AI系统——梯度累积算法
- 明天博士论文要答辩了,只有一张12G二手卡,今晚通宵要搞定10个模型实验
- 挖槽,突然想出一个T9开天霹雳模型,加载不进去我那张12G的二手卡,感觉要错过今年上台Best Paper领奖

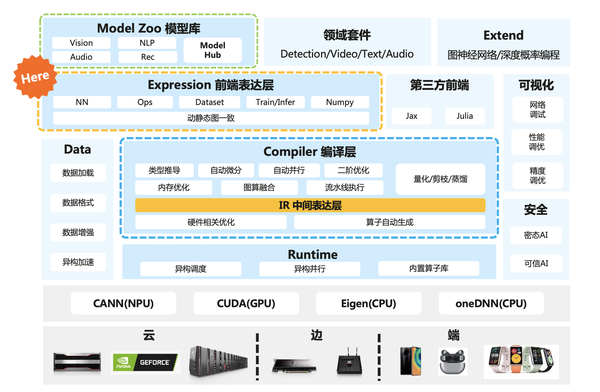
Batch size的作用
训练数据的Batch size大小对训练过程的收敛性,以及训练模型的最终准确性具有关键影响。通常,每个神经网络和数据集的Batch size大小都有一个最佳值或值范围。
不同的神经网络和不同的数据集可能有不同的最佳Batch size大小。
Batch size对内存的影响
- 模型参数:网络模型需要用到的权重参数和偏差。
- 优化器变量:优化器算法需要的变量,例如动量momentum。
- 中间计算变量:网络模型计算产生的中间值,这些值临时存储在AI加速芯片的内存中,例如,每层激活的输出。
- 工作区Workspace:AI加速芯片的内核实现是需要用到的局部变量,其产生的临时内存,例如算子D=A+B/C中B/C计算时产生的局部变量。
使用大Batch size的方法
梯度累积原理
学习率 learning rate:一定条件下,Batch size越大训练效果越好,梯度累积则模拟了batch size增大的效果,如果accumulation steps为4,则Batch size增大了4倍,根据ZOMI的经验,使用梯度累积的时候需要把学习率适当放大。 归一化 Batch Norm:accumulation steps为4时进行Batch size模拟放大效果,和真实Batch size相比,数据的分布其实并不完全相同,4倍Batch size的BN计算出来的均值和方差与实际数据均值和方差不太相同,因此有些实现中会使用Group Norm来代替Batch Norm。
梯度累积实现
for i, (images, labels) in enumerate(train_data):
# 1. forwared 前向计算
outputs = model(images)
loss = criterion(outputs, labels) # 2. backward 反向传播计算梯度
optimizer.zero_grad()
loss.backward()
optimizer.step()
- model(images) 输入图像和标签,前向计算。
- criterion(outputs, labels) 通过前向计算得到预测值,计算损失函数。
- ptimizer.zero_grad() 清空历史的梯度信息。
- loss.backward() 进行反向传播,计算当前batch的梯度。
- optimizer.step() 根据反向传播得到的梯度,更新网络参数。
# 梯度累加参数
accumulation_steps = 4 for i, (images, labels) in enumerate(train_data):
# 1. forwared 前向计算
outputs = model(imgaes)
loss = criterion(outputs, labels) # 2.1 loss regularization loss正则化
loss += loss / accumulation_steps # 2.2 backward propagation 反向传播计算梯度
loss.backward() # 3. update parameters of net
if ((i+1) % accumulation)==0:
# optimizer the net
optimizer.step()
optimizer.zero_grad() # reset grdient
- model(images) 输入图像和标签,前向计算。
- criterion(outputs, labels) 通过前向计算得到预测值,计算损失函数。
- loss / accumulation_steps loss每次更新,因此每次除以steps累积到原梯度上。
- loss.backward() 进行反向传播,计算当前batch的梯度。
- 多次循环伪代码步骤1-2,不清空梯度,使梯度累加在历史梯度上。
- optimizer.step() 梯度累加一定次数后,根据所累积的梯度更新网络参数。
- optimizer.zero_grad() 清空历史梯度,为下一次梯度累加做准备。
参考文献
- [1] Hermans, Joeri R., Gerasimos Spanakis, and Rico Möckel. "Accumulated gradient normalization." Asian Conference on Machine Learning. PMLR, 2017.
- [2] Lin, Yujun, et al. "Deep gradient compression: Reducing the communication bandwidth for distributed training." arXiv preprint arXiv:1712.01887 (2017).
AI系统——梯度累积算法的更多相关文章
- Silverlight 2.5D RPG游戏技巧与特效处理:(十一)AI系统
Silverlight 2.5D RPG游戏技巧与特效处理:(十一)AI系统 作者: 深蓝色右手 来源: 博客园 发布时间: 2011-04-19 11:18 阅读: 1282 次 推荐: 0 ...
- AI技术原理|机器学习算法
摘要 机器学习算法分类:监督学习.半监督学习.无监督学习.强化学习 基本的机器学习算法:线性回归.支持向量机(SVM).最近邻居(KNN).逻辑回归.决策树.k平均.随机森林.朴素贝叶斯.降维.梯度增 ...
- 广告系统中weak-and算法原理及编码验证
wand(weak and)算法基本思路 一般搜索的query比较短,但如果query比较长,如是一段文本,需要搜索相似的文本,这时候一般就需要wand算法,该算法在广告系统中有比较成熟的应 该,主要 ...
- 腾讯公司数据分析岗位的hadoop工作 线性回归 k-means算法 朴素贝叶斯算法 SpringMVC组件 某公司的广告投放系统 KNN算法 社交网络模型 SpringMVC注解方式
腾讯公司数据分析岗位的hadoop工作 线性回归 k-means算法 朴素贝叶斯算法 SpringMVC组件 某公司的广告投放系统 KNN算法 社交网络模型 SpringMVC注解方式 某移动公司实时 ...
- 基于R语言的梯度推进算法介绍
通常来说,我们可以从两个方面来提高一个预测模型的准确性:完善特征工程(feature engineering)或是直接使用Boosting算法.通过大量数据科学竞赛的试炼,我们可以发现人们更钟爱于Bo ...
- 科学家开发新AI系统,可读取大脑信息并表达复杂思想
我们终于找到了一种方法,可以在核磁共振成像的信号中看到这种复杂的想法.美国卡内基梅隆大学的Marcel Just说,思维和大脑活动模式之间的对应关系告诉我们这些想法是如何构建的. 人工智能系统表明,大 ...
- 梯度优化算法Adam
最近读一个代码发现用了一个梯度更新方法, 刚开始还以为是什么奇奇怪怪的梯度下降法, 最后分析一下是用一阶梯度及其二次幂做的梯度更新.网上搜了一下, 果然就是称为Adam的梯度更新算法, 全称是:自适应 ...
- [源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积
[源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积 目录 [源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积 0x00 摘要 0x01 概述 1.1 前文回 ...
- ptorch常用代码梯度篇(梯度裁剪、梯度累积、冻结预训练层等)
梯度裁剪(Gradient Clipping) 在训练比较深或者循环神经网络模型的过程中,我们有可能发生梯度爆炸的情况,这样会导致我们模型训练无法收敛. 我们可以采取一个简单的策略来避免梯度的爆炸,那 ...
随机推荐
- useEffect无限调用问题
1.useEfect()的基本用法 const [test,setTest] = useState(1) const init=()=>{ setTest(2) } useEffect(()=& ...
- ciscn_2019_en_3
例行检查我就不放了,64位的程序放入ida中 可以看到s到buf的距离是0x10,因为puts是遇到\x00截止.而且题目没有限制我们s输入的数量,所以可以通过这个puts泄露出libc的基值 很明显 ...
- 联盛德 HLK-W806 (十): 在 CDK IDE开发环境中使用WM-SDK-W806
目录 联盛德 HLK-W806 (一): Ubuntu20.04下的开发环境配置, 编译和烧录说明 联盛德 HLK-W806 (二): Win10下的开发环境配置, 编译和烧录说明 联盛德 HLK-W ...
- 🏆【CI/CD技术专题】「Docker实战系列」(1)本地进行生成镜像以及标签Tag推送到DockerHub
背景介绍 Docker镜像构建成功后,只要有docker环境就可以使用,但必须将镜像推送到Docker Hub上去.创建的镜像最好要符合Docker Hub的tag要求,因为在Docker Hub注册 ...
- 解决Tomcat10.0.12源码编译问题进而剖析其优秀分层设计架构
概述 Tomcat.Jetty.Undertow这几个都是非常有名实现Servlet规范的应用服务器,Tomcat本身也是业界上非常优秀的中间件,简单可将Tomcat看成是一个Http服务器+Serv ...
- CF938A Word Correction 题解
Content 有一个长度为 \(n\) 的,只包含小写字母的字符串,只要有两个元音字母相邻,就得删除后一个元音字母(\(\texttt{a,e,i,o,u,y}\) 中的一个),请求出最后得到的字符 ...
- Spring学习(二)三种方式的依赖注入
1.前言 上一篇讲到第一个Spring项目的创建.以及bean的注入.当然.注入的方式一共有三种.本文将展开细说. 1.set注入:本质是通过set方法赋值 1.创建老师类和课程类 1.Course ...
- 自动化中不能犯的4个RPA错误-RPA学习天地
自动化在客户支持中的使用预计在未来几年会加速. 根据Dimension Research的数据,2022年72%的客户互动将通过机器人流程自动化(RPA)等新兴技术进行.电话互动将从41%下降到12% ...
- 【LeetCode】905. Sort Array By Parity 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述: 题目大意 解题方法 自定义sorted函数的cmp 日期 题目地址:h ...
- 论文翻译:2020_Joint NN-Supported Multichannel Reduction of Acoustic Echo, Reverberation and Noise
论文地址:https://ieeexploreieee.fenshishang.com/abstract/document/9142362 神经网络支持的回声.混响和噪声联合多通道降噪 摘要 我们考虑 ...