innodb和myisam对比及索引原理区别
InnoDB和MyISAM是很多人在使用MySQL时最常用的两个表类型,这两个表类型各有优劣,5.7之后就不一样了
1、事务和外键
InnoDB具有事务,支持4个事务隔离级别,回滚,崩溃修复能力和多版本并发的事务安全,包括ACID。如果应用中需要执行大量的INSERT或UPDATE操作,则应该使用InnoDB,这样可以提高多用户并发操作的性能
MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。如果应用中需要执行大量的SELECT查询,那么MyISAM是更好的选择
2、全文索引
Innodb不支持全文索引,如果一定要用的话,最好使用sphinx等搜索引擎。myisam对中文支持的不是很好
不过新版本的Innodb已经支持了
3、锁
mysql支持三种锁定级别,行级、页级、表级;
MyISAM支持表级锁定,提供与 Oracle 类型一致的不加锁读取(non-locking read in SELECTs)
InnoDB支持行级锁,InnoDB表的行锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表,注意间隙锁的影响
例如update table set num=1 where name like “%aaa%”
4、存储
MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型, .frm文件存储表定义,数据文件的扩展名为.MYD, 索引文件的扩展名是.MYI
InnoDB,基于磁盘的资源是InnoDB表空间数据文件和它的日志文件,InnoDB 表的大小只受限于操作系统文件的大小
注意:MyISAM表是保存成文件的形式,在跨平台的数据转移中使用MyISAM存储会省去不少的麻烦
5、索引
InnoDB(索引组织表)使用的聚簇索引、索引就是数据,顺序存储,因此能缓存索引,也能缓存数据
MyISAM(堆组织表)使用的是非聚簇索引、索引和文件分开,随机存储,只能缓存索引
6、并发
MyISAM读写互相阻塞:不仅会在写入的时候阻塞读取,MyISAM还会在读取的时候阻塞写入,但读本身并不会阻塞另外的读
InnoDB 读写阻塞与事务隔离级别相关
7、场景选择
MyISAM
- 不需要事务支持(不支持)
- 并发相对较低(锁定机制问题)
- 数据修改相对较少(阻塞问题),以读为主
- 数据一致性要求不是非常高
- 尽量索引(缓存机制)
- 调整读写优先级,根据实际需求确保重要操作更优先
- 启用延迟插入改善大批量写入性能
- 尽量顺序操作让insert数据都写入到尾部,减少阻塞
- 分解大的操作,降低单个操作的阻塞时间
- 降低并发数,某些高并发场景通过应用来进行排队机制
- 对于相对静态的数据,充分利用Query Cache可以极大的提高访问效率
- MyISAM的Count只有在全表扫描的时候特别高效,带有其他条件的count都需要进行实际的数据访问
InnoDB
- 需要事务支持(具有较好的事务特性)
- 行级锁定对高并发有很好的适应能力,但需要确保查询是通过索引完成
- 数据更新较为频繁的场景
- 数据一致性要求较高
- 硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存利用率,尽可能减少磁盘 IO
- 主键尽可能小,避免给Secondary index带来过大的空间负担
- 避免全表扫描,因为会使用表锁
- 尽可能缓存所有的索引和数据,提高响应速度
- 在大批量小插入的时候,尽量自己控制事务而不要使用autocommit自动提交
- 合理设置innodb_flush_log_at_trx_commit参数值,不要过度追求安全性
- 避免主键更新,因为这会带来大量的数据移动
8、其它细节
1)InnoDB 中不保存表的具体行数,注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的
2)对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引, 如果你为一个表指定AUTO_INCREMENT列,在数据词典里的InnoDB表句柄包含一个名为自动增长计数器的计数器,它被用在为该列赋新值。自动增长计数器仅被存储在主内存中,而不是存在磁盘
3)DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除
4)LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用
5)如果执行大量的SELECT,MyISAM是更好的选择,如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表
7、为什么MyISAM会比Innodb 的查询速度快
InnoDB 在做SELECT的时候,要维护的东西比MYISAM引擎多很多;
1)InnoDB 要缓存数据和索引,MyISAM只缓存索引块,这中间还有换进换出的减少
2)innodb寻址要映射到块,再到行,MyISAM记录的直接是文件的OFFSET,定位比INNODB要快
3)InnoDB 还需要维护MVCC一致;虽然你的场景没有,但他还是需要去检查和维护
MVCC ( Multi-Version Concurrency Control )多版本并发控制
InnoDB :通过为每一行记录添加两个额外的隐藏的值来实现MVCC,这两个值一个记录这行数据何时被创建,另外一个记录这行数据何时过期(或者被删除)。但是InnoDB并不存储这些事件发生时的实际时间,相反它只存储这些事件发生时的系统版本号。这是一个随着事务的创建而不断增长的数字。每个事务在事务开始时会记录它自己的系统版本号。每个查询必须去检查每行数据的版本号与事务的版本号是否相同。让我们来看看当隔离级别是REPEATABLE READ时这种策略是如何应用到特定的操作的
SELECT InnoDB必须每行数据来保证它符合两个条件
1、InnoDB必须找到一个行的版本,它至少要和事务的版本一样老(也即它的版本号不大于事务的版本号)。这保证了不管是事务开始之前,或者事务创建时,或者修改了这行数据的时候,这行数据是存在的。
2、这行数据的删除版本必须是未定义的或者比事务版本要大。这可以保证在事务开始之前这行数据没有被删除。
8、mysql性能讨论
MyISAM最为人垢病的缺点就是缺乏事务的支持
InnoDB 的磁盘性能很令人担心
MySQL 缺乏良好的 tablespace
两种类型最主要的差别就是Innodb 支持事务处理与外键和行级锁.而MyISAM不支持.所以MyISAM往往就容易被人认为只适合在小项目中使用。
我作为使用MySQL的用户角度出发,Innodb和MyISAM都是比较喜欢的,但是从我目前运维的数据库平台要达到需求:99.9%的稳定性,方便的扩展性和高可用性来说的话,MyISAM绝对是我的首选。
原因如下:
1、首先我目前平台上承载的大部分项目是读多写少的项目,而MyISAM的读性能是比Innodb强不少的。
2、MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引,而Innodb是索引和数据是紧密捆绑的,没有使用压缩从而会造成Innodb比MyISAM体积庞大不小。
3、从平台角度来说,经常隔1,2个月就会发生应用开发人员不小心update一个表where写的范围不对,导致这个表没法正常用了,这个时候MyISAM的优越性就体现出来了,随便从当天拷贝的压缩包取出对应表的文件,随便放到一个数据库目录下,然后dump成sql再导回到主库,并把对应的binlog补上。如果是Innodb,恐怕不可能有这么快速度,别和我说让Innodb定期用导出xxx.sql机制备份,因为我平台上最小的一个数据库实例的数据量基本都是几十G大小。
4、从我接触的应用逻辑来说,select count(*) 和order by 是最频繁的,大概能占了整个sql总语句的60%以上的操作,而这种操作Innodb其实也是会锁表的,很多人以为Innodb是行级锁,那个只是where对它主键是有效,非主键的都会锁全表的。
5、还有就是经常有很多应用部门需要我给他们定期某些表的数据,MyISAM的话很方便,只要发给他们对应那表的frm.MYD,MYI的文件,让他们自己在对应版本的数据库启动就行,而Innodb就需要导出xxx.sql了,因为光给别人文件,受字典数据文件的影响,对方是无法使用的。
6、如果和MyISAM比insert写操作的话,Innodb还达不到MyISAM的写性能,如果是针对基于索引的update操作,虽然MyISAM可能会逊色Innodb,但是那么高并发的写,从库能否追的上也是一个问题,还不如通过多实例分库分表架构来解决。
7、如果是用MyISAM的话,merge引擎可以大大加快应用部门的开发速度,他们只要对这个merge表做一些select count(*)操作,非常适合大项目总量约几亿的rows某一类型(如日志,调查统计)的业务表。
当然Innodb也不是绝对不用,用事务的项目如模拟炒股项目,我就是用Innodb的,活跃用户20多万时候,也是很轻松应付了,因此我个人也是很喜欢Innodb的,只是如果从数据库平台应用出发,我还是会首选MyISAM。
另外,可能有人会说你MyISAM无法抗太多写操作,但是我可以通过架构来弥补,说个我现有用的数据库平台容量:主从数据总量在几百T以上,每天十多亿 pv的动态页面,还有几个大项目是通过数据接口方式调用未算进pv总数,(其中包括一个大项目因为初期memcached没部署,导致单台数据库每天处理 9千万的查询)。而我的整体数据库服务器平均负载都在0.5-1左右。
MyISAM索引实现
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。如图:
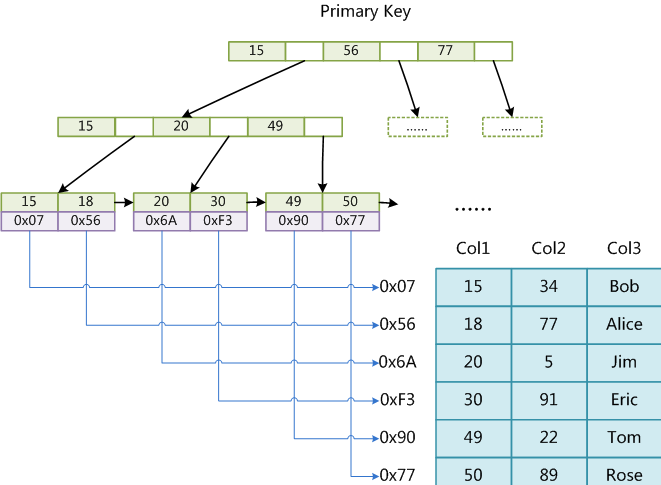
这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
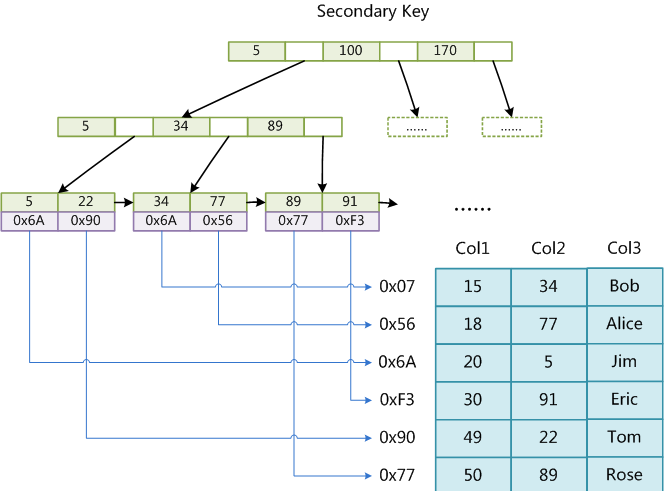
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
InnoDB索引实现
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
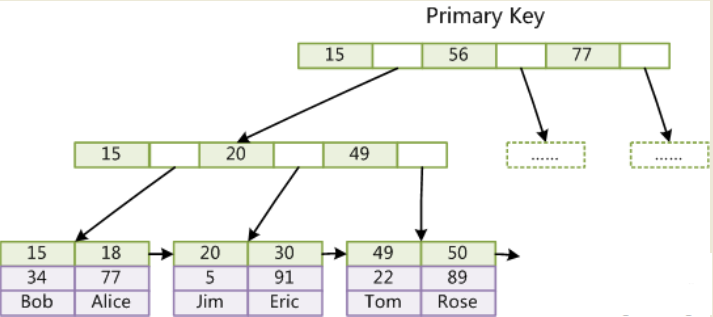
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
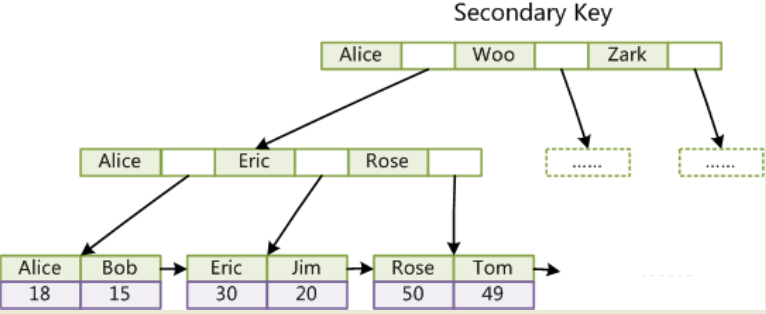
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
总结
在数据库开发中,了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助。例如,知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好做法,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
innodb和myisam对比及索引原理区别的更多相关文章
- 警惕 InnoDB 和 MyISAM 创建 Hash 索引陷阱
MySql 最经常使用存储引擎 InnoDB 和 MyISAM 都不支持 Hash 索引,它们默认的索引都是 B-Tree.可是假设你在创建索引的时候定义其类型为 Hash,MySql 并不会报错,并 ...
- innodb和myisam对比
MyISAM特点 1)不支持行锁(MyISAM只有表锁),读取时对需要读到的所有表加锁,写入时则对表加排他锁: 2)不支持事务 3)不支持外键 4)不支持崩溃后的安全恢复 5)在表有读取查询的同时,支 ...
- MySQL存储引擎Innodb和MyISAM对比总结
Innodb引擎 InnoDB是一个事务型的存储引擎,设计目标是处理大数量数据时提供高性能的服务,它在运行时会在内存中建立缓冲池,用于缓冲数据和索引. Innodb引擎优点 1.支持事务处理.ACID ...
- (转)InnoDB与MyISAM引擎区别
MyISAM与InnoDB两者之间区别与选择,详细总结,性能对比 2015年06月25日 21:58:42 阅读数:1827更多 个人分类: mysql 1.MyISAM:默认表类型,它是基于传统 ...
- INNODB与MyISAM两种表存储引擎区别
mysql数据库分类为INNODB为MyISAM两种表存储引擎了,两种各有优化在不同类型网站可能选择不同,下面小编为各位介绍mysql更改表引擎INNODB为MyISAM技巧. 常见的mysql表引擎 ...
- MySQL存储引擎:InnoDB和MyISAM的差别/优劣评价/评测/性能测试
InnoDB和MyISAM简介 MyISAM:这个是默认类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的 顺序访问方法) 的缩写 ...
- innodb和myisam数据库文件存储详解以及mysql表空间
数据库常用的两种引擎有Innodb和Myisam,关于二者的区别参考:https://www.cnblogs.com/qlqwjy/p/7965460.html 1.关于数据库的存储在两种引擎的存储是 ...
- 数据库(11)-- Hash索引和BTree索引 的区别
索引是帮助mysql获取数据的数据结构.最常见的索引是Btree索引和Hash索引. 不同的引擎对于索引有不同的支持:Innodb和MyISAM默认的索引是Btree索引:而Mermory默认的索引是 ...
- Mysql表的七种引擎类型,InnoDB和MyISAM引擎对比区别总结
InnoDB和MyISAM区别总结 我用MySQL的时候用的是Navicat for MySQL(Navicat for mysql v9.0.15注册码生成器)操作库.表操作的,默认的表就是Inno ...
随机推荐
- Mysql多实例搭建部署
[部署背景] 公司测试环境需求多个数据库实例,但是只分配一台MySQL机器,所以进行多实例部署. [部署搭建] 创建软件包路径 mkdir /data/soft/package /dat ...
- go的常用数据类型-持续优化篇
p.p1 { margin: 0; font: 12px "Helvetica Neue"; color: rgba(69, 69, 69, 1) } p.p2 { margin: ...
- silky微服务业务主机简介
目录 主机的概念 通用主机 web主机 业务主机类型 使用web主机构建微服务应用 使用通用主机构建微服务应用 构建具有websocket能力的微服务应用 构建网关 开源地址 在线文档 主机的概念 s ...
- 菜鸡的Java笔记 第十四 String 类常用方法
/*String 类常用方法 将所有String类的常用方法全部记下来,包括方法名称,参数作用以及类型 一个成熟的编程语言,除了它的语法非常完善之外,那么也需要提供有大量的开发类库 ...
- 麒麟Linux上编译subversion
麒麟Linux上编译subversion svn-1.7不支持svn info --show-item=revision[1]获取revision. svn-1.12开始不能保存密码stackover ...
- [hdu6588]Function
令$m=\lfloor \sqrt[3]{n} \rfloor-1$ $\sum_{i=1}^{n}gcd(floor(\sqrt[3]{i}),i)$=$\sum_{i=1}^{m}\sum ...
- [bzoj1305]跳舞
考虑如果没有k个人,那么就是裸的二分答案+最大流对于这k个人,再在原来的每一个点裂点,中间的流量为k,然后裂出来的点向所有不能匹配的点连边,再二分答案+最大流即可 1 #include<bits ...
- 明明pip安装python的模块了,pycharm还是找不到的解决方案
以前pycharm的安装包和python的环境一直都不能融合在一起,到了今天才知道,原来他们都是有自己的工作环境的 自己的工作环境(虚拟解释器)和安装python的工作环境(基本解释器)不是一个环境, ...
- Java生产环境JVM设置成固定堆大小深层原理
可能很多人都知道Java程序上生产后,运维人员都会设定好JVM的堆大小,而且还是把最大最小设置成一样的值.那究竟是为什么呢?一般而言,Java程序如果你不显示设定该值得话,会自动进行初始化设定. -X ...
- x86汇编反编译到c语言之——(2)if语句
一. 测试的C语句及编译后的x86汇编代码 int a; int b; int main(void) { int c; if (c) a = 4; else b = 5; return 0; } 1 ...