感知机与支持向量机 (SVM)
感知机与SVM一样都是使用超平面对空间线性可分的向量进行分类,不同的是:感知机的目标是尽可能将所有样本分类正确,这种策略指导下得出的超平面可能有无数个,然而SVM不仅需要将样本分类正确,还需要最大化最小分类间隔,对SVM不熟悉的朋友可以移步我另一篇文章:支持向量机(SVM)之硬阈值 - ZhiboZhao - 博客园 (cnblogs.com)。
为了系统地分析二者的区别,本文还是首先介绍感知机模型,学习策略以及求解思路
一、感知机模型
还是假定在 \(p\) 维空间有 \(m\) 组训练样本对,构成训练集 $T = { (x_{1}, y_{1}), (x_{2}, y_{2}),...,(x_{n}, y_{n})} $,其中 \(x_{i} \in R^{1 \times p}\),\(y_{i}\in \{-1, +1\}\),以二维空间为例,在线性可分的情况下,所有样本在空间可以描述为:
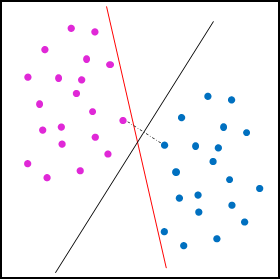
在上图中,紫色和蓝色的圆形代表不同的类别,红色的实线表示任意一条能够将这两种区分的超平面,理论上这种超平面有无数条,都有可能是感知机的解,然而SVM的模型解出来的超平面很有可能通过最大化最小间隔的策略得到的黑色的实线。我们将超平面表示为:\(\Phi: b+w_{1}x_{1}+w_{2}x_{2}+...+w_{p}x_{p} = 0\),写成矩阵形式为:\(\Phi: w^{T}x + b = 0\),根据高中数学的知识,可以得出 $ w $ 表示超平面的法向量,\(b\) 表示超平面的截距。感知机的最终目标可以表示为:
w^{T}x_{i}+b<0,\quad if \quad y_{i}=-1
\]
通过有监督的训练,不断地学习超平面的参数 \((w, b)\),最终找到一个超平面 \(f(x) = w^{T}x + b\) 网络能够根据任意输入 \(x_{i}\) 输出对应的值来区分不同的模型。
二、感知机的学习策略
感知机是根据错误驱动的思想来进行学习,具体来说,先给待学习参数 \((w,b)\) 一个初始值,得到的初始超平面一般无法正确区分类别,我们用集合 \(D\) 来代表被错误分类的样本,那么最终的学习策略就是最小化被错误分类的点的个数,定量表示如下:
\]
函数 \(\psi(x)\) 定义为:
\psi(x) = 0, \quad if\quad x>0
\]
因为当 \(y_{i}f(x_{i}) = y_{i}(w^{T}x_{i}+b) <0\) 时,该点被错误分类,于是损失函数 \(L(w,b)\) 就记录了总共被错误分类的个数,最小化loss就能求出超平面参数。
然而随着 \((w,b)\) 的改变,指示函数 \(\psi\) 要么为0,要么为1,是一个不连续的函数,因此损失函数不可导,也就不容易求出极值,需要将 \(L(w,b)\) 转换成 \((w,b)\) 的连续函数。
根据高中知识,我们得到空间内任意一点到超平面的距离为:
\]
那么对于正确分类的正样本点,其到超平面的距离设为正数,对于正确分类的错样本点,其道超平面的距离设为复数,那么所有正确分类的样本到超平面的距离可以表示为:
\]
因此,所有错误分类的样本的到超平面的总距离就可以表示为:
\]
所以,感知机的损失函数最终定义为:
\]
显然:
当正类样本被分成负类样本时 \(w^{T}x_{i}+b < 0,y_{i}>0\),
当负类样本被分成正类样本时 \(w^{T}x_{i}+b > 0,y_{i}<0\),
因此,损失函数是非负的,且分类错误的点就越少,分类错误的点就离超平面越近,其值越小。
三、感知机的求解算法
由于损失函数 \(L(w,b)\) 是自变量的连续函数,因此可以用随机梯度下降 (SGD) 的方式进行求解。那么损失函数的梯度如下:
\nabla_{b}L(w,b) = \dfrac{\partial L(w,b)}{\partial b} = -\sum_{x_{i} \in D}y_{i}
\]
采用随机梯度下降法更新的公式为:
\]
感知机与支持向量机 (SVM)的更多相关文章
- 【Supervised Learning】支持向量机SVM (to explain Support Vector Machines (SVM) like I am a 5 year old )
Support Vector Machines 引言 内核方法是模式分析中非常有用的算法,其中最著名的一个是支持向量机SVM 工程师在于合理使用你所拥有的toolkit 相关代码 sklearn-SV ...
- [转] 从零推导支持向量机 (SVM)
原文连接 - https://zhuanlan.zhihu.com/p/31652569 摘要 支持向量机 (SVM) 是一个非常经典且高效的分类模型.但是,支持向量机中涉及许多复杂的数学推导,并需要 ...
- 【python与机器学习实战】感知机和支持向量机学习笔记(一)
对<Python与机器学习实战>一书阅读的记录,对于一些难以理解的地方查阅了资料辅以理解并补充和记录,重新梳理一下感知机和SVM的算法原理,加深记忆. 1.感知机 感知机的基本概念 感知机 ...
- 机器学习——支持向量机SVM
前言 学习本章节前需要先学习: <机器学习--最优化问题:拉格朗日乘子法.KKT条件以及对偶问题> <机器学习--感知机> 1 摘要: 支持向量机(SVM)是一种二类分类模型, ...
- 【IUML】支持向量机SVM
从1995年Vapnik等人提出一种机器学习的新方法支持向量机(SVM)之后,支持向量机成为继人工神经网络之后又一研究热点,国内外研究都很多.支持向量机方法是建立在统计学习理论的VC维理论和结构风险最 ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
- 机器学习算法 - 支持向量机SVM
在上两节中,我们讲解了机器学习的决策树和k-近邻算法,本节我们讲解另外一种分类算法:支持向量机SVM. SVM是迄今为止最好使用的分类器之一,它可以不加修改即可直接使用,从而得到低错误率的结果. [案 ...
- 机器学习之支持向量机—SVM原理代码实现
支持向量机—SVM原理代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9596898.html 1. 解决 ...
随机推荐
- 04.06 UCF Local Programming Contest 2017
A.Electric Bill 题意:简单计算题,超过1000部分额外算 1 #include<stdio.h> 2 int main(){ 3 int money1,money2; 4 ...
- 如何通过在线CRM提升企业竞争力?
随着信息技术的快速发展,在线CRM系统也得到了更加广泛的应用,已经在企业中逐渐开始普及.CRM系统对于优化企业流程有着十分重要的意义,它能够让企业的经营管理更加敏捷,并且可以快速地响应企业的业务流程. ...
- CRM帮助B2B企业持续改善战略决策「下篇」
尽管数据早已深入人心,但依然有相当比率的B2B企业在管理和战略决策时依赖直觉而不是客户数据.不停变化的B2B市场表明了以客户为中心的趋向和格局,CRM客户管理系统能够协助您更好的使用客户数据并最大限度 ...
- 『动善时』JMeter基础 — 19、JMeter配置元件【随机变量】
目录 1.随机变量介绍 2.随机变量界面详解 3.随机变量的使用 (1)测试计划内包含的元件 (2)线程组界面内容 (3)随机变量界面内容 (4)HTTP请求界面内容 (5)查看结果 1.随机变量介绍 ...
- SDK安全测试
设备调试 strace MI 5X 链接:https://pan.baidu.com/s/1KfsfEgjniozXGUD_69m0SQ 提取码:mulo 推strace到手机中 adb push s ...
- Linux中169.254.0.0/24的路由来自哪里
在Linux中,发现每次系统启动时,都会将(169.254.0.0/16)路由启动并将其添加到路由表中.但是并不知道这条路由具有什么功能和它到底来自于哪里? [root@master01 ~]# ro ...
- 适用于windows10 Linux子系统的安装管理配置 How To Management Windows Subsystem for Linux WSL
什么是WSL Windows Subsystem for Linux 简称WLS,适用于Linux的Windows子系统,可以直接在Windows上运行Linux环境(包括大部分命令行工具) Linu ...
- [DB] MapReduce 例题
词频统计(word count) 一篇文章用哈希表统计即可 对互联网所有网页的词频进行统计(Google搜索引擎的需求),无法将所有网页读入内存 map:将单词提取出来,对每个单词输入一个<wo ...
- 如何用Python画一个圣诞树呢?
# ./sd.py * *** ***** ******* ********* |[root@bogon shengdan]# vim sd.py[root@bogon shengdan]# cat ...
- Linux 通过 UUID 在 fstab 中自动挂载分区
Linux 通过 UUID 在 fstab 中自动挂载分区 summerm6关注 2019.10.17 16:29:00字数 1,542阅读 605 https://xiexianbin.cn/lin ...