hive学习笔记之三:内部表和外部表
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
《hive学习笔记》系列导航
本篇概览
- 本文是《hive学习笔记》系列的第三篇,要学习的是各种类型的表及其特点,主要内容如下:
- 建库
- 内部表(也叫管理表或临时表)
- 外部表
- 表的操作
接下来从最基本的建库开始
建库
- 创建名为test的数据库(仅当不存在时才创建),添加备注信息test database:
create database if not exists test
comment 'this is a database for test';
- 查看数据库列表(名称模糊匹配):
hive> show databases like 't*';
OK
test
test001
Time taken: 0.016 seconds, Fetched: 2 row(s)
- describe database命令查看此数据库信息:
hive> describe database test;
OK
test this is a database for test hdfs://node0:8020/user/hive/warehouse/test.db hadoop USER
Time taken: 0.035 seconds, Fetched: 1 row(s)
- 上述命令可见,test数据库在hdfs上的存储位置是hdfs://node0:8020/user/hive/warehouse/test.db,打开hadoop的web页面,查看hdfs目录,如下图,该路径的文件夹已经创建,并且是以.db结尾的:
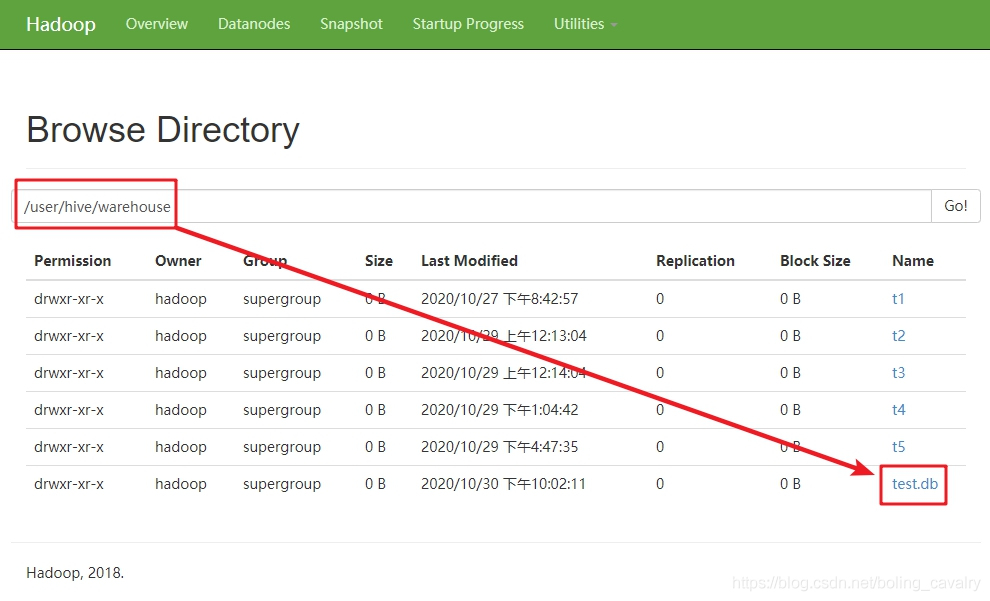
5. 新建数据库的文件夹都在/user/hive/warehouse下面,这是在中配置的,如下图红框:

6. 删除数据库,加上if exists,当数据库不存在时,执行该语句不会返回Error:
hive> drop database if exists test;
OK
Time taken: 0.193 seconds
以上就是常用的库相关操作,接下来实践表相关操作;
内部表
- 按照表数据的生命周期,可以将表分为内部表和外部表两类;
- 内部表也叫管理表或临时表,该类型表的生命周期时由hive控制的,默认情况下数据都存放在/user/hive/warehouse/下面;
- 删除表时数据会被删除;
- 以下命令创建的就是内部表,可见前面两篇文章中创建的表都是内部表:
create table t6(id int, name string)
row format delimited
fields terminated by ',';
- 向t6表新增一条记录:
insert into t6 values (101, 'a101');
- 使用hadoop命令查看hdfs,可见t6表有对应的文件夹,里面的文件保存着该表数据:
[hadoop@node0 bin]$ ./hadoop fs -ls /user/hive/warehouse/t6
Found 1 items
-rwxr-xr-x 3 hadoop supergroup 9 2020-10-31 11:14 /user/hive/warehouse/t6/000000_0
- 查看这个000000_0文件的内容,如下可见,就是表内的数据:
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t6/000000_0
101 a101
- 执行命令drop table t6;删除t6表,再次查看t6表对应的文件,发现整个文件夹都不存在了:
[hadoop@node0 bin]$ ./hadoop fs -ls /user/hive/warehouse/
Found 5 items
drwxr-xr-x - hadoop supergroup 0 2020-10-27 20:42 /user/hive/warehouse/t1
drwxr-xr-x - hadoop supergroup 0 2020-10-29 00:13 /user/hive/warehouse/t2
drwxr-xr-x - hadoop supergroup 0 2020-10-29 00:14 /user/hive/warehouse/t3
drwxr-xr-x - hadoop supergroup 0 2020-10-29 13:04 /user/hive/warehouse/t4
drwxr-xr-x - hadoop supergroup 0 2020-10-29 16:47 /user/hive/warehouse/t5
外部表
- 创建表的SQL语句中加上external,创建的就是外部表了;
- 外部表的数据生命周期不受Hive控制;
- 删除外部表的时候不会删除数据;
- 外部表的数据,可以同时作为多个外部表的数据源共享使用;
- 接下来开始实践,下面是建表语句:
create external table t7(id int, name string)
row format delimited
fields terminated by ','
location '/data/external_t7';
- 查看hdfs文件,可见目录/data/external_t7/已经创建:
[hadoop@node0 bin]$ ./hadoop fs -ls /data/
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2020-10-31 12:02 /data/external_t7
- 新增一条记录:
insert into t7 values (107, 'a107');
- 在hdfs查看t7表对应的数据文件,可以见到新增的内容:
[hadoop@node0 bin]$ ./hadoop fs -ls /data/external_t7
Found 1 items
-rwxr-xr-x 3 hadoop supergroup 9 2020-10-31 12:06 /data/external_t7/000000_0
[hadoop@node0 bin]$ ./hadoop fs -cat /data/external_t7/000000_0
107,a107
- 试试多个外部表共享数据的功能,执行以下语句再建个外部表,名为t8,对应的存储目录和t7是同一个:
create external table t8(id_t8 int, name_t8 string)
row format delimited
fields terminated by ','
location '/data/external_t7';
- 建好t8表后立即查看数据,发现和t7表一模一样,可见它们已经共享了数据:
hive> select * from t8;
OK
107 a107
Time taken: 0.068 seconds, Fetched: 1 row(s)
hive> select * from t7;
OK
107 a107
Time taken: 0.074 seconds, Fetched: 1 row(s)
- 接下来删除t7表,再看t8表是否还能查出数据,如下可见,数据没有被删除,可以继续使用:
hive> drop table t7;
OK
Time taken: 1.053 seconds
hive> select * from t8;
OK
107 a107
Time taken: 0.073 seconds, Fetched: 1 row(s)
- 把t8表也删掉,再去看数据文件,如下所示,依然存在:
[hadoop@node0 bin]$ ./hadoop fs -cat /data/external_t7/000000_0
107,a107
- 可见外部表的数据不会在删除表的时候被删除,因此,在实际生产业务系统开发中,外部表是我们主要应用的表类型;
表的操作
- 再次创建t8表:
create table t8(id int, name string)
row format delimited
fields terminated by ',';
- 修改表名:
alter table t8 rename to t8_1;
- 可见修改表名已经生效:
hive> alter table t8 rename to t8_1;
OK
Time taken: 0.473 seconds
hive> show tables;
OK
alltype
t1
t2
t3
t4
t5
t6
t8_1
values__tmp__table__1
values__tmp__table__2
Time taken: 0.029 seconds, Fetched: 10 row(s)
- 添加字段:
alter table t8_1 add columns(remark string);
查看表结构,可见已经生效:
hive> desc t8_1;
OK
id int
name string
remark string
Time taken: 0.217 seconds, Fetched: 3 row(s)
至此,咱们对内部表和外部表已经有了基本了解,接下来的文章学习另一种常见的表类:分区表;
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
hive学习笔记之三:内部表和外部表的更多相关文章
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- hive 内部表和外部表的区别和理解
1. 内部表 create table test (name string , age string) location '/input/table_data'; 注:hive默认创建的是内部表 此时 ...
- 【转】Hive内部表、外部表
hive内部表.外部表区别自不用说,可实际用的时候还是要小心. 1. 内部表: create table tt (name string , age string) location '/input/ ...
- hive内部表、外部表
hive内部表.外部表区别自不用说,可实际用的时候还是要小心. Hive的数据分为表数据和元数据,表数据是Hive中表格(table)具有的数据:而元数据是用来存储表的名字,表的列和分区及其属性,表的 ...
- hive 学习笔记——表的入门操作和命令
1.受控表(managed table)包括内部表.分区表.桶表: 1.1.分区表 创建分区表: create table banji(id INT,name STRING) partitioned ...
- 一起学Hive——创建内部表、外部表、分区表和分桶表及导入数据
Hive本身并不存储数据,而是将数据存储在Hadoop的HDFS中,表名对应HDFS中的目录/文件.根据数据的不同存储方式,将Hive表分为外部表.内部表.分区表和分桶表四种数据模型.每种数据模型各有 ...
- hive内部表、外部表、分区
hive内部表.外部表.分区 内部表(managed table) 默认创建的是内部表(managed table),存储位置在hive.metastore.warehouse.dir设置,默认位置是 ...
- Hive创建内部表、外部表
使用hive需要hive环境 启动Hive 进入HIVE_HOME/bin,启动hive ./hive 内部表 建表 hive> create table fz > (id int,nam ...
- hive 内部表与外部表的区别
hive 内部表: hive> create table soyo55(name STRING,addr STRING,money STRING) row format delimited fi ...
随机推荐
- Beta——事后分析
事后总结 NameNotFound 团队 项目 内容 北航-2020-软件工程(春季学期) 班级博客 要求 Beta事后分析 课程目标 通过团队合作完成一个软件项目的开发 会议截图 一.设想和目标 软 ...
- beta设计和计划
项目 内容 课程:北航-2020-春-软件工程 博客园班级博客 要求 Beta设计和计划 我们在这个课程的目标是 提升团队管理及合作能力,开发一项满意的工程项目 这个作业在哪个具体方面帮助我们实现目标 ...
- [在学习Django框架之前所需要了解的知识点]
[在学习Django框架之前所需要了解的知识点] Web框架本质 我们可以这样理解:所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端. 这样我们就可以自己实现 ...
- Java集合详解(三):HashMap原理解析
概述 本文是基于jdk8_271版本进行分析的. HashMap是Map集合中使用最多的.底层是基于数组+链表实现的,jdk8开始底层是基于数组+链表/红黑树实现的.HashMap也会动态扩容,与Ar ...
- 前端必读:Vue响应式系统大PK(下)
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 原文参考:https://www.sitepoint.com/vue-3-reactivity-system ...
- [刷题] 283 Move Zeros
要求 将所有的0,移动到vector的后面比如; [1,3,0,12,5] -> [1,3,12,5,0] 实现 第一版程序,时间.空间复杂度都是O(n) 1 #include<iostr ...
- 【山外笔记-工具框架】SVN版本控制系统
[山外笔记-框架工具]SVN版本控制系统 学习资料: 1.本文打印版下载地址:[山外笔记-框架工具笔记]SVN版本控制工具-打印版.pdf 2.SVN和TortoiseSVN在线中文文档:http:/ ...
- 选择“保留window设置、个人文件及应用”或者“升级安装windows并保留文件设置和应用程序”的 处理干净以后用ghost备份
个人经验 第一次装好以后 把所有常用软件什么的 还有系统的更新全部装好 删去乱七八糟的临时文件啊什么的 处理干净以后用ghost备份下次需要重装直接从ghost镜像恢复 然后更新软件 打补丁 再备份 ...
- Docker Swarm(一)集群部署
一.机器环境 机器规划 172.16.0.89 swarm的manager节点 manager-node 172.16.0.90 swarm的node节点 node1 机器版本(均是:CentOS L ...
- tail -n 10 /etc/passwd
# tail -n 10 /etc/passwdrpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologinchrony:x:992:987::/ ...