Attention Is All You Need
概
Transformer.
主要内容
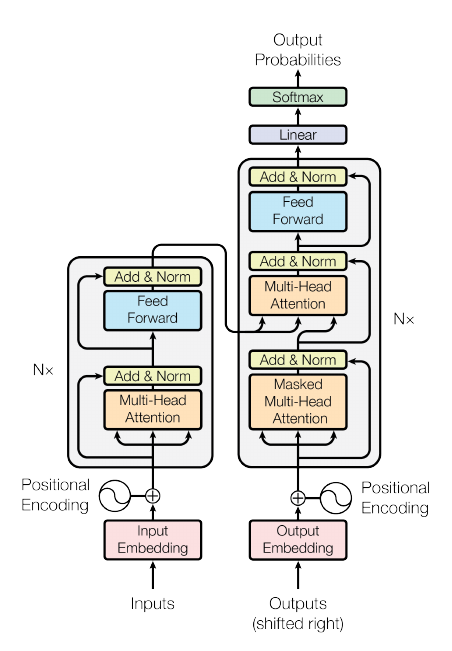
流程:
输出词句(source tokens)\(\mathbb{R}^S\), 通过字典(nn.Embedding)得到相应的embeddings:
\[x_i \in \mathbb{R}^D, i=1\cdots, S,
\]由于是按照batch来计算的, 故整个可以输入可以有下列表示:
\[X \in \mathbb{R}^{B\times S \times D}.
\]注: pytorch里输入是(S, B, D).
纯粹的attention不具备捕捉输入顺序的功能, 所以引入position embeddings:
\[p_{i, 2j} = \sin (i / 10000^{2j/D}), \: p_{i, 2j+1} = \cos (i / 10000^{2j/D}).
\]\[x_i = x_i + p_i.
\]encoder部分, 总共有N个, 每个进行如下的操作:
multi-attention: 首先, 定义权重矩阵\(W^Q, W^K, W^V \in \mathbb{R}^{D\times D}\),
\[Q = XW^Q, \\
K = XW^K, \\
V = XW^V,
\]注: 这里的都是按batch的矩阵乘法(torch.matmul).
接下来变形(假设有\(H\)个heads)
\[(B, S, D) \rightarrow (B, S, H \times D/H) \rightarrow (B, H, S, D/H).
\]此时\(Q, K, V\in \mathbb{R}^{B\times H \times S \times D/H}\).
接下来计算scores,
\[Z = QK^T \in \mathbb{R}^{B\times H \times S \times S},
\]注: 这里的\(K^T\)实际上是key.transpose(-2, -1), 此矩阵乘法是按照最后两个维度进行的(torch.matmul(Q, K.transpose(-2, -1))).
接下来对dim=-1进行softmax:
\[Z =\mathrm{Softmax}(\frac{Z}{\sqrt{D/H}}),
\]一般的代码实现中是:
\[Z = \mathrm{Dropout}(\mathrm{Softmax}(\frac{Z}{\sqrt{D/H}})),
\]计算最后的结果
\[Z = Z V,
\]依旧是torch.matmul(Z, V)的意思, 再转成\(Z \in \mathbb{R}^{B \times S \times D}\), 最后outer projection, 根据\(W^{D \times D}\),
\[Z = ZW,
\]最后有个残差连接:
\[X = \mathrm{LayerNorm}(X + Z),
\]依旧实际中采用
\[X = \mathrm{LayerNorm}(X + \mathrm{Dropout}(Z)).
\]feed forward: 这部分就是简单的:
\[X = \mathrm{LayerNorm}(X + \mathrm{ReLU}(XW_1 + b_1) W_2 + b2),
\]在实际中加入dropout:
\[X = \mathrm{LayerNorm}(X + \mathrm{Dropout}[\mathrm{Dropout}[\mathrm{ReLU}(XW_1 + b_1)] W_2 + b2]).
\]decoder部分, 同样由N个部件组成, 每个部件由self-attention, multi-attention 和 feed forward三部分组成, self-attention 和 feed forward 就是上面介绍的, multi-attention部分出入主要在于:
\[Q = YW^Q, \\
K = XW^K, \\
V = XW^V,
\]这里用\(Y \in \mathbb{R}^{B \times T \times D}\)指代target embeddings. 需要注意的\(T, S\)即tokens的数量不一定一致, 但是矩阵乘法部分是没有问题的.
output probabilities, 输出最后的概率:
\[P = \mathrm{softmax}(VW) \in \mathbb{R}^{B \times T \times N_{voc}},
\]这里\(N_{voc}\)是字典的长度.
一个很重要的问题是, source, target是什么? 这篇博文讲得很清楚, 这里复述一下. 举个例子, 翻译任务, "You are welcome." -> "Da nada" 英语翻译成西班牙语, 那么 source = ['You', 'are', 'welcome', 'pad'], target = ['start', 'Da', 'nada', 'pad'], 预测的目标就是['Da', 'nada'].
在inference的时候, 是没有target的, 故流程如下:
- source = ['You', 'are', 'welcome', 'pad']通过encoder转成特征表示\(f\)用于重复利用;
- target = ['start', 'pad'], 输入decoder, 配合\(f\)得到预测, 取第一个预测'Da'(假设如此);
- 将其加入target = ['start', 'Da', 'pad'], 重复2, 得到预测['Da', 'nada'].
- 倘若还有后续, 便是重复上面的过程, 这是一种greedy的搜索方式.
问题: 那么为什么训练的时候不采取这种方式呢? 上面提到的那篇博文中, 提到这么做会导致训练困难且冗长, 但是我的感觉是, 这篇文章采取的是auto-agressive的逻辑, 所以每一个预测仅与它之前的词有关, 所以当已知target的时候, 重复上面的操作等价于直接传入整个target的预测. 因为在inference的时候, 只能一个一个来, 故比较恶心. 下面贴个上面博文的流程图, 感觉会清楚不少.
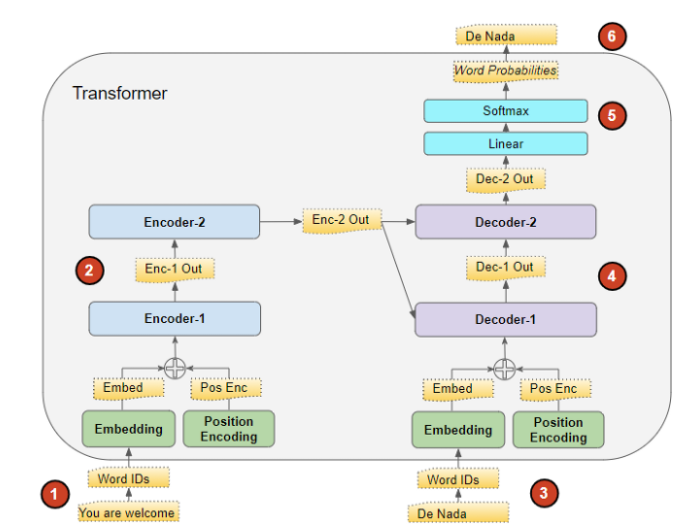
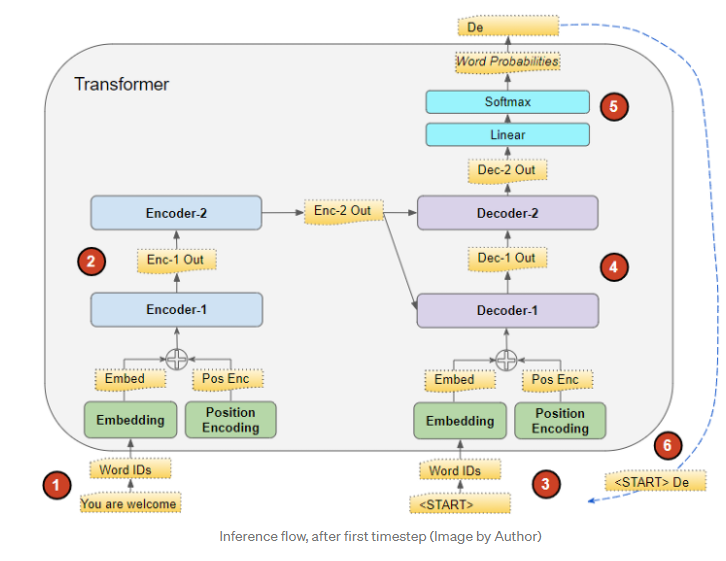
下面给出一些分析(多半是看别人的)
Positional Encoding
auto_regressive
注意到文章中有这么一句话:
At each step the model is auto-regressive [10], consuming the previously generated symbols as additional input when generating the next.
在代码中是通过mask实现的, 假设\(p\)代表scores, 一般来说attention的输出就是
\]
此时是不满足auto-regressive, 为了保证\(o\)仅与\(V_1, \cdots, v_i\)有关(假设此为第i个token), 只需
\]
若
\]
只需
m_j = 0, j \le i, \quad m_j = -\infty, j > i.
\]
这里\(m\)即为mask.
实际上, 代码中还出现了pad_mask, 估计是tokens除了词以外还有别的类别和标签之类的符号, 这些不用于value部分就加上了.
当然mask是非强制性的.
额外的细节
注意到下面给出的代码中, 用于训练的标签smoothing的, 这个直觉上是对的, 毕竟替代词应该是不少的, 严格的one-hot不是好的主意.
代码
Pytorch 1.8 版本是有Transformer的实现的, 就是比较复杂, 感觉还是配合下面的比较容易理解:
Attention Is All You Need的更多相关文章
- Attention:本博客暂停更新
Attention:本博客暂停更新 2016年11月17日08:33:09 博主遗产 http://www.cnblogs.com/radiumlrb/p/6033107.html Dans cett ...
- attention 机制
参考:modeling visual attention via selective tuning attention问题定义: 具体地, 1) the need for region of inte ...
- (转)注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 本文转自:http://www.cnblogs.com/robert-dlut/p/5952032.html 近年来,深度 ...
- 论文笔记之:Deep Attention Recurrent Q-Network
Deep Attention Recurrent Q-Network 5vision groups 摘要:本文将 DQN 引入了 Attention 机制,使得学习更具有方向性和指导性.(前段时间做 ...
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了 ...
- PowerVault TL4000 Tape Library 告警:“Media Attention”
Dell PowerVault TL4000 磁带库机的指示灯告警,从Web管理平台登录后,在菜单"Library Status"下发现如下告警信息: Library Sta ...
- paper 27 :图像/视觉显著性检测技术发展情况梳理(Saliency Detection、Visual Attention)
1. 早期C. Koch与S. Ullman的研究工作. 他们提出了非常有影响力的生物启发模型. C. Koch and S. Ullman . Shifts in selective visual ...
- Attention and Augmented Recurrent Neural Networks
Attention and Augmented Recurrent Neural Networks CHRIS OLAHGoogle Brain SHAN CARTERGoogle Brain Sep ...
- (转)Attention
本文转自:http://www.cosmosshadow.com/ml/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/2016/03/08/Attention.ht ...
- 论文笔记之:Multiple Object Recognition With Visual Attention
Multiple Object Recognition With Visual Attention Google DeepMind ICRL 2015 本文提出了一种基于 attention 的用 ...
随机推荐
- day19 进程管理
day19 进程管理 什么是进程,什么是线程 1.什么是程序 一般情况下,代码,安装包等全部都是应用程序 2.什么是进程 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进 ...
- 多人协作解决方案,git flow的使用
简介 Gitflow工作流程围绕项目发布定义了严格的分支模型. 为不同的分支分配了非常明确的角色,并且定义了使用场景和用法.除了用于功能开发的分支,它还使用独立的分支进行发布前的准备.记录以及后期维护 ...
- 内存管理——array new,array delete
1.array new array new就是申请一个数组空间,所以在delete的时候一定不能忘记在delete前加[] delete加上[]符号以后,就相当于告诉系统"我这里是数组对象, ...
- git pull、git fetch、git merge、git rebase的区别
一.git pull与git fetch区别 1.两者的区别 两者都是更新远程仓库代码到本地. git fetch相当于是从远程获取最新版本到本地,不会自动merge. 只是将远程仓库最新 ...
- lvm 创建扩展
fdisk /dev/sdgnpt8ewpartprobepvcreate /dev/sdg1vgcreate multibank /dev/sdg1lvcreate -l +100%FREE -n ...
- Android消除Toast延迟显示
Toast可以用来显示音量改变或者保存更新消息,如果用户一直点击,Toast会排队一个一个的,直到消息队列全部显示完,这样的效果显然是不好的,下面来看解决方法 Toast.makeText(ac ...
- OC简单介绍
一.OC与C的对比 关键字 OC新增的关键字在使用时,注意部分关键字以"@"开头 方法->函数 定义与实现 数据类型 新增:BOOL/NSObject/id/SEL/bloc ...
- redis入门到精通系列(二):redis操作的两个实践案例
在前面一篇博客中我们已经学完了redis的五种数据类型操作,回顾一下,五种操作类型分别为:字符串类型(string).列表类型(list).散列类型(hash).集合类型(set).有序集合类型(so ...
- 快速上手git gitlab协同合作
简单记录,整理. 摘要 为方便大家快速上手Git,并使用Gitlab协同合作,特编写此手册,手册内容不会太丰富与深入.主要包含如下内容: Git 使用教程1.1 安装1.2 常用命令1.3 版本控制1 ...
- error信息
/opt/hadoop/src/contrib/eclipse-plugin/build.xml:61: warning: 'includeantruntime' was not set, defau ...