个人作业2-6.4-Python爬取顶会信息
1、个人作业2
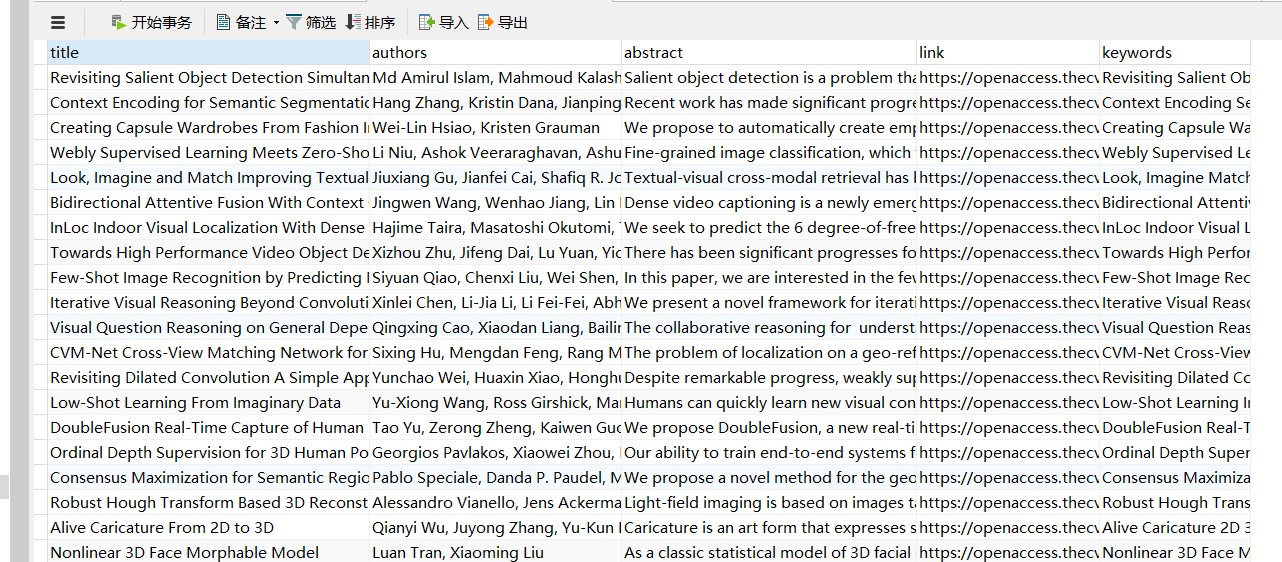
数据爬取阶段
import requests
from lxml import etree
import pymysql
def getdata(url):
# 请求CVPR主页
page_text = requests.get(url).text
parser = etree.HTMLParser(encoding="utf-8")
tree = etree.HTML(page_text, parser=parser)
#html
# 爬取论文连接
hrefs = tree.xpath('//dt[@class="ptitle"]/a/@href')
print(len(hrefs))
# 爬取论文信息
titles = []
pdfs = []
abstracts = []
authors = []
keywords = []
for href in hrefs:
db = pymysql.connect(host="127.0.0.1", user="root", password="lin0613",
database="users")
href = "https://openaccess.thecvf.com/" + href
page_text = requests.get(href).text
tree_link = etree.HTML(page_text, parser=parser)
title = tree_link.xpath('/html/body/div/dl/dd/div[@id="papertitle"]/text()')
title[0] = title[0].strip()
titles += title
title[0] = title[0].replace(":", "")
words = title[0].split()
keyword = ""
for word in words:
if checkword(word):
save_keywords(pymysql.connect(host="127.0.0.1", user="root", password="lin0613",database="users"), word)
keyword += word + " "
keywords.append(keyword)
pdf = tree_link.xpath('/html/body/div/dl/dd/a[contains(text(),"pdf")]/@href')
pdf[0] = pdf[0].replace("../../", "https://openaccess.thecvf.com/")
pdfs += pdf
abstract = tree_link.xpath('/html/body/div/dl/dd/div[@id="abstract"]/text()')
abstract[0] = abstract[0].strip()
abstracts += abstract
author = tree_link.xpath('/html/body/div/dl/dd/div/b/i/text()')
authors += author
# print(title)
# print(author)
# print(pdf)
# print(abstract)
save(db, title[0], author[0], abstract[0], href, keyword)
print(titles)
print(hrefs)
print(authors)
print(abstracts)
print(pdfs)
def save(db, title, author, abstract, link, keyword):
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 插入语句
sql = "INSERT INTO papers(title, authors, abstract_text, original_link, keywords) \
VALUES ('%s', '%s', '%s', '%s', '%s')" % \
(title, author, abstract, link, keyword)
try:
# 执行sql语句
cursor.execute(sql)
print("true")
# 执行sql语句
db.commit()
except:
print("error wenzhang")
# 发生错误时回滚
db.rollback()
# 关闭数据库连接
db.close()
def save_keywords(db, keyword):
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 插入语句
sql = "INSERT INTO keywords(keyword) VALUES ('%s')" % (keyword)
try:
# 执行sql语句
cursor.execute(sql)
# 执行sql语句
print("true")
db.commit()
except:
print("error word")
# 发生错误时回滚
db.rollback()
# 关闭数据库连接
db.close()
def checkword(word):
invalid_words = ['the', 'a', 'an', 'and', 'by', 'of', 'in', 'on', 'is', 'to', "as", "from", "for", "with", "that",
"have", "by", "on", "upon", "about", "above", "across", "among", "ahead", "after", "a",
"analthough", "at", "also", "along", "around", "always", "away", "anyup", "under", "untilbefore",
"between", "beyond", "behind", "because", "what", "when", "would", "could", "who", "whom", "whose",
"which", "where", "why", "without", "whether", "down", "during", "despite", "over", "off", "only",
"other", "out", "than", "the", "thenthrough", "throughout", "that", "these", "this", "those",
"there", "therefore", "some", "such", "since", "so", "can", "many", "much", "more", "may", "might",
"must", "ever", "even", "every", "each" ,"with","A","With","From"]
if word.lower() in invalid_words:
return False
else:
return True
if __name__ == '__main__':
#getdata("https://openaccess.thecvf.com/CVPR2018?day=2018-06-20")
getdata("https://openaccess.thecvf.com/CVPR2018?day=2018-06-21")
getdata("https://openaccess.thecvf.com/CVPR2019?day=2019-06-18")
#getdata("https://openaccess.thecvf.com/CVPR2019?day=2019-06-19")
#getdata("https://openaccess.thecvf.com/CVPR2019?day=2019-06-20")
getdata("https://openaccess.thecvf.com/CVPR2020?day=2020-06-16")
#getdata("https://openaccess.thecvf.com/CVPR2020?day=2020-06-17")
#getdata("https://openaccess.thecvf.com/CVPR2020?day=2020-06-18")
#getdata("https://openaccess.thecvf.com/CVPR2018?day=2018-06-19")
个人作业2-6.4-Python爬取顶会信息的更多相关文章
- Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label 页面显示如下: 在Chrome浏览器中审查元素,找到对应的链接: 然后 ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
- Python 爬取美团酒店信息
事由:近期和朋友聊天,聊到黄山酒店事情,需要了解一下黄山的酒店情况,然后就想着用python 爬一些数据出来,做个参考 主要思路:通过查找,基本思路清晰,目标明确,仅仅爬取美团莫一地区的酒店信息,不过 ...
- python 爬取豆瓣书籍信息
继爬取 猫眼电影TOP100榜单 之后,再来爬一下豆瓣的书籍信息(主要是书的信息,评分及占比,评论并未爬取).原创,转载请联系我. 需求:爬取豆瓣某类型标签下的所有书籍的详细信息及评分 语言:pyth ...
- python爬取电影网站信息
一.爬取前提1)本地安装了mysql数据库 5.6版本2)安装了Python 2.7 二.爬取内容 电影名称.电影简介.电影图片.电影下载链接 三.爬取逻辑1)进入电影网列表页, 针对列表的html内 ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- python爬取梦幻西游召唤兽资质信息(不包含变异)
一.分析 1.爬取网站:https://xyq.163.com/chongwu/ 2.获取网页源码: request.get("https://xyq.163.com/chongwu/&qu ...
- python 爬取bilibili 视频信息
抓包时发现子菜单请求数据时一般需要rid,但的确存在一些如游戏->游戏赛事不使用rid,对于这种未进行处理,此外rid一般在主菜单的响应中,但有的如番剧这种,rid在子菜单的url中,此外返回的 ...
- python爬取网业信息案例
需求:爬取网站上的公司信息 代码如下: import json import os import shutil import requests import re import time reques ...
随机推荐
- yarn 过程中遇到的问题
场景 项目中打包遇到了点问题,所以想删除原先装好的依赖包,重新yarn,结果神奇的报错了,无语... 遇到的问题 (1)error An unexpected error occurred: &quo ...
- SHARPENING (HIGHPASS) SPATIAL FILTERS
目录 Laplacian UNSHARP MASKING AND HIGHBOOST FILTERING First-Order Derivatives Roberts cross-gradient ...
- Proximal Algorithms 7 Examples and Applications
目录 LASSO proximal gradient method ADMM 矩阵分解 ADMM算法 多时期股票交易 随机最优 Robust and risk-averse optimization ...
- 【ElasticSearch】异常 Request cannot be executed; I/O reactor status: STOPPED
Caused by: java.lang.RuntimeException: Request cannot be executed; I/O reactor status: STOPPED at or ...
- Java基础(八)——IO流5_其他流
一.其他 1.System.in.System.out(标准输入.输出流) System.in:标准的输入流,默认从键盘输入. System.out:标准的输出流,默认从控制台输出. 改变标准输入输出 ...
- Eclipse启动SpringCloud微服务集群的方法
1.说明 下面这篇文章介绍了Eureka Server集群的启动方法, SpringCloud创建Eureka模块集群 是通过jar包启动时指定配置文件的方式实现的. 现在只有Eureka Serve ...
- 解决windows update失败,正在还原的问题
其实这个不算问题,等上几个小时,还原完毕就好了,不过也有快速解决的办法. 所需工具:U盘.光盘等可以进入PE系统的工具,dism++软件 1.下载dism++工具,根据你的系统,选择使用32位还是64 ...
- Ubuntu18.04编译Fuchsia
编译环境 系统:Ubuntu 18.04.1 LTS 64-bit 内存:8 GiB CPU:Intel Core i5-4200M CPU @ 2.50GHz × 4 1.安装编译环境 sudo a ...
- JavaScript 钩子
<!DOCTYPE html> <html> <head> <meta charset="utf-8"/> <script s ...
- python 中的省略号
在查看django源码时遇到下列内容:sweat: 这个省略号是什么意思? 来自为知笔记(Wiz)