精选Hive高频面试题11道,附答案详细解析(好文收藏)
1. hive内部表和外部表的区别
未被external修饰的是内部表,被external修饰的为外部表。
区别:
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是
hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
本文首发于公众号【五分钟学大数据】
2. Hive有索引吗
Hive支持索引(3.0版本之前),但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键。并且Hive索引提供的功能很有限,效率也并不高,因此Hive索引很少使用。
- 索引适用的场景:
适用于不更新的静态字段。以免总是重建索引数据。每次建立、更新数据后,都要重建索引以构建索引表。
- Hive索引的机制如下:
hive在指定列上建立索引,会产生一张索引表(Hive的一张物理表),里面的字段包括:索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量。
Hive 0.8版本后引入bitmap索引处理器,这个处理器适用于去重后,值较少的列(例如,某字段的取值只可能是几个枚举值)
因为索引是用空间换时间,索引列的取值过多会导致建立bitmap索引表过大。
注意:Hive中每次有数据时需要及时更新索引,相当于重建一个新表,否则会影响数据查询的效率和准确性,Hive官方文档已经明确表示Hive的索引不推荐被使用,在新版本的Hive中已经被废弃了。
扩展:Hive是在0.7版本之后支持索引的,在0.8版本后引入bitmap索引处理器,在3.0版本开始移除索引的功能,取而代之的是2.3版本开始的物化视图,自动重写的物化视图替代了索引的功能。
3. 运维如何对hive进行调度
将hive的sql定义在脚本当中;
使用azkaban或者oozie进行任务的调度;
监控任务调度页面。
4. ORC、Parquet等列式存储的优点
ORC和Parquet都是高性能的存储方式,这两种存储格式总会带来存储和性能上的提升。
Parquet:
Parquet支持嵌套的数据模型,类似于Protocol Buffers,每一个数据模型的schema包含多个字段,每一个字段有三个属性:重复次数、数据类型和字段名。
重复次数可以是以下三种:required(只出现1次),repeated(出现0次或多次),optional(出现0次或1次)。每一个字段的数据类型可以分成两种:
group(复杂类型)和primitive(基本类型)。Parquet中没有Map、Array这样的复杂数据结构,但是可以通过repeated和group组合来实现的。
由于Parquet支持的数据模型比较松散,可能一条记录中存在比较深的嵌套关系,如果为每一条记录都维护一个类似的树状结可能会占用较大的存储空间,因此Dremel论文中提出了一种高效的对于嵌套数据格式的压缩算法:Striping/Assembly算法。通过Striping/Assembly算法,parquet可以使用较少的存储空间表示复杂的嵌套格式,并且通常Repetition level和Definition level都是较小的整数值,可以通过RLE算法对其进行压缩,进一步降低存储空间。
Parquet文件是以二进制方式存储的,是不可以直接读取和修改的,Parquet文件是自解析的,文件中包括该文件的数据和元数据。
ORC:
ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗。
和Parquet类似,ORC文件也是以二进制方式存储的,所以是不可以直接读取,ORC文件也是自解析的,它包含许多的元数据,这些元数据都是同构ProtoBuffer进行序列化的。
ORC会尽可能合并多个离散的区间尽可能的减少I/O次数。
ORC中使用了更加精确的索引信息,使得在读取数据时可以指定从任意一行开始读取,更细粒度的统计信息使得读取ORC文件跳过整个row group,ORC默认会对任何一块数据和索引信息使用ZLIB压缩,因此ORC文件占用的存储空间也更小。
在新版本的ORC中也加入了对Bloom Filter的支持,它可以进一
步提升谓词下推的效率,在Hive 1.2.0版本以后也加入了对此的支
持。
5. 数据建模用的哪些模型?
1. 星型模型
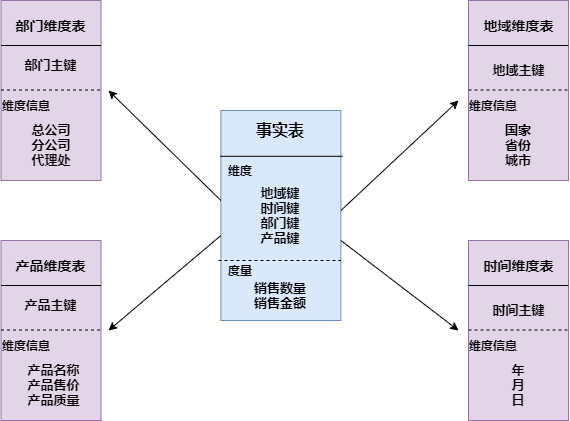
星形模式(Star Schema)是最常用的维度建模方式。星型模式是以事实表为中心,所有的维度表直接连接在事实表上,像星星一样。
星形模式的维度建模由一个事实表和一组维表成,且具有以下特点:
a. 维表只和事实表关联,维表之间没有关联;
b. 每个维表主键为单列,且该主键放置在事实表中,作为两边连接的外键;
c. 以事实表为核心,维表围绕核心呈星形分布。
2. 雪花模型
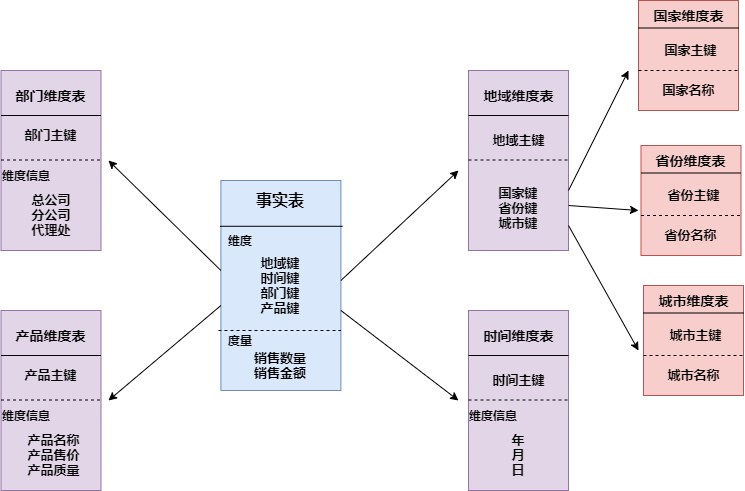
雪花模式(Snowflake Schema)是对星形模式的扩展。雪花模式的维度表可以拥有其他维度表的,虽然这种模型相比星型更规范一些,但是由于这种模型不太容易理解,维护成本比较高,而且性能方面需要关联多层维表,性能比星型模型要低。
3. 星座模型
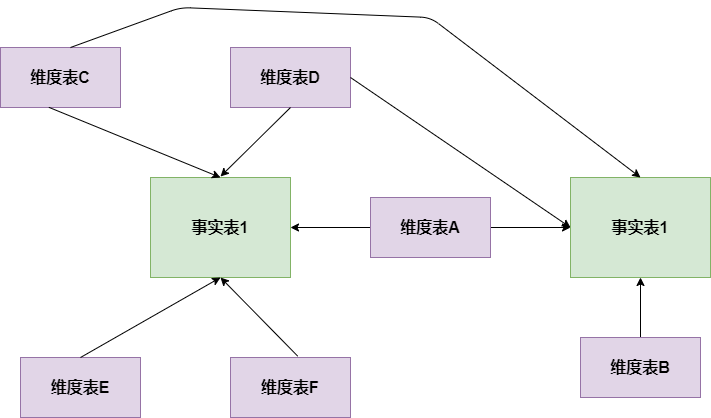
星座模式是星型模式延伸而来,星型模式是基于一张事实表的,而星座模式是基于多张事实表的,而且共享维度信息。前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。在业务发展后期,绝大部分维度建模都采用的是星座模式。
数仓建模详细介绍可查看:通俗易懂数仓建模
6. 为什么要对数据仓库分层?
用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据。
如果不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。
通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
数据仓库详细介绍可查看:万字详解整个数据仓库建设体系
7. 使用过Hive解析JSON串吗
Hive处理json数据总体来说有两个方向的路走:
将json以字符串的方式整个入Hive表,然后通过使用UDF函数解析已经导入到hive中的数据,比如使用
LATERAL VIEW json_tuple的方法,获取所需要的列名。在导入之前将json拆成各个字段,导入Hive表的数据是已经解析过的。这将需要使用第三方的
SerDe。
详细介绍可查看:Hive解析Json数组超全讲解
8. sort by 和 order by 的区别
order by 会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序)只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
sort by不是全局排序,其在数据进入reducer前完成排序.
因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1, 则sort by只保证每个reducer的输出有序,不保证全局有序。
9. 数据倾斜怎么解决
数据倾斜问题主要有以下几种:
空值引发的数据倾斜
不同数据类型引发的数据倾斜
不可拆分大文件引发的数据倾斜
数据膨胀引发的数据倾斜
表连接时引发的数据倾斜
确实无法减少数据量引发的数据倾斜
以上倾斜问题的具体解决方案可查看:Hive千亿级数据倾斜解决方案
注意:对于 left join 或者 right join 来说,不会对关联的字段自动去除null值,对于 inner join 来说,会对关联的字段自动去除null值。
小伙伴们在阅读时注意下,在上面的文章(Hive千亿级数据倾斜解决方案)中,有一处sql出现了上述问题(举例的时候原本是想使用left join的,结果手误写成了join)。此问题由公众号读者发现,感谢这位读者指正。
10. Hive 小文件过多怎么解决
1. 使用 hive 自带的 concatenate 命令,自动合并小文件
使用方法:
#对于非分区表
alter table A concatenate;
#对于分区表
alter table B partition(day=20201224) concatenate;
注意:
1、concatenate 命令只支持 RCFILE 和 ORC 文件类型。
2、使用concatenate命令合并小文件时不能指定合并后的文件数量,但可以多次执行该命令。
3、当多次使用concatenate后文件数量不在变化,这个跟参数 mapreduce.input.fileinputformat.split.minsize=256mb 的设置有关,可设定每个文件的最小size。
2. 调整参数减少Map数量
设置map输入合并小文件的相关参数(执行Map前进行小文件合并):
在mapper中将多个文件合成一个split作为输入(CombineHiveInputFormat底层是Hadoop的CombineFileInputFormat方法):
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 默认
每个Map最大输入大小(这个值决定了合并后文件的数量):
set mapred.max.split.size=256000000; -- 256M
一个节点上split的至少大小(这个值决定了多个DataNode上的文件是否需要合并):
set mapred.min.split.size.per.node=100000000; -- 100M
一个交换机下split的至少大小(这个值决定了多个交换机上的文件是否需要合并):
set mapred.min.split.size.per.rack=100000000; -- 100M
3. 减少Reduce的数量
reduce 的个数决定了输出的文件的个数,所以可以调整reduce的个数控制hive表的文件数量。
hive中的分区函数 distribute by 正好是控制MR中partition分区的,可以通过设置reduce的数量,结合分区函数让数据均衡的进入每个reduce即可:
#设置reduce的数量有两种方式,第一种是直接设置reduce个数
set mapreduce.job.reduces=10;
#第二种是设置每个reduce的大小,Hive会根据数据总大小猜测确定一个reduce个数
set hive.exec.reducers.bytes.per.reducer=5120000000; -- 默认是1G,设置为5G
#执行以下语句,将数据均衡的分配到reduce中
set mapreduce.job.reduces=10;
insert overwrite table A partition(dt)
select * from B
distribute by rand();
对于上述语句解释:如设置reduce数量为10,使用 rand(), 随机生成一个数 x % 10 ,
这样数据就会随机进入 reduce 中,防止出现有的文件过大或过小。
4. 使用hadoop的archive将小文件归档
Hadoop Archive简称HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。
#用来控制归档是否可用
set hive.archive.enabled=true;
#通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;
#控制需要归档文件的大小
set har.partfile.size=1099511627776;
使用以下命令进行归档:
ALTER TABLE A ARCHIVE PARTITION(dt='2021-05-07', hr='12');
对已归档的分区恢复为原文件:
ALTER TABLE A UNARCHIVE PARTITION(dt='2021-05-07', hr='12');
注意:
归档的分区可以查看不能 insert overwrite,必须先 unarchive
Hive 小文件问题具体可查看:解决hive小文件过多问题
11. Hive优化有哪些
1. 数据存储及压缩:
针对hive中表的存储格式通常有orc和parquet,压缩格式一般使用snappy。相比与textfile格式表,orc占有更少的存储。因为hive底层使用MR计算架构,数据流是hdfs到磁盘再到hdfs,而且会有很多次,所以使用orc数据格式和snappy压缩策略可以降低IO读写,还能降低网络传输量,这样在一定程度上可以节省存储,还能提升hql任务执行效率;
2. 通过调参优化:
并行执行,调节parallel参数;
调节jvm参数,重用jvm;
设置map、reduce的参数;开启strict mode模式;
关闭推测执行设置。
3. 有效地减小数据集将大表拆分成子表;结合使用外部表和分区表。
4. SQL优化
大表对大表:尽量减少数据集,可以通过分区表,避免扫描全表或者全字段;
大表对小表:设置自动识别小表,将小表放入内存中去执行。
Hive优化详细剖析可查看:Hive企业级性能优化
--END--
精选Hive高频面试题11道,附答案详细解析(好文收藏)的更多相关文章
- 面试系列二:精选大数据面试真题JVM专项-附答案详细解析
公众号(五分钟学大数据)已推出大数据面试系列文章-五分钟小面试,此系列文章将会深入研究各大厂笔面试真题,并根据笔面试题扩展相关的知识点,助力大家都能够成功入职大厂! 大数据笔面试系列文章分为两种类型: ...
- 2017常见的50道java基础面试题整理(附答案)
1.作用域public,private,protected,以及不写时的区别 答: 区别如下: 2.Anonymous Inner Class (匿名内部类) 是否可以extends(继承)其它类,是 ...
- 2019年JVM面试都问了什么?快看看这22道面试题!(附答案解析)
一. Java 类加载过程? Java 类加载需要经历一下 7 个过程: 1. 加载 加载是类加载的第一个过程,在这个阶段,将完成一下三件事情: • 通过一个类的全限定名获取该类的二进制流. • 将该 ...
- 总结2020最新50道Python面试题集锦(附答案)
Python是目前编程领域最受欢迎的语言.在本文中,我将总结Python面试中最常见的50个问题.每道题都提供参考答案,希望能够帮助你在2019年求职面试中脱颖而出,找到一份高薪工作.这些面试题涉及P ...
- Java高频面试题70道
1.作用域public,private,protected,以及不写时的区别? 答:区别如下: 作用域 当前类 同一packag 子孙类 其他package public √ √ √ √ prote ...
- 给你准备好了——50道Python面试题集锦(附答案)
Python是目前编程领域最受欢迎的语言.在本文中,我将总结Python面试中最常见的50个问题.每道题都提供参考答案,希望能够帮助你在2019年求职面试中脱颖而出,找到一份高薪工作.这些面试题涉及P ...
- 2019 最新 阿里天猫、蚂蚁、钉钉ava 面试题汇总,附答案
Java面试前需要做足各方面的准备工作,肯定都会浏览大量的面试题,本人也不例外,这是一些最新面试题,分享给大家. Java基础 面向对象的特征:继承.封装和多态 int 和 Integer 有什么区别 ...
- 纯干货分享!2020阿里java岗笔试面试题总结(附答案)
前言 2020金九银十马上结束,现为大家整理了这次金九银十面试阿里的面试题总结,都是我从朋友那拿到的面试真题,话不多说,满满的干货分享给大家! int a=10是原子操作吗? 是的. 注意点: i+ ...
- Mybatis常考面试题汇总(附答案)
1.#{}和${}的区别是什么? #{}和${}的区别是什么? 在Mybatis中,有两种占位符 #{}解析传递进来的参数数据 ${}对传递进来的参数原样拼接在SQL中 #{}是预编译处理,${}是字 ...
随机推荐
- Dart 学习
语言特性 Dart所有的东西都是对象, 即使是数字numbers.函数function.null也都是对象,所有的对象都继承自Object类. Dart动态类型语言, 尽量给变量定义一个类型,会更安全 ...
- .Net5 下Dictionary 为什么可以在foreach中Remove
在一个讨论群里,看见有人说Dictionary可以在foreach中直接调用Remove了,带着疑问,写了简单代码进行尝试 class Program { static void Main(strin ...
- 在Python中创建M x N的数组
在Python中创建M x N的数组 一般有三种方法: 列表乘法 dp = [[0] * n] * m for 循环 dp= [[0 for _ in range(n)] for _ in range ...
- [源码解析] 并行分布式框架 Celery 之架构 (2)
[源码解析] 并行分布式框架 Celery 之架构 (2) 目录 [源码解析] 并行分布式框架 Celery 之架构 (2) 0x00 摘要 0x01 上文回顾 0x02 worker的思考 2.1 ...
- PAT (Basic Level) Practice (中文)1078 字符串压缩与解压 (20 分) 凌宸1642
PAT (Basic Level) Practice (中文)1078 字符串压缩与解压 (20 分) 凌宸1642 题目描述: 文本压缩有很多种方法,这里我们只考虑最简单的一种:把由相同字符组成的一 ...
- jenkins构建maven聚合项目,发布jar包,可配置单独发布某个模块
https://blog.csdn.net/qq_42703181/article/details/109643330
- OO第四单元作业总结以及课程总结
第四单元总结--UML 第四单元作业架构分析 第一次作业其实是本单元三次作业中最难的一次.由于第一次是第一次作业,要考虑到搭建框架和设计架构,这次作业的思维性很强.在了解了各个类型元素(Element ...
- 深入了解springcloud gateway 的限流重试机制
前言 前面给大家介绍了Spring Cloud Gateway的入门教程,这篇给大家探讨下Spring Cloud Gateway的一些其他功能. Spring Cloud Gateway中的重试 我 ...
- 「starter推荐」简单高效Excel 导出工具
EasyExcel EasyExcel是一个基于Java的简单.省内存的读写Excel的开源项目.在尽可能节约内存的情况下支持读写百M的Excel. 64M内存1分钟内读取75M(46W行25列)的E ...
- day-7 xctf-level2
xctf-level2 题目传送门:https://adworld.xctf.org.cn/task/answer?type=pwn&number=2&grade=0&id=5 ...