parquet列存储本身自带压缩 配合snappy或者lzo等可以进行二次压缩
上传txt文件到hdfs,txt文件大小是74左右。
这里提醒一下,是不是说parquet加lzo可以把数据压缩到这个地步,因为我的测试数据存在大量重复。所以下面使用parquet和lzo的压缩效果特别好。

创建hive表,使用parquet格式存储数据
不可以将txt数据直接加载到parquet的表里面,需要创建临时的txt存储格式的表
CREATE TABLE emp_txt (
empno int,
ename string,
job string,
mgr int,
hiredate DATE,
sal int,
comm int,
deptno int
)
partitioned BY(dt string,hour string)
row format delimited fields terminated by ",";
然后在创建parquet的表
CREATE TABLE emp_parquet (
empno int,
ename string,
job string,
mgr int,
hiredate DATE,
sal int,
comm int,
deptno int
)
partitioned BY(dt string,hour string)
row format delimited fields terminated by ","
stored as PARQUET;
加载数据
# 先将数据加载到emp_txt
load data inpath '/test/data' overwrite into table emp_txt partition(dt='2020-01-01',hour='01');
#再从emp_txt将数据加载到emp_parquet里面
insert overwrite table emp_parquet
select empno,ename,job,mgr,hiredate,sal,comm,deptno
from emp_txt where dt='2020-01-01' AND hour='01';
可以看到这里生成了两个文件,加起来5.52M,可见大大的将原始的txt进行了压缩

下面我们使用parquet加lzo的方式,来看看数据的压缩情况
CREATE TABLE emp_parquet_lzo (
empno int,
ename string,
job string,
mgr int,
hiredate DATE,
sal int,
comm int,
deptno int
)
partitioned by (dt string,hour string)
row format delimited fields terminated by ","
stored as PARQUET
tblproperties('parquet.compression'='lzo');
加载数据到emp_parquet_lzo
insert overwrite table emp_parquet_lzo partition (dt='2020-01-01',hour='01')
select empno,ename,job,mgr,hiredate,sal,comm,deptno
from emp_txt where dt='2020-01-01' AND hour='01';
数据相比较于仅仅使用parquet,数据被进一步的压缩了。但是这里提醒一下,是不是说pzrquet加lzo可以把数据压缩到这个地步,因为我的测试数据存在大量重复。

综上总结
txt文本文件,在使用parquet加压缩格式,相比较于仅仅使用parquet,可以更进一步的将数据压缩。
拓展
1.parquet压缩格式
parquet格式支持有四种压缩,分别是lzo,gzip,snappy,uncompressed,在数据量不大的情况下,四种压缩的区别也不是太大。
2.hive的分区是支持层级分区
也就是分区下面还可以有分区的,如上面的 partitioned by (dt string,hour string) 在插入数据的时候使用逗号分隔,partition(dt='2020-01-01',hour='01')
3.本次测试中,一个74M的文件,使用在insert overwrite ... select 之后,为什么会产生两个文件
首先要声明一下,我的hive使用的执行引擎是tez,替换了默认的mapreduce执行引擎。
我们看一下执行页面,这里可以看到形成了两个map,这里是map-only,一般数据的加载操作都是map-only的,所以,有多少的map,就会产生几个文件。
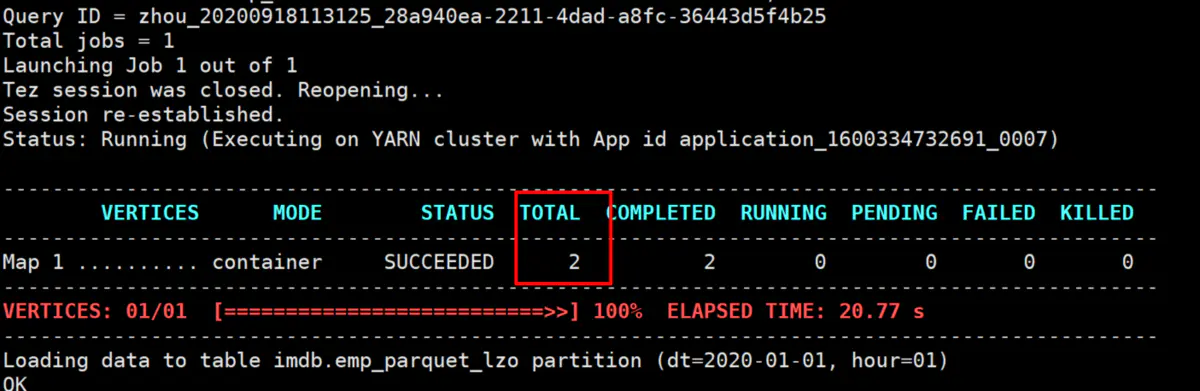
从图片可以看出,这里是tez把74M的文件分成了两个,这里的52428800是50M,也就是这里的splitsize不是hadoop的mr的默认的128M,而是这里的50M,所以,74M的文件会被分为两个,一个是50M,一个是24M,.然后我们看上面的emp_parquet的文件,一个式3.7M,也是1.8M,正好和50M和24M的比例是对应的。
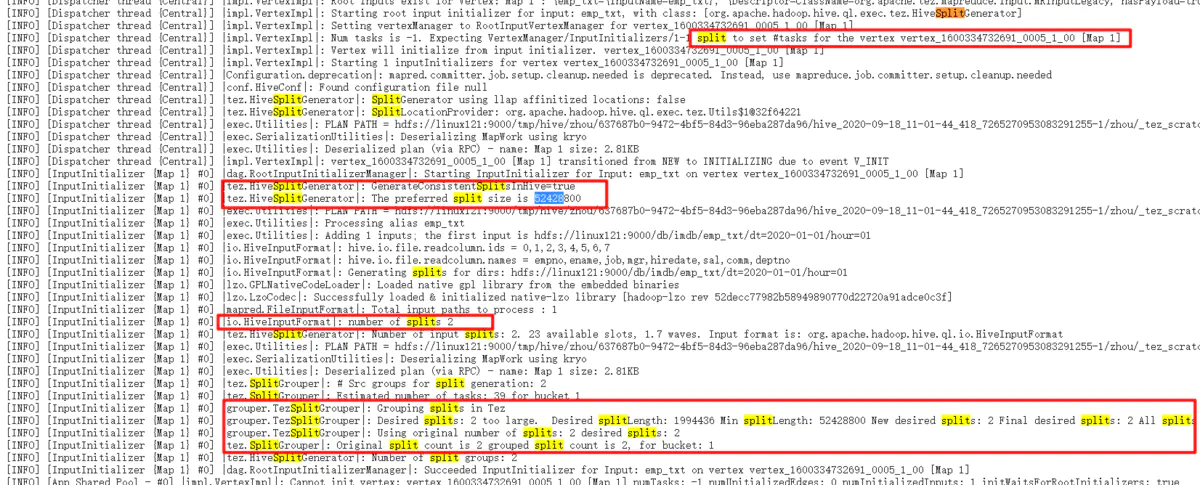
所以,一切事情都是有原因的,这里的splitsize是50M,才会导致形成两个文件的。但是我没有找到这哥tez的splitsize的具体配置是什么,以后找到的话,再进行补充。
parquet列存储本身自带压缩 配合snappy或者lzo等可以进行二次压缩的更多相关文章
- 万亿级日志与行为数据存储查询技术剖析——Hbase系预聚合方案、Dremel系parquet列存储、预聚合系、Lucene系
转自:http://www.infoq.com/cn/articles/trillion-log-and-data-storage-query-techniques?utm_source=infoq& ...
- 【转】深入分析 Parquet 列式存储格式
Parquet 是面向分析型业务的列式存储格式,由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 的孵化器里毕业成为 Apache 顶级项目,最新的版本是 1. ...
- 深入分析Parquet列式存储格式【转】
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- Parquet列式存储格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- 深入分析Parquet列式存储格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目,最新的版本是1.8.0. 列式存储 列式存 ...
- 从NSM到Parquet:存储结构的衍化
http://blog.csdn.net/dc_726/article/details/41777661 为了优化MapReduce及MR之前的各种工具的性能,在Hadoop内建的数据存储格式外,又涌 ...
- Vertica: 基于DBMS架构的列存储数据仓库
介绍 Vertica(属于HP公司),是一个基于DBMS架构的数据库系统,适合读密集的分析型数据库应用,比方数据仓库,白皮书中全名称为VerticaAnalytic Database.从命名中也可以看 ...
- SQL Server 2014新特性探秘(3)-可更新列存储聚集索引
简介 列存储索引其实在在SQL Server 2012中就已经存在,但SQL Server 2012中只允许建立非聚集列索引,这意味着列索引是在原有的行存储索引之上的引用了底层的数据,因此会 ...
- Druid(准)实时分析统计数据库——列存储+高效压缩
Druid是一个开源的.分布式的.列存储系统,特别适用于大数据上的(准)实时分析统计.且具有较好的稳定性(Highly Available). 其相对比较轻量级,文档非常完善,也比较容易上手. Dru ...
随机推荐
- 多线程-停止线程方式-Interrupt
1 package multithread4; 2 /* 3 * 停止线程: 4 * 1,stop方法. 5 * 6 * 2,run方法结束. 7 * 8 * 怎么控制线程的任务结束呢? 9 * 任务 ...
- SP419/422 TRANSP(2) - Transposing is Fun
首先可以发现转置本质上就是一个置换,问题就转化为求一个排列排成有序的最少次数. 这是一个经典问题,答案为点数减循环置换的个数,考虑如何求循环置换. 发现有两个特殊性质:置换为转置,矩阵的边长为 \(2 ...
- SimpleDateFormat简介及替代方案
简介 SimpleDateFormat是一个时间格式化工具,可以将字符串格式化时间Date类型,也可以将Date类型格式化为字符串String类型,但其线程不安全. 常用方法 public final ...
- Spring @Cacheable 缓存不生效的问题
最近在项目中使用了Ehcache缓存,使用方式是用Spring提供的 @Cacheable 注解的方式,这种方式简单.快速.方便,推荐使用. 在使用的过程中,遇到了缓存不生效的情况,经过分析处理,总结 ...
- bom案例3-放大镜
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- mysql处理警告 Warning: Using a password on the command line interface can be insecure.
vim /etc/mysql/my.cnf [mysqldump] user=user_name password=password 格式: [只用密码的命令] user=用户名 password=密 ...
- 项目架构(结构)搭建:主流结构(UITabBarController + 导航控制器)
/* 项目架构(结构)搭建:主流结构(UITabBarController + 导航控制器) -> 项目开发方式 1.storyboard 2.纯代码 */ @interface AppDele ...
- 基于Java的简单银行管理系统(MVC设计模式)
项目导航 功能展示 项目描述 项目结构 `data` `service` `utils` `view ` 欠缺与总结 源码下载 功能展示 本系统基于命令台窗口,暂未与图形页面结合.话不多说,先上效果图 ...
- ansible-playbook实现MySQL的二进制部署
1.ansible服务器配置 1.1 安装ansible # yum -y install ansible 1.2 配置主机清单文件 # vi /etc/ansible/hosts [local] 1 ...
- 基于FMC接口的Kintex-7 XC7K325T PCIeX4 3U PXIe接口卡
一.板卡概述 本板卡基于Xilinx公司的FPGAXC7K325T-2FFG900 芯片,pin_to_pin兼容FPGAXC7K410T-2FFG900 ,支持PCIeX8.64bit DDR3容量 ...