Hive之分析函数
一、sum() over(partition by)
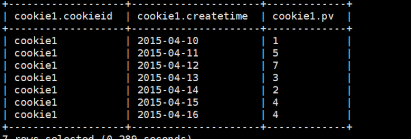
- 数据准备
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
- 查询语句
select
cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1,
sum(pv) over (partition by cookieid order by createtime) as pv2,
sum(pv) over (partition by cookieid) as pv3,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5,
sum(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from cookie1;
- 查询结果
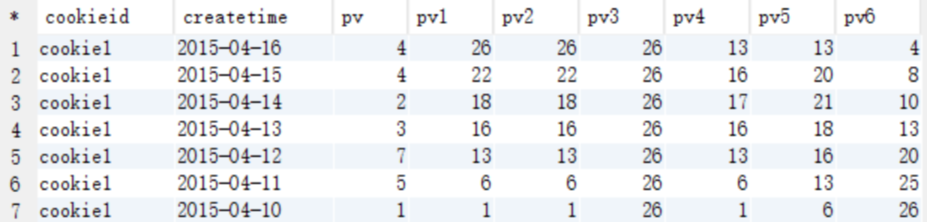
查询结果说明
- pv1: 分组内从起点到当前行的pv累积,如,11号的pv1=2015-04-10号的pv + 2015-04-11号的pv, 2015-04-12号=10号+11号+12号
- pv2: 同pv1
- pv3: 分组内(cookie1)所有的pv累加
- pv4: 分组内当前行+往前3行,如,11号=10号+11号, 12号=10号+11号+12号, 13号=10号+11号+12号+13号, 14号=11号+12号+13号+14号
- pv5: 分组内当前行+往前3行+往后1行,如,14号=11号+12号+13号+14号+15号=5+7+3+2+4=21
- pv6: 分组内当前行+往后所有行,如,13号=13号+14号+15号+16号=3+2+4+4=13,14号=14号+15号+16号=2+4+4=10
partition by 的参数说明
如果不指定ROWS BETWEEN,默认为从起点到当前行;
如果不指定ORDER BY,则将分组内所有值累加;
关键是理解ROWS BETWEEN含义,也叫做WINDOW子句:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING:表示到后面的终点
–其他AVG,MIN,MAX,和SUM用法一样。
二、avg()、min()、max() over(partition)
avg()、min()、max() over(partition) 与 sum() over(partition) 类似,都是对窗口做操作
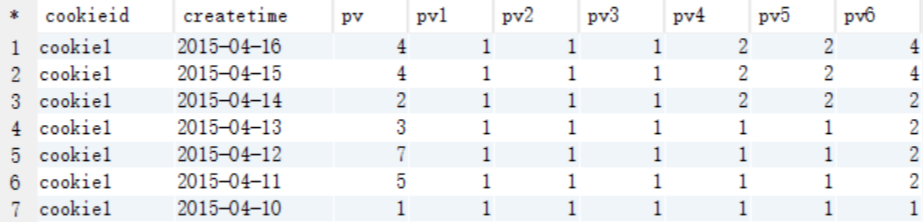
- min() over(partition) 的查询语句
select
cookieid,
createtime,
pv,
min(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1, -- 默认为从起点到当前行
min(pv) over (partition by cookieid order by createtime) as pv2, --从起点到当前行,结果同pv1
min(pv) over (partition by cookieid) as pv3, --分组内所有行
min(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4, --当前行+往前3行
min(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5, --当前行+往前3行+往后1行
min(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6 --当前行+往后所有行
from cookie1;
- 结果展示
三、row_number() over(partition by)
row_number()从1开始,为每一条分组记录返回一个数字
row_number() OVER (ORDER BY id DESC) 是先把id列降序,再为降序以后的每条id记录返回一个序号。
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)
- 数据准备
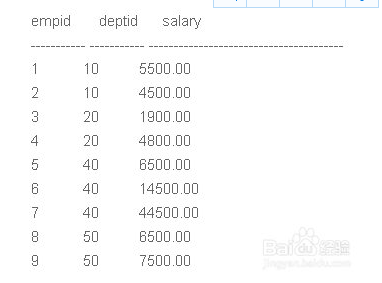
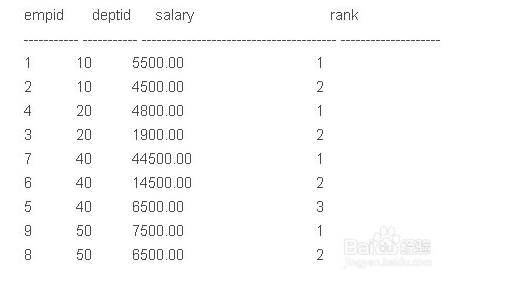
- 查询:需根据部门分组,显示每个部门的工资等级
SELECT *, Row_Number() OVER (partition by deptid ORDER BY salary desc) rank FROM employee
四、用over(partition by) 还是 group by
总结区别:over(partition by) 和 group by的区别
- group by:单纯分组,要查询非group by字段时需要用 collect_set()[0]处理,或者子查询处理
- over(partition by):不仅能分组,还能同时查询非分区字段,不仅可以使用sum()、avg()、min()、max()等功能,还可以使用row_number() 对数据进行排名功能
group by
在hive中使用group by时,是不能select 非group by 字段的。
select name,sex from people group by sex;
---------------------------------------------------
会报错:
FAILED: SemanticException [Error 10025]: Line 1:15 Expression not in GROUP BY key 'name'
解决这个问题的方式有很多:在子查询中做group by然后用left join 连接,在外层selec。还有就是用collect_set()包围这个非group by字段
select collect_set(name)[0],sex from people group by sex;
- over(partition by)
当然,用over(partition by)也能解决分组问题,在分组的同时会对相同key的进行回填处理
数据展示
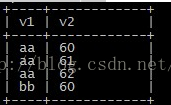
查询语句
select v1,v2,sum(v2) over(partition by v1) as sum from wmg_test;
结果展示
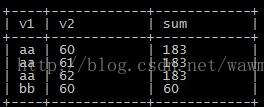
所以要做到取一条分组数据,就在外层去重
select distinct v1,sum_01
from (
select v1,sum(v2) over(partition by v1) as sum_01
from wmg_test
) a;
结果展示

Hive之分析函数的更多相关文章
- [Hive_10] Hive 的分析函数
0. 说明 Hive 的分析函数 窗口函数 | 排名函数 | 最大值 | 分层次 | lead && lag 统计活跃用户 | cume_dist 1. 窗口函数(开窗函数) ove ...
- hive窗口函数/分析函数详细剖析
hive窗口函数/分析函数 在sql中有一类函数叫做聚合函数,例如sum().avg().max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的.但是有时 ...
- hive中分析函数window子句
hive中有些分析函数功能确实很强大,在和sum,max等聚合函数结合起来能实现不少功能. 直接上代码演示吧 原始数据 channel1 2016-11-10 1 channel1 2016-11-1 ...
- Hive 窗口分析函数
1.窗口函数 1.LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值 第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值 ...
- Hive的分析函数的使用
原文: https://www.toutiao.com/i6769120000578945544/?group_id=6769120000578945544 我们先准备数据库.表和数据 开窗分析函数相 ...
- Hive Ntile分析函数学习
NTILE(n) 用于将分组数据按照顺序切分成n片,返回当前记录所在的切片值 NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid O ...
- Hive—简单窗口分析函数
hive 窗口分析函数 : jdbc:hive2:> select * from t_access; +----------------+---------------------------- ...
- Hive 分析函数lead、lag实例应用
Hive的分析函数又叫窗口函数,在oracle中就有这样的分析函数,主要用来做数据统计分析的. Lag和Lead分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead) ...
- Hive简记
在大数据工作中难免遇到数据仓库(OLAP)架构,以及通过Hive SQL简化分布式计算的场景.所以想通过这篇博客对Hive使用有一个大致总结,希望道友多多指教! 摘要: 1.Hive安装 2.Hive ...
随机推荐
- Pandas高级教程之:处理缺失数据
目录 简介 NaN的例子 整数类型的缺失值 Datetimes 类型的缺失值 None 和 np.nan 的转换 缺失值的计算 使用fillna填充NaN数据 使用dropna删除包含NA的数据 插值 ...
- 远程连接MySQL错误“plugin caching_sha2_password could not be loaded”的解决办法
远程连接MySQL错误"plugin caching_sha2_password could not be loaded"的解决办法 问题描述: 今天在阿里云租了一个服务器,当我用 ...
- Vue(5)计算属性computed
前言 一般情况下属性都是放到data中的,但是有些属性可能是需要经过一些逻辑计算后才能得出来,那么我们可以把这类属性变成计算属性.比如以下: <div id="example" ...
- 示例讲解PostgreSQL表分区的三种方式
我最新最全的文章都在南瓜慢说 www.pkslow.com,欢迎大家来喝茶! 1 简介 表分区是解决一些因单表过大引用的性能问题的方式,比如某张表过大就会造成查询变慢,可能分区是一种解决方案.一般建议 ...
- 数据同步Datax与Datax_web的部署以及使用说明
一.DataX3.0概述 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳定高 ...
- 二、RabbitMQ 进阶特性及使用场景 [.NET]
前言 经过上一篇的介绍,相信大家对RabbitMQ 的各种概念有了一定的了解,及如何使用RabbitMQ.Client 去发送和消费消息. 特性及使用场景 1. TTL 过期时间 TTL可以用来指定q ...
- 去除office自动生成目录后生成的小框框(内容控件,目录控件)
如何自动生成目录在这里就不进行阐述了,想必能看到这这里的人已经完成了目录的自动生成,那我就来直接演示如何去除自动生成目录后烦人的目录内容控件吧 直接上图片
- Docker安装运行Portainer
基本简介 Portainer是一个轻量级的docker环境管理UI,可以用来管理docker宿主机和docker swarm集群.他的轻量级,轻量到只要个不到100M的docker镜像容器就可以完整的 ...
- 22、lnmp_nginx反向代理(负载均衡)、高可用
负载均衡,根据ip和端口号找到相应的web服务器站点(即端口区分): 22.1.nginx的负载均衡: 1.介绍: 网站的访问量越来越大,服务器的服务模式也得进行相应的升级,比如分离出数据库服务器.分 ...
- AcWing 828. 模拟栈
实现一个栈,栈初始为空,支持四种操作: (1) "push x" – 向栈顶插入一个数x: (2) "pop" – 从栈顶弹出一个数: (3) "em ...