【计理01组03号】Java基础知识
简单数据类型的取值范围
byte:8 位,1 字节,最大数据存储量是 255,数值范围是 −128 ~ 127。short:16 位,2 字节,最大数据存储量是 65536,数值范围是 −32768 ~ 32767。int:32 位,4 字节,最大数据存储容量是 2^32 - 1,数值范围是 −2^31 ~ 2^31 - 1。long:64 位,8 字节,最大数据存储容量是 2^64 - 1 数值范围是 −2^63 ~ 2^63 - 1。float:32 位,4 字节,数值范围是 3.4e−45 ~ 1.4e38,直接赋值时必须在数字后加上f或F。double:64 位,8 字节,数值范围在 4.9e−324 ~ 1.8e308,赋值时可以加 d 或 D,也可以不加。boolean:只有true和false两个取值。char:16 位,2 字节,存储 Unicode 码,用单引号'赋值。
字符型
关系运算符和逻辑运算符
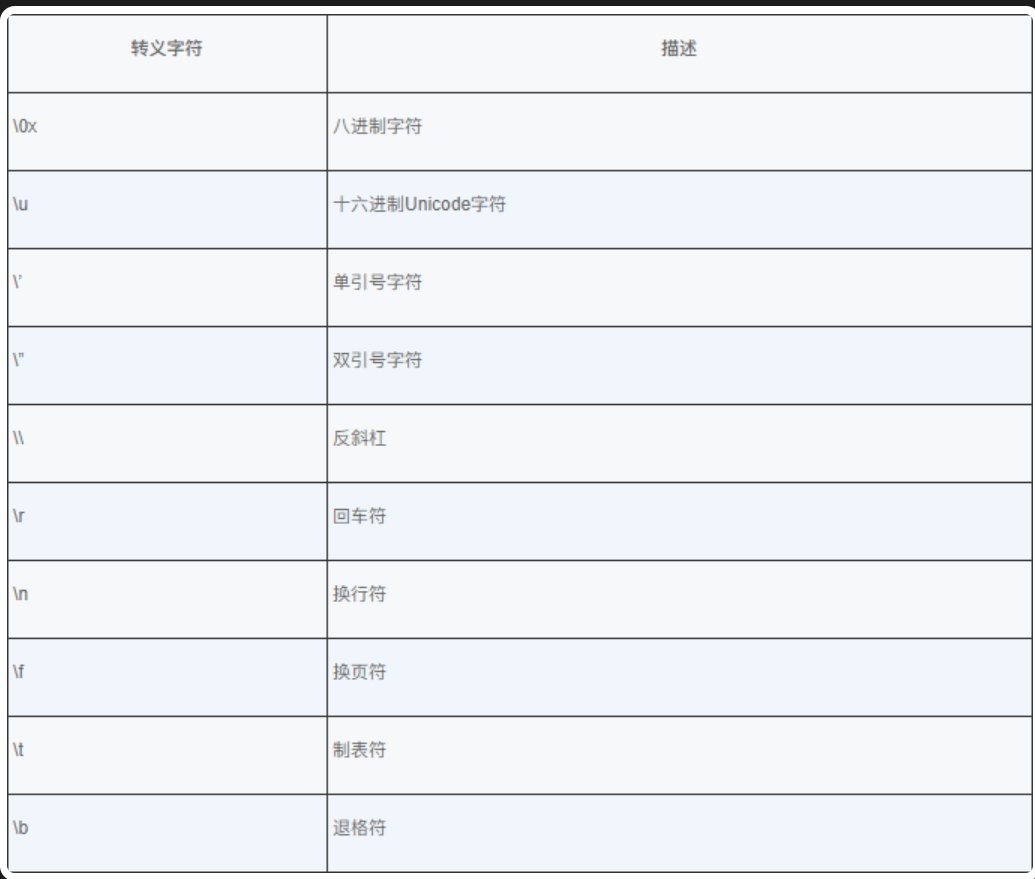
在 Java 程序设计中,关系运算符(Relational Operator)和逻辑运算符(Logical Operator)显得十分重要。关系运算符定义值与值之间的相互关系,逻辑(logical)运算符定义可以用真值和假值连接在一起的方法。
关系运算符
在数学运算中有大于、小于、等于、不等于关系,在程序中可以使用关系运算符来表示上述关系。下图中列出了 Java 中的关系运算符,通过这些关系运算符会产生一个结果,这个结果是一个布尔值,即 true 或 false。在 Java 中,任何类型的数据,都可以用 == 比较是不是相等,用 != 比较是否不相等,只有数字才能比较大小,关系运算的结果可以直接赋予布尔变量。
逻辑运算符
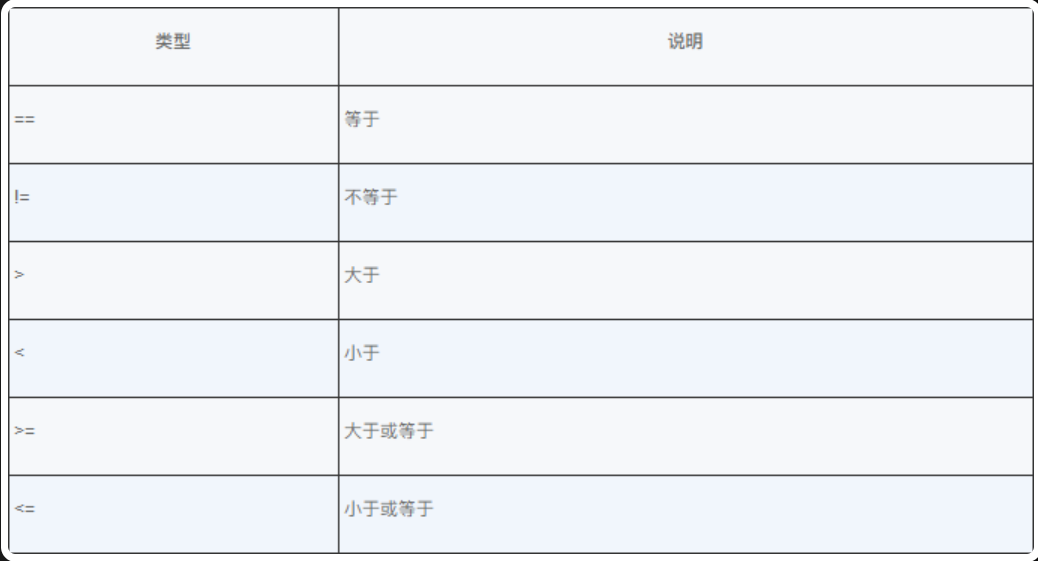
布尔逻辑运算符是最常见的逻辑运算符,用于对布尔型操作数进行布尔逻辑运算,Java 中的布尔逻辑运算符如下图示。

逻辑运算符与关系运算符运算后得到的结果一样,都是布尔类型的值。在 Java 程序设计中,&& 和 || 布尔逻辑运算符不总是对运算符右边的表达式求值,如果使用逻辑与 & 和逻辑或 |,则表达式的结果可以由运算符左边的操作数单独决定。通过下表,同学们可以了解常用逻辑运算符 &&、||、! 运算后的结果。

位逻辑运算符
在 Java 程序设计中,使用位逻辑运算符来操作二进制数据。读者必须注意,位逻辑运算符只能操作二进制数据。如果用在其他进制的数据中,需要先将其他进制的数据转换成二进制数据。位逻辑运算符(Bitwise Operator)可以直接操作整数类型的位,这些整数类型包括 long、int、short、char 和 byte。Java 语言中位逻辑运算符的具体说明如下表所示。

因为位逻辑运算符能够在整数范围内对位操作,所以这样的操作对一个值产生什么效果是很重要的。具体来说,了解 Java 如何存储整数值并且如何表示负数是非常有用的。下表中演示了操作数 A 和操作数 B 按位逻辑运算的结果。

移位运算符把数字的位向右或向左移动,产生一个新的数字。Java 的右移运算符有两个,分别是 >> 和 >>>。
>>运算符:把第一个操作数的二进制码右移指定位数后,将左边空出来的位以原来的符号位填充。即,如果第一个操作数原来是正数,则左边补 0;如果第一个操作数是负数,则左边补 1。>>>:把第一个操作数的二进制码右移指定位数后,将左边空出来的位以 0 填充。
条件运算符
条件运算符是一种特殊的运算符,也被称为三目运算符。它与前面所讲的运算符有很大不同,Java 中提供了一个三目运算符,其实这跟后面讲解的 if 语句有相似之处。条件运算符的目的是决定把哪个值赋给前面的变量。在 Java 语言中使用条件运算符的语法格式如下所示。
变量 = (布尔表达式) ? 为 true 时赋予的值 : 为 false 时赋予的值;赋值运算符
注意:在 Java 中可以对赋值运算符进行扩展,其中最为常用的有如下扩展操作。
另外,在后面的学习中我们会接触到
equals()方法,此方法和赋值运算符==的功能类似。要想理解两者之间的区别,我们需要从变量说起。Java 中的变量分为两类,一类是值类型,它存储的是变量真正的值,比如基础数据类型,值类型的变量存储在内存的栈中;另一类是引用类型,它存储的是对象的地址,与该地址对应的内存空间中存储的才是我们需要的内容,比如字符串和对象等,引用类型的变量存储在内存中的堆中。赋值运算符==比较的是值类型的变量,如果比较两个引用类型的变量,比较的就是它们的引用地址。equals()方法只能用来比较引用类型的变量,也就是比较引用的内容。
==运算符比较的是左右两边的变量是否来自同一个内存地址。如果比较的是值类型(基础数据类型,如int和char之类)的变量,由于值类型的变量存储在栈里面,当两个变量有同一个值时,其实它们只用到同一个内存空间,所以比较的结果是true。
eqluals()方法是 Object 类的基本方法之一,所以每个类都有自己的equals()方法,功能是比较两个对象是否是同一个,通俗的理解就是比较这两个对象的内容是否一样。
赋值运算符是等号 =,Java 中的赋值运算与其他计算机语言中的赋值运算一样,起到赋值的作用。在 Java 中使用赋值运算符的格式如下所示。
+=:对于x+=y,等效于x=x+y。-=:对于x-=y,等效于x=x−y。*=:对于x*=y,等效于x=x*y。/=:对于x/=y,等效于x=x/y。%=:对于x%=y,等效于x=x%y。&=:对于x&=y,等效于x=x&y。|=:对于x|=y,等效于x=x|y。^=:对于x^=y,等效于x=x^y。<<=:对于x<<=y,等效于x=x<<y。>>=:对于x>>=y,等效于x=x>>y。>>>=:对于x>>>=y,等效于x=x>>>y。
其中,变量 var 的类型必须与表达式 expression 的类型一致。 赋值运算符有一个有趣的属性,它允许我们对一连串变量进行赋值。请看下面的代码。 在上述代码中,使用一条赋值语句将变量 x、y、z 都赋值为 100。这是由于 = 运算符表示右边表达式的值,因此 z = 100 的值是 100,然后该值被赋给 y,并依次被赋给 x。使用字符串赋值是给一组变量赋予同一个值的简单办法。在赋值时类型必须匹配,否则将会出现编译错误。
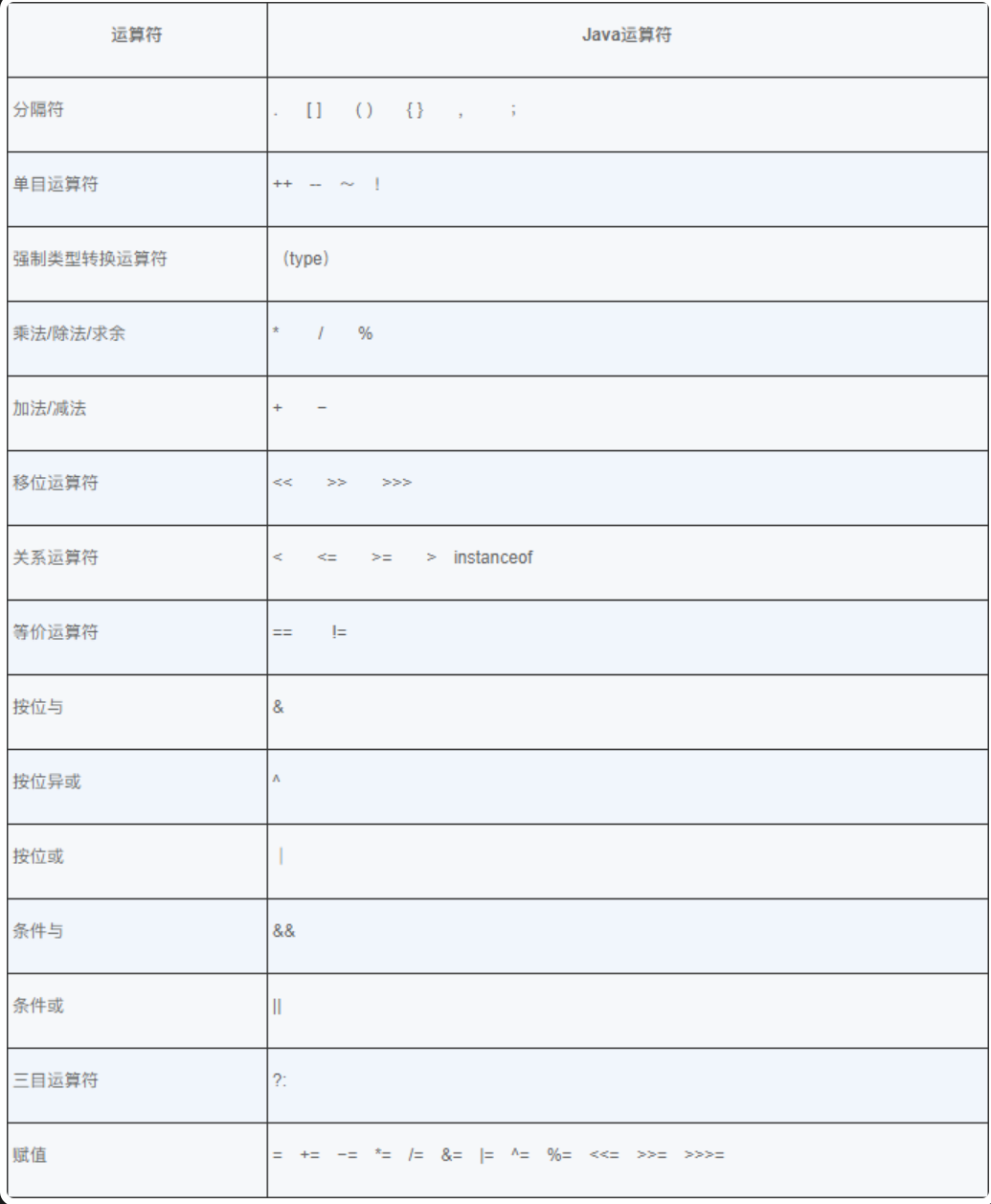
运算符的优先级
数学中的运算都是从左向右运算的,在 Java 中除了单目运算符、赋值运算符和三目运算符外,大部分运算符也是从左向右结合的。单目运算符、赋值运算符和三目运算符是从右向左结合的,也就是说,它们是从右向左运算的。乘法和加法是两个可结合的运算,也就是说,这两个运算符左右两边的操作符可以互换位置而不会影响结果。
运算符有不同的优先级,所谓优先级,就是在表达式运算中的运算顺序。下表中列出了包括分隔符在内的所有运算符的优先级,上一行中的运算符总是优先于下一行的。
字符串的初始化
在 Java 程序中,使用关键字 new 来创建 String 实例,具体格式如下所示。
String a = new String();
上面这行代码创建了一个名为 a 的 String 类的实例,并把它赋给变量,但它此时是一个空的字符串。接下来就为这个字符串复制,赋值代码如下所示。
a = "I am a person.";
在 Java 程序中,我们将上述两句代码合并,就可以产生一种简单的字符串表示方法。
String s = new String("I am a person.");
除了上面的表示方法,还有表示字符串的如下一种形式。
String s = ("I am a person.");String 类
在 Java 程序中可以使用 String 类来操作字符串,在该类中有许多方法可以供程序员使用。
索引
在 Java 程序中,通过索引函数 charAt() 可以返回字符串中指定索引的位置。读者需要注意的是,这里的索引数字从零开始,使用格式如下所示。
public char charAt(int index)
追加字符串
追加字符串函数 concat() 的功能是在字符串的末尾添加字符串,追加字符串是一种比较常用的操作,具体语法格式如下所示。
public String concat(String s)StringBuffer 类
StringBuffer 类是 Java 中另一个重要的操作字符串的类,当需要对字符串进行大量的修改时,使用 StringBuffer 类是最佳选择。接下来将详细讲解 StringBuffer 类中的常用方法。
追加字符
在 StringBuffer 类中实现追加字符功能的方法的语法格式如下所示。
public synchronized StringBuffer append(char b)
插入字符
前面的字符追加方法总是在字符串的末尾添加内容,倘若需要在字符串中添加内容,就需要使用方法 insert(),语法格式如下所示。
public synchronized StringBuffer insert(int offset, String s)
上述语法格式的含义是:将第 2 个参数的内容添加到第 1 个参数指定的位置,换句话说,第 1 个参数表示要插入的起始位置,第 2 个参数是需要插入的内容,可以是包括 String 在内的任何数据类型。
颠倒字符
字符颠倒方法能够将字符颠倒,例如 "我是谁",颠倒过来就变成 "谁是我",很多时候需要颠倒字符。字符颠倒方法 reverse() 的语法格式如下所示。
public synchronized StringBuffer reverse()自动类型转换
如果系统支持把某种基本类型的值直接赋给另一种基本类型的变量,这种方式被称为自动类型转换。当把一个取值范围小的数值或变量直接赋给另一个取值范围大的变量时,系统可以进行自动类型转换。
Java 中所有数值型变量之间可以进行类型转换,取值范围小的可以向取值范围大的进行自动类型转换。就好比有两瓶水,当把小瓶里的水倒入大瓶时不会有任何问题。Java 支持自动类型转换的类型如下图所示。

在上图所示的类型转换图中,箭头左边的数值可以转换为箭头右边的数值。当对任何基本类型的值和字符串进行连接运算时,基本类型的值将自动转换为字符串类型,尽管字符串类型不再是基本类型,而是引用类型。因此,如果希望把基本类型的值转换为对应的字符串,可以对基本类型的值和一个空字符串进行连接。
Java 11 新特性:新增的 String 函数
在新发布的 JDK 11 中,新增了 6 个字符串函数。下面介绍各个字符串函数。
String.repeat(int)函数
String.repeat(int)的功能是根据 int 参数的值重复 String。String.lines()函数
String.lines()的功能是返回从该字符串中提取的行,由行终止符分隔。行要么是零个或多个字符的序列,后面跟着一个行结束符;要么是一个或多个字符的序列,后面是字符串的结尾。一行不包括行终止符。在 Java 程序中,使用函数String.lines()返回的流包含该字符串中出现的行的顺序。String.strip()函数
String.strip()的功能是返回一个字符串,该字符串的值为该字符串,其中所有前导和尾部空白均被删除。如果该 String 对象表示空字符串,或者如果该字符串中的所有代码点是空白的,则返回一个空字符串。否则,返回该字符串的子字符串,该字符串从第一个不是空白的代码点开始,直到最后一个不是空白的代码点,并包括最后一个不是空白的代码点。在 Java 程序中,开发者可以使用此函数去除字符串开头和结尾的空白。String.stripLeading()函数
String.stripLeading()的功能是返回一个字符串,其值为该字符串,并且删除字符串前面的所有空白。如果该 String 对象表示空字符串,或者如果该字符串中的所有代码点是空白的,则返回空字符串。String.stripTrailing()函数
String.stripTrailing()的功能是返回一个字符串,其值为该字符串,并且删除字符串后面的所有空白。如果该 String 对象表示空字符串,或者如果该字符串中的所有代码点是空白的,则返回空字符串。String.isBlank()函数
String.isBlank()的功能是判断字符串是否为空或仅包含空格。如果字符串为空或仅包含空格则返回true;否则,返回false。
定义常量时的注意事项
在 Java 语言中,主要利用 final 关键字(在 Java 类中灵活使用 static 关键字)来进行 Java 常量的定义。当常量被设定后,一般情况下就不允许再进行更改。在定义常量时,需要注意如下 3 点。
- 在定义 Java 常量的时候,就需要对常量进行初始化。也就是说,必须在声明常量时就对它进行初始化。跟局部变量或类成员变量不同,在定义一个常量的时候,进行初始化之后,在应用程序中就无法再次对这个常量进行赋值。如果强行赋值的话,编译器会弹出错误信息,并拒绝接受这一新值。
- 需要注意
final关键字的使用范围。final关键字不仅可以用来修饰基本数据类型的常量,还可以用来修饰对象的引用或方法,比如数组就是对象引用。为此,可以使用final关键字定义一个常量的数组。这是 Java 语言中的一大特色。一个数组对象一旦被final关键字设置为常量数组之后,它就只能恒定地指向一个数组对象,无法将其指向另一个对象,也无法更改数组中的值。 - 需要注意常量的命名规则。在定义变量或常量时,不同的语言,都有自己的一套编码规则。这主要是为了提高代码的共享程度与易读性。在 Java 中定义常量时,也有自己的一套规则。比如在给常量取名时,一般都用大写字母。在 Java 语言中,区分大小写字母。之所以采用大写字母,主要是为了跟变量进行区分。虽然说给常量取名时采用小写字母,也不会有语法上的错误,但是为了在编写代码时能够一目了然地判断变量与常量,最好还是能够将常量设置为大写字母。另外,在常量中,往往通过下划线来分隔不同的字符,而不像对象名或类名那样,通过首字母大写的方式来进行分隔。这些规则虽然不是强制性的,但是为了提高代码的友好性,方便开发团队中的其他成员阅读,这些规则还是需要遵守的。 总之,Java 开发人员需要注意,被定义为
final的常量需要采用大写字母命名,并且中间最好使用下划线作为分隔符来连接多个单词。定义为final的数据不论是常量、对象引用还是数组,在主函数中都不可以改变,否则会被编辑器拒绝并提示错误信息。
char 类型中单引号的意义
char 类型使用单引号括起来,而字符串使用双引号括起来。关于 String 类的具体用法以及对应的各个方法,读者可以参考查阅 API 文档中的信息。其实 Java 语言中的单引号、双引号和反斜线都有特殊的用途,如果在一个字符串中包含这些特殊字符,应该使用转义字符。
例如希望在 Java 程序中表示绝对路径 c:\daima,但这种写法得不到我们期望的结果,因为 Java 会把反斜线当成转义字符,所以应该写成 c:\\daima 的形式。只有同时写两个反斜线,Java 才会把第一个反斜线当成转义字符,与后一个反斜线组成真正的反斜线。
正无穷和负无穷的问题
Java 还提供了 3 个特殊的浮点数值——正无穷大、负无穷大和非数,用于表示溢出和出错。
例如,使用一个正浮点数除以 0 将得到正无穷大,使用一个负浮点数除以 0 将得到负无穷大,用 0.0 除以 0.0 或对一个负数开方将得到一个非数。
正无穷大通过 Double 或 Float 的 POSITIVE_INFINITY 表示,负无穷大通过 Double 或 Float 的 NEGATIVE_INFINITY 表示,非数通过 Double 或 Float 的 NaN 表示。
请注意,只有用浮点数除以 0 才可以得到正无穷大或负无穷大,因为 Java 语言会自动把和浮点数运算的 0(整数)当成 0.0(浮点数)来处理。如果用一个整数除以 0,则会抛出 “ArithmeticException:/by zero”(除以 0 异常)。
移位运算符的限制
Java 移位运算符只能用于整型,不能用于浮点型。也就是说,>>、>>>和<<这 3 个移位运算符并不适合所有的数值类型,它们只适合对 byte、short、char、int 和 long 等整型数进行运算。除此之外,进行移位运算时还有如下规则:
- 对于低于
int类型(如byte、short和char)的操作数来说,总是先自动类型转换为int类型后再移位。 - 对于
int类型的整数移位,例如a >> b,当b > 32时,系统先用b对 32 求余(因为int类型只有 32 位),得到的结果才是真正移位的位数。例如,a >> 33和a >> l的结果完全一样,而a >> 32的结果和a相同。 - 对
long类型的整数移位时,例如a >> b,当b > 64时,总是先用b对 64 求余(因为long类型是 64 位),得到的结果才是真正移位的位数。 当进行位移运算时,只要被移位的二进制码没有发生有效位的数字丢失现象(对于正数而言,通常指被移出的位全部都是 0),不难发现左移 n 位就相当于乘以 2n,右移则相当于除以 2n。这里存在一个问题:左移时,左边舍弃的位通常是无效的,但右移时,右边舍弃的位常常是有效的,因此通过左移和右移更容易看出这种运行结果,并且位移运算不会改变操作数本身,只是得到一个新的运算结果,原来的操作数本身是不会改变的。
if 语句
if 语句由保留字 if、条件语句和位于后面的语句组成。条件语句通常是一个布尔表达式,结果为 true 和 false。如果条件为 true,则执行语句并继续处理其后的下一条语句;如果条件为 false,则跳过语句并继续处理紧跟整个 if 语句的下一条语句。例如在下图中,当条件(condition)为 true 时,执行 statement1 语句;当条件为 false 时,执行 statement2 语句。
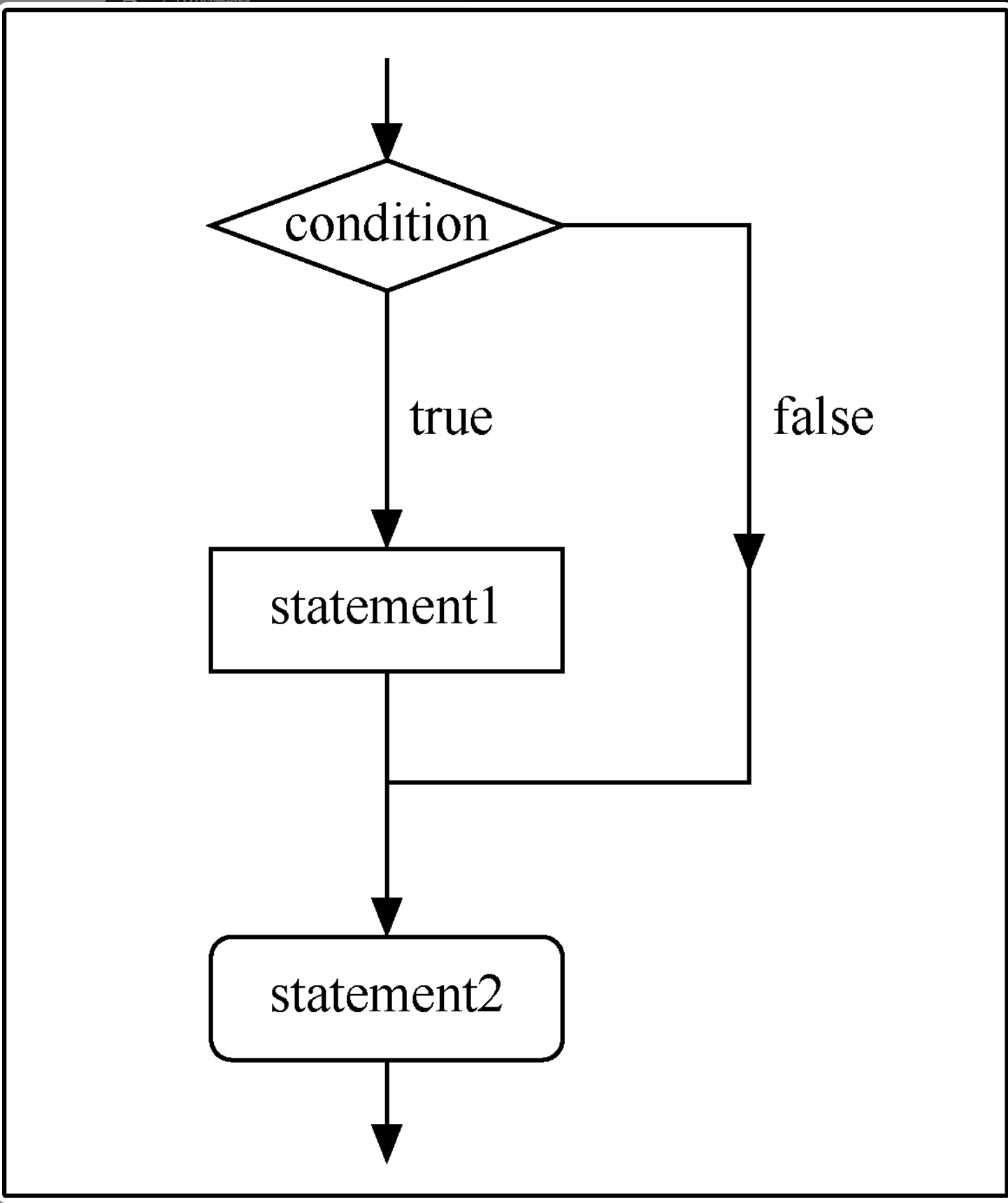
if 语句的语法格式如下所示。
if (条件表达式)
语法说明:if 是该语句中的关键字,后续紧跟一对小括号,这对小括号任何时候都不能省略。小括号的内部是具体的条件,语法上要求条件表达式的结果为 boolean 类型。后续为功能代码,也就是当条件成立时执行的代码。在书写程序时,一般为了直观地表达包含关系,功能代码需要缩进。
例如下面的演示代码。
int a = 10; //定义 int 型变量 a 的初始值是 10
if (a >= 0)
System.out.println("a 是正数"); //a 大于或等于 0 时的输出内容
if ( a % 2 == 0)
System.out.println("a 是偶数"); //a 能够整除 2 时的输出内容
在上述演示代码中,第一个条件判断变量 a 的值是否大于或等于零,如果该条件成立,输出 "a 是正数";第二个条件判断变量 a 是否为偶数,如果成立,也输出 "a 是偶数"。
再看下面的代码的执行流程。
int m = 20; //定义 int 型变量 m 的初始值是 20
if ( m > 20) //如果变量 m 的值大于 20
m += 20; //将 m 的值加上 20
System.out.println(m); //输出 m 的值
按照前面的语法格式说明,只有 m += 20 这行代码属于功能代码,而后续的输出语句和前面的条件形成顺序结构,所以该程序执行以后输出的结果为 20。当条件成立时,如果需要执行的语句有多句,可以使用语句块来进行表述,具体语法格式如下所示。
if (条件表达式) {
功能代码块;
}
这种语法格式中,使用功能代码块来代替前面的功能代码,这样可以在代码块内部书写任意多行代码,而且也使整个程序的逻辑比较清楚,所以在实际的代码编写中推荐使用这种方式。
if语句的延伸
在第一种 if 语句中,大家可以看到,并不对条件不符合的内容进行处理。因为这是不允许的,所以 Java 引入了另外一种条件语句 if…else,基本语法格式如下所示。
if (condition) // 设置条件 condition
statement1; // 如果条件 condition 成立,执行 statement1 这一行代码
else // 如果条件 condition 不成立
statement2; // 执行 statement2 这一行代码
if…else 语句的执行流程如下图所示。

有多个条件判断的 if 语句
if 语句实际上是一种功能十分强大的条件语句,可以对多种情况进行判断。可以判断多个条件的语句是 if-else-if,语法格式如下所示。
if (condition1)
statement1;
else if (condition2)
statement2;
else
statement3;
上述语法格式的执行流程如下。
- 判断第一个条件 condition1,当为
true时执行 statement1,并且程序运行结束。当 condition1 为false时,继续执行后面的代码。 - 当 condition1 为
false时,接下来先判断 condition2 的值,当 condition2 为true时执行 statement2,并且程序运行结束。当 condition2 为false时,执行后面的 statement3。也就是说,当前面的两个条件 condition1 和 condition2 都不成立(为false)时,才会执行 statement3。
if-else-if 的执行流程如下图所示。

在 Java 语句中,if…else 可以嵌套无限次。可以说,只要遇到值为 true 的条件,就会执行对应的语句,然后结束整个程序的运行。
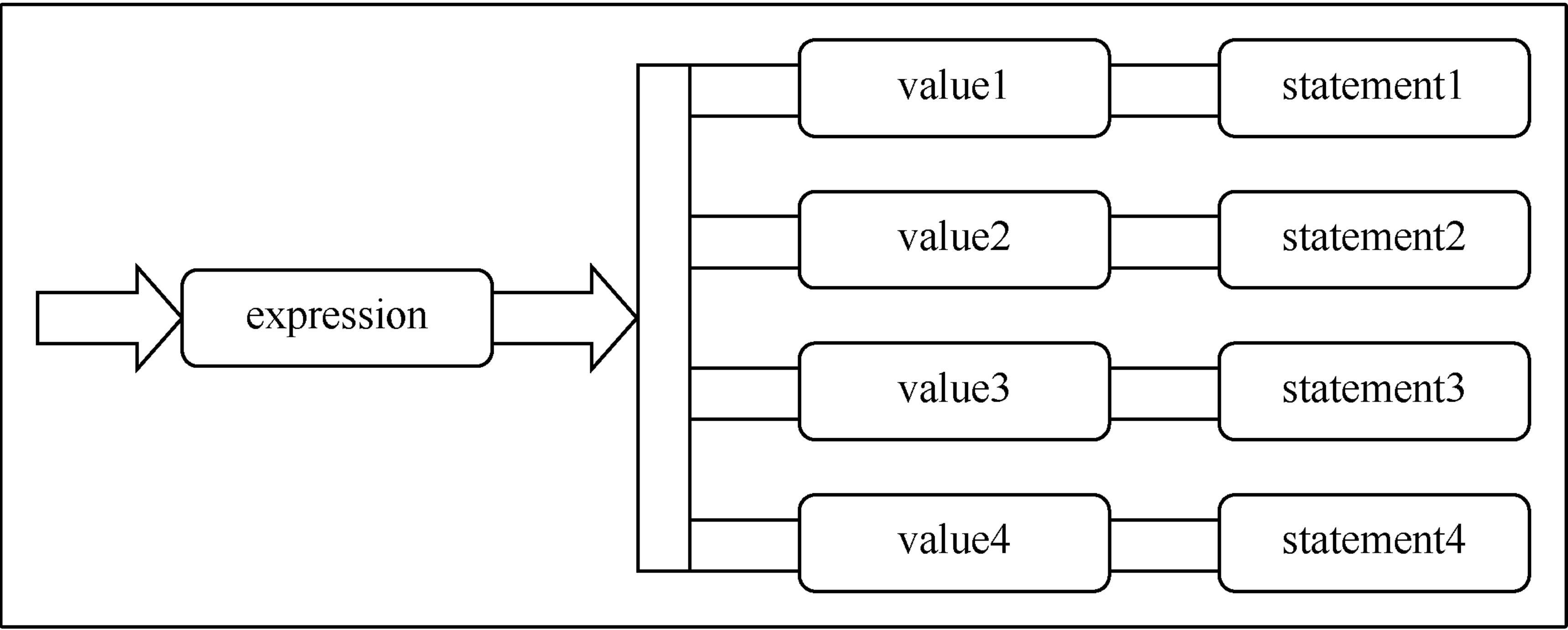
switch 语句的形式
switch 语句能够对条件进行多次判断,具体语法格式如下所示。
switch(整数选择因子) {
case 整数值 1 : 语句; break;
case 整数值 2 : 语句; break;
case 整数值 3 : 语句; break;
case 整数值 4 : 语句; break;
case 整数值 5 : 语句; break;
//..
case 整数值 n : 语句; break;
default: 语句;
}
其中,整数选择因子 必须是 byte、short、int 和 char 类型,每个整数必须是与 整数选择因子 类型兼容的一个常量,而且不能重复。整数选择因子 是一个特殊的表达式,能产生整数。switch 能将整数选择因子的结果与每个整数做比较。发现相符的,就执行对应的语句(简单或复合语句)。没有发现相符的,就执行 default 语句。
在上面的定义中,大家会注意到每个 case 均以一个 break 结尾。这样可使执行流程跳转至 switch 主体的末尾。这是构建 switch 语句的一种传统方式,但 break 是可选的。若省略 break,将会继续执行后面的 case 语句的代码,直到遇到 break 为止。尽管通常不想出现这种情况,但对有经验的程序员来说,也许能够善加利用。注意,最后的 default 语句没有 break,因为执行流程已到达 break 的跳转目的地。当然,如果考虑到编程风格方面的原因,完全可以在 default 语句的末尾放置一个 break,尽管它并没有任何实际用处。
switch 语句的执行流程如下图所示。
无 break 的情况
多次出现了 break 语句,其实在 switch 语句中可以没有 break 这个关键字。一般来说,当 switch 遇到一些 break 关键字时,程序会自动结束 switch 语句。如果把 switch 语句中的 break 关键字去掉了,程序将继续向下执行,直到整个 switch 语句结束。
case 语句后没有执行语句
当 case 语句后没有执行语句时,即使条件为 true,也会忽略掉不执行。
default 可以不在结尾
通过前面的学习,很多初学者可能会误认为 default 一定位于 switch 的结尾。其实不然,它可以位于 switch 中的任意位置
for 循环
在 Java 程序中,for 语句是最为常见的一种循环语句,for 循环是一种功能强大且形式灵活的结构,下面对它进行讲解。
书写格式
for 语句是一种十分常见的循环语句,语法格式如下所示。
for(initialization;condition;iteration){
statements;
}
从上面的语法格式可以看出,for 循环语句由如下 4 部分组成。
initialization:初始化操作,通常用于初始化循环变量。condition:循环条件,是一个布尔表达式,用于判断循环是否持续。iteration:循环迭代器,用于迭代循环变量。statements:要循环执行的语句(可以有多条语句)。
上述每一部分间都用分号分隔,如果只有一条语句需要重复执行,大括号就没有必要有了。
在 Java 程序中,for 循环的执行过程如下。
- 当循环启动时,先执行初始化操作,通常这里会设置一个用于主导循环的循环变量。重要的是要理解初始化表达式仅被执行一次。
- 计算循环条件。
condition必须是一个布尔表达式,它通常会对循环变量与目标值做比较。如果这个布尔表达式为真,则继续执行循环体statements;如果为假,则循环终止。 - 执行循环迭代器,这部分通常是用于递增或递减循环变量的一个表达式,以便接下来重新计算循环条件,判断是否继续循环。
在 Java 程序里,除了 for 语句以外,while 语句也是十分常见的循环语句,其特点和 for 语句十分类似。while 循环语句的最大特点,就是不知道循环多少次。在 Java 程序中,当不知道某个语句块或语句需要重复运行多少次时,通过使用 while 语句可以实现这样的循环功能。当循环条件为真时,while 语句重复执行一条语句或某个语句块。while 语句的基本使用格式如下所示。
while (condition) // condition 表达式是循环条件,其结果是一个布尔值
{
statements;
}
while 语句的执行流程如下图所示。
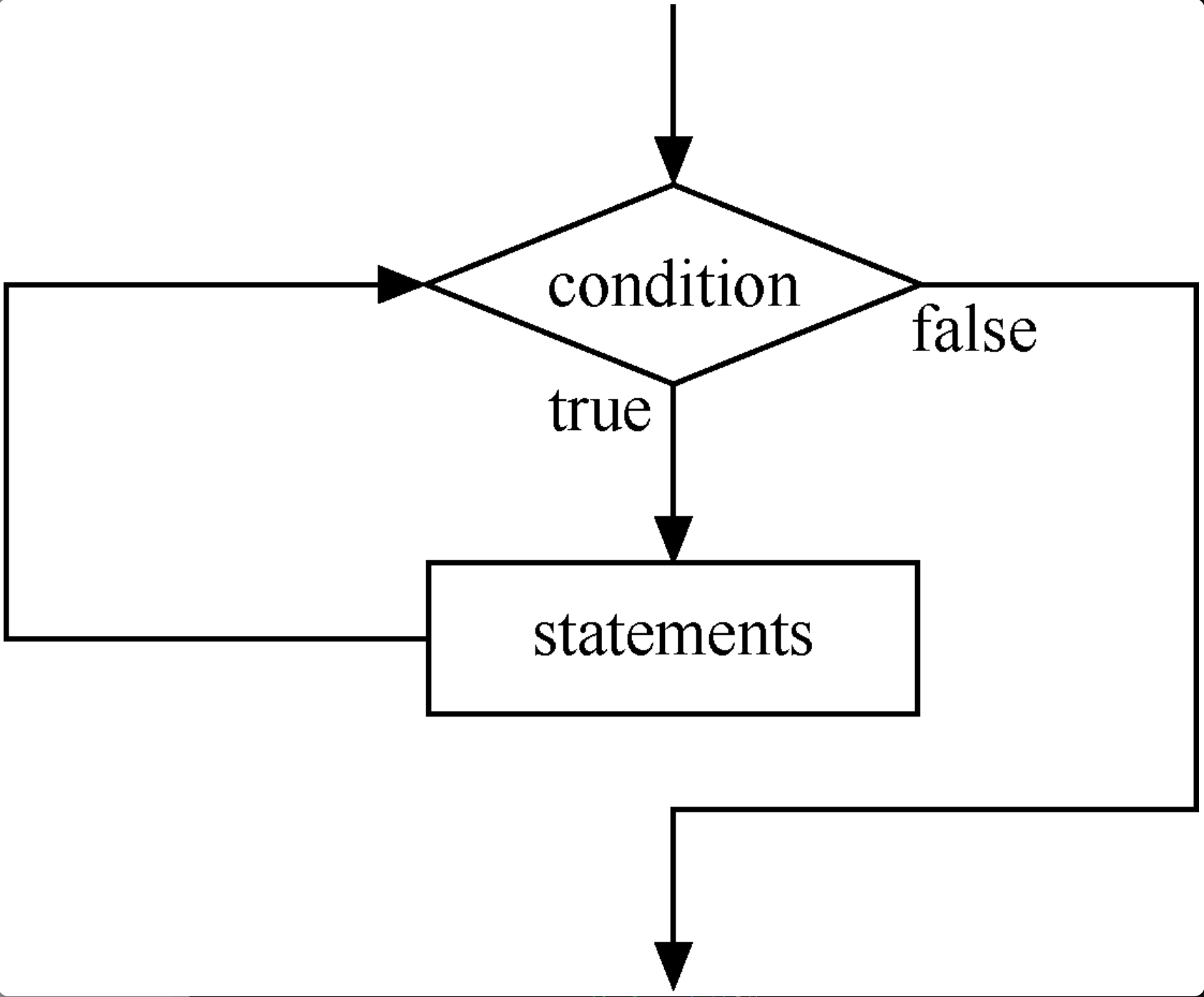
许多软件程序中会存在这种情况:当条件为假时也需要执行语句一次。初学者可以这么理解,在执行一次循环后才测试循环的条件表达式。在 Java 语言中,我们可以使用 do…while 语句实现上述循环。
书写格式
在 Java 语言中,do…while 循环语句的特点是至少会执行一次循环体,因为条件表达式在循环的最后。do…while 循环语句的使用格式如下所示。
do{
statements;
}
while (condition) // condition 表示循环条件,是一个布尔值
在上述格式中,do…while 语句先执行 statement 一次,然后判断循环条件。如果结果为真,循环继续;如果为假,循环结束。
do…while 循环语句的执行流程如下图所示。
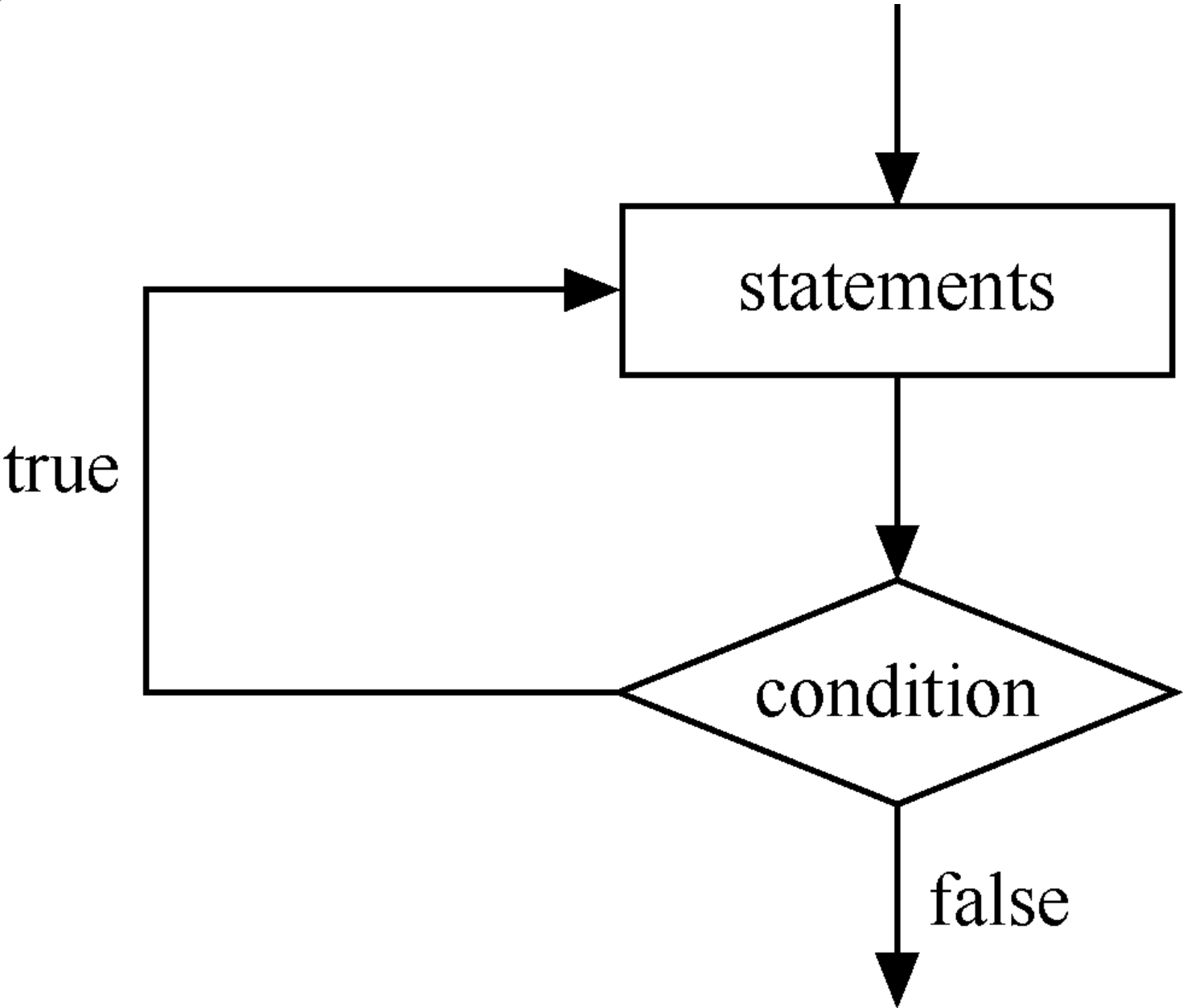
break 语句的应用
在本小节前面的内容中,我们事实上已经接触过 break 语句,了解到它在 switch 语句里可以终止一条语句。其实除这个功能外,break 还能实现其他功能,例如退出循环。break 语句根据用户使用的不同,可以分为无标号退出循环和有标号退出循环两种。
无标号退出循环是指直接退出循环,当在循环语句中遇到 break 语句时,循环会立即终止,循环体外面的语句也将会重新开始执行。
return 语句的使用
在 Java 程序中,使用 return 语句可以返回一个方法的值,并把控制权交给调用它的语句。return 语句的语法格式如下所示。
return [expression];
expression 表示表达式,是可选参数,表示要返回的值,它的数据类型必须同方法声明中返回值的类型一致,这可以通过强制类型转换实现。
在编写 Java 程序时,return 语句如果被放在方法的最后,它将用于退出当前的程序,并返回一个值。如果把单独的 return 语句放在一个方法的中间,会出现编译错误。如果非要把 return 语句放在方法的中间,可以使用条件语句 if,然后将 return 语句放在这个方法的中间,用于实现将程序中未执行的全部语句退出。
continue 语句
在 Java 语言中,continue 语句不如前面几种跳转语句应用得多,其作用是强制当前这轮迭代提前返回,也就是让循环继续执行,但不执行当前迭代中 continue 语句生效之后的语句。
使用 for 循环的技巧
控制 for 循环的变量经常只用于该循环,而不用在程序的其他地方。在这种情况下,可以在循环的初始化部分声明变量。当我们在 for 循环内声明变量时,必须记住重要的一点:该变量的作用域在 for 循环执行后就结束了(因此,该变量的作用域仅限于 for 循环内)。由于循环控制变量不会在程序的其他地方使用,因此大多数程序员都在 for 循环中声明它。
另外,初学者经常以为,只要在 for 后面的括号中控制了循环迭代语句,就万无一失了,其实不是这样的。请看下面的代码。
public class TestForError {
public static void main(String[] args) {
// 循环的初始化条件、循环条件、循环迭代语句都在下面一行
for (int count = 0; count < 10; count++) {
System.out.println(count);
// 再次修改了循环变量
count *= 0.1;
}
System.out.println("循环结束!");
}
}
在上述代码中,我们在循环体内修改了 count 变量的值,并且把这个变量的值乘以 0.1,这会导致 count 的值永远都不超过 10,所以上述程序是一个死循环。
其实在使用 for 循环时,还可以把初始化条件定义在循环体之外,把循环迭代语句放在循环体内。把 for 循环的初始化语句放在循环之前定义还有一个好处,那就是可以扩大初始化语句中定义的变量的作用域。在 for 循环里定义的变量,其作用域仅在该循环内有效。for 循环终止以后,这些变量将不可被访问。
跳转语句的选择技巧
由此可见,continue 的功能和 break 有点类似,区别在于 continue 只是中止当前迭代,接着开始下一次迭代;而 break 则完全终止循环。我们可以将 continue 的作用理解为:略过当前迭代中剩下的语句,重新开始新一轮的迭代。
声明一维数组
数组本质上就是某类元素的集合,每个元素在数组中都拥有对应的索引值,只需要指定索引值就可以取出对应的数据。在 Java 中声明一维数组的格式如下所示。
int[] arrar;
也可以用下面的格式。
int array[];
虽然这两种格式的形式不同,但含义是一样的,各个参数的具体说明如下。
int:数组类型。array:数组名称。[]:一维数组的内容通过这个符号括起来。
除上面声明的整型数组外,还可以声明多种数据类型的数组,例如下面的代码。
boolean[] array; // 声明布尔型数组
float[] array; // 声明浮点型数组
double[] array; // 声明双精度型数组创建一维数组
创建数组实质上就是为数组申请相应的存储空间,数组的创建需要用大括号 {} 括起来,然后将一组相同类型的数据放在存储空间里,Java 编译器负责管理存储空间的分配。创建一维数组的方法十分简单,具体格式如下所示。
int[] a = {1,2,3,5,8,9,15};
上述代码创建了一个名为 a 的整型数组,但是为了访问数组中的特定元素,应指定数组元素的位置序号,也就是索引(又称下标),一维数组的内部结构如下图所示。

上面这个数组的名称是 a,方括号的数值表示数组元素的索引,这个序号通常也被称为下标。这样就可以很清楚地表示每一个数组元素,数组 a 的第一个值就用 a[0] 表示,第 2 个值就用 a[1] 表示,以此类推。
初始化一维数组
在 Java 程序里,一定要将数组看作一个对象,它的数据类型和前面的基本数据类型相同。很多时候我们需要对数组进行初始化处理,在初始化的时候需要规定数组的大小。当然,也可以初始化数组中的每一个元素。下面的代码演示了 3 种初始化一维数组的方法。
int[] a = new int[8]; // 使用 new 关键字创建一个含有 8 个元素的 int 类型的数组 a
int[] a = new int{1,2,3,4,5,6,7,8}; // 初始化并设置数组 a 中的 8 个数组元素
int[] a = {1,2,3,4}; // 初始化并设置数组 a 中的 4 个数组元素
对上面代码的具体说明如下所示。
int:数组类型。a:数组名称。new:对象初始化语句。
在初始化数组的时候,当使用关键字 new 创建数组后,一定要明白它只是一个引用,直到将值赋给引用,开始进行初始化操作后才算真正结束。在上面 3 种初始化数组的方法中,同学们可以根据自己的习惯选择一种初始化方法。
声明二维数组
在前面已经学习了声明一维数组的知识,声明二维数组也十分简单,因为它与声明一维数组的方法十分相似。很多程序员习惯将二维数组看作一种特殊的一维数组,其中的每个元素又是一个数组。声明二维数组的语法格式如下所示。
float A[][]; //float 类型的二维数组 A
char B[][]; //char 类型的二维数组 B
int C[][]; //int 类型的二维数组 C
上述代码中各个参数的具体说明如下所示。
float、char和int:表示数组和类型。A、B和C:表示数组的名称。[][]:二维数组的内容通过这个符号括起来。
创建二维数组的过程,实际上就是在计算机上申请一块存储空间的过程,例如下面是创建二维数组的代码。
int A[][]={
{1,2,3,4},
{5,6,7,8},
{9,10,11,12},
};
上述代码创建了一个二维数组,A 是数组名,实质上这个二维数组相当于一个 3 行 4 列的矩阵。当需要获取二维数组中的值时,可以使用索引来显示,具体格式如下所示。
array[i - 1][j - 1];
上述代码中各个参数的具体说明如下所示。
i:数组的行数。j:数组的列数。
下面以一个二维数组为例,看一下 3 行 4 列的数组的内部结构,如下图所示。

初始化二维数组
初始化二维数组的方法非常简单,可以看作是由多个一维数组构成,也是使用下面的语法格式实现的。
array = new int[][]{
{第一个数组第一个元素的值,第一个数组第二个元素的值,第一个数组第三个元素的值},
{第二个数组第一个元素的值,第二个数组第二个元素的值,第二个数组第三个元素的值},
};
或者使用 new 关键字。
array = new int[3][4]; // 创建一个 3 行 4 列的数组。
使用 new 关键字初始化的数组,其所有元素的值都默认为该数组的类型的默认值。这里是 int 类型数组,则默认值为 0.
上述代码中各个参数的具体说明如下所示。
array:数组名称。new:对象实例化语句。int:数组类型。
声明三维数组
声明三维数组的方法十分简单,与声明一维、二维数组的方法相似,具体格式如下所示。
float a[][][];
char b[][][];
上述代码中各个参数的具体说明如下所示。
float和char:数组类型。a和b:数组名称。
创建三维数组的方法
在 Java 程序中,创建三维数组的方法也十分简单,例如下面的代码。
int [][][] a = new int[2][2][3];初始化三维数组
初始化三维数组的方法十分简单,例如可以用下面的代码初始化一个三维数组。
int[][][]a={
//初始化三维数组
{{1,2,3}, {4,5,6}}
{{7,8,9},{10,11,12}}
}
通过上述代码,可以定义并且初始化三维数组中元素的值。
复制数组
复制数组是指复制数组中的数值,在 Java 中可以使用 System 的方法 arraycopy() 实现数组复制功能。方法 arraycopy() 有两种语法格式,其中第一种语法格式如下所示。
System.arraycopy(arrayA,indexA,arrayB,indexB,a.length);
arrayA:来源数组名称。indexA:来源数组的起始位置。arryaB:目的数组名称。indexB:要从来源数组复制的元素个数。
上述数组复制方法 arraycopy() 有一定局限,可以考虑使用方法 arraycopy() 的第二种格式,使用第二种格式可以复制数组内的任何元素。第二种语法格式如下所示。
System.arraycopy(arrayA,2,arrayB,3,3);
arrayA:来源数组名称。2:来源数组从起始位置开始的第2个元素。arrayB:目的数组名称。3:目的数组从其实位置开始的第3个元素。3:从来源数组的第 2 个元素开始复制3个元素。
比较数组
比较数组就是检查两个数组是否相等。如果相等,则返回布尔值 true;如果不相等,则返回布尔值 false。在 Java 中可以使用方法 equals() 比较数组是否相等,具体格式如下所示。
Arrays.equals(arrayA,arrayB);
arrayA:待比较数组的名称。arrayB:待比较数组的名称。
如果两个数组相等,就会返回 true;否则返回 false。
排序数组
排序数组是指对数组内的元素进行排序,在 Java 中可以使用方法 sort() 实现排序功能,并且排序规则是默认的。方法 sort() 的语法格式如下所示。
Arrays.sort(array);
参数 array 是待排序数组的名称。
搜索数组中的元素
在 Java 中可以使用方法 binarySearch() 搜索数组中的某个元素,语法格式如下所示。
int i = binarySearch(a,"abcde");
a:要搜索的数组名称。abcde:需要在数组中查找的内容。
填充数组
在 Java 程序设计里,可以使用 fill() 方法向数组中填充元素。fill() 方法的功能十分有限,只能使用同一个数值进行填充。使用 fill() 方法的语法格式如下所示。
int a[] = new int[10];
Arrays.fill(array,11);
其中,参数 a 是将要填充的数组的名称,上述格式的含义是将数值 11 填充到数组 a 中。
遍历数组
在 Java 语言中,foreach 语句是从 Java 1.5 开始出现的新特征之一,在遍历数组和遍历集合方面,foreach 为开发人员提供极大的方便。从实质上说,foreach 语句是 for 语句的特殊简化版本,虽然 foreach 语句并不能完全取代 for 语句,但是任何 foreach 语句都可以改写为 for 语句版本。
foreach 并不是一个关键字,习惯上将这种特殊的 for 语句称为 foreach 语句。从英文字面意思理解,foreach 就是「为每一个」的意思。foreach 语句的语法格式如下所示。
for(type 变量 x : 遍历对象 obj){
引用了 x 的 Java 语句;
}
其中,type 是数组元素或集合元素的类型,变量 x 是一个形参,foreach 循环自动将数组元素、集合元素依次赋给变量 x。
动态初始化数组的规则
在执行动态初始化时,程序员只需要指定数组的长度即可,即为每个数组元素指定所需的内存空间,系统将负责为这些数组元素分配初始值。在指定初始值时,系统按如下规则分配初始值。
- 数组元素的类型是基本类型中的整数类型(
byte、short、int和long),数组元素的值是 0。 - 数组元素的类型是基本类型中的浮点类型(
float、double),数组元素的值是 0.0。 - 数组元素的类型是基本类型中的字符类型(
char),数组元素的值是 '\u0000'。 - 数组元素的类型是基本类型中的布尔类型(
boolean),数组元素的值是false。 - 数组元素的类型是引用类型(类、接口和数组),数组元素的值是
null。
引用类型
如果内存中的一个对象没有任何引用的话,就说明这个对象已经不再被使用了,从而可以被垃圾回收。不过由于垃圾回收器的运行时间不确定,可被垃圾回收的对象实际被回收的时间是不确定的。对于一个对象来说,只要有引用存在,它就会一直存在于内存中。如果这样的对象越来越多,超出 JVM 中的内存总数,JVM 就会抛出 OutOfMemory 错误。虽然垃圾回收器的具体运行是由 JVM 控制的,但是开发人员仍然可以在一定程度上与垃圾回收器进行交互,目的在于更好地帮助垃圾回收器管理好应用的内存。这种交互方式就是从 JDK 1.2 开始引入的 java.lang.ref 包。
强引用
在一般的 Java 程序中,见到最多的就是强引用(strong reference)。例如 Date date = new Date(),其中的 date 就是一个对象的强引用。对象的强引用可以在程序中到处传递。很多情况下,会同时有多个引用指向同一个对象。强引用的存在限制了对象在内存中的存活时间。假如对象 A 中包含对象 B 的一个强引用,那么一般情况下,对象 B 的存活时间就不会短于对象 A。如果对象 A 没有显式地把对象 B 的引用设为 null 的话,那么只有当对象 A 被垃圾回收之后,对象 B 才不再有引用指向它,才可能获得被垃圾回收的机会。 除了强引用之外,java.lang.ref包还提供了对一个对象的另一种不同的引用方式。JVM 的垃圾回收器对于不同类型的引用有不同的处理方式。
软引用
软引用(soft reference)在强度上弱于强引用,通过类 SoftReference 来表示。它的作用是告诉垃圾回收器,程序中的哪些对象不那么重要,当内存不足的时候是可以被暂时回收的。当 JVM 中的内存不足时,垃圾回收器会释放那些只被软引用指向的对象。如果全部释放完这些对象之后,内存仍不足,则会抛出 OutOfMemory 错误。软引用非常适合于创建缓存。当系统内存不足时候,缓存中的内容是可以被释放的。比如考虑一个图像编辑器的程序。该程序会把图像文件的全部内容读取到内存中,以方便进行处理。用户也可以同时打开多个文件。当同时打开的文件过多时,就可能造成内存不足。如果使用软引用来指向图像文件的内容,垃圾回收器就可以在必要的时候回收这些内存。
数组的初始化
在 Java 中不存在只分配内存空间而不赋初始值的情况。因为一旦为数组的每个数组元素分配内存空间,内存空间里存储的内容就是数组元素的值,即使内存空间存储的内容为空,「空」也是值,用 null 表示。不管以哪一种方式初始化数组,只要为数组元素分配了内存空间,数组元素就有了初始值。获取初始值的方式有两种:一种由系统自动分配;另一种由程序员指定。
Java 面向对象的几个核心概念
类
只要是一门面向对象的编程语言(例如 C++、C#等),那么就一定有类这个概念。类是指将相同属性的东西放在一起,类是一个模板,能够描述一类对象的行为和状态。请看下面两个例子。
- 在现实生活中,可以将人看成一个类,这类称为人类。
- 如果某个男孩想找一个对象(女朋友),那么所有的女孩都可能是这个男孩的女朋友,所有的女孩就是一「类」。
Java 中的每一个源程序至少都会有一个类,在本书前面介绍的实例中,用关键字 class 定义的都是类。Java 是面向对象的程序设计语言,类是面向对象的重要内容,我们可以把类当成一种自定义数据类型,可以使用类来定义变量,这种类型的变量统称为引用型变量。也就是说,所有类都引用数据类型。
对象
对象是实际存在某个类中的每一个个体,因而也称为实例(instance)。对象的抽象是类,类的具体化就是对象,也可以说类的实例是对象。类用来描述一系列对象,类会概述每个对象包括的数据和行为特征。因此,我们可以把类理解成某种概念、定义,它规定了某类对象所共同具有的数据和行为特征。
接着前面的两个例子。
- 人这个「类」的范围实在是太笼统了,人类里面的秦始皇是一个具体的人,是一个客观存在的人,我们就将秦始皇称为一个对象。
- 想找对象(女朋友)的男孩已经找到目标了,他的女朋友名叫「大美女」。注意,假设叫这个名字的女孩人类中仅有这一个,此时名叫「大美女」的这个女孩就是一个对象。
在面向对象的程序中,首先要将一个对象看作一个类,假定人是对象,任何一个人都是一个对象,类只是一个大概念而已,而类中的对象是具体的,它们具有自己的属性(例如漂亮、身材好)和方法(例如会作诗、会编程)。
Java 中的对象
通过上面的讲解可知,我们的身边有很多对象,例如车、狗、人等。所有这些对象都有自己的状态和行为。拿一条狗来说,它的状态有名字、品种、颜色;行为有叫、摇尾巴和跑。
现实对象和软件对象之间十分相似。软件对象也有状态和行为,软件对象的状态就是属性,行为通过方法来体现。在软件开发过程中,方法操作对象内部状态的改变,对象的相互调用也是通过方法来完成的。
注意:类和对象有以下区别。
类描述客观世界里某一类事物的共同特征,而对象则是类的具体化,Java 程序使用类的构造器来创建该类的对象。
类是创建对象的模板和蓝图,是一组类似对象的共同抽象定义。类是一个抽象的概念,不是一个具体的事物。
对象是类的实例化结果,是真实的存在,代表现实世界的某一事物。
属性
属性有时也称为字段,用于定义该类或该类的实例所包含的数据。在 Java 程序中,属性通常用来描述某个对象的具体特征,是静态的。例如姚明(对象)的身高为 2.6m,小白(对象)的毛发是棕色的,二郎神(对象)额头上有只眼睛等,都是属性。
方法
方法用于定义该类或该类实例的行为特征或功能实现。 每个对象都有自己的行为或者使用它们的方法,比如说一只狗(对象)会跑会叫等。我们把这些行为称为方法,它是动态的,可以使用这些方法来操作一个对象。
类的成员
属性和方法都被称为所在类的成员,因为它们是构成一个类的主要部分,如果没有这两样东西,那么类的定义也就没有内容了。
定义类
在 Java 语言中,定义类的语法格式如下所示。
[修饰符] class 类名
{
零到多个构造器的定义…
零到多个属性…
零到多个方法…
}
在上面定义类的语法格式中,修饰符可以是 public、final 或 static,也可以完全省略它们,类名只要是一个合法的标识符即可,但这仅满足了 Java 的语法要求;如果从程序的可读性方面来看,那么 Java 类名必须由一个或多个有意义的单词构成,其中每个单词的首字母大写,其他字母全部小写,单词与单词之间不要使用任何分隔符。
在定义一个类时,它可以包含 3 个最常见的成员,它们分别是构造器、属性和方法。这 3 个成员可以定义零个或多个。如果 3 个成员都只定义了零个,则说明定义了一个空类,这没有太大的实际意义。类中各个成员之间的定义顺序没有任何影响,各个成员之间可以相互调用。需要注意的是,一个类的 static 方法需要通过实例化其所在类来访问该类的非 static 成员。
下面的代码定义一个名为 person 的类,这是具有一定特性(人类)的一类事物,而 Tom 则是类的一个对象实例,其代码如下所示。
class person {
int age; //人具有 age 属性
String name; //人具有 name 属性
void speak(){ //人具有 speak 方法
System.out.println("My name is"+name);
}
}
public static void main(String args[]){
//类及类属性和方法的使用
person Tom=new person(); //创建一个对象
Tom.age=27; //对象的 age 属性是 27
Tom.name="TOM"; //对象的 name 属性是 TOM
Tom.speak(); //对象的方法是 speak
}
一个类需要具备对应的属性和方法,其中属性用于描述对象,而方法可让对象实现某个具体功能。例如在上述实例代码中,类、对象、属性和方法的具体说明如下所示。
- 类:代码中的
person就是一个类,它代表人类。 - 对象:代码中的 Tom(注意,不是 TOM)就是一个对象,它代表一个具体的人。
- 属性:代码中有两个属性:
age和name,其中属性 age 表示对象 Tom 这个人的年龄是 27,属性 name 表示对象 Tom 这个人的名字是 TOM。 - 方法:代码中的
speak()是一个方法,它表示对象 Tom 这个人具有说话这一技能。
定义属性
在 Java 中定义属性的语法格式如下所示。
[修饰符] 属性类型 属性名 [=默认值];
上述格式的具体说明如下所示。
- 修饰符:修饰符可以省略,也可以是
public、protected、private、static、final,其中public、protected、private最多只能出现一个,它可以与static、final组合起来修饰属性。 - 属性类型:属性类型可以是 Java 语言允许的任何数据类型,它包括基本类型和现在介绍的复合类型。
- 属性名:属性名只要是一个合法的标识符即可,但这只是从语法角度来说的。如果从程序可读性角度来看,那么作者建议属性名应该由一个或多个有意义的单词构成,第一个单词的首字母小写,后面每个单词的首字母大写,其他字母全部小写,单词与单词之间不需使用任何分隔符。
- 默认值:在定义属性时可以定义一个由用户指定的默认值,如果用户没有指定默认值,则该属性的默认值就是其所属类型的默认值。
定义方法
在 Java 中定义方法的语法格式如下所示。
[修饰符] 方法返回值类型 方法名 ([形参列表。..]){
由零条或多条可执行语句组成的方法体;
}
修饰符:它可以省略,也可以是
public、protected、private、static、final、abstract,其中public、protected、private这 3 个最多只能出现一个;abstract和final最多只能出现一个,它们可以与static组合起来共同修饰方法。方法返回值类型:返回值类型可以是 Java 语言允许的任何数据类型,这包括基本类型、复合类型与 _
void类型_。如果声明了方法的返回值类型,则方法体内就必须有一个有效的return语句,该语句可以是一个变量或一个表达式,这个变量或者表达式的类型必须与该方法声明的返回值类型相匹配。当然,如果一个方法中没有返回值,那么我们也可以将返回值声明成void类型。方法名:方法名的命名规则与属性的命名规则基本相同,我们建议方法名以英文的动词开头。
形参列表:形参列表用于定义该方法可以接受的参数,形参列表由零到多组“参数类型形参名”组合而成,多组参数之间以英文逗号(,)隔开,形参类型和形参名之间以英文空格隔开。一旦在定义方法时指定了形参列表,则在调用该方法时必须传入对应的参数值——谁调用方法,谁负责为形参赋值。
在方法体中的多条可执行性语句之间有着严格的执行顺序,在方法体前面的语句总是先执行,在方法体后面的语句总是后执行。
同学们实际上在前面的章节中已经多次接触过方法,例如 public static void main(String args[]){...} 这段代码中就使用了方法 main(),在下面的代码中也定义了几个方法。
public class test_class {
//定义一个无返回值的方法
public void cheng(){ //方法名是 cheng
System.out.println("我已经长大了"); //方法 cheng 的功能是输出文本"我已经长大了"
//…
}
//定义一个有返回值的方法
public int Da(){ //方法名是 Da
int a=100; //定义变量 a,设置初始值是 100
return a; //方法 Da 的功能返回变量 a 的值
}定义构造器
构造器是一个创建对象时自动调用的特殊方法,目的是执行初始化操作。构造器的名称应该与类的名称一致。当 Java 程序在创建一个对象时,系统会默认初始化该对象的属性,基本类型的属性值为 0(数值类型)、false(布尔类型),把所有的引用类型设置为 null。构造器是类创建对象的根本途径,如果一个类没有构造器,那么这个类通常将无法创建实例。为此 Java 语言提供构造器机制,系统会为该类提供一个默认的构造器。一旦为类提供了构造器,那么系统将不再为该类提供构造器。
定义构造器的语法格式与定义方法的语法格式非常相似,在调用时,我们可以通过关键字 new 来调用构造器,从而返回该类的实例。下面,我们先来看一下定义构造器的语法格式。
[修饰符] 构造器名 ([形参列表。..]);
{
由零条或多条可执行语句组成的构造器执行体;
}
上述格式的具体说明如下所示。
修饰符:修饰符可以省略,也可以是
public、protected、private其中之一。构造器名:构造器名必须和类名相同。
形参列表:这和定义方法中的形参列表的格式完全相同。
与一般方法不同的是,构造器不能定义返回值的类型,也不能使用 void 定义构造器没有返回值。如果为构造器定义了返回值的类型,或使用 void 定义构造器没有返回值,那么在编译时就不会出错,但 Java 会把它当成一般方法来处理。下面的代码演示了使用构造器的过程。
public class Person { //定义类 Person
public String name; //定义属性 name
public int age; //定义属性 age
public Person(String name, int age) { //构造器函数 Person()
this.name = name; //开始自定义构造器,添加 name 属性
this.age = age; //继续自定义构造器,添加 age 属性
}
public static void main(String[] args) {
// 使用自定义的构造器创建对象(构造器是创建对象的重要途径)
Person p = new Person("小明", 12); //创建对象 p,名字是“小明”,年龄是 12
System.out.println(p.age); //输出对象 p 的年龄
System.out.println(p.name); //输出对象 p 的名字
}
}public 修饰符
在 Java 程序中,如果将属性和方法定义为 public 类型,那么此属性和方法所在的类和及其子类、同一个包中的类、不同包中的类都可以访问这些属性和方法。
private 修饰符
在 Java 程序里,如果将属性和方法定义为 private 类型,那么该属性和方法只能在自己的类中访问,在其他类中不能访问。
protected 修饰符
在编写 Java 应用程序时,如果使用修饰符 protected 修饰属性和方法,那么该属性和方法只能在自己的子类和类中访问。
其他修饰符
前面几节讲解的修饰符是在 Java 中最常用的修饰符。除了这几个修饰符外,在 Java 程序中还有许多其他的修饰符,具体说明如下所示。
- 默认修饰符:如果没有指定访问控制修饰符,则表示使用默认修饰符,这时变量和方法只能在自己的类及同一个包下的类中访问。
static:由static修饰的变量称为静态变量,由static修饰的方法称为静态方法。final:由final修饰的变量在程序执行过程中最多赋值一次,所以经常定义它为常量。transient:它只能修饰非静态变量,当序列化对象时,由transient修饰的变量不会序列化到目标文件。当对象从序列化文件中重构对象时(反序列化过程),不会恢复由transient字段修饰的变量。volatile:和transient一样,它只能修饰变量。这个关键字的作用就是告诉编译器,只要是被此关键字修饰的变量都是易变、不稳定的。abstract:由abstract修饰的成员称为抽象方法,用abstract修饰的类可以扩展(增加子类),且不能直接实例化。用abstract修饰的方法不能在声明它的类中实现,且必须在某个子类中重写。synchronized:该修饰符只能应用于方法,不能修饰类和变量。此关键字用于在多线程访问程序中共享资源时实现顺序同步访问资源。
方法与函数的关系
不论是从定义方法的语法上来看,还是从方法的功能上来看,都不难发现方法和函数之间的相似性。尽管实际上方法是由传统函数发展而来的,但方法与传统的函数有着显著不同。在结构化编程语言里,函数是老大,整个软件由许多的函数组成。在面向对象的编程语言里,类才是老大,整个系统由许多的类组成。因此在 Java 语言里,方法不能独立存在,方法必须属于类或对象。在 Java 中如果需要定义一个方法,则只能在类体内定义,不能独立定义一个方法。一旦将一个方法定义在某个类体内,并且这个方法使用 static 来修饰,则这个方法属于这个类;否则,这个方法属于这个类的对象。
在 Java 语言中,类型是静态的,即我们当定义一个类之后,只要不再重新编译这个类文件,那么该类和该类对象所拥有的方法是固定的,且永远都不会改变。因为 Java 中的方法不能独立存在,它必须属于一个类或者一个对象,所以方法也不能像函数那样独立执行。在执行方法时必须使用类或对象作为调用者,即所有方法都必须使用 类。方法 或 对象。方法 的格式来调用。此处可能会产生一个问题,当同一个类的不同方法之间相互调用时,不可以直接调用吗?在此需要明确一个原则:当在同一个类的一个方法中调用另外一个方法时,如果被调方法是普通方法,则默认使用 this 作为调用者;如果被调方法是静态方法,则默认使用类作为调用者。尽管从表面上看起来某些方法可以独立执行,但实际上它还是使用 this 或者类来作为调用者。
永远不要把方法当成独立存在的实体,正如现实世界由类和对象组成,而方法只能作为类和对象的附属,Java 语言里的方法也是一样。讲到此处,可以总结 Java 里的方法有如下主要属性。
- 方法不能独立定义,只能在类体里定义。
- 从逻辑意义上来看,方法要么属于该类本身,要么属于该类的一个对象。
- 永远不能独立执行方法,执行方法必须使用类或对象作为调用者。
长度可变的方法
自 JDK 1.5 之后,在 Java 中可以定义形参长度可变的参数,从而允许为方法指定数量不确定的形参。如果在定义方法时,在最后一个形参类型后增加 3 点 ...,则表明该形参可以接受多个参数值,它们当成数组传入。在下面的实例代码中定义了一个形参长度可变的方法。
不使用 void 关键字构造方法名
前面小节节已经讲解了构造器的知识,在此提醒同学们,构造方法没有返回类型,不用 void 修饰,只有一个 public 之类的修饰符而已。
递归方法
如果一个方法在其方法体内调用自身,那么这称为方法递归。方法递归包含一种隐式的循环,它会重复执行某段代码,但这种重复执行无须循环控制。
使用 this
在讲解变量时,曾经将变量分为局部变量和全局变量两种。当局部变量和全局变量的数据类型和名称都相同时,全局变量将会被隐藏,不能使用。为了解决这个问题,Java 规定可以使用关键字 this 去访问全局变量。使用 this 的语法格式如下所示。
this. 成员变量名
this. 成员方法名()创建和使用对象
在 Java 程序中,一般通过关键字 new 来创建对象,计算机会自动为对象分配空间,然后访问变量和方法。对于不同的对象,变量也是不同的,方法由对象调用。
使用静态变量和静态方法
在前面已经讲过,只要使用修饰符 static 关键字在变量和方法前面,那么这个变量和方法就称作静态变量和静态方法。静态变量和静态方法的访问只需要类名,通过运算 . 即可以实现对变量的访问和对方法的调用。
抽象类和抽象方法的基础
抽象方法和抽象类必须使用 abstract 修饰符来定义,有抽象方法的类只能定义成抽象类,类里可以没有抽象方法。所谓抽象类是指只声明方法的存在而不去实现它的类,抽象类不能实例化,也就是不能创建对象。在定义抽象类时,要在关键字 class 前面加上关键字 abstract,其具体格式如下所示。
abstract class 类名{
类体
}
- 抽象类必须使用
abstract修饰符来修饰,抽象方法也必须使用abstract修饰符来修饰,方法不能有方法体。 - 抽象类不能实例化,无法使用关键字 new 来调用抽象类的构造器创建抽象类的实例。
- 抽象类里不能包含抽象方法,这个抽象类也不能创建实例。
- 抽象类可以包含属性、方法(普通方法和抽象方法都可以)、构造器、初始化块、内部类、枚举类 6 种。抽象类的构造器不能创建实例,主要用于被其子类调用。
- 含有抽象方法的类(包括直接定义一个抽象方法;继承一个抽象父类,但没有完全实现父类包含的抽象方法;实现一个接口,但没有完全实现接口包含的抽象方法)只能定义成抽象类。
由此可见,抽象类同样能包含与普通类相同的成员。只是抽象类不能创建实例,普通类不能包含抽象方法,而抽象类可以包含抽象方法。
抽象方法和空方法体的方法不是同一个概念。例如 public abstract void test() 是一个抽象方法,它根本没有方法体,即方法定义后没有一对花括号。然而,但 public void test(){} 是一个普通方法,它已经定义了方法体,只是这个方法体为空而已,即它的方法体什么也不做,因此这个方法不能使用 abstract 来修饰。
抽象类必须有一个抽象方法
创建抽象类最大的要求是必须有一个抽象方法
抽象类的作用
抽象类不能创建实例,它只能当成父类来继承。从语义的角度看,抽象类是从多个具体类中抽象出来的父类,它具有更高层次的抽象。从多个具有相同特征的类中抽象出一个抽象类,以这个抽象类作为其子类的模板,从而避免子类设计的随意性。
抽象类体现的是一种模板模式的设计,抽象类为多个子类的通用模板,子类在抽象类的基础上进行扩展、改造,但总体上子类会大致保留抽象类的行为方式。如果编写一个抽象父类,父类提供了多个子类的通用方法,并把一个或多个方法留给其子类实现,那么这就是一种模板模式,模板模式也是最常见、最简单的设计模式之一。接下来看一个模板模式的实例代码,在它演示的抽象父类中,父类的普通方法依赖于一个抽象方法,而抽象方法则推迟到子类中实现。
软件包的定义
定义软件包的方法十分简单,只需要在 Java 源程序的第一句中添加一段代码即可。在 Java 中定义包的格式如下所示。
package 包名;
package 声明了多程序中的类属于哪个包,在一个包中可以包含多个程序,在 Java 程序中还可以创建多层次的包,具体格式如下所示。
package 包名1[.包名2[.包名3]];
新建 UseFirst.java 文件,编写以下代码。
package China.CQ; //加载一个包,其中父目录函数“China”的子目录是"CQ"
public class UseFirst { //定义类
public static void main(String[] args){
System.out.println("这个程序定义了一个包");
}
}
执行上述代码后将会创建一个多层次的包。由此可见,定义软件包的过程实际上就是新建一个文件夹,将编译后的文件放在新建文件夹中。定义软件包实际上完成的就是这个事情。
在程序里插入软件包
在 Java 程序中插入软件包的方法十分简单,只需使用 import 语句插入所需的类即可。在上一节实验中,已经对插入软件包这个概念进行了初次的接触。在 Java 程序中插入软件包的格式如下所示。
import 包名1.[包名2[.包名3]].(类名1*);
上述格式中,各个参数的具体说明如下所示。
- 包名 1:一级包。
- 包名 2:二级包。
- 类名:是需要导入的类名。也可以使用
*号,表示将导入这个包中的所有类。
掌握 this 的好处
关键字 this 最大的作用就让类中的一个方法访问该类的另一个方法或属性。其实 this 关键字是很容易理解的,接下来作者举两个例子进行对比,相信大家看后对 this 的知识就完全掌握了。
第一段代码演示了没有使用 this 的情况,具体代码如下所示。
class A {
private int aa, bb; // 声明两个 int 类型变量
public int returnData(int x, int y) { // 一个返回整数的方法
aa = x;
bb = y;
return aa + bb;
}
}
在第二段代码中使用 this,具体代码如下所示。
在下面的代码中需要重点注意在 MyDate newDay=new MyDate(this); 语句中 this 的作用。
class MyDate {
private int day;
private int month;
private int year; // 定义 3 个成员变量
public MyDate(int day, int month, int year) {
this.day = day;
this.month = month;
this.year = year;
} // 构造方法
public MyDate(MyDate date) {
this.day = date.day;
this.month = date.month;
this.year = date.year; // 将参数 Date 类中的成员变量赋给 MyDate 类
} // 构造方法
public int getDay() {
return day;
}// 方法
public void setDay(int day) {
this.day = day; // 参数 day 赋给此类中的 ddy
}
public MyDate addDays(int moreDay) {
MyDate newDay = new MyDate(this);
newDay.day = newDay.day + moreDay;
return newDay; // 返回整个类
}
public void print() {
System.out.println("My Date: " + year + "-" + month + "-" + day);
}
}
public class TestMyDate {
public static void main(String args[]) {
MyDate myBirth = new MyDate(19, 11, 1987); // 利用构造函数初始化
MyDate next = myBirth.addDays(7);
// addDays() 的返回值是类,将其返回值赋给变量 next
next.print();
}
}
事实上,前两个类从本质说是相同的,而为什么在第二个类中使用 this 关键字呢?注意,第二个类中的方法 returnData (int aa,int bb) 的形式参数分别为 aa 和 bb,这刚好和 private int aa,bb; 里的变量名是一样的。现在问题来了:究竟如何在 returnData 的方法体中区别形式参数 aa 和全局变量 aa 呢?两个 bb 也是如此吗?这就是引入 this 关键字的用处所在了。this.aa 表示的是全局变量 aa,而没有加 this 的 aa 表示形式参数 aa,bb 也是如此。
在此建议,在编程中不能过多使用 this 关键字。这从上面的代码中也可以看出,当相同的变量名加上 this 关键字过多时,有时会让人分不清。这时可以按照第三段代码进行修改,避免使用 this 关键字。
class A {
private int aa, bb; // 声明两个 int 类型变量
public int returnData(int aa1, int bb1) {
aa = aa1; // 在 aa 后面加上数字 1 加以区分,其他以此类推
bb = bb1;
return aa + bb;
}
}
由此可以看出,尽管上面的第一段代码、第二段代码、第三段代码都是一样的,但是第三段代码既避免了使用 this 关键字,又避免了第一段代码中参数意思不明确的缺点,所以建议使用与第三段代码一样的方法。
推出抽象方法的原因
当编写一个类时,常常会为该类定义一些方法,这些方法用以描述该类的行为方式,这时这些方法都有具体的方法体。在某些情况下,某个父类只是知道其子类应该包含什么样的方法,但却无法准确知道这些子类如何实现这些方法,例如定义一个 Shape 类,这个类应该提供一个计算周长的方法 scalPerimeter(),不同 Shape 子类对周长的计算方法是不一样的,也就是说 Shape 类无法准确知道其子类计算周长的方法。
很多人以为,既然 Shape 不知道如何实现 scalPerimeter() 方法,那么就干脆不要管它了。其实这是不正确的作法,假设有一个 Shape 引用变量,该变量实际上会引用到 Shape 子类的实例,那么这个 Shape 变量就无法调用 scalPerimeter() 方法,必须将其强制类型转换为其子类类型才可调用 scalPerimeter() 方法,这就降低了 Shape 的灵活性。 究竟如何既能在 Shape 类中包含 scalPerimeter() 方法,又无须提供其方法实现呢?Java 中的做法是使用抽象方法满足该要求。抽象方法是只有方法签名,并没有方法实现的方法。
static 修饰的作用
使用 static 修饰的方法属于这个类,或者说属于该类的所有实例所共有。使用 static 修饰的方法不但可以使用类作为调用者来调用,也可以使用对象作为调用者来调用。值得指出的是,因为使用 static 修饰的方法还是属于这个类的,所以使用该类的任何对象来调用这个方法都将会得到相同的执行结果,这与使用类作为调用者的执行结果完全相同。
不使用 static 修饰的方法则属于该类的对象,它不属于这个类。因此不使用 static 修饰的方法只能用对象作为调用者来调用,不能使用类作为调用者来调用。使用不同对象作为调用者来调用同一个普通方法,可能会得到不同的结果。
数组内是同一类型的数据
Java 是一门是面向对象的编程语言,能很好地支持类与类之间的继承关系,这样可能产生一个数组里可以存放多种数据类型的假象。例如有一个水果数组,要求每个数组元素都是水果,实际上数组元素既可以是苹果,也可以是香蕉,但这个数组中的数组元素类型还是唯一的,只能是水果类型。
另外,由于数组是一种引用类型的变量,因此使用它定义一个变量时,仅表示定义了一个引用变量(也就是定义了一个指针),这个引用变量还未指向任何有效的内存,因此定义数组时不能指定数组的长度。由于定义数组仅是定义了一个引用变量,并未指向任何有效的内存空间,所以还没有内存空间来存储数组元素,这时这个数组也不能使用,只有数组初始化后才可以使用。
继承的定义
类的继承是指从已经定义的类中派生出一个新类,是指我们在定义一个新类时,可以基于另外一个已存在的类,从已存在的类中继承有用的功能(例如属性和方法)。这时已存在的类便被称为父类,而这个新类则称为子类。在继承关系中,父类一般具有所有子类的共性特征,而子类则会为自己增加一些更具个性的方法。类的继承具有传递性,即子类还可以继续派生子类,因此,位于上层的类在概念上就更抽象,而位于下层的类在概念上就更具体。
父类和子类
继承是面向对象的机制,利用继承可以创建一个公共类,这个类具有多个项目的共同属性。我们可再用一些具体的类来继承该类,同时加上自己特有的属性。在 Java 中实现继承的方法十分简单,具体格式如下所示。
<修饰符> class <子类名> extends <父类名> {
[<成员变量定义>]…
[<方法定义>]…
}
我们通常所说的子类一般指的是某父类的直接子类,而父类也可称为该子类的直接超类。如果存在多层继承关系,比如,类 A 继承的是类 B,则它们之间的关系就必须符合下面的要求。
- 若存在另外一个类 C,类 C 是类 B 的子类,类 A 是类 C 的子类,那么可以判断出类 A 是类 B 的子类。
- 在 Java 程序中,一个类只能有一个父类,也就是说在 extends 关键字前只能有一个类,它不支持多重继承。
调用父类的构造方法
构造方法是 Java 类中比较重要的方法,一个子类可以访问构造方法,这在前面已经使用过多次。Java 语言调用父类构造方法的具体格式如下所示。
super(参数);访问父类的属性和方法
在 Java 程序中,一个类的子类可以访问父类的属性和方法,具体语法格式如下所示。
super.[方法和全局变量];【计理01组03号】Java基础知识的更多相关文章
- 【计理01组08号】SSM框架整合
[计理01组08号]SSM框架整合 数据库准备 本次课程使用 MySQL 数据库.首先启动 mysql : sudo service mysql start 然后在终端下输入以下命令,进入到 MySQ ...
- 【计理01组04号】JDK基础入门
java.lang包 java.lang包装类 我们都知道 java 是一门面向对象的语言,类将方法和属性封装起来,这样就可以创建和处理相同方法和属性的对象了.但是 java 中的基本数据类型却不是面 ...
- 【计理01组30号】Java 实现日记写作软件
项目分析 代码设计 com.shiyanlou.entity User.java package com.shiyanlou.entity; public class User { private S ...
- JAVA基础知识之网络编程——-网络基础(Java的http get和post请求,多线程下载)
本文主要介绍java.net下为网络编程提供的一些基础包,InetAddress代表一个IP协议对象,可以用来获取IP地址,Host name之类的信息.URL和URLConnect可以用来访问web ...
- Java基础知识总结(超级经典)
Java基础知识总结(超级经典) 写代码: 1,明确需求.我要做什么? 2,分析思路.我要怎么做?1,2,3. 3,确定步骤.每一个思路部分用到哪些语句,方法,和对象. 4,代码实现.用具体的java ...
- 毕向东—Java基础知识总结(超级经典)
Java基础知识总结(超级经典) 写代码: 1,明确需求.我要做什么? 2,分析思路.我要怎么做?1,2,3. 3,确定步骤.每一个思路部分用到哪些语句,方法,和对象. 4,代码实现.用具体的java ...
- 黑马毕向东Java基础知识总结
Java基础知识总结(超级经典) 转自:百度文库 黑马毕向东JAVA基础总结笔记 侵删! 写代码: 1,明确需求.我要做什么? 2,分析思路.我要怎么做?1,2,3. 3,确定步骤.每一个思路部 ...
- java基础知识小总结【转】
java基础知识小总结 在一个独立的原始程序里,只能有一个 public 类,却可以有许多 non-public 类.此外,若是在一个 Java 程序中没有一个类是 public,那么该 Java 程 ...
- Java 基础知识总结
作者QQ:1095737364 QQ群:123300273 欢迎加入! 1.数据类型: 数据类型:1>.基本数据类型:1).数值型: 1}.整型类型(byte 8位 (by ...
随机推荐
- 数仓day02
1. 什么是ETL,ETL都是怎么实现的? ETL中文全称为:抽取.转换.加载 extract transform load ETL是传数仓开发中的一个重要环节.它指的是,ETL负责将分布的. ...
- winXP 下安装python3.3.2
1. 安装python-3.3.2 2. 安装setuptools 下载解压后,进入路径 python setup.py install 3.安装pip 下载解压后,进入路径 python setup ...
- 【Linux】【Services】【SaaS】Spinnaker
1. 简介 1.1. 说明: Spinnaker 是 Netflix 的开源项目,是一个持续交付平台,它定位于将产品快速且持续的部署到多种云平台上.Spinnaker 通过将发布和各个云平台解耦,来将 ...
- Mysql的行级锁
我们首先需要知道的一个大前提是:mysql的锁是由具体的存储引擎实现的.所以像Mysql的默认引擎MyISAM和第三方插件引擎 InnoDB的锁实现机制是有区别的. Mysql有三种级别的锁定:表级锁 ...
- 如何使用gitHub管理自己的项目
GitHub 与 Git Git是一种分布式版本控制系统,与svn是同样的概念 GitHub是一个网站,提供Git服务 前提:你的本机电脑已经安装了git,并且已经注册了gitHub账号 Git上传本 ...
- java实现数组集合转成json格式
一.下载fastjson.jar http://repo1.maven.org/maven2/com/alibaba/fastjson 二.项目添加jar包 Java Build Path 三.导入类 ...
- 商城项目的购物车模块的实现------通过session实现
1.新建购物车的实体类Cart public class Cart implements java.io.Serializable{ private Shangpin shangpin;//存放商品实 ...
- Identity Server 4 从入门到落地(十)—— 编写可配置的客户端和Web Api
前面的部分: Identity Server 4 从入门到落地(一)-- 从IdentityServer4.Admin开始 Identity Server 4 从入门到落地(二)-- 理解授权码模式 ...
- Java中的对于多态的理解
一.什么是多态 面向对象的三大特性:封装.继承.多态 多态的定义:指允许不同类的对象对同一消息做出响应.即同一消息可以根据发送对象的不同而采用多种不同的行为方式.(发送消息就是函数调用) 实现多态的技 ...
- 【antd】如何自定义antd组件form表单中Form.Item里的内容组件
需求:现有一个form表单,但是其中一个元素比较复杂,并不是简单的输入框或者下拉框之类的.但是我又希望能通过form.validateFields().then()去获得它的值,就不需要在当前页面写大 ...