源码级别理解 Redis 持久化机制
文章首发于公众号“蘑菇睡不着”,欢迎来访~
前言
大家都知道 Redis 是一个内存数据库,数据都存储在内存中,这也是 Redis 非常快的原因之一。虽然速度提上来了,但是如果数据一直放在内存中,是非常容易丢失的。比如 服务器关闭或宕机了,内存中的数据就木有了。为了解决这一问题,Redis 提供了 持久化 机制。分别是 RDB 以及 AOF 持久化。
RDB
什么是 RDB 持久化?
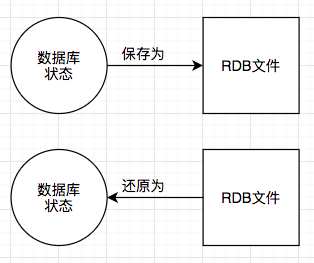
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
RDB 的优点?
- RDB 是一种表示某个即时点的 Redis 数据的紧凑文件。RDB 文件适用于备份。例如,你可能想要每小时归档最近24小时的 RDB 文件,每天保存近30天的 RDB 快照。这允许你很容易的恢复不同版本的数据集以容灾。
- RDB 非常适合于灾难恢复,作为一个紧凑的单一文件,可以被传输到远程的数据中心。
- RDB 最大化了 Redis 的性能。因为 Redis 父进程持久化时唯一需要做的是启动(fork)一个子进程,由子进程完成所有剩余的工作。父进程实例不需要执行像磁盘IO这样的操作。
- RDB 在重启保存了大数据集的实例比 AOF 快。
RDB 的缺点?
- 当你需要在Redis停止工作(例如停电)时最小化数据丢失,RDB可能不太好。你可以配置不同的保存点(save point)来保存RDB文件(例如,至少5分钟和对数据集100次写之后,但是你可以有多个保存点)。然而,你通常每隔5分钟或更久创建一个RDB快照,所以一旦Redis因为任何原因没有正确关闭而停止工作,你就得做好最近几分钟数据丢失的准备了。
- RDB需要经常调用fork()子进程来持久化到磁盘。如果数据集很大的话,fork()比较耗时,结果就是,当数据集非常大并且CPU性能不够强大的话,Redis会停止服务客户端几毫秒甚至一秒。AOF也需要fork(),但是你可以调整多久频率重写日志而不会有损(trade-off)持久性(durability)。
RDB 文件的创建与载入
有个两个 Redis 命令可以用于生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE。
SAVE 命令会阻塞 Redis 服务器进程,直到 RDB 文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求。
> SAVE // 一直等到 RDB 文件创建完毕
OK
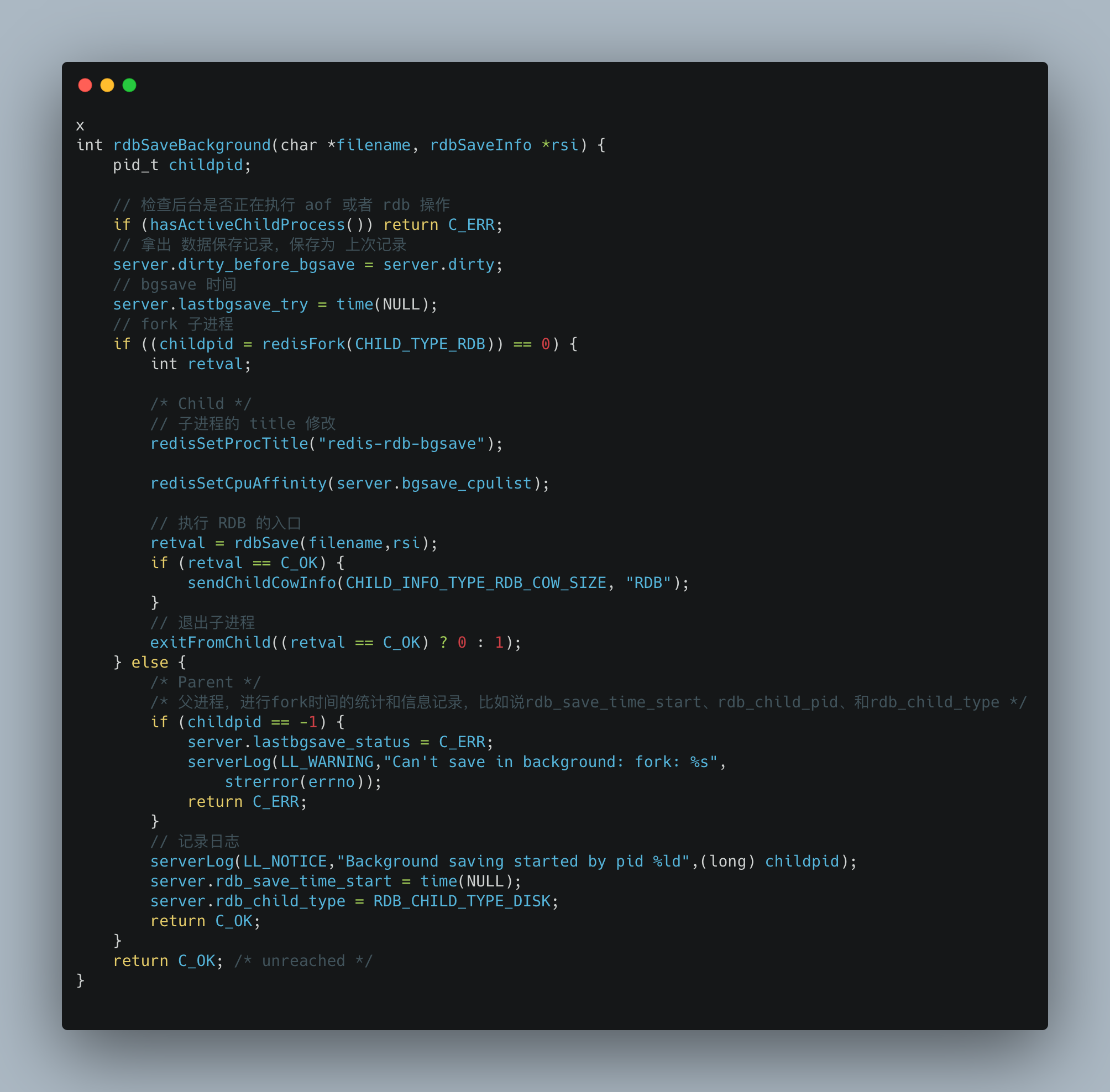
和 SAVE 命令直接阻塞服务器进程不同的是,BGSAVE 命令会派生出一个子进程,然后由子进程负责创建 RDB 文件,服务器进程(父进程)继续处理命令进程。
执行fork的时候操作系统(类Unix操作系统)会使用写时复制(copy-on-write)策略,即fork函数发生的一刻父子进程共享同一内存数据,当父进程要更改其中某片数据时(如执行一个写命令 ),操作系统会将该片数据复制一份以保证子进程的数据不受影响,所以新的RDB文件存储的是执行fork一刻的内存数据。
> BGSAVE // 派生子进程,并由子进程创建 RDB 文件
Background saving started
生成 RDB 文件由两种方式:一种是手动,就是上边介绍的用命令的方式;另一种是自动的方式。
接下来详细介绍一下自动生成 RDB 文件的流程。
Redis 允许用户通过设置服务器配置的 save 选项,让服务器每隔一段时间自动执行一次 BGSAVE 命令。
用户可以通过在 redis.conf 配置文件中的 SNAPSHOTTING 下 save 选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会执行 BGSAEVE 命令。
如,以下配置:
save 900 1
save 300 10
save 60 10000
上边三个配置的含义是:
- 服务器在 900 秒内,对数据库进行了至少 1 次修改。
- 服务器在 300 秒内,对数据库进行了至少 10 次修改。
- 服务器在 60 秒内,对数据库进行了至少 10000 次修改。
如果没有手动去配置 save 选项,那么服务器会为 save 选项配置默认参数:
save 900 1
save 300 10
save 60 10000
接着,服务器就会根据 save 选项的配置,去设置服务器状态 redisServer 结构的 saveparams 属性:
struct redisServer{
// ...
// 记录了保存条件的数组
struct saveparams *saveparams;
// ...
};
saveparams 属性是一个数组,数组中的每一个元素都是一个 saveparam 结构,每个 saveparam 结构都保存了一个 save 选项设置的保存条件:
struct saveparam {
// 秒数
time_t seconds;
// 修改数
int changes;
};
除了 saveparams 数组之外,服务器状态还维持着一个 dirty 计数器,以及一个 lastsave 属性;
struct redisServer {
// ...
// 修改计数器
long long dirty;
// 上一次执行保存时间
time_t lastsave;
// ...
}
- dirty 计数器记录距离上一次成功执行 SAVE 或 BGSAVE 命令之后,服务器对数据库状态(服务器中的所有数据库)进行了多少次修改(包括写入、删除、更新等操作)。
- lastsave 属性是一个 UNIX 时间戳,记录了服务器上一次执行 SAVE 或 BGSAVE 命令的时间。
检查条件是否满足触发 RDB
Redis 的服务器周期性操作函数 serverCron 默认每隔 100 毫秒执行一次,该函数用于对正在运行的服务器进行维护,它的其中一项工作就是检查 save 选项所设置的保存条件是否已经满足,如果满足的话就执行 BGSAVE 命令。
Redis serverCron 源码解析如下:
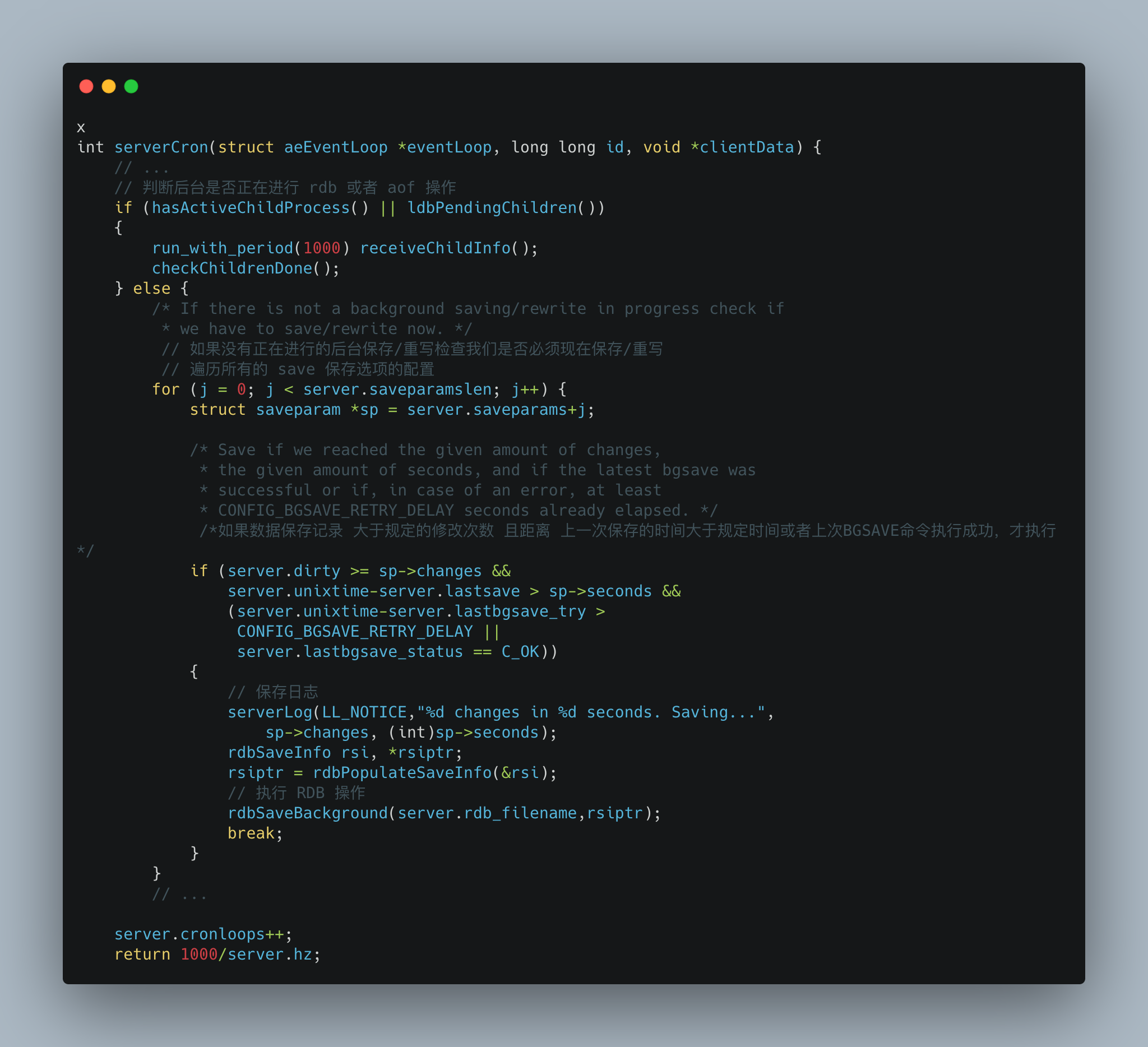
程序会遍历并检查 saveparams 数组中的所有保存条件,只要有任意一个条件被满足,服务器就会执行 BGSAVE 命令。
下面是 rdbSaveBackground 的源码流程:
RDB 文件结构
下图展示了一个完整 RDB 文件所包含的各个部分。

redis 文件的最开头是 REDIS 部分,这个部分的长度是 5 字节,保存着 “REDIS” 五个字符。通过这五个字符,程序可以在载入文件时,快速检查所载入的文件是否时 RDB 文件。
db_version 长度为 4 字节,他的值时一个字符串表示的整数,这个整数记录了 RDB 文件的版本号,比如 “0006” 就代表 RDB 文件的版本为第六版。
database 部分包含着零个或任意多个数据库,以及各个数据库中的键值对数据:
- 如果服务器的数据库状态为空(所有数据库都是空的),那么这个部分也为空,长度为 0 字节。
- 如果服务器的数据库状态为非空(有至少一个数据库非空),那么这个部分也为非空,根据数据库所保存键值对的数量、类型和内容不同,这个部分的长度也会有所不同。
EOF 常量的长度为 1 字节,这个常量标志着 RDB 文件正文内容的结束,当读入程序遇到这个值后,他知道所有数据库的所有键值对已经载入完毕了。
check_sum 是一个 8 字节长的无符号整数,保存着一个校验和,这个校验和时程序通过对 REDIS、db_version、database、EOF 四个部分的内容进行计算得出的。服务器在载入 RDB 文件时,会将载入数据所计算出的校验和与 check_sum 所记录的校验和进行对比,以此来检查 RDB 是否有出错或者损坏的情况。
举个例子:下图是一个 0 号数据库和 3 号数据库的 RDB 文件。第一个就是 “REDIS” 表示是一个 RDB 文件,之后的 “0006” 表示这是第六版的 REDIS 文件,然后是两个数据库,之后就是 EOF 结束标识符,最后就是 check_sum。

AOF 持久化
什么是 AOF 持久化
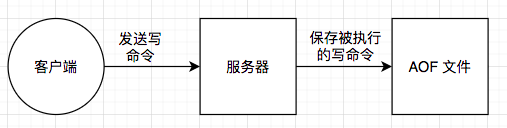
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大.
AOF 的优点?
- 使用AOF 会让你的Redis更加耐久: 你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据.
- AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题.
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点?
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
AOF持久化的实现
AOF持久化功能的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤。
命令追加
当 AOF 持久化功能处于打开状态时,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的 aof_buf 缓冲区的末尾。
struct redisServer {
// ...
// AOF 缓冲区
sds aof_buf;
// ..
};
如果客户端向服务器发送以下命令:
> set KEY VALUE
OK
那么服务器在执行这个 set 命令之后,会将以下协议内容追加到 aof_buf 缓冲区的末尾;
*3\r\n$3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVALUE\r\n
AOF 文件的写入与同步
Redis的服务器进程就是一个事件循环(loop),这个循环中的文件事件负责接收客户端
的命令请求,以及向客户端发送命令回复,而时间事件则负责执行像 serverCron 函数这样需
要定时运行的函数。
因为服务器在处理文件事件时可能会执行写命令,使得一些内容被追加到aof_buf缓冲区
里面,所以在服务器每次结束一个事件循环之前,它都会调用 flushAppendOnlyFile 函数,考
虑是否需要将aof_buf缓冲区中的内容写入和保存到AOF文件里面,这个过程可以用以下伪代
码表示:
def eventLoop():
while True:
#处理文件事件,接收命令请求以及发送命令回复
#处理命令请求时可能会有新内容被追加到 aof_buf缓冲区中
processFileEvents()
#处理时间事件
processTimeEvents()
#考虑是否要将 aof_buf中的内容写入和保存到 AOF文件里面
flushAppendOnlyFile()
flushAppendOnlyFile函数的行为由服务器配置的 appendfsync 选项的值来决定,各个不同
值产生的行为如下表所示。
| appendfsync 选项的值 | flushAppendOnlyFile 函数的行为 |
|---|---|
| always | 将 aof_buf 缓冲区中的所有内容写入并同步到 AOF 文件 |
| everysec | 将 aof_buf 缓冲区中的所有内容写入到 AOF 文件,如果上次同步 AOF 文件的时间距离现在超过一秒钟,那么再次对 AOF 文件进行同步,并且这个同步操作是由一个线程专门负责执行的 |
| no | 将 aof_buf 缓冲区中的所有内容写入到 AOF 文件,但并不对 AOF 文件进行同步,何时同步由操作系统来决定 |
如果用户没有主动为appendfsync选项设置值,那么appendfsync选项的默认值为everysec。
写到这里有的小伙伴可能会对上面说的写入和同步含义弄混,这里说一下:
写入:将 aof_buf 中的数据写入到 AOF 文件中。
同步:调用 fsync 以及 fdatasync 函数,将 AOF 文件中的数据保存到磁盘中。
通俗地讲就是,你要往一个文件写东西,写的过程就是写入,而同步则是将文件保存,数据落到磁盘上。
大家之前看文章的时候是不是大多都说 AOF 最多丢失一秒钟的数据,那是因为 redis AOF 默认是 everysec 策略,这个策略每秒执行一次,所以 AOF 持久化最多丢失一秒钟的数据。
AOF 文件的载入与数据还原
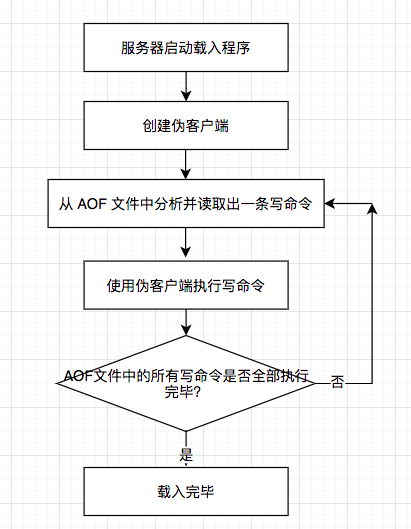
因为AOF文件里面包含了重建数据库状态所需的所有写命令,所以服务器只要读入并重新执行一遍AOF文件里面保存的写命令,就可以还原服务器关闭之前的数据库状态。 Redis读取AOF文件并还原数据库状态的详细步骤如下:
- 创建一个不带网络连接的伪客户端(fake client):因为Redis的命令只能在客户端上 下文中执行,而载入AOF文件时所使用的命令直接来源于AOF文件而不是网络连接,所以服 务器使用了一个没有网络连接的伪客户端来执行AOF文件保存的写命令,伪客户端执行命令 的效果和带网络连接的客户端执行命令的效果完全一样。
- 从AOF文件中分析并读取出一条写命令。
- 使用伪客户端执行被读出的写命令。
- 一直执行步骤2和步骤3,直到AOF文件中的所有写命令都被处理完毕为止。
当完成以上步骤之后,AOF文件所保存的数据库状态就会被完整地还原出来,整个过程 如下图所示。
AOF 重写
因为AOF持久化是通过保存被执行的写命令来记录数据库状态的,所以随着服务器运行 时间的流逝,AOF文件中的内容会越来越多,文件的体积也会越来越大,如果不加以控制的 话,体积过大的AOF文件很可能对Redis服务器、甚至整个宿主计算机造成影响,并且AOF文 件的体积越大,使用AOF文件来进行数据还原所需的时间就越多。
如 客户端执行了以下命令是:
> rpush list "A" "B"
OK
> rpush list "C"
OK
> rpush list "D"
OK
> rpush list "E" "F"
OK
那么光是为了记录这个list键的状态,AOF文件就需要保存四条命令。
对于实际的应用程度来说,写命令执行的次数和频率会比上面的简单示例要高得多,所 以造成的问题也会严重得多。 为了解决AOF文件体积膨胀的问题,Redis提供了AOF文件重写(rewrite)功能。通过该 功能,Redis服务器可以创建一个新的AOF文件来替代现有的AOF文件,新旧两个AOF文件所 保存的数据库状态相同,但新AOF文件不会包含任何浪费空间的冗余命令,所以新AOF文件 的体积通常会比旧AOF文件的体积要小得多。 在接下来的内容中,我们将介绍AOF文件重写的实现原理,以及BGREWEITEAOF命令 的实现原理。
虽然Redis将生成新AOF文件替换旧AOF文件的功能命名为“AOF文件重写”,但实际上, AOF文件重写并不需要对现有的AOF文件进行任何读取、分析或者写入操作,这个功能是通 过读取服务器当前的数据库状态来实现的。
就像上面的情况,服务器完全可以将这六条命令合并成一条。
> rpush list "A" "B" "C" "D" "E" "F"
除了上面列举的列表键之外,其他所有类型的键都可以用同样的方法去减少 AOF文件中的命令数量。首先从数据库中读取键现在的值,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令,这就是AOF重写功能的实现原理。
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序在处理列表、 哈希表、集合、有序集合这四种可能会带有多个元素的键时,会先检查键所包含的元素数 量,如果元素的数量超过了redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD常量的值,那 么重写程序将使用多条命令来记录键的值,而不单单使用一条命令。 在目前版本中,REDIS_AOF_REWRITE_ITEMS_PER_CMD常量的值为64,这也就是 说,如果一个集合键包含了超过64个元素,那么重写程序会用多条SADD命令来记录这个集 合,并且每条命令设置的元素数量也为64个。
AOF 后台重写
AOF 重写会执行大量的写操作,这样会影响主线程,所以redis AOF 重写放到了子进程去执行。这样可以达到两个目的:
- 子进程进行AOF重写期间,服务器进程(父进程)可以继续处理命令请求。
- 子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况 下,保证数据的安全性。
但是有一个问题,当子进程重写数据时,主进程依然在处理新的数据,这也就会造成数据不一致情况。
为了解决这种数据不一致问题,Redis服务器设置了一个AOF重写缓冲区,这个缓冲区在 服务器创建子进程之后开始使用,当Redis服务器执行完一个写命令之后,它会同时将这个写 命令发送给AOF缓冲区和AOF重写缓冲区,如下图:
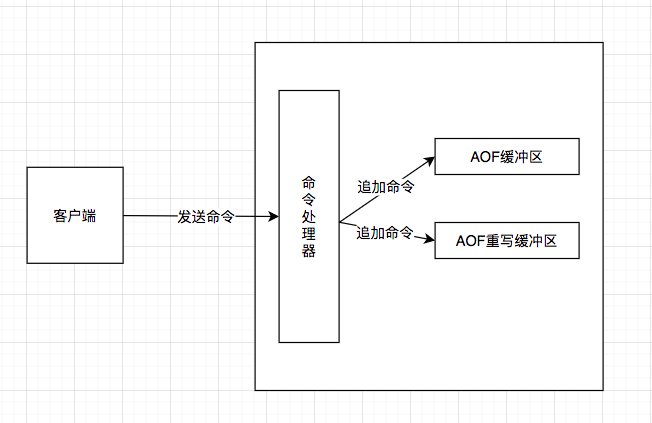
这也就是说,在子进程执行AOF重写期间,服务器进程需要执行以下三个工作:
- 执行客户端发来的命令。
- 将执行后的写命令追加到AOF缓冲区。
- 将执行后的写命令追加到AOF重写缓冲区。
这样一来可以保证:
- AOF缓冲区的内容会定期被写入和同步到AOF文件,对现有AOF文件的处理工作会如常 进行。
- 从创建子进程开始,服务器执行的所有写命令都会被记录到AOF重写缓冲区里面。
当子进程完成AOF重写工作之后,它会向父进程发送一个信号,父进程在接到该信号之 后,会调用一个信号处理函数,并执行以下工作:
- 将AOF重写缓冲区中的所有内容写入到新AOF文件中,这时新AOF文件所保存的数 据库状态将和服务器当前的数据库状态一致。
- 对新的AOF文件进行改名,原子地(atomic)覆盖现有的AOF文件,完成新旧两个 AOF文件的替换。
这个信号处理函数执行完毕之后,父进程就可以继续像往常一样接受命令请求了。
在整个AOF后台重写过程中,只有信号处理函数执行时会对服务器进程(父进程)造成 阻塞,在其他时候,AOF后台重写都不会阻塞父进程,这将AOF重写对服务器性能造成的影 响降到了最低。
Redis 混合持久化
Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。但是 AOF 恢复比较慢,Redis 4.0 推出了混合持久化。
混合持久化: 将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是 自持久化开始到持久化结束 的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小。
于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重启效率因此大幅得到提升。
觉得文章不错的话,小伙伴们麻烦点个赞、关个注、转个发一下呗~你的支持就是我写文章的动力。
更多精彩的文章请关注公众号“蘑菇睡不着”。
你越主动就会越主动,我们下期见~
源码级别理解 Redis 持久化机制的更多相关文章
- [Redis源码阅读]redis持久化
作为web开发的一员,相信大家的面试经历里少不了会遇到这个问题:redis是怎么做持久化的? 不急着给出答案,先停下来思考一下,然后再看看下面的介绍.希望看了这边文章后,你能够回答这个问题. 为什么需 ...
- 【JVM】深度分析Java的ClassLoader机制(源码级别)
原文:深度分析Java的ClassLoader机制(源码级别) 为了更好的理解类的加载机制,我们来深入研究一下ClassLoader和他的loadClass()方法. 源码分析 public abst ...
- 从Android源码的角度分析Binder机制
欢迎访问我的个人博客,原文链接:http://wensibo.top/2017/07/03/Binder/ ,未经允许不得转载! 前言 大家好,好久不见,距离上篇文章已经有35天之久了,因为身体不舒服 ...
- CentOS 7.4 源码编译安装 Redis
一.CentOS 7.4 源码编译安装 Redis 1.下载源码并解压 wget http://download.redis.io/releases/redis-4.0.10.tar.gz tar ...
- Java ArrayList源码分析(含扩容机制等重点问题分析)
写在最前面 这个项目是从20年末就立好的 flag,经过几年的学习,回过头再去看很多知识点又有新的理解.所以趁着找实习的准备,结合以前的学习储备,创建一个主要针对应届生和初学者的 Java 开源知识项 ...
- 浅谈:Redis持久化机制(二)AOF篇
浅谈:Redis持久化机制(二)AOF篇 上一篇我们提及到了redis的默认持久化方式RDB,是一种通过存储快照数据方式持久化的机制,它在宕机后会丢失掉最后一次更新RDB文件后的数据,这也是由于它 ...
- storm源码之理解Storm中Worker、Executor、Task关系 + 并发度详解
本文导读: 1 Worker.Executor.task详解 2 配置拓扑的并发度 3 拓扑示例 4 动态配置拓扑并发度 Worker.Executor.Task详解: Storm在集群上运行一个To ...
- Solr4.8.0源码分析(19)之缓存机制(二)
Solr4.8.0源码分析(19)之缓存机制(二) 前文<Solr4.8.0源码分析(18)之缓存机制(一)>介绍了Solr缓存的生命周期,重点介绍了Solr缓存的warn过程.本节将更深 ...
- Solr4.8.0源码分析(18)之缓存机制(一)
Solr4.8.0源码分析(18)之缓存机制(一) 前文在介绍commit的时候具体介绍了getSearcher()的实现,并提到了Solr的预热warn.那么本文开始将详细来学习下Solr的缓存机制 ...
随机推荐
- 三、jmeter常用的元件及组件
一.HTTP cookie Manager 用来储浏览器产生的用户信息,Stepping Thread Group 可用于模拟阶梯加压! 二.HTTP Cache Manager 缓存管理器(模拟浏览 ...
- 浅析DDD——领域驱动设计的理解
浅析DDD--领域驱动设计的理解 我觉得领域驱动设计概念的提出,是为了更清晰的区分边界.这里的边界包括业务边界和功能的边界,每个边界都包含具体的领域对象,当业务和功能的领域对象一一对应上之后,业务的变 ...
- Redis数据结构—跳跃表
目录 Redis数据结构-跳跃表 跳跃表产生的背景 跳跃表的结构 利用跳跃表查询有序链表 Redis跳跃表图示 Redis跳跃表数据结构 小结 Redis数据结构-跳跃表 大家好,我是白泽,最近学校有 ...
- NumPy之:ndarray多维数组操作
NumPy之:ndarray多维数组操作 目录 简介 创建ndarray ndarray的属性 ndarray中元素的类型转换 ndarray的数学运算 index和切片 基本使用 index wit ...
- copy函数与ostream_iterator、reverse_iterator
#include <iostream> #include <iterator> #include <vector> int main() { using names ...
- Cookie&Session-授课
1 会话技术 1.1 会话管理概述 1.1.1 什么是会话 会话:浏览器和服务器之间的多次请求和响应 为了实现一些功能,浏览器和服务器之间可能会产生多次的请求和响应,从浏览器访问服务器开始,到访问服务 ...
- 常用加密算法学习总结之数字证书与TLS/SSL
数字证书 对于一个安全的通信,应该有以下特征: 完整性:消息在传输过程中未被篡改 身份验证:确认消息发送者的身份 不可否认:消息的发送者无法否认自己发送了信息 显然,数字签名和消息认证码是不符合要求的 ...
- who -b
~]# who -b 系统引导 2020-05-03 19:57[root@localhost ~]# who -r 运行级别 5 2020-05-03 19:58
- Linux 部署 iSCSI 服务端
Linux 部署 iSCSI 服务端 服务端实验环境 iSCSI-server :RHEL8 IP:192.168.121.10 一.服务端安装 target 服务和 targetcli 命令行工具 ...
- 064.Python开发虚拟环境
在使用 Python 开发的过程中,工程一多,难免会碰到不同的工程依赖不同版本的库的问题:亦或者是在开发过程中不想让物理环境里充斥各种各样的库,引发未来的依赖灾难.此时,我们需要对于不同的工程使用不同 ...