使用并行Foreach优化SqlSugarMapper
最近在迁移公司导入导出项目时,发现导出速度特别慢,大概2K数据需要导出近半个小时,通过在程序各个地方埋点,最终定位到了Sqlsugar的Mapper中,随后通过并行Foreach单独抽出Mapper中的业务方法,性能提升近30倍,当然,此属于个人总结可能并不适用于读者业务逻辑,最重要的一点:业务上优化远比技术层面优化要来得快,效率更高!
有性能瓶颈吗?
SqlSugar的Mapper经过打印日志发现,即使mapper中的执行是串行的,在内存中处理数据速度也是非常快的,但是当在mapper中有些耗时操作时,数据量越大处理时间便成线性增长。
例如在此导出业务中,有涉及到手机号码加解密的逻辑,因为解密耗时将近0.5秒,所以导出1000条数据的时候,光手机号码处理就需要耗时500秒,此间还没法做其他操作,所以我认定性能瓶颈在Sqlsugar的Mapper上,准备从此处开刀。
定位问题所在
秉着大胆猜想,小心求证的原则,
既然猜想问题是处在Mapper上,先上代码。
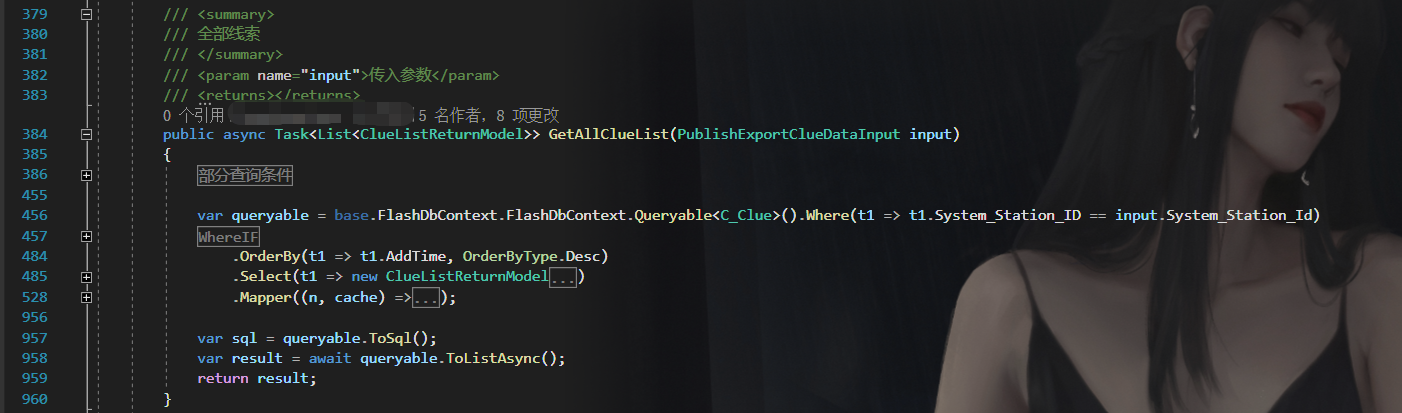
这是一个非常复杂的数据查询,从行号即可看到,此方法有近600行代码,给他稍微整理一下,这个查询结构如下:
var aList = await DbContext.Queryable<TableA>().Where(x => x.code == input.Acode).ToList();
var bList = ...
var cList = ...
......
var queryable = DBContext.Queryable<TableMaster>().Where(x => x.SystemId == input.SystemId)
.WhereIF(!input.Phone.IsNullOrWhiteSpace(), x => x.Phone == input.Phone.Trim().Encrypt())
.WhereIF(input.Acode>0),x => aList.Contains(x.Acode))
.WhereIF(input.Bcode>0),x => bList.Contains(x.Bcode))
......
.OrderBy(x => x.CreateTime, OrderByType.Desc)
.Select(x => new RetrunListModel
{
ID = x.Id,
SystemId = x.SystemId,
Phone = x.Phone,
Acode = x.Acode,
Bcode = x.Bcode,
......
})
.Mapper((model, cache) =>
{
// 类型一:查询中间表赋值
// 使用Master表查询结果中的ACode,从A表中的Name查询数来
var aList = cache.Get(h =>
{
var aCodeList = h.Where(x => x.ACode > 0).Select(x => x.ACode).Distinct().ToList();
return DbContext.Queryable<TableA>().Where(x => x.SystemId == input.SystemId)
.Where(x => aCodeList.Contains(x.ACode))
.Select(x => new TableA
{
Id = x.Id,
Name = x.Name,
}).ToList();
}
// 将查询的结果赋值给model,即最终的接收结果
model.AName = aCodeList.Where(x => x.Id == n.ACode).FirstOrDefault()?.Name ?? "";
// 类型二:对数据解密
if(input.IsDecrypt)
{
model.Phone = xxxService.DecryptPhone(model.Phone)
}
......
});
直接看向Mapper,在这里的业务有两种类型:
- 第一种类型,通过从表去对查询结果中的字段赋值,这里只会在第一次查询从表有耗时操作,因为他会在查询子表后,将结果存在缓存中,即aList,后续取值都从缓存中取,故后续基本无需耗时。
- 第二种类型,对查询结果的某一字段进行处理,例如加解密,这里调用的是解密方法,故每次都是需要将该字段传递至解密服务中,因此每次都需耗时去解密,所以性能瓶颈卡在这里。
干说可能不好懂,画了张图
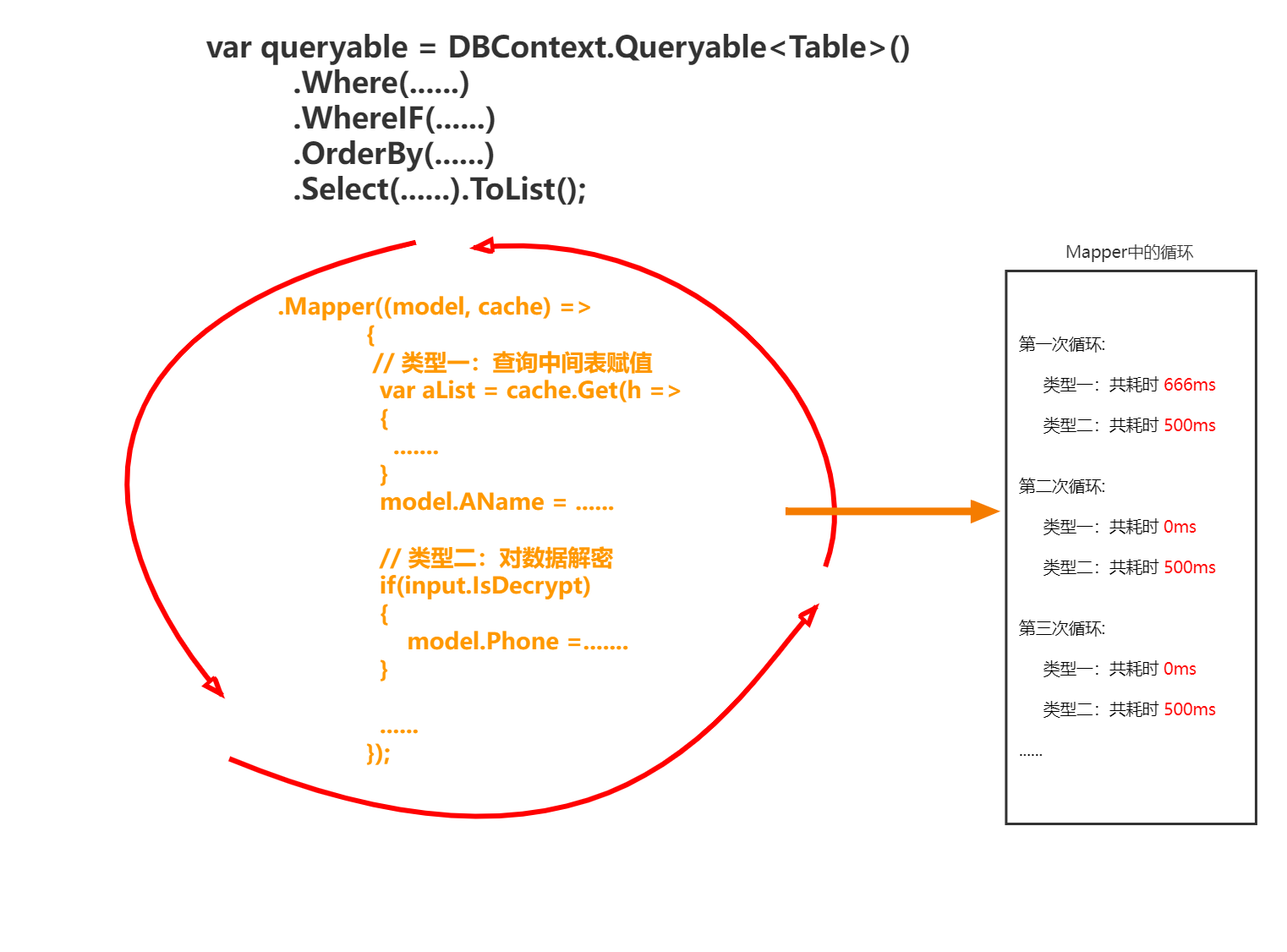
并行Foreach
很显然从上图可以看出,由于循环解密需要耗时较长,就算把Mapper单独抽出来,还是需要循环去将字段解密,看起来无解,但是这里可以是使用并行foreach去处理的,也可以用多线程这里不做展开,但是再次给读者提个醒,业务上去做优化远比技术上优化来的快,效率更高!
认识并行库
.Net Framework4 引入了新的Task Parallel Library(任务并行库,TPL),它支持数据并行、任务并行和流水线。
当并行循环运行时,TPL会将数据源按照内置的分区算法(或者你可以自定义一个分区算法)将数据划分为多个不相交的子集,然后,从线程池中选择线程并行地处理这些数据子集,每个线程只负责处理一个数据子集。在后台,任务计划程序将根据系统资源和工作负荷来对任务进行分区。如有可能,计划程序会在工作负荷变得不平衡的情况下在多个线程和处理器之间重新分配工作。
在对任何代码(包括循环)进行并行化时,一个重要的目标是利用尽可能多的处理器,但不要过度并行化到使行处理的开销让任何性能优势消耗殆尽的程度。比如:对于嵌套循环,只会对外部循环进行并行化,原因是不会在内部循环中执行太多工作。少量工作和不良缓存影响的组合可能会导致嵌套并行循环的性能降低。
由于循环体是并行运行的,迭代范围的分区是根据可用的逻辑内核数、分区大小以及其他因素动态变化的,因此无法保证迭代的执行顺序。
TPL引入了System.Threading.Tasks ,主类是Task,这个类表示一个异步的并发的操作,然而我们不一定要使用Task类的实例,可以使用Parallel静态类。
它提供了Parallel.Invoke, Parallel.For,Parallel.Forecah 三个方法
当然此处是我读了《.net 并发编程实战》,大神博客以及官方文档,稍微总结的,后文贴上链接,他们文章更详细。
上代码
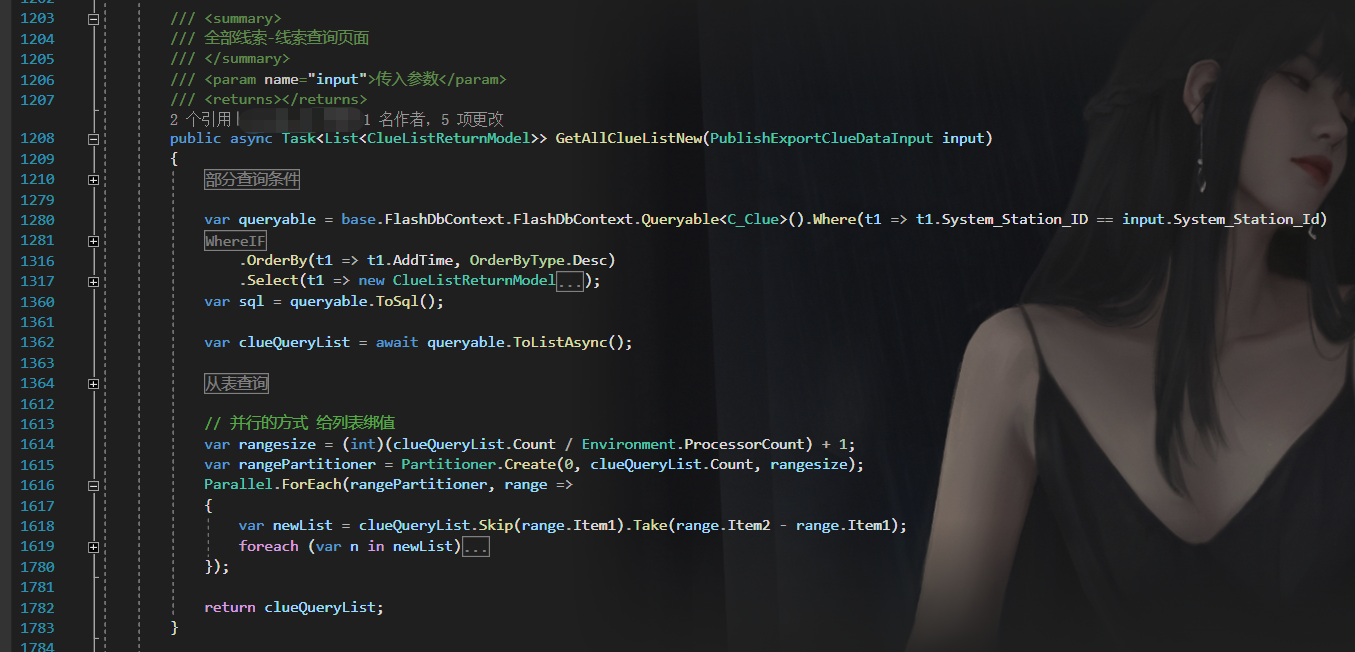
这里的思路就是,先将结果查询出出来,然后将之前的从表查询以及字段赋值处理,单独抽出来通过并行Foreach的方式,快速处理加解密这类耗时操作。
var aList = await DbContext.Queryable<TableA>().Where(x => x.code == input.Acode).ToList();
var bList = ...
var cList = ...
......
var queryable =await DBContext.Queryable<TableMaster>().Where(x => x.SystemId == input.SystemId)
.WhereIF(!input.Phone.IsNullOrWhiteSpace(), x => x.Phone == input.Phone.Trim().Encrypt())
.WhereIF(input.Acode>0),x => aList.Contains(x.Acode))
.WhereIF(input.Bcode>0),x => bList.Contains(x.Bcode))
......
.OrderBy(x => x.CreateTime, OrderByType.Desc)
.Select(x => new RetrunListModel
{
ID = x.Id,
SystemId = x.SystemId,
Phone = x.Phone,
Acode = x.Acode,
Bcode = x.Bcode,
......
}).ToListAsync();
var aCodeList = h.Where(x => x.ACode > 0).Select(x => x.ACode).Distinct().ToList();
var aList = DbContext.Queryable<TableA>().Where(x => x.SystemId == input.SystemId)
.Where(x => aCodeList.Contains(x.ACode))
.Select(x => new TableA
{
Id = x.Id,
Name = x.Name,
}).ToList();
......
// 并行的方式 给列表绑值
var rangesize = (int)(clueQueryList.Count / Environment.ProcessorCount) + 1;
var rangePartitioner = Partitioner.Create(0, clueQueryList.Count, rangesize);
Parallel.ForEach(rangePartitioner, range =>
{
var newList = clueQueryList.Skip(range.Item1).Take(range.Item2 - range.Item1);
foreach (var model in newList)
{
// 字段赋值
model.AName = aList.Where(x => x.Id == n.ACode).FirstOrDefault()?.Name ?? "";
// 手机号码加解密
model.Phone = xxxService.DecryptPhone(model.Phone)
......
}
});
return clueQueryList;
- 看到并行部分,在将sqlsugar的Mapper抽出来之后,这里使用并行的foreach去处理查询结果,包括字段赋值,耗时更长的加解密操作。
- 这里是使用并行foreach与分区器,将需要操作的数据按照逻辑处理器分成指定的块,然后再并行处理数据,于是可以完全发挥出多核处理器的优势。
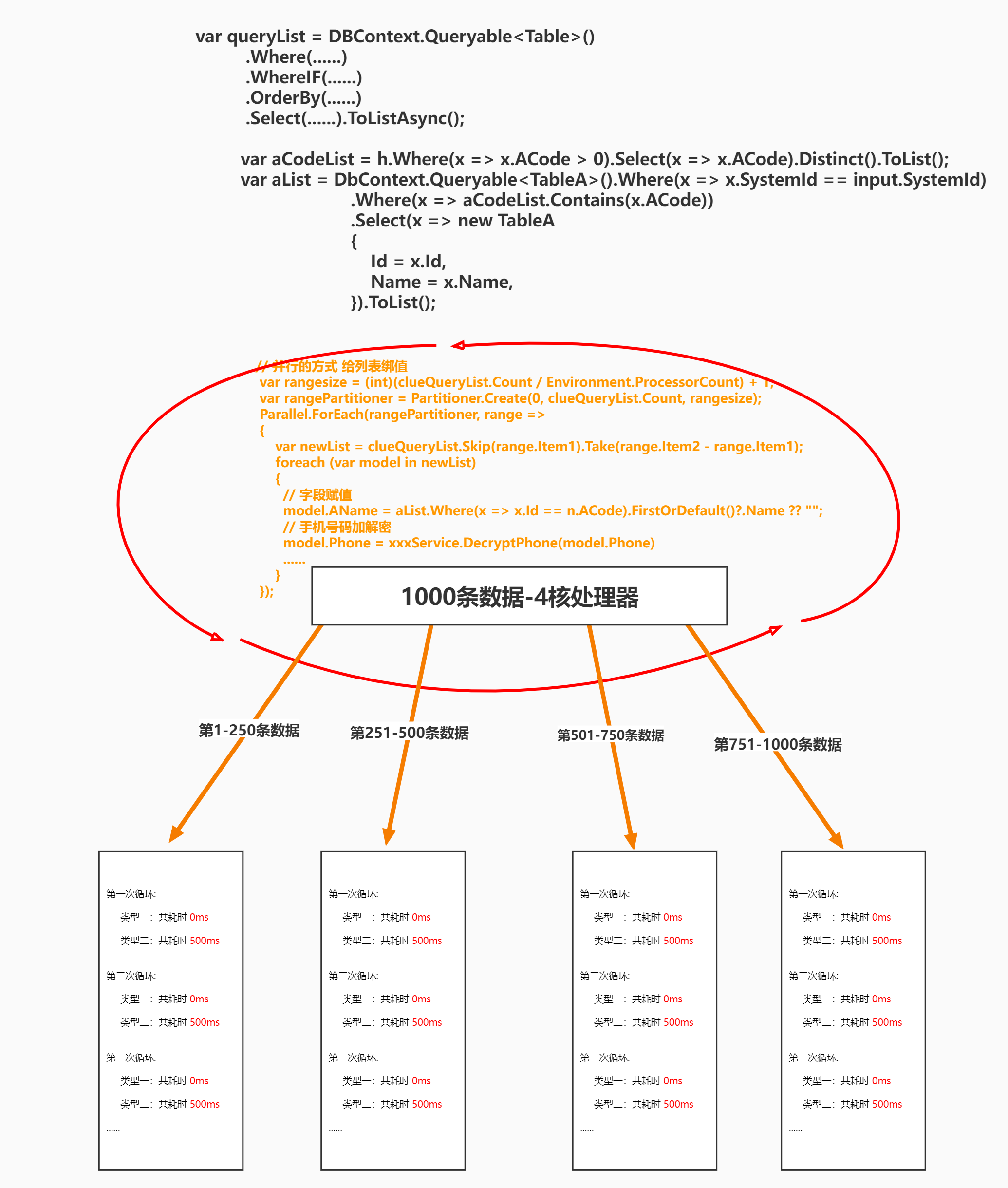
这样通过数据分块之后,并行处理,效率会成倍数上升,并且微软的并行库(TPL)也针对并行foreach做了许多优化,TPL在幕后使用的负载均衡机制都是非常高效的,比如我们不使用分区器,直接对数据源进行负载均衡的并行执行,这里推荐一个博客,指定最大并行度:https://www.cnblogs.com/QinQouShui/p/12134232.html
System.Threading.Tasks.Parallel.ForEach(list, new ParallelOptions() { MaxDegreeOfParallelism = 12 }, range =>
{
#region 业务代码
#endregion
});
优化效果
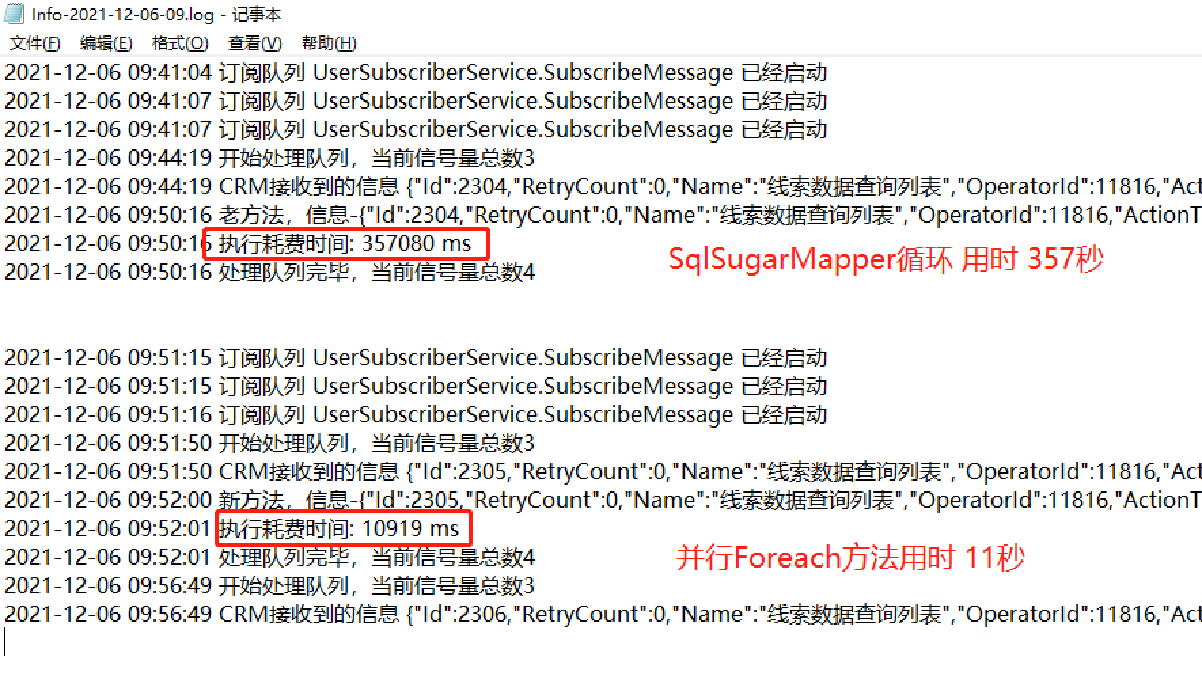
测试用的服务器是八核,前后两次导出3500条数据,使用SQLSugarMapper与并行Foreach对比速度
总结
大致总结一下几点
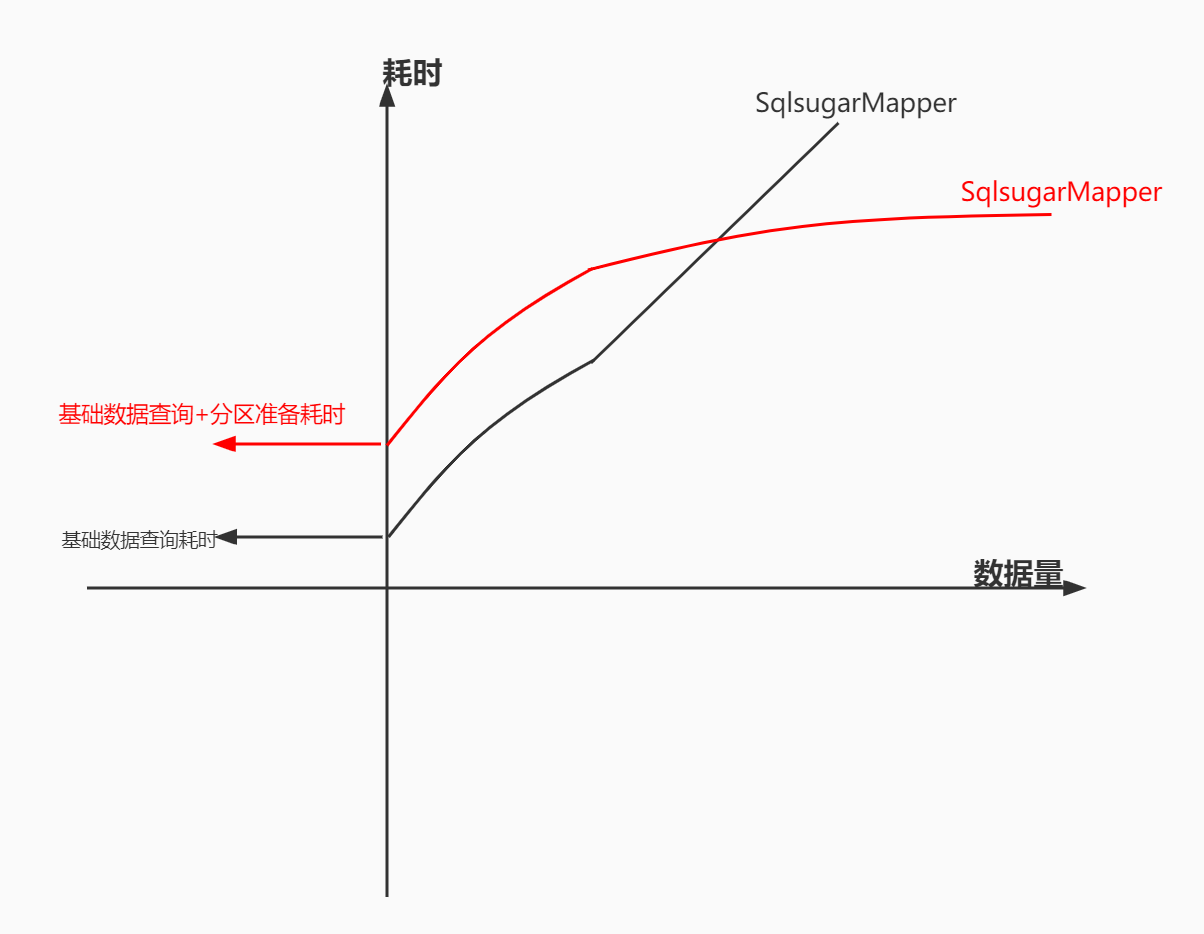
- 分区器+并行foreach不是银弹,数据量较大时,他的优势才能弥补分区所消耗的资源与时间。
- 逻辑处理越多,多核处理优势越大
- 并行处理需要解决多个并行任务处理同一条数据的情况,此文是使用分区器隔离
参考资料
【书籍】《.net并发编程实战》
【官方文档】《.NET 中的并行编程》https://docs.microsoft.com/zh-cn/dotnet/standard/parallel-programming/
【博客园】《.Net并行编程高级教程--Parallel》https://www.cnblogs.com/stoneniqiu/p/4857021.html
【博客园】《8天玩转并发》
https://www.cnblogs.com/huangxincheng/category/368987.html
【博客园】《异步编程:.NET4.X 数据并行》
https://www.cnblogs.com/heyuquan/archive/2013/03/13/parallel-for-foreach-invoke.html
【博客园】《Parallel.ForEach 之 MaxDegreeOfParallelism》
https://www.cnblogs.com/QinQouShui/p/12134232.html
【自己总结】《如何运用并行编程Parallel提升任务执行效率》https://mp.weixin.qq.com/s/3qli3cM9ZLweG9aj-nYdBw
使用并行Foreach优化SqlSugarMapper的更多相关文章
- NET中并行开发优化
NET中并行开发优化 让我们考虑一个简单的编程挑战:对大数组中的所有元素求和.现在可以通过使用并行性来轻松优化这一点,特别是对于具有数千或数百万个元素的巨大阵列,还有理由认为,并行处理时间应该与常规时 ...
- 关于 SSIS 并行foreach loop的一个设计思路
SSIS 包在控制流方面的性能优化,主要是提高并行度. 可以设置并发线程数MaxConcurrentExecuteables. SSIS中的foreach loop container 不是并行执行任 ...
- 【58沈剑架构系列】mysql并行复制优化思路
一.缘起 mysql主从复制,读写分离是互联网用的非常多的mysql架构,主从复制最令人诟病的地方就是,在数据量较大并发量较大的场景下,主从延时会比较严重. 为什么mysql主从延时这么大? 回答:从 ...
- .Net中的并行编程-6.常用优化策略
本文是.Net中的并行编程第六篇,今天就介绍一些我在实际项目中的一些常用优化策略. 一.避免线程之间共享数据 避免线程之间共享数据主要是因为锁的问题,无论什么粒度的锁 ...
- Parallel.ForEach() 并行循环
现在的电脑几乎都是多核的,但在软件中并还没有跟上这个节奏,大多数软件还是采用传统的方式,并没有很好的发挥多核的优势. 微软的并行运算平台(Microsoft’s Parallel Computing ...
- Java 进阶7 并发优化 1 并行程序的设计模式
本章重点介绍的是基于 Java并行程序开发以及优化的方法,对于多核的 CPU,传统的串行程序已经很好的发回了 CPU性能,此时如果想进一步提高程序的性能,就应该使用多线程并行的方式挖掘 CPU的 ...
- java-11-Stream优化并行流
并行流 多线程 把一个内容分成多个数据块 不同线程分别处理每个数据块的流 串行流 单线程 一个线程处理所有数据 java8 对并行流优化 StreamAPI 通过pa ...
- [源码解析] PyTorch分布式优化器(2)----数据并行优化器
[源码解析] PyTorch分布式优化器(2)----数据并行优化器 目录 [源码解析] PyTorch分布式优化器(2)----数据并行优化器 0x00 摘要 0x01 前文回顾 0x02 DP 之 ...
- [源码解析] PyTorch分布式优化器(3)---- 模型并行
[源码解析] PyTorch分布式优化器(3)---- 模型并行 目录 [源码解析] PyTorch分布式优化器(3)---- 模型并行 0x00 摘要 0x01 前文回顾 0x02 单机模型 2.1 ...
随机推荐
- Gradle入门及SpringBoot项目构建
https://blog.csdn.net/qq_27520051/article/details/90384483 一.介绍 Gradle 是一种构建工具,它抛弃了基于XML的构建脚本,取而代之的是 ...
- 文件管理与XMl、JSON解析
1.使用内部存储器 你可以直接保存文件在设备的内部存储.默认情况下,文件保存在你的应用程序的内部存储,其他应用程序或用户不能访问.当用户卸载你的应用城西是,这些文件被删除. (一)在内部存储创建并写入 ...
- 【Java 8】Stream.distinct() 列表去重示例
在这篇文章里,我们将提供Java8 Stream distinct()示例. distinct()返回由该流的不同元素组成的流.distinct()是Stream接口的方法. distinct()使用 ...
- java 整型
byte(1字节).short(2字节).int(4字节).long(16字节) java中前缀加上0b或者0B就可以写二进制数,前缀加上0就可以写八进制数,前缀加上0x或者0X就可以写十六进制数 一 ...
- 【Linux】【CentOS】【FTP】FTP服务器安装与配置(vsftpd、lftp)
[初次学习.配置的笔记,如有不当,欢迎在评论区纠正 -- 萌狼蓝天 @ 2021-12-02] 基本概念 FTP访问方式 实体账号:本地账户 来宾账户:guest 匿名登录:anonymous fp ...
- 记一次SQL Server insert触发器操作
需求:在河道水情表(ST_RIVER_R )新增插入数据时,更新实时数据表(SS_data) 中关联字段的值. 需求概括下:当A表中新增数据时,同时更新B表中的某字段 代码如下: USE [DBCNB ...
- python实现skywalking邮件告警webhook接口
1.介绍 Skywalking可以对链路追踪到数据进行告警规则配置,例如响应时间.响应百分比等.发送警告通过调用webhook接口完成.webhook接口用户可以自定义. 2.默认告警规则 告警配置文 ...
- windows下安装linux虚拟机(wsl2),并安装docker。
一.windows terminal(重要工具,但也可以不装) 这是微软官方推荐的终端工具,类似mac的iterm2,可同时开启多个终端,最开始默认有power shall,cmd,可下载gsudo集 ...
- pipeline when指令
目录 一.简介 二.选项 单独判断 条件组合 一.简介 when指令允许pipeline根据给定的条件,决定是否执行阶段内的步骤.when指令必须至少包含一个条件.when指令除了支持branch判断 ...
- ciscn_2019_n_8 1
拿到题目老样子先判断是多少位的程序 可以看到是32位的程序,然后再查看开启的保护 然后将程序放入ida进行汇编 先shift+f12查看程序是否有system和binsh 可以看到有system和bi ...