介绍一下常见的EEPROM,ATMEL的AT24x系列中的AT24C02,学会了这个芯片,其他系列的芯片也是类似的. AT24C02的存储容量为2K bit,内容分成32页,每页8Byte ( ...
- sqoop导入导出到mysql,hbase,hive,hdfs系统,多表关联导出案例
Sqoop工具1.协助 RDBMS 与 Hadoop 之间进行高效的大数据交流.把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)同时也可以把数据从 Hadoop 系 ...
- Ubuntu 查看用户历史记录
Ubuntu 查看用户历史记录 1. 查看用户命令行历史记录 1. 查看当前登录账号所属用户的历史命令行记录 打开命令行,输入 history 就会看到当前登录账号所属用户的历史记录 2. 查看系统所 ...
- ISCTF2023
ISCTF 2023 Misc 签到题 公众号发送:小蓝鲨,我想打ctf ISCTF{W3lcom3_7O_2023ISCTF&BlueShark} 你说爱我?尊嘟假嘟 你说爱我替换.,真嘟替 ...
- 如何计算QPS、PV和需要部署机器数量?
基本概念 网站访问量的常用衡量标准:独立访客(UV) 和 综合浏览量(PV),一般以日为单位来计算. 独立访客(UV):指一定时间范围内相同访客多次访问网站,只计算为1个独立访客. 综合浏览量(PV) ...