MySQL分页优化_别再用offset和limit分页了
终于要对MySQL优化下手了,本文将对分页进行优化说明,希望可以得到一个合适你的方案。
开始之前,先分享一套MySQL教程,小白入门或者学习巩固都可以看
MySQL基础入门-mysql教程-数据库实战(MySQL基础+MySQL高级+MySQL优化+MySQL34道作业题)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
分页这个话题已经是老生常谈了,但是有多少小伙伴一边是既希望优化的自己的系统,另一边在项目上还是保持自己独有的个性。
优化这件事是需要自己主动行动起来的,自己搞测试数据,只有在测试的路上才会发现更多你未知的事情。
本文小编也会针对分页优化这个话题进行解读。
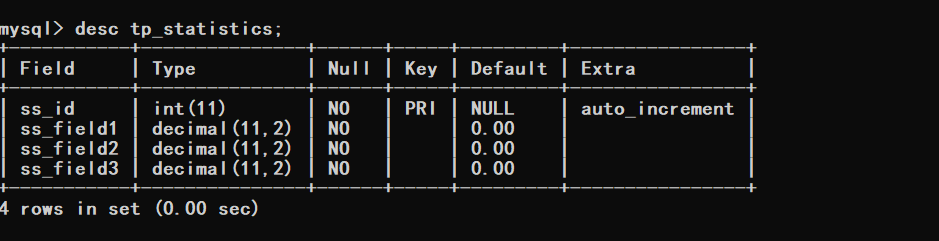
一、表结构
这个数据库结构就是小编目前线上项目的表,只不过将字段名改了而已,还有将时间字段取消了。
数据库结构如下
1 CREATE TABLE `tp_statistics` (
2 `ss_id` int(11) NOT NULL AUTO_INCREMENT,
3 `ss_field1` decimal(11,2) NOT NULL DEFAULT '0.00',
4 `ss_field2` decimal(11,2) NOT NULL DEFAULT '0.00',
5 `ss_field3` decimal(11,2) NOT NULL DEFAULT '0.00',
6 PRIMARY KEY (`ss_id`)
7 ) ENGINE=InnoDB AUTO_INCREMENT=3499994 DEFAULT CHARSET=utf8 COLLATE=utf8mb4_general_ci ROW_FORMAT=COMPACT;
根据以上信息可以看到目前表里边的数据有350万记录,接下来就针对这350W条记录进行查询优化。
二、初探查询效率
先来写一个查询的SQL语句,先看一下查询耗费的时间。
根据下图可以看到查询时间基本忽略不计,但是要注意的是limit的偏移量值。

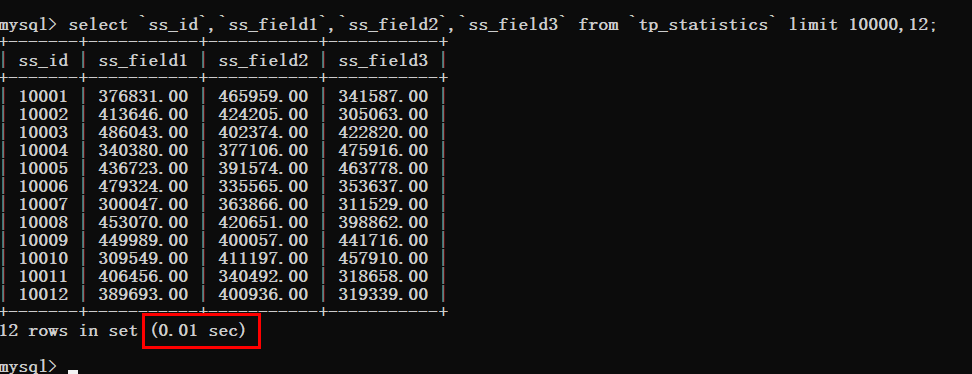
于是我们要一步一步的加大这个偏移量然后进行测试,先将偏移量改为10000
可以看到查询时间还是非常理想的。
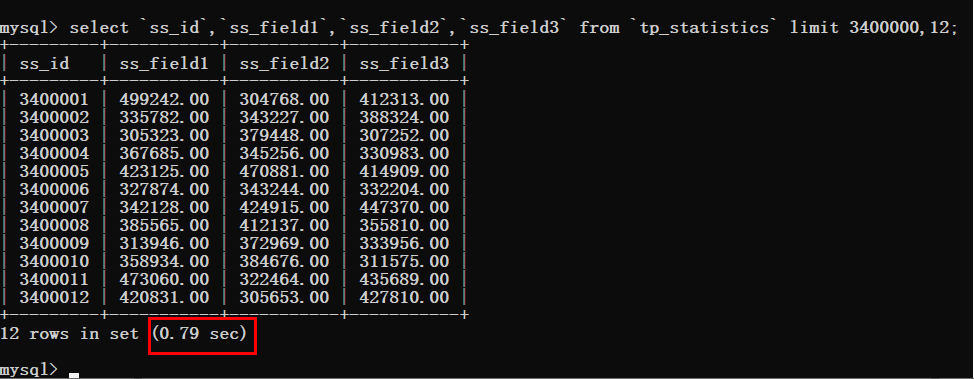
为了节省时间咔咔将这个偏移量的值直接调整到340W。
这个时候就可以看到非常明显的变化了,查询时间猛增到了0.79s。
出现了这样的情况,那肯定就需要进行优化了,拿起键盘就是干。
三、分析查询耗时的原因
提到分析SQL语句,必备的知识点就是explain,如果对这个工具不会使用的可以去看看MySQL的基础部分。
根据下图可以看到三条查询语句都进行了表扫描。

都知道只要有关于分页就必存在排序,那么加一个排序再来看一下查询效率。
然后在进行对排序的语句进行分析查看。
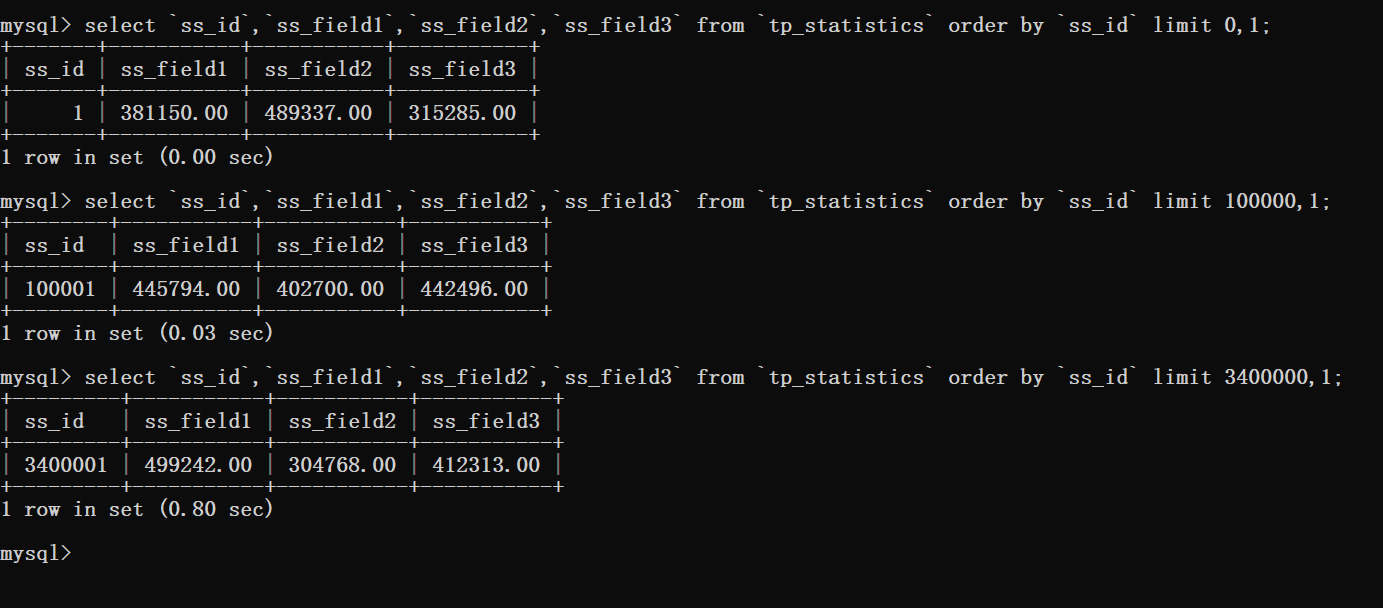
通过这里看到当使用了排序时数据库扫描的行数就是偏移量加上需要查询的数量。
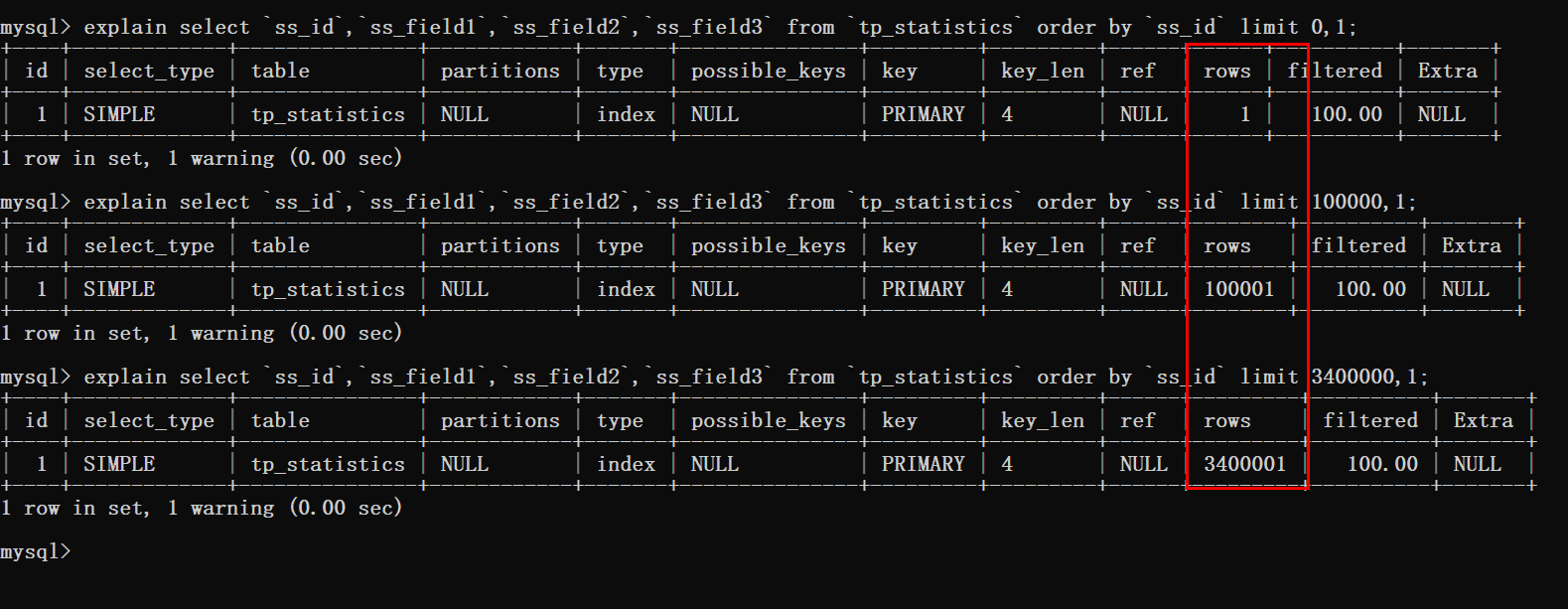
此时就可以知道的是,在偏移量非常大的时候,就像上图案例中的limit 3400000,12这样的查询。
此时MySQL就需要查询3400012行数据,然后在返回最后12条数据。
前边查询的340W数据都将被抛弃,这样的执行结果可不是我们想要的。
小编之前看到相关文章说是解决这个问题的方案,要么直接限制分页的数量,要么就优化当偏移量非常大的时候的性能。
如果你都把本文看到了这里,那怎么会让你失望,肯定是优化大偏移量的性能问题。
四、优化
既然提到了优化,无非就那么俩点,加索引,使用其它的方案来代替这个方案。
小编提供的这条数据表结构信息,完全可以理解为就是图书馆的借阅记录,字段的什么都不要去关心就可以了。
对于排序来说,在这种场景下是不会给时间加排序的,而是给主键加排序,并且由于添加测试数据的原因将时间字段给取消了。
接下来使用覆盖索引加inner join的方式来进行优化。
1 select ss_id,ss_field1,ss_field2,ss_field3 from tp_statistics inner join ( select ss_id from tp_statistics order by ss_id limit 3000000,10) b using (ss_id);
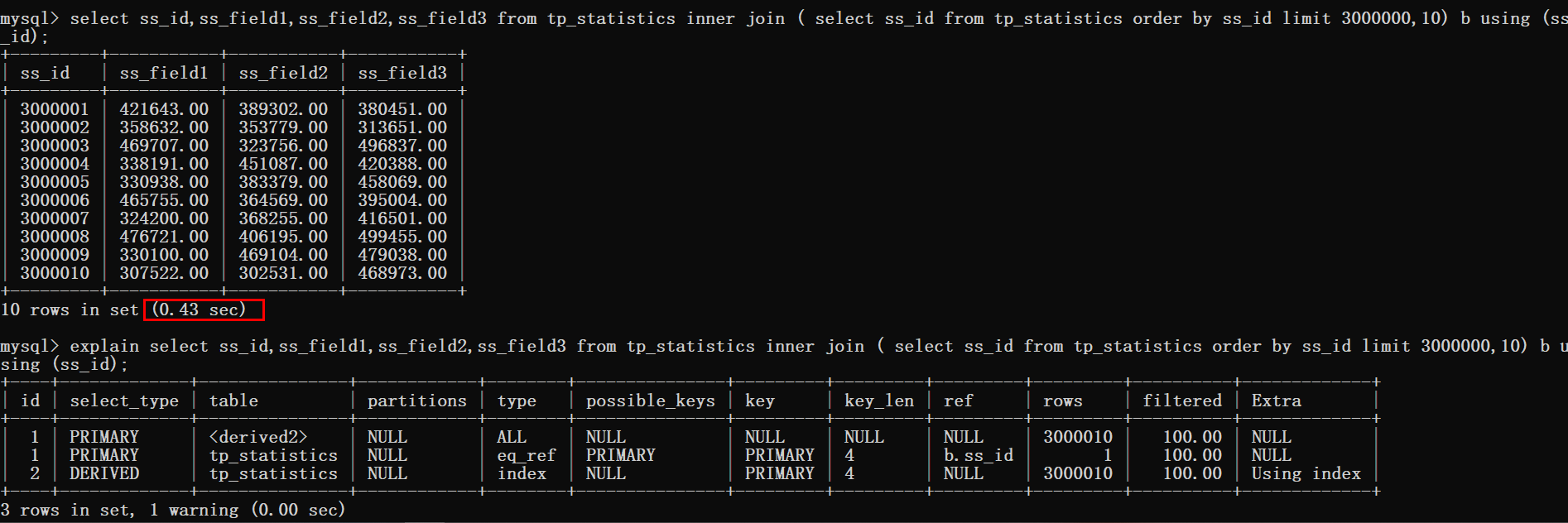
从上图可以看到查询时间从0.8s优化到了0.4s,但是这样的效果还是不尽人意。
于是只能更换一下思路再进行优化。

既然优化最大偏移量这条路有点坎坷,能不能从其它方面进行入手。
估计有很多同学已经知道咔咔将要抛出什么话题了。
没错,就是使用where > id 然后使用limit。
先来测试一波结果,在写具体实现方案。
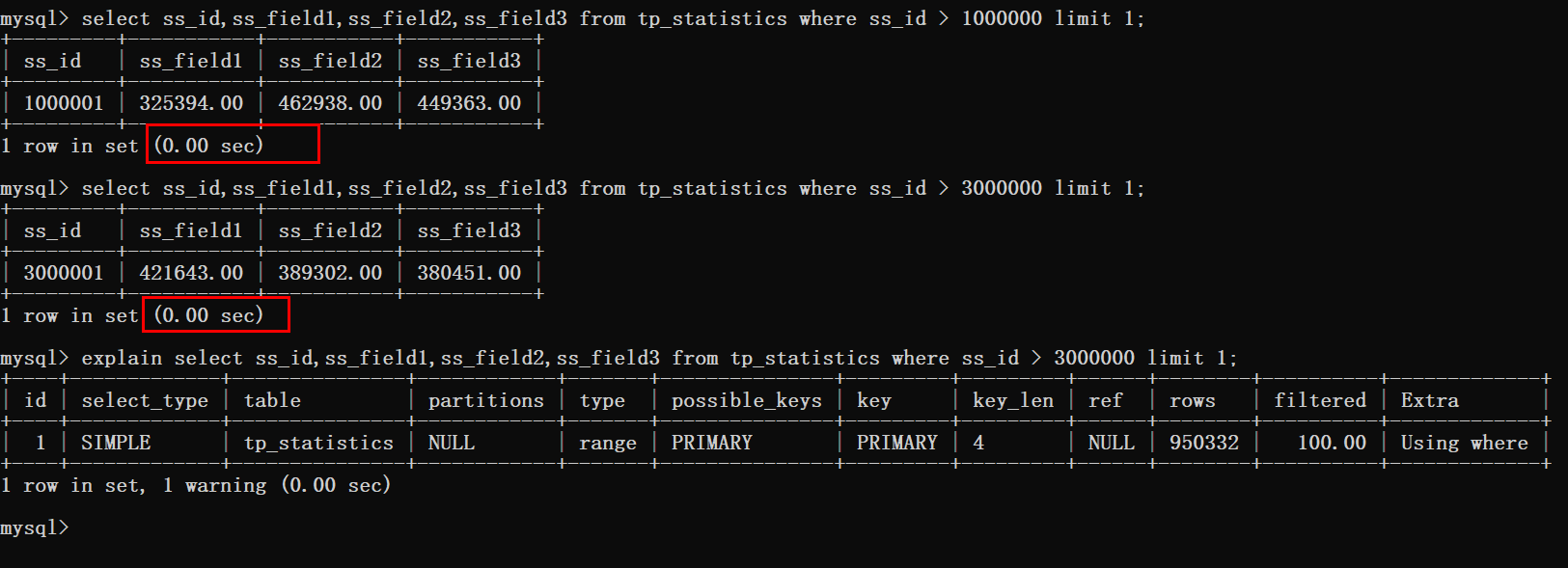
根据上图可以看到这种方式是十分可行的,分页在300W条数据以后的查询时间也基本忽略不计。
那么这种方案要怎么实现呢!
五、方案落地
其实这个方案真的很简单,只需要简单的转换一下思路即可。

当客户端第一次获取数据的时候就正常传递offset、limit俩个参数。
首次返回的数据就使用客户端传递过来的offset、limit进行获取。
当第一次的数据返回成功后。
客户端第二次拉取数据时这个时候参数就发生改变了,就不能再是offset、limit了。
此时应该传递的参数就是第一次获取的数据最后一条数据的id。
此时的参数就为last_id、limit。
后台获取到last_id后就可以在sql语句中使用where条件 < last_id
咔咔这里给的情况是数据在倒叙的情况下,如果正序就是大于last_id即可。
接下来咔咔使用一个案例给大家直接明了的说明。
实战案例
如下就是将要实战演示的案例,例如首次使用page、limit获取到了数据。
返回结果的最后一条数据的id就是3499984
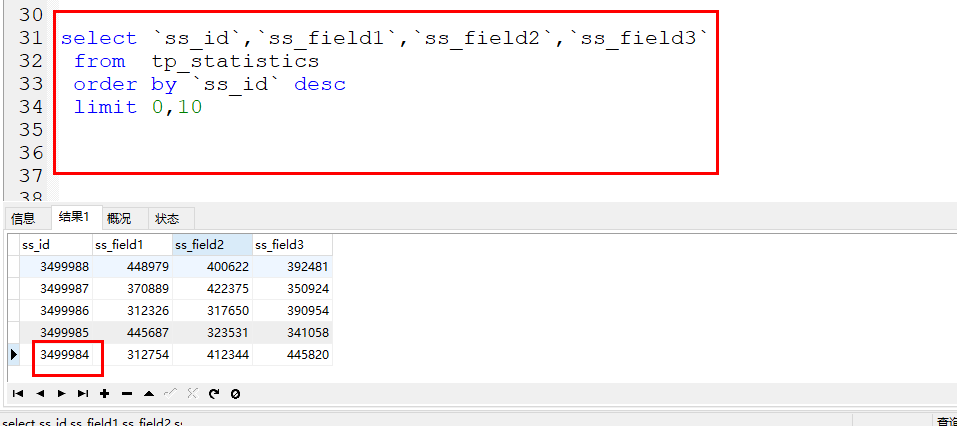
此时如果在获取第二条记录就不是使用offset、limit了,就是传递last_id和limit了。
如下图
此时就是使用的where条件来进行直接过滤数据,条件就是id小于上次数据的最后一条id即可。
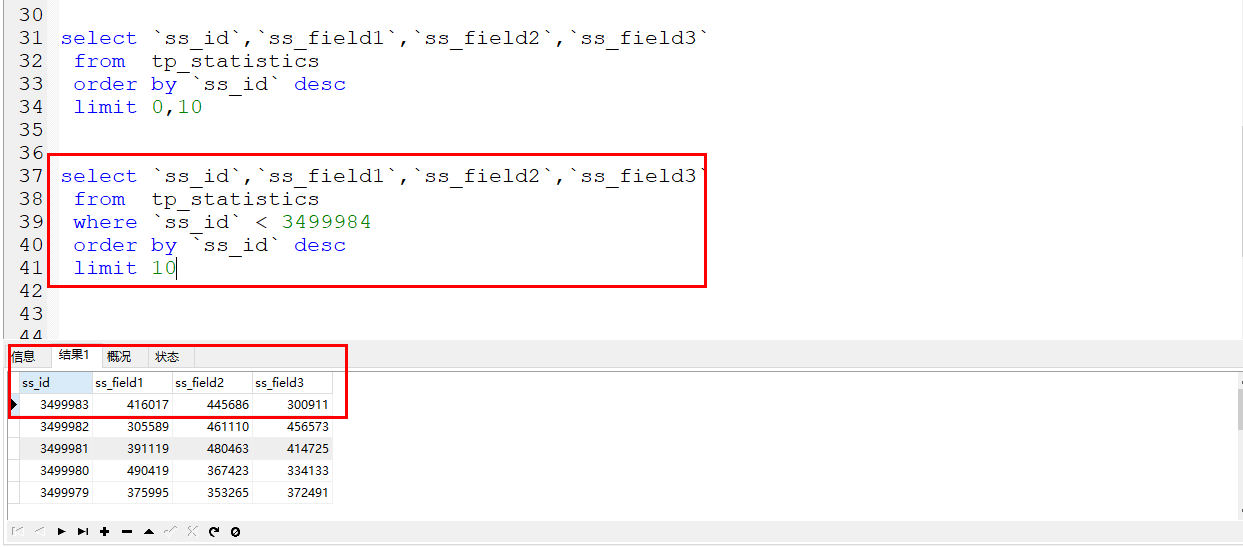
时间对比
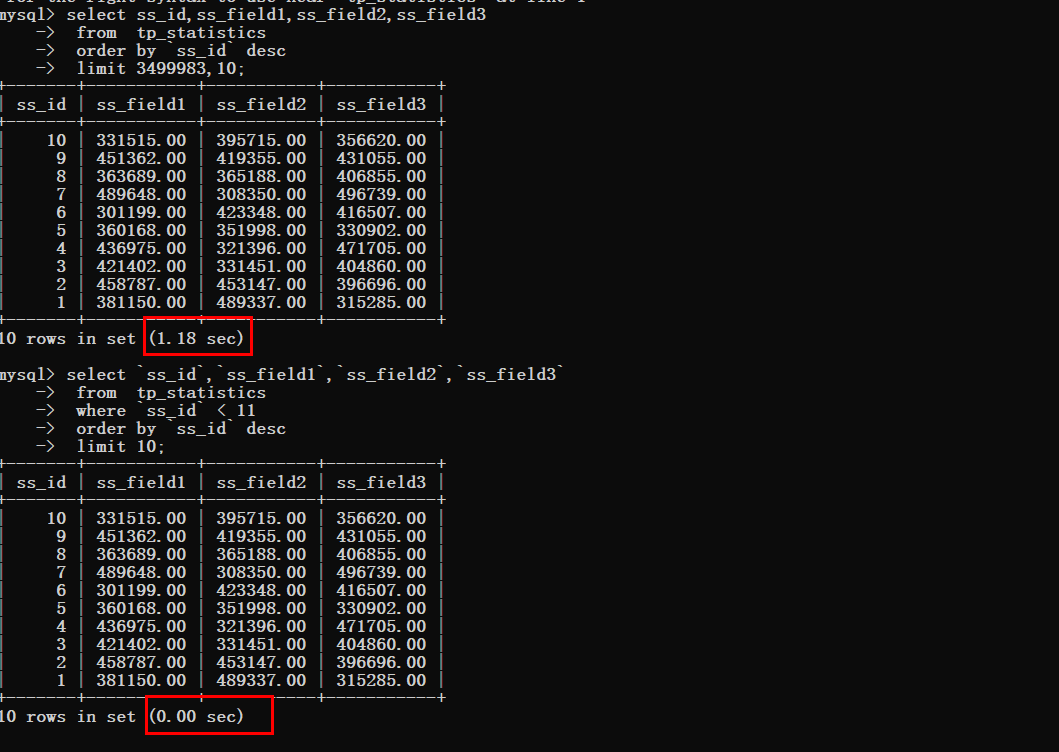
假设现在要获取最后一条数据
没有优化之前
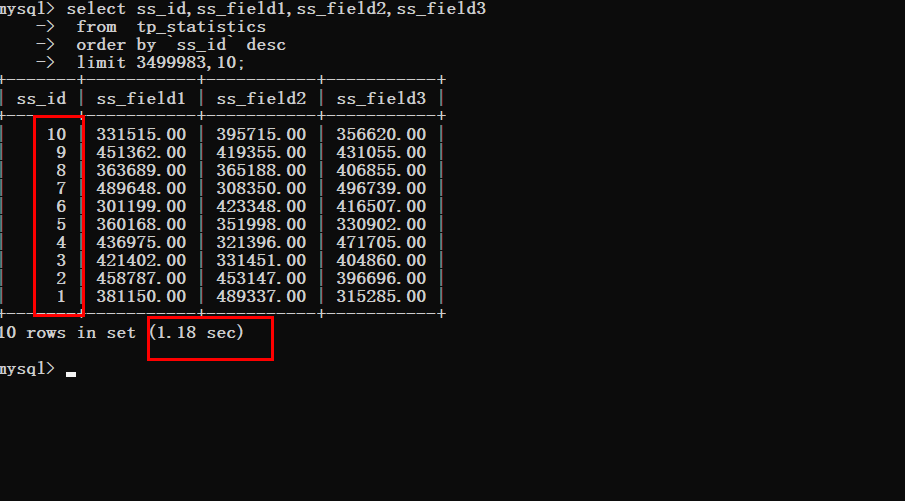
优化之后可以明显的看到查询时间的变化
六、总结
关于limit优化简单几句话概述一下。
数据量大的时候不能使用offset、limit来进行分页,因为offset越大,查询时间越久。
当然不能说所有的分页都不可以,如果你的数据就那么几千、几万条,那就很无所谓,随便使用。
落地方案就是上边的方案,首次使用offset、limit获取数据,第二次获取数据使用where条件到第一次数据最后一条id即可。
————————————————
MySQL分页优化_别再用offset和limit分页了的更多相关文章
- 分页技巧_改进JSP页面中的公共分页代码_实现分页时可以有自定义的过滤与排序条件
分页技巧__改进JSP页面中的公共分页代码 自定义过滤条件问题 只有一个url地址不一样写了很多行代码 public>>pageView.jspf添加 分页技巧__实现分页时可以有自定义的 ...
- mysql的优化_第十一篇(查询计划篇)
Mysql优化(出自官方文档) - 第十一篇(查询计划篇) 目录 Mysql优化(出自官方文档) - 第十一篇(查询计划篇) 1 EXPLAIN Output Format EXPLAIN Join ...
- MySQL数据库优化_索引
1.添加索引后减少查询需要的行数,提高查询性能 (1) 建表 CREATE TABLE `site_user` ( `id` ) NOT NULL AUTO_INCREMENT COMMENT '自增 ...
- mysql进阶(二)之细谈索引、分页与慢日志
索引 1.数据库索引 数据库索引是一种数据结构,可以以额外的写入和存储空间为代价来提高数据库表上的数据检索操作的速度,以维护索引数据结构.索引用于快速定位数据,而无需在每次访问数据库表时搜索数据库表中 ...
- 【MySQL】分页优化
前段时间由于项目的原因,对一个由于分页而造成性能较差的SQL进行优化,现在将优化过程中学习到关于分页优化的知识跟大家简单分享下. 分页不外乎limit,offset,在这两个关键字中,limit其实不 ...
- 在MySQL中如何使用覆盖索引优化limit分页查询
背景 今年3月份时候,线上发生一次大事故.公司主要后端服务器发生宕机,所有接口超时.宕机半小时后,又自动恢复正常.但是过了2小时,又再次发生宕机. 通过接口日志,发现MySQL数据库无法响应服务器.在 ...
- 【mysql优化】大数据量分页优化
limit 翻页原理 limit offset,N, 当offset非常大时, 效率极低, 原因是mysql并不是跳过offset行,然后单取N行, 而是取offset+N行,返回放弃前offset行 ...
- MySQL 百万级分页优化
MySQL 百万级分页优化 http://www.jb51.net/article/31868.htm 一般刚开始学SQL的时候,会这样写 : , ; 但在数据达到百万级的时候,这样写会慢死 : , ...
- MySQL分页优化中的“INNER JOIN方式优化分页算法”到底在什么情况下会生效?
本文出处:http://www.cnblogs.com/wy123/p/7003157.html 最近无意间看到一个MySQL分页优化的测试案例,并没有非常具体地说明测试场景的情况下,给出了一种经典的 ...
随机推荐
- SQL驱动限制,导致插入失败
insert into TB_IF_ORDERS (DC_CD,JOB_DT,SEQ_NO,ORDER_KEY,ORDER_ID,ORDER_LINE_NUM,COMPANY_CD,CUST_CD,S ...
- 任务4 PHP扩展模块安装
/usr/local/php/bin/php -m //如何查看PHP加载了哪些模块 #cd /usr/local/src #wget http://pecl.php.net/get/redis-2 ...
- 【odoo14】第十八章、自动化测试
当我们开发大型应用的时候,通过自动化测试可以大幅提高应用的健壮性.每年,odoo都会发布新版本,自动化测试对于应用的回归测试非常有帮助.幸运的是,odoo框架有不同自动化测试用例.odoo主要包括三种 ...
- 设计模式之建造者模式(BuilderPattern)
一.意义 将一个复杂的对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示. 说明:复杂对象的构建,比如一个对象有几十个成员属性,那么我们在创建这个对象,并给成员属性赋值时,就会很麻烦.采用 ...
- VUE移动端音乐APP学习【四】:scroll组件及loading组件开发
scroll组件 制作scroll 组件,然后嵌套一个 DOM 节点,使得该节点就能够滚动.该组件中需要引入 BetterScroll 插件. scroll.vue: <template> ...
- CSS浮动布局带来的高度塌陷以及其解决办法
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="U ...
- Linux+mysql混杂
一.linux 1.linux中给某一文件中批量新增一个内容 先vim进入文件,然后先按ctrl+v 然后选中需要的行数, 在shift+i 写你要添加的东西 然后在按下esc 二,mysql 1.l ...
- 你要偷偷学会排查线上CPU飙高的问题,然后惊艳所有人!
GitHub 20k Star 的Java工程师成神之路,不来了解一下吗! GitHub 20k Star 的Java工程师成神之路,真的不来了解一下吗! GitHub 20k Star 的Java工 ...
- CMS前世今生
CMS一直是面试中的常考点,今天我们用通俗易懂的语言简单介绍下. 垃圾回收器为什么要分区分代? 如上图:JVM虚拟机将堆内存区域分代了,先生代是朝生夕死的区域,老年代是老不死的区域,不同的年代对象有不 ...
- Java中的集合Set - 入门篇
前言 大家好啊,我是汤圆,今天给大家带来的是<Java中的集合Set - 入门篇>,希望对大家有帮助,谢谢 简介 前面介绍了集合List,映射Map,最后再简单介绍下集合Set,相关类如下 ...