【LeetCode】116. 填充每个节点的下一个右侧节点指针 Populating Next Right Pointers in Each Node 解题报告(Python)
- 作者: 负雪明烛
- id: fuxuemingzhu
- 个人博客:http://fuxuemingzhu.cn/
题目地址:https://leetcode.com/problems/populating-next-right-pointers-in-each-node/description/
题目描述
给定一个完美二叉树,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例:
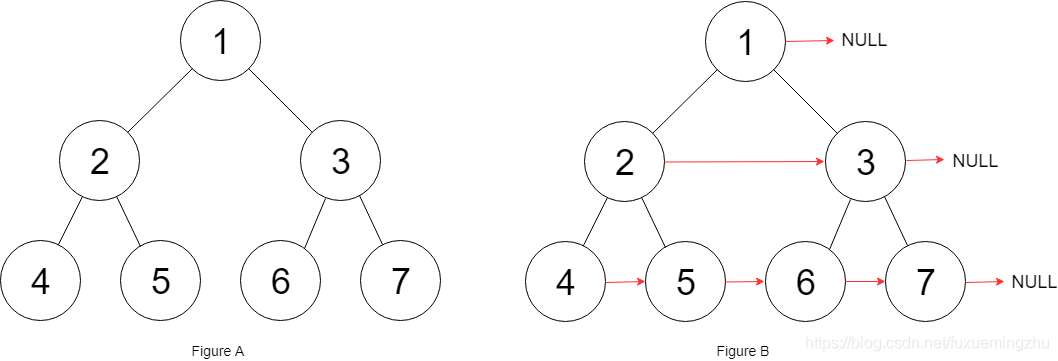
输入:{"$id":"1","left":{"$id":"2","left":{"$id":"3","left":null,"next":null,"right":null,"val":4},"next":null,"right":{"$id":"4","left":null,"next":null,"right":null,"val":5},"val":2},"next":null,"right":{"$id":"5","left":{"$id":"6","left":null,"next":null,"right":null,"val":6},"next":null,"right":{"$id":"7","left":null,"next":null,"right":null,"val":7},"val":3},"val":1}
输出:{"$id":"1","left":{"$id":"2","left":{"$id":"3","left":null,"next":{"$id":"4","left":null,"next":{"$id":"5","left":null,"next":{"$id":"6","left":null,"next":null,"right":null,"val":7},"right":null,"val":6},"right":null,"val":5},"right":null,"val":4},"next":{"$id":"7","left":{"$ref":"5"},"next":null,"right":{"$ref":"6"},"val":3},"right":{"$ref":"4"},"val":2},"next":null,"right":{"$ref":"7"},"val":1}
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。
提示:
- 你只能使用常量级额外空间。
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
题目大意
把一棵完全二叉树的每层节点之间顺序连接,形成单链表。
解题方法
递归
树的问题一般都可以用递归解决。这个题中,同样可以使用dfs解决。
注意题目已经声明了是完全二叉树,从根节点开始找到任意节点,将其左孩子指向右孩子。如果该节点已经指向了同层的其他节点,说明需要连接两个子树,比如例子中的2->3,那么不仅要把2的左孩子4指向右孩子5,还要把2的右孩子5指向2的next节点的左孩子6。这样递归完成了,每层就是单链表了。
发现一篇文章讲得很细:http://www.cnblogs.com/yrbbest/p/4437341.html
"""
# Definition for a Node.
class Node(object):
def __init__(self, val=0, left=None, right=None, next=None):
self.val = val
self.left = left
self.right = right
self.next = next
"""
class Solution(object):
def connect(self, root):
"""
:type root: Node
:rtype: Node
"""
if not root: return
if root.right:
root.left.next = root.right
if root.next:
root.right.next = root.next.left
self.connect(root.left)
self.connect(root.right)
return root
日期
2018 年 3 月 14 日 --霍金去世日
【LeetCode】116. 填充每个节点的下一个右侧节点指针 Populating Next Right Pointers in Each Node 解题报告(Python)的更多相关文章
- Java实现 LeetCode 116 填充每个节点的下一个右侧节点指针
116. 填充每个节点的下一个右侧节点指针 给定一个完美二叉树,其所有叶子节点都在同一层,每个父节点都有两个子节点.二叉树定义如下: struct Node { int val; Node *left ...
- [LeetCode] 116. 填充每个节点的下一个右侧节点指针
题目链接 : https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node/ 题目描述: 给定一个完美二叉树 ...
- Java实现 LeetCode 117 填充每个节点的下一个右侧节点指针 II(二)
117. 填充每个节点的下一个右侧节点指针 II 给定一个二叉树 struct Node { int val; Node *left; Node *right; Node *next; } 填充它的每 ...
- [leetcode-117]填充每个节点的下一个右侧节点指针 II
(1 AC) 填充每个节点的下一个右侧节点指针 I是完美二叉树.这个是任意二叉树 给定一个二叉树 struct Node { int val; Node *left; Node *right; Nod ...
- LeetCode OJ:Populating Next Right Pointers in Each Node II(指出每一个节点的下一个右侧节点II)
Follow up for problem "Populating Next Right Pointers in Each Node". What if the given tre ...
- leetcode 117. 填充每个节点的下一个右侧节点指针 II(二叉树,DFS)
题目链接 https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node-ii/ 题目大意 给定一个二叉树 s ...
- 117. 填充每个节点的下一个右侧节点指针 II
Q: 给定一个二叉树 struct Node { int val; Node *left; Node *right; Node *next; } 填充它的每个 next 指针,让这个指针指向其下一个右 ...
- leetcode117. 填充每个节点的下一个右侧节点指针 II
给定一个二叉树struct Node { int val; Node *left; Node *right; Node *next;}填充它的每个 next 指针,让这个指针指向其下一个右侧节 ...
- LeetCode: Populating Next Right Pointers in Each Node 解题报告
Populating Next Right Pointers in Each Node TotalGiven a binary tree struct TreeLinkNode { Tree ...
随机推荐
- Python爬虫3大解析库使用导航
1. Xpath解析库 2. BeautifulSoup解析库 3. PyQuery解析库
- 超好玩:使用 Erda 构建部署应用是什么体验?
作者|郑成 来源|尔达 Erda 公众号 导读:最近在 Erda 上体验了一下构建并部署一个应用,深感其 DevOps 平台的强大与敏捷,不过为了大家能够快速上手,我尽量简化应用程序,用一个简单的返回 ...
- 20. VIM命令操作技巧
V可视化选中当前行,根据光标可多行 ctrl+v 可视化块 v可视化根据光标 行间移动 快速增删改查 d 0 删除当前位置到行首 d $ 删除当前位置到行尾 d t (" ] ) )符号 ...
- Linux网络(网络模型和收发流程)
网络模型 为了解决网络互联中异构设备的兼容性问题,并解耦复杂的网络包处理流程,国际标准化组织制定的开放式系统互联通信参考模型(Open System Interconnection Reference ...
- Oracle参数文件—pfile与spfile
oracle的参数文件:pfile和spfile 1.pfile和spfile Oracle中的参数文件是一个包含一系列参数以及参数对应值的操作系统文件.它们是在数据库实例启动时候加载的, ...
- Rest使用get还是post
1. get是从服务器上获取数据,post是向服务器传送数据. 2. get是把参数数据队列加到提交表单的ACTION属性所指的URL中,值和表单内各个字段一一对应,在URL中可以看到.post是通过 ...
- ActiveRecord教程
(一.ActiveRecord基础) ActiveRecord是Rails提供的一个对象关系映射(ORM)层,从这篇开始,我们来了解Active Record的一些基础内容,连接数据库,映射表,访问数 ...
- 【Linux】【Services】【Docker】Docker File
Docker Images: docker commit Dockerfile:文本文件,镜像文件构建脚本: Dockerfile:由一系列用于根据基础镜像构建新的镜像文件的专用指令序列组成: 指令: ...
- elasticSearch索引库查询的相关方法
package com.hope.es;import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.c ...
- Solon 1.6.6 发布,细节打磨
Solon 已有120个生态扩展插件,此次更新主要为细节打磨: 增加 @Inject("ds1") BeanWrap bw 模式注入 @Configuration public c ...