Linux系统Mariadb初始化相关(ubuntu)
#事先声明,此文是一边写一边操作的,中间可能有不一致的地方,大体思路就是参照windows下的目录规范,将 mysql的各目录及文件进行类比放置,然后执行重建数据库命令,也许你只是想修改下data目录,那么下面的指令按需修改即可
#数据库重建 sudo mysql_install_db --defaults-file=/opt/mysql/conf/my.cnf --datadir=/opt/mysql/data/ --user=mysql
#创建新的mysql目录,data和log目录
sudo mkdir /opt/mysql /opt/mysql/data /opt/mysql/log /opt/mysql/share /opt/mysql/bin
#复制原有的相关命令 到 mysql/bin
sudo cp -r /usr/bin/mysql* /opt/mysql/bin && sudo cp -r /usr/bin/mariadb* /opt/mysql/bin
sudo cp -r /usr/sbin/mysql* /opt/mysql/bin && sudo cp -r /usr/sbin/mariadb* /opt/mysql/bin
sudo cp -r /user/bin/my_print_defaults /opt/mysql/bin
#复制配置文件
sudo cp -r /etc/mysql /opt/mysql && sudo mv /opt/mysql/mysql /opt/mysql/conf
#复制原有的plugin 到 mysql/plugin
sudo cp -r /usr/lib/mysql/plugin /opt/mysql
#复制原有的charset目录到share目录
sudo cp -r /usr/share/mysql/* /opt/mysql/share
#编辑全局 my.cnf 配置文件
sudo vim /opt/mysql/conf/my.cnf
#注释原有的两行#include代码,复制粘贴如下代码后保存并退出
!includedir /opt/mysql/conf/conf.d/
!includedir /opt/mysql/conf/mariadb.conf.d/
执行如下命令
sudo vim conf/mariadb.conf.d/50-server.cnf
执行清空指令:
:%d
复制粘贴如下内容


[server]
character-set-server=utf8mb4
[mysqld]
pid-file = /run/mysqld/mysqld.pid
basedir=/opt/mysql
datadir=/opt/mysql/data
character-set-server=utf8mb4
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
max_connections=1000
server-id = 109
thread_handling=pool-of-threads back_log = 600
# MySQL能有的连接数量。当主要MySQL线程在一个很短时间内得到非常多的连接请求,这就起作用,
# 然后主线程花些时间(尽管很短)检查连接并且启动一个新线程。back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。
# 如果期望在一个短时间内有很多连接,你需要增加它。也就是说,如果MySQL的连接数据达到max_connections时,新来的请求将会被存在堆栈中,
# 以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。
# 另外,这值(back_log)限于您的操作系统对到来的TCP/IP连接的侦听队列的大小。
# 你的操作系统在这个队列大小上有它自己的限制(可以检查你的OS文档找出这个变量的最大值),试图设定back_log高于你的操作系统的限制将是无效的。
max_connections = 500
# MySQL的最大连接数,如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,介于MySQL会为每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。可以过'conn%'通配符查看当前状态的连接数量,以定夺该值的大小。
max_connect_errors = 6000
# 对于同一主机,如果有超出该参数值个数的中断错误连接,则该主机将被禁止连接。如需对该主机进行解禁,执行:FLUSH HOST。
open_files_limit = 65535
# MySQL打开的文件描述符限制,默认最小1024;当open_files_limit没有被配置的时候,比较max_connections*5和ulimit -n的值,哪个大用哪个,
# 当open_file_limit被配置的时候,比较open_files_limit和max_connections*5的值,哪个大用哪个。
table_open_cache = 128
# MySQL每打开一个表,都会读入一些数据到table_open_cache缓存中,当MySQL在这个缓存中找不到相应信息时,才会去磁盘上读取。默认值64
# 假定系统有200个并发连接,则需将此参数设置为200*N(N为每个连接所需的文件描述符数目);
# 当把table_open_cache设置为很大时,如果系统处理不了那么多文件描述符,那么就会出现客户端失效,连接不上
max_allowed_packet = 1024M
# 接受的数据包大小;增加该变量的值十分安全,这是因为仅当需要时才会分配额外内存。例如,仅当你发出长查询或MySQLd必须返回大的结果行时MySQLd才会分配更多内存。
# 该变量之所以取较小默认值是一种预防措施,以捕获客户端和服务器之间的错误信息包,并确保不会因偶然使用大的信息包而导致内存溢出。
binlog_cache_size = 128M
# 一个事务,在没有提交的时候,产生的日志,记录到Cache中;等到事务提交需要提交的时候,则把日志持久化到磁盘。默认binlog_cache_size大小32K
max_heap_table_size = 128M
# 定义了用户可以创建的内存表(memory table)的大小。这个值用来计算内存表的最大行数值。这个变量支持动态改变
tmp_table_size = 128M
# MySQL的heap(堆积)表缓冲大小。所有联合在一个DML指令内完成,并且大多数联合甚至可以不用临时表即可以完成。
# 大多数临时表是基于内存的(HEAP)表。具有大的记录长度的临时表 (所有列的长度的和)或包含BLOB列的表存储在硬盘上。
# 如果某个内部heap(堆积)表大小超过tmp_table_size,MySQL可以根据需要自动将内存中的heap表改为基于硬盘的MyISAM表。还可以通过设置tmp_table_size选项来增加临时表的大小。也就是说,如果调高该值,MySQL同时将增加heap表的大小,可达到提高联接查询速度的效果
read_buffer_size = 128M
# MySQL读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小。
# 如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能
read_rnd_buffer_size = 128M
# MySQL的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,
# MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大
sort_buffer_size = 128M
# MySQL执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。
# 如果不能,可以尝试增加sort_buffer_size变量的大小
join_buffer_size = 128M
# 联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每连接独享
thread_cache_size = 8
# 这个值(默认8)表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中,
# 如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多新的线程,
# 增加这个值可以改善系统性能.通过比较Connections和Threads_created状态的变量,可以看到这个变量的作用。(–>表示要调整的值)
# 根据物理内存设置规则如下:
# 1G —> 8
# 2G —> 16
# 3G —> 32
# 大于3G —> 64
query_cache_size = 128M
#MySQL的查询缓冲大小(从4.0.1开始,MySQL提供了查询缓冲机制)使用查询缓冲,MySQL将SELECT语句和查询结果存放在缓冲区中,
# 今后对于同样的SELECT语句(区分大小写),将直接从缓冲区中读取结果。根据MySQL用户手册,使用查询缓冲最多可以达到238%的效率。
# 通过检查状态值'Qcache_%',可以知道query_cache_size设置是否合理:如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况,
# 如果Qcache_hits的值也非常大,则表明查询缓冲使用非常频繁,此时需要增加缓冲大小;如果Qcache_hits的值不大,则表明你的查询重复率很低,
# 这种情况下使用查询缓冲反而会影响效率,那么可以考虑不用查询缓冲。此外,在SELECT语句中加入SQL_NO_CACHE可以明确表示不使用查询缓冲
query_cache_limit = 128M
#指定单个查询能够使用的缓冲区大小,默认1M
key_buffer_size = 128M
#指定用于索引的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),到你能负担得起那样多。如果你使它太大,
# 系统将开始换页并且真的变慢了。对于内存在4GB左右的服务器该参数可设置为384M或512M。通过检查状态值Key_read_requests和Key_reads,
# 可以知道key_buffer_size设置是否合理。比例key_reads/key_read_requests应该尽可能的低,
# 至少是1:100,1:1000更好(上述状态值可以使用SHOW STATUS LIKE 'key_read%'获得)。注意:该参数值设置的过大反而会是服务器整体效率降低
ft_min_word_len = 4
# 分词词汇最小长度,默认4
transaction_isolation = REPEATABLE-READ
# MySQL支持4种事务隔离级别,他们分别是:
# READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE.
# 如没有指定,MySQL默认采用的是REPEATABLE-READ,ORACLE默认的是READ-COMMITTED
log_bin = mysql-bin
binlog_format = mixed
#超过30天的binlog删除
expire_logs_days = 30
log_error =/opt/mysql/logs/mysql-error.log
#错误日志路径
slow_query_log = 1
#慢查询时间 超过1秒则为慢查询
long_query_time = 1
slow_query_log_file = /opt/mysql/logs/mysql-slow.log
performance_schema = 0
#explicit_defaults_for_timestamp
#lower_case_table_names = 1 #不区分大小写
#MySQL选项以避免外部锁定。该选项默认开启
#skip-external-locking
#默认存储引擎
default-storage-engine = InnoDB
innodb_file_per_table = 1
# InnoDB为独立表空间模式,每个数据库的每个表都会生成一个数据空间
# 独立表空间优点:
# 1.每个表都有自已独立的表空间。
# 2.每个表的数据和索引都会存在自已的表空间中。
# 3.可以实现单表在不同的数据库中移动。
# 4.空间可以回收(除drop table操作处,表空不能自已回收)
# 缺点:
# 单表增加过大,如超过100G
# 结论:
# 共享表空间在Insert操作上少有优势。其它都没独立表空间表现好。当启用独立表空间时,请合理调整:innodb_open_files
innodb_open_files = 5000
# 限制Innodb能打开的表的数据,如果库里的表特别多的情况,请增加这个。这个值默认是300
innodb_buffer_pool_size = 1024M
# InnoDB使用一个缓冲池来保存索引和原始数据, 不像MyISAM.
# 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少.
# 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80%
# 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.
# 注意在32位系统上你每个进程可能被限制在 2-3.5G 用户层面内存限制,
# 所以不要设置的太高.
innodb_write_io_threads = 4
innodb_read_io_threads = 4
# innodb使用后台线程处理数据页上的读写 I/O(输入输出)请求,根据你的 CPU 核数来更改,默认是4
# 注:这两个参数不支持动态改变,需要把该参数加入到my.cnf里,修改完后重启MySQL服务,允许值的范围从 1-64
innodb_thread_concurrency = 0
# 默认设置为 0,表示不限制并发数,这里推荐设置为0,更好去发挥CPU多核处理能力,提高并发量
innodb_purge_threads = 1
# InnoDB中的清除操作是一类定期回收无用数据的操作。在之前的几个版本中,清除操作是主线程的一部分,这意味着运行时它可能会堵塞其它的数据库操作。
# 从MySQL5.5.X版本开始,该操作运行于独立的线程中,并支持更多的并发数。用户可通过设置innodb_purge_threads配置参数来选择清除操作是否使用单
# 独线程,默认情况下参数设置为0(不使用单独线程),设置为 1 时表示使用单独的清除线程。建议为1
innodb_flush_log_at_trx_commit = 2
# 0:如果innodb_flush_log_at_trx_commit的值为0,log buffer每秒就会被刷写日志文件到磁盘,提交事务的时候不做任何操作(执行是由mysql的master thread线程来执行的。
# 主线程中每秒会将重做日志缓冲写入磁盘的重做日志文件(REDO LOG)中。不论事务是否已经提交)默认的日志文件是ib_logfile0,ib_logfile1
# 1:当设为默认值1的时候,每次提交事务的时候,都会将log buffer刷写到日志。
# 2:如果设为2,每次提交事务都会写日志,但并不会执行刷的操作。每秒定时会刷到日志文件。要注意的是,并不能保证100%每秒一定都会刷到磁盘,这要取决于进程的调度。
# 每次事务提交的时候将数据写入事务日志,而这里的写入仅是调用了文件系统的写入操作,而文件系统是有 缓存的,所以这个写入并不能保证数据已经写入到物理磁盘
# 默认值1是为了保证完整的ACID。当然,你可以将这个配置项设为1以外的值来换取更高的性能,但是在系统崩溃的时候,你将会丢失1秒的数据。
# 设为0的话,mysqld进程崩溃的时候,就会丢失最后1秒的事务。设为2,只有在操作系统崩溃或者断电的时候才会丢失最后1秒的数据。InnoDB在做恢复的时候会忽略这个值。
# 总结
# 设为1当然是最安全的,但性能页是最差的(相对其他两个参数而言,但不是不能接受)。如果对数据一致性和完整性要求不高,完全可以设为2,如果只最求性能,例如高并发写的日志服务器,设为0来获得更高性能
innodb_lock_wait_timeout = 12000
# InnoDB事务在被回滚之前可以等待一个锁定的超时秒数。InnoDB在它自己的锁定表中自动检测事务死锁并且回滚事务。InnoDB用LOCK TABLES语句注意到锁定设置。默认值是50秒
#bulk_insert_buffer_size = 1M
# 此参数确定数据日志文件的大小,更大的设置可以提高性能,但也会增加恢复故障数据库所需的时间
#innodb_log_files_in_group = 3
# 为提高性能,MySQL可以以循环方式将日志文件写到多个文件。推荐设置为3
#innodb_max_dirty_pages_pct = 90
# innodb主线程刷新缓存池中的数据,使脏数据比例小于90%
#innodb_lock_wait_timeout = 12000
# InnoDB事务在被回滚之前可以等待一个锁定的超时秒数。InnoDB在它自己的锁定表中自动检测事务死锁并且回滚事务。InnoDB用LOCK TABLES语句注意到锁定设置。默认值是50秒 [client]
plugin-dir=/opt/mysql/plugin
执行如下命令初始化数据库
sudo mysql_install_db --defaults-file=/opt/mysql/conf/my.cnf --basedir=/opt/mysql --datadir=/opt/mysql/data --user=mysql
附加说明:可能中途还是会遇到些奇奇怪怪的问题,但是解决问题的核心思想是固定的,即windows平台有哪些文件,linux平台也差不多
其次,就是权限问题 sudo chown -R mysql:mysql /opt/mysql/ && sudo chown -R mysql:mysql /opt/mysql/*
最后,如果完成以上操作了 执行命令 sudo mysql -u root -p 回车即可登录数据库,而后执行如下命令修改下密码并 flush privileges
alter user 'root'@'localhost' identified by '12345';
就可以通过navicat的ssh通道进行连接,如下图

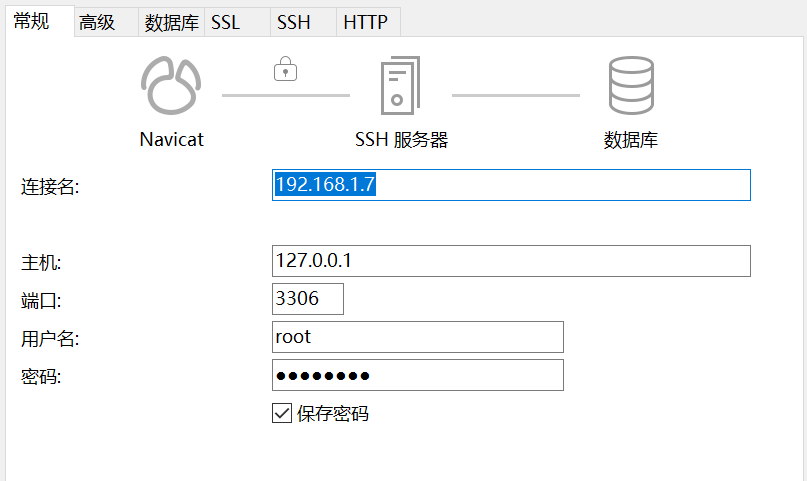
然后通过navicat修改下root 的host为%,而后 FLUSH PRIVILEGES
就可以无ssh通道进行连接了,当然如果你在线上生产服务器这么玩,那么建议修改下3306端口或者关闭防火墙的3306端口,只通过ssh通道(默认22端口也建议改为其它1024以后的任意端口)进行连接更为安全。
备注: chown -R mysql 文件夹名字 ,用于递归更改文件夹及自文件夹的拥有人为mysql
Linux系统Mariadb初始化相关(ubuntu)的更多相关文章
- Linux系统运维相关的面试题 (问答题)
这里给大家整理了一些Linux系统运维相关的面试题,有些问题没有标准答案,希望要去参加Linux运维面试的朋友,可以先思考下这些问题. 一.Linux操作系统知识 1.常见的Linux发行版本都有 ...
- Linux系统之网络相关的命令
Linux系统之网络相关的命令 网络概述 网络:通过通信介质和通信设备 将分布不同地点的两台或多台计算机,经过相应的程序实现通信switch 交换机router 路由器网络的功能:数据通信:利用网络传 ...
- JAVA如何利用Swiger获取Linux系统电脑配置相关信息
最近开发java应用程序,涉及到获取Linux服务器相关配置的问题,特地网上搜寻了下,采用Swiger包可以直接获取,再次小结一下,以便于以后能方便使用,也便于其他童鞋们学习. 推荐大家参考链接:ht ...
- windows系统如何通过Xshell 客户端连接 linux系统(主要介绍ubuntu系统)
一. 1.查看ubuntu系统的ip地址:ifconfig 在window系统运行窗口下:ping ubuntu系统的IP地址:例如:ping 192.168.163.129 出现下述命令就是ping ...
- Linux安装MariaDB+初始化数据库
背景说明: 在数据库中,mysql的是常用的数据库之一:作为一款开源的软件被广大公司所使用. 但是,mysql在被Oracle公司收购后,难免在以后会有取消开源的问题.所以急需一款新的数据库产品替换m ...
- Linux 系统及编程相关知识总汇
Linux C function() 参考手册 STL 学习文档 Linux内核
- 初涉定制linux系统之——rpm相关安装包的准备
在上一篇博客http://www.cnblogs.com/dengtr/p/5543820.html#3634582 中介绍了如何定制Centos系统镜像,但其中有个问题,就是服务所依赖的安装包不在原 ...
- Linux 系统的初始化配置
1.零时配置网卡IP地址 2.配置永久生效IP地址 需要进如 cd /etc/sysconfig/network-scripts 找到网卡文件编辑 3.零时主机名的更改. 4.永久主机名的更 ...
- Install Ubuntu On Windows10(win10上安装linux系统)
一.准备: 硬件:U盘 软件:ultraiso.Ubuntu镜像文件 二.安装linux: 1.Ubuntu官网(http://www.ubuntu.org.cn/download/alternati ...
- saltstack 初始化LINUX系统
前面我们已经了解了saltstack的基础功能,现在就可以使用saltstack为初始化新安装的linux系统. 初始化列表: 1.关闭selinux 3.修改sshd配置文件 4.内核优化 5.ul ...
随机推荐
- 告别os.path,拥抱pathlib
pathlib 模块是在Python3.4版本中首次被引入到标准库中的,作为一个可选模块.从Python3.6开始,内置的 open 函数以及 os . shutil 和 os.path 模块中的各种 ...
- Vue 动态插入组件 用js函数的方式
Vue 动态插入组件 用js函数的方式 第一步 import vue组件 第二步 Vue把组件扩展进去 第三步 创建实例 第四步 将组件的el挂载到document.body上 第五步 设置组件内部d ...
- 推荐一款idea神级免费插件【Bito-ChatGPT】
今天推荐一款IDEA 插件神器:Bito-ChatGPT,在 IDEA 中安装直接可以使用 GPT,不需要使用魔法! 还有很重要的一点这个插件完全免费,且不限次数(目前是免费不限制次数). 环境要求: ...
- js使用typeof与instanceof相结合编写一个判断常见变量类型的函数
/** * 常见类型判断 * @param {any} param */ function getParamType(param) { // 先判断是否能用typeof 直接判断 let types1 ...
- 06.Java虚拟机问题
目录介绍 6.0.0.1 运行时数据区域有哪些?Java虚拟机栈是做什么的?本地方法栈又是做什么的? 6.0.0.2 对象的内存布局?对象的访问定位方式有哪些?使用指针访问和使用句柄访问各具有何优势? ...
- 三维模型OBJ格式轻量化压缩在大规模场景的加载和渲染的作用分析
三维模型OBJ格式轻量化压缩在大规模场景的加载和渲染的作用分析 OBJ格式是一种常用的三维模型文件格式,它存储了三维模型的几何信息和纹理坐标等相关属性.在大规模场景中加载和渲染三维模型时,OBJ格式的 ...
- Oracle与MySQL的差异和对比
Oracle与MySQL的差异和对比:配套hands-on参考脚本. 方便客户针对培训课件内容进行动手实践,加强理解. --------------------------------- -- 主题: ...
- DevOps迈向标准化,平台工程让开发运维更轻松
在近一代人的时间里,DevOps 在软件开发和运维领域占据了主导地位.这是一套开发人员都离不开的技能和方法.Pearl Zhu 在 "The Digital Master" 一书中 ...
- 浅谈ET框架--ECS设计核心(一)
ET框架的ECS设计核心可以总结为一句话,那就是: 继承转组件,多态转分发 OOP设计里的继承更换为组件Component模式,多态转成分发模式. 框架代码里头的案例: 数值组件挂载Entity上. ...
- OpenHarmony社区运营报告(2023年8月)
本月快讯 ● 2023年8月3日,OpenAtom OpenHarmony(以下简称"OpenHarmony")发布了Beta2版本.OpenHarmony 4.0 Beta2 ...