在模仿中精进数据分析与可视化01——颗粒物浓度时空变化趋势(Mann–Kendall Test)
本文是在模仿中精进数据分析与可视化系列的第一期——颗粒物浓度时空变化趋势(Mann–Kendall Test),主要目的是参考其他作品模仿学习进而提高数据分析与可视化的能力,如果有问题和建议,欢迎在评论区指出。若有其他想要看的作品,也欢迎在评论区留言并给出相关信息。
所用数据和代码的下载地址如下:
链接:https://pan.baidu.com/s/1IixHE9aPf1u9qFkdAdHQaA
提取码:hmq2
复制这段内容后打开百度网盘手机App,操作更方便哦
简介
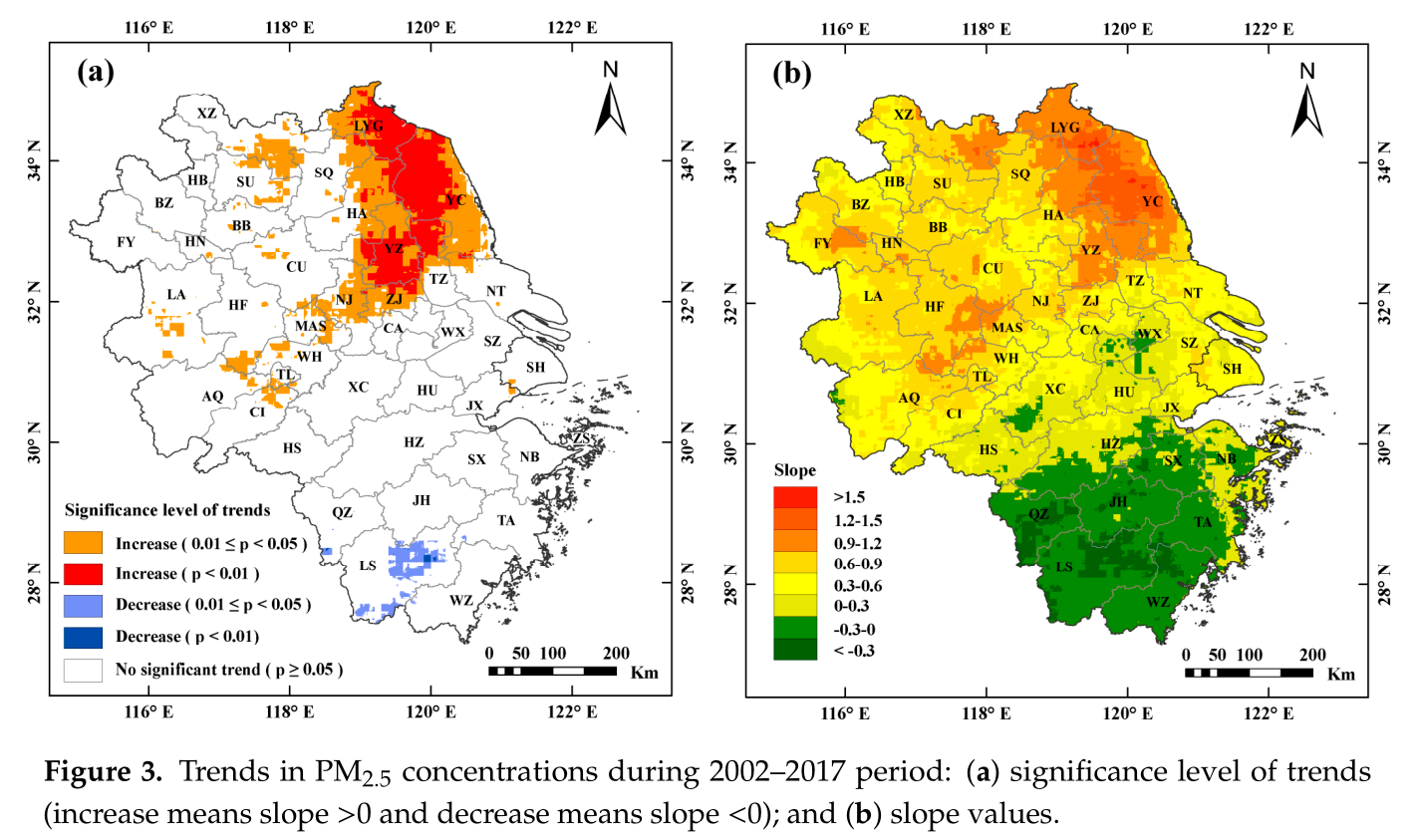
本次要模仿的作品来自论文Investigating the Impacts of Urbanization on PM2.5 Pollution in the Yangtze River Delta of China: A Spatial Panel Data Approach,研究区域为上海、安徽、浙江和江苏,所用数据为 2002–2017该区域PM2.5浓度栅格数据,数据来源于 Dalhousie University Atmospheric Composition Analysis Group开发的年均PM2.5数据集V4.CH.03,空间分辨率为0.01°×0.1°(原论文采用数据的空间分辨率为1km×1km,但我在该网站上找不到,可能是不提供下载了)。
数据下载和处理
数据下载格式为.asc,使用arcpy将其转为.tif格式,所用代码如下。
# -*- coding: utf-8 -*-import arcpyimport osinpath = "./ASCII" #待转换的栅格的存储路径,会转换该路径下的所有栅格outpath = "./TIF" #输出栅格的路径,最好是空路径filetype = "FLOAT"print "Starting Convert!"for filename in os.listdir(inpath):if filename.endswith(".asc"):filepath = os.path.join(inpath, filename)outfilepath = os.path.join(outpath, filename.replace(".asc", ".tif"))arcpy.ASCIIToRaster_conversion(filepath, outfilepath, filetype)print "Convert Over!"
Mann–Kendall趋势分析
Mann–Kendall趋势分析的具体计算方法这里不再赘述,原文作者采用R语言的trend package计算的,本文采用python的pymannkendall计算,github项目地址为https://github.com/mmhs013/pyMannKendall。
原文的趋势分析包括两部分,一部分是计算slope值,slope值为正,则表明具有上升的趋势,反之亦然;另一部分是计算p值,p值越小趋势越显著,0.01<p<0.05说明趋势显著,p<0.01说明趋势非常显著。二者分别采用pymannkendall的sens_slope和original_test函数计算,pymannkendall的简单用法介绍如下。
A quick example of pyMannKendall usage is given below. Several more examples are provided here.
import numpy as npimport pymannkendall as mk# Data generation for analysisdata = np.random.rand(360,1)result = mk.original_test(data)print(result)
Output are like this:
Mann_Kendall_Test(trend='no trend', h=False, p=0.9507221701045581, z=0.06179991635055463, Tau=0.0021974620860414733, s=142.0, var_s=5205500.0, slope=1.0353584906597959e-05, intercept=0.5232692553379981)
Whereas, the output is a named tuple, so you can call by name for specific result:
print(result.slope)
or, you can directly unpack your results like this:
trend, h, p, z, Tau, s, var_s, slope, intercept = mk.original_test(data)
计算并保存结果
这里依然使用arcpy作为分析计算的工具,所用代码如下。
pymannkendall较为臃肿,计算速度很慢(全部计算用了十几分钟),并且暂不支持numba加速,有需要大量计算的可根据其源码重新编写函数,实现numba加速,如本文的get_slope函数,在使用numba加速后计算pvalues仅需4秒,使用pymannkendall的sens_test则需要几分钟的时间。
# -*- coding: utf-8 -*-import arcpyimport osfrom glob import globimport numpy as npimport pymannkendall as mkinpath = r"./TIF" #.tif文件的保存路径p_path = r"./pvalues.tif" #p-values的输出路径slope_path = r"./slopes.tif" #slopes的输出路径trend_path = r"./trends.tif" #原图左图中不同的趋势border_path = r"./Shapefiles/border.shp" #研究区域# 获取2002-2017年的栅格数据的路径def get_raster_paths(inpath):paths = []for year in range(2002, 2018):year_path = glob(os.path.join(inpath, "*"+str(year)+"*.tif"))if year_path:paths.append(year_path[0])else:print "can't find raster of {} year!".format(year)return paths# 裁剪栅格,并将结果转为numpy数组def clip_raster_to_array(paths, border):out_image = arcpy.sa.ExtractByMask(paths[0], border)# 掩膜提取x_cell_size, y_cell_size = out_image.meanCellWidth, out_image.meanCellHeight #x,y方向的像元大小ExtentXmin, ExtentYmin = out_image.extent.XMin, out_image.extent.YMin #取x,y坐标最小值lowerLeft = arcpy.Point(ExtentXmin, ExtentYmin) #取得数据起始点范围noDataValue = out_image.noDataValue #取得数据的noData值out_image = arcpy.RasterToNumPyArray(out_image) #将栅格转为numpy数组out_image[out_image==noDataValue] = np.NAN #将数组中的noData值设为nanarrays = np.full(shape=(len(paths), out_image.shape[0], out_image.shape[1]),fill_value=np.NAN, dtype=out_image.dtype)arrays[0] = out_imagefor i in range(1, len(paths)):out_image = arcpy.sa.ExtractByMask(paths[i], border)out_image = arcpy.RasterToNumPyArray(out_image)out_image[out_image==noDataValue] = np.NANarrays[i] = out_imagereturn arrays, (lowerLeft, x_cell_size, y_cell_size, noDataValue)def array_to_raster(path, data, rasterInfo):new_raster = arcpy.NumPyArrayToRaster(data, *rasterInfo) #数组转栅格new_raster.save(path) #保存栅格# 计算slope值def get_slope(x):if np.isnan(x).any():return np.NANidx = 0n = len(x)d = np.ones(int(n*(n-1)/2))for i in range(n-1):j = np.arange(i+1,n)d[idx : idx + len(j)] = (x[j] - x[i]) / (j - i)idx = idx + len(j)return np.median(d)# 计算p值def get_pvalue(x):if np.isnan(x).any():return np.NANresult = mk.original_test(x)return result.ppaths = get_raster_paths(inpath)arrays, rasterinfo = clip_raster_to_array(paths, border_path)print "clip raster to array over!"slopes = np.apply_along_axis(get_slope, 0, arrays)print "calculate p-value over!"pvalues = np.apply_along_axis(get_pvalue, 0, arrays)print "calculate slope over!"#计算有显著和非常显著趋势的区域trends = np.full(shape=slopes.shape, fill_value=np.NaN)trends[~np.isnan(slopes)] = 0 #不显著的区域设为0trends[(slopes>0) & ((0.01<pvalues) & (pvalues<0.05))] = 1 #比较显著增加的区域设为1trends[(slopes>0) & (pvalues<0.01)] = 2 #显著增加的区域设为2trends[(slopes<0) & ((0.01<pvalues) & (pvalues<0.05))] = 3 #比较显著减少的区域设为3trends[(slopes<0) & (pvalues<0.01)] = 4 #显著减少的区域设为4# 保存栅格array_to_raster(p_path, pvalues, rasterinfo)array_to_raster(slope_path, slopes, rasterinfo)array_to_raster(trend_path, trends, rasterinfo)print "save rasters over!"
结果绘图
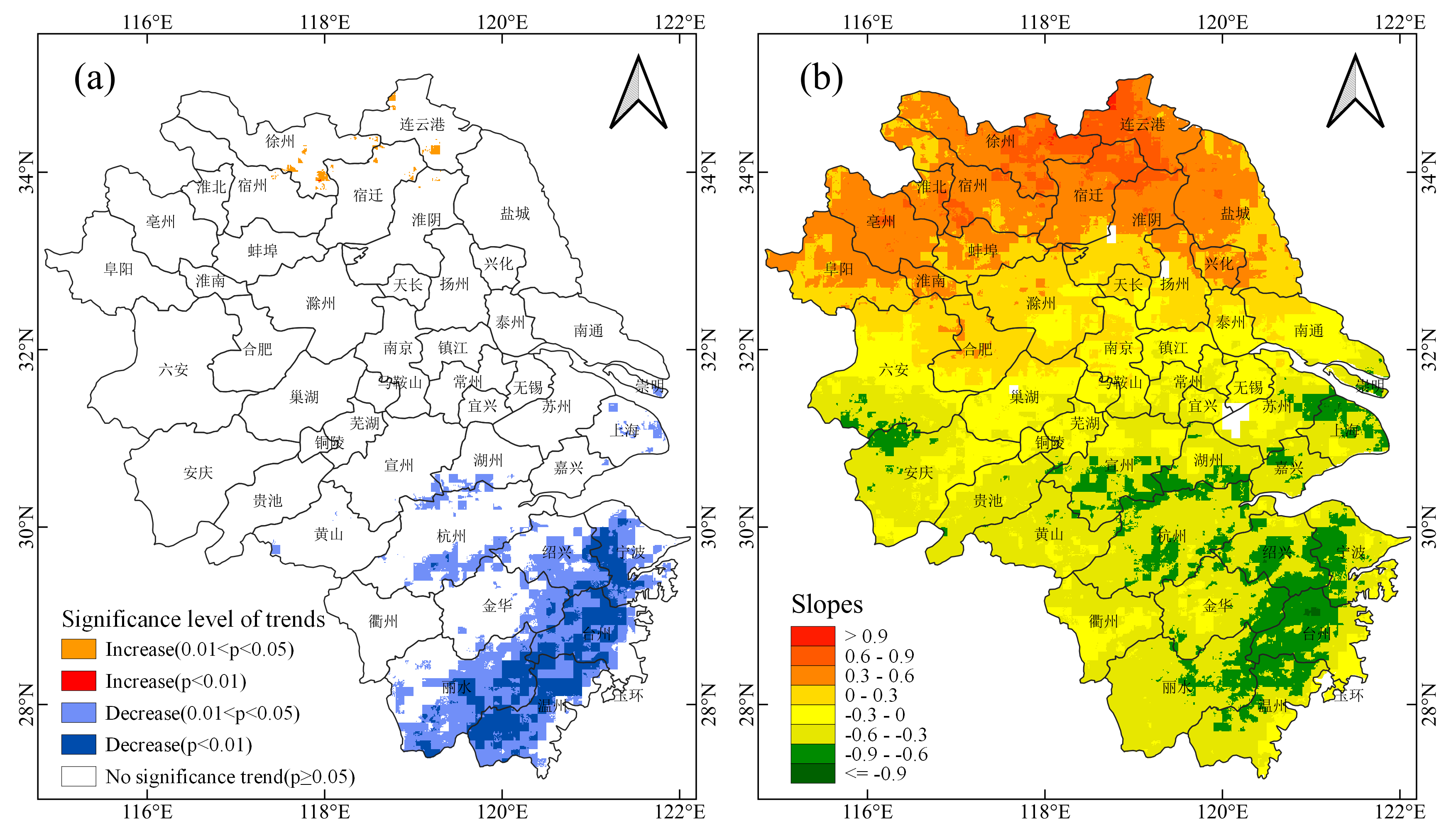
由于QGIS软件打开和一些相关操作的速度都要比ArcGIS快的多,而且QGIS内置的取色器的功能也方便绘图时设置颜色,因此本文使用QGIS绘制结果图,如下图所示。
在模仿中精进数据分析与可视化01——颗粒物浓度时空变化趋势(Mann–Kendall Test)的更多相关文章
- (在模仿中精进数据可视化05)疫情期间市值增长top25公司
本文完整代码及数据已上传至我的Github仓库https://github.com/CNFeffery/FefferyViz 1 简介 新冠疫情对很多实体经济带来冲击的同时,也给很多公司带来了新的增长 ...
- (在模仿中精进数据可视化03)OD数据的特殊可视化方式
本文完整代码已上传至我的Github仓库https://github.com/CNFeffery/FefferyViz 1 简介 OD数据是交通.城市规划以及GIS等领域常见的一类数据,特点是每一条数 ...
- (数据科学学习手札78)基于geopandas的空间数据分析——基础可视化
本文对应代码和数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 通过前面的文章,我们已经对geopanda ...
- 数据分析 | 数据可视化图表,BI工具构建逻辑
本文源码:GitHub·点这里 || GitEE·点这里 一.数据可视化 1.基础概念 数据可视化,是关于数据视觉表现形式的科学技术研究.其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽取出 ...
- Cytoscape.js – 用于数据分析和可视化的交互图形库
Cytoscape.js 是一个开源的 JavaScript 图形库,您可以使用 Cytoscape.js 进行数据分析和可视化.Cytoscape.js 可以轻松的继承到你的网站或者 Web 应用 ...
- 2017 年 机器学习之数据挖据、数据分析,可视化,ML,DL,NLP等知识记录和总结
今天是2017年12月30日,2017年的年尾,2018年马上就要到了,回顾2017过的确实很快,不知不觉就到年末了,再次开篇对2016.2017年的学习数据挖掘,机器学习方面的知识做一个总结,对自己 ...
- python中利用matplotlib绘图可视化知识归纳
python中利用matplotlib绘图可视化知识归纳: (1)matplotlib图标正常显示中文 import matplotlib.pyplot as plt plt.rcParams['fo ...
- Simulink--MATLAB中的一种可视化仿真工具
Simulink是MATLAB中的一种可视化仿真工具, 是一种基于MATLAB的框图设计环境,是实现动态系统建模.仿真和分析的一个软件包,被广泛应用于线性系统.非线性系统.数字控制及数字信号处理的建 ...
- Pytorch在colab和kaggle中使用TensorBoard/TensorboardX可视化
在colab和kaggle内核的Jupyter notebook中如何可视化深度学习模型的参数对于我们分析模型具有很大的意义,相比tensorflow, pytorch缺乏一些的可视化生态包,但是幸好 ...
随机推荐
- 【JavaScript】Leetcode每日一题-移除元素
[JavaScript]Leetcode每日一题-移除元素 [题目描述] 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度. 不要使用 ...
- 第四部分 数据搜索之使用HBASE的API实现条件查询
因为数据清洗部分需要用到Mapreduce,所以先解决hbase的问题,可以用命令先在hbase存一下简单的数据进行查询,之后只要替换数据就可以实现了原本功能 在看该部分前,确保Hase API看了, ...
- layui中select的change事件、动态追加option
说明:layui中用jquery 中的选择器例如$('#id').change(function(){})发现不起作用 layui操作:lay-felter标识操作哪个select html部分: & ...
- Mybatis学习之自定义持久层框架(三) 自定义持久层框架:读取并解析配置文件
前言 前两篇文章分别讲解了JDBC和Mybatis的基本知识,以及自定义持久层框架的设计思路,从这篇文章开始,我们正式来实现一个持久层框架. 新建一个项目 首先我们新建一个maven项目,将其命名为I ...
- 简单说几个MySQL高频面试题
前言: 在各类技术岗位面试中,似乎 MySQL 相关问题经常被问到.无论你面试开发岗位或运维岗位,总会问几道数据库问题.经常有小伙伴私信我,询问如何应对 MySQL 面试题.其实很多面试题都是大同小异 ...
- 19 常用API
API 什么是API? API (Application Programming Interface) :应用程序编程接口 简单来说:就是Java帮我们已经写好的一些方法,我们直接拿过来用就可以了 1 ...
- ES6对象的新增方法的使用
Object.assign Object Object.assign(target, ...sources) 将所有可枚举属性的值从一个或多个源对象复制到目标对象 参数: target 目标对象 so ...
- 如何设计一个高性能 Elasticsearch mapping
目录 前言 mapping mapping 能做什么 Dynamic mapping dynamic=true dynamic=runtime dynamic=false dynamic=strict ...
- [刷题] 237 Delete Nodes in a Linked List
要求 给定链表中的一个节点,删除该节点 思路 通过改变节点的值实现 实现 1 struct ListNode { 2 int val; 3 ListNode *next; 4 ListNode(in ...
- 删除所有空白列 cat yum.log | awk '{$1=$2=$3=$4=null;print $0}'>>yum.log1 sed ‘s/[ \t]*$//g' 删除所有空格 sed -i s/[[:space:]]//g yum.log
2.删除行末空格 代码如下: 删除所有空白列 cat yum.log | awk '{$1=$2=$3=$4=null;print $0}'>>yum.log1 sed 's/[ \t]* ...