java后端知识点梳理——java基础
面向对象
java三大特性
- 封装: 将事务封装成一个类,达到解耦,隐藏细节的效果。通过get/set等方法,封装了内部逻辑,并保留了特定的接口与外界联系。
- 继承: 从一个已知的类中派生出一个新的类,新类可以拥有已知类的行为和属性,并且可以通过覆盖/重写来增强已知类的能力。
- 多态: 同一个实现接口,使用不同的实例而执行不同的操作。继承是多态的基础,没有继承就没有多态。
关于继承
- Java中不支持多继承,即一个类只可以有一个父类存在。
- Java中的构造函数是不可以继承的,如果一个父类构造函数时私有的,那么久不允许有子类存在。
- 子类拥有父类非private的属性和方法
- 子类可以添加自己的方法和属性,即对父类进行扩展
- 子类可以重新定义父类的方法,即方法的覆盖/重写
关于覆盖/重写(@Override)
子类中的方法与父类中继承的方法有完全相同的返回值类型、方法名、参数个数以及参数类型,但子类丰富或修改了功能。
关于重载
重载是指在一个类中(包括父类)存在多个同名的不同方法,这些方法的参数个数,顺序以及类型不同均可以构成方法的重载。如果仅仅是修饰符、返回值、抛出的异常不同,那么这是两个相同的方法。
所以只有方法返回值不同是不能构成重载的
如:
public int add(int a, int b){}
public void add(int a, int b){}
在调用add方法的时候,系统并不知道你要调用哪一个。
子类与父类的相互转型
假设有两个类,Father是父类,Son是其子类。
- 向上转型
子类对象转为父类,父类可以是接口。
Father f1 = new Son();
问题:在向上转型的过程中,我们容易出现方法丢失的问题,比如我们将一个导出类(子类)进行向上转型,但是在基类(父类)中可能缺少部分导出类(子类)的方法,所以我们对导出类(子类)进行向上转型之后,使用基类(父类)对象去调用方法,只能调用基类(父类)有的方法。
- 向下转型
父类对象转为子类
Son s1 = (Son) f1;
注意:该父类必须实际指向了一个子类对象才可强制类型向下转型,看看下面的错误例子
Father f2 = new Father();
Son s2 = (Son)f2;
为什么Son s1 = (Son) f1;可以转型而Son s2 = (Son)f2;转型失败?
因为 f1 指向一个子类对象,但 f2 被传给了一个 Father 对象,这也就说明了该父类必须实际指向了一个子类对象才可强制类型向下转型
JDK, JRE, JVM
- JDK: java 开发工具包,包含了JRE,同时还包含了java编译器javac、监控工具jconsole、分析工具jvisualvm
- JRE: java 运行时环境,包含了java虚拟机、java基础类库
- JVM: 是指Java虚拟机,当我们运行一个程序时,JVM负责将字节码转换为特定机器代码,JVM提供了内存管理/垃圾回收和安全机制等
区别与联系:
- JDK是开发工具包,用来开发Java程序,而JRE是Java的运行时环境
- JDK和JRE中都包含了JVM
- JVM是Java编程的核心,独立于硬件和操作系统,具有平台无关性,而这也是Java程序可以一次编写,多处执行的原因
Java语言的平台无关性是如何实现的?
- JVM屏蔽了操作系统和底层硬件的差异
- Java面向JVM编程,先编译生成字节码文件,然后交给JVM解释成机器码执行
- 通过规定基本数据类型的取值范围和行为
抽象类与接口
java中通过abstract来定义抽象类,通过interface关键字来定义接口
抽象类和接口的主要区别可以总结如下:
- 抽象类中可以没有抽象方法,也可以抽象方法和非抽象方法共存
- 接口中的方法在JDK8之前只能是抽象的,JDK8版本开始提供了接口中方法的default实现
- 抽象类和类一样是单继承的,但接口可以继承多个接口
- 抽象类中可以存在普通的成员变量;接口中的变量必须是static final类型的,必须被初始化,接口中只有常量,没有变量
8种基本数据类型
| 数据类型 | 字节 | 位 |
|---|---|---|
| byte | 1 | 8 |
| short | 2 | 16 |
| int | 4 | 32 |
| long | 8 | 64 |
| float | 4 | 32 |
| double | 8 | 64 |
| char | 2 | 16 |
| boolean | - | - |
注:boolean没有规定
==、equals、hashcode
背景介绍
- == 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象。比较的是真正意义上的指针操作。
- equals用来比较的是两个对象的内容是否相等,由于所有的类都是继承自java.lang.Object类的,所以适用于所有对象,如果没有对该方法进行覆盖的话,调用的仍然是Object类中的方法,而Object中的equals方法返回的却是==的判断。
- hashCode() 方法用于返回字符串的哈希码,如果两个对象相同,那么它们的hashCode值一定要相同。
总结:
- 对于复合数据类型之间进行equals比较,在没有覆写equals方法的情况下,他们之间的比较还是内存中的存放位置的地址值,跟双等号(==)的结果相同;如果被复写,按照复写的要求来。
- 对于 ==
- 是个运算符
- 基本类型:比较的就是值是否相同
- 引用类型:比较的就是地址值是否相同
- 对于equals()
- 是个方法
- 基本类型:与==一致,都是比较值
- 引用类型:默认情况下,比较的是地址值,重写该方法后比较对象的成员变量值是否相同,但在一些类库中已经重写了这个方法(一般都是用来比较对象的成员变量值是否相同),比如:String,Integer,Date 等类中,所以他们不再是比较类在堆中的地址了。
- 对于hashcode()
- 是个方法,返回值是一个对象的哈希码
- 如果两个对象通过equals方法比较相等,那么他的hashCode一定相等;如果两个对象通过equals方法比较不相等,那么他的hashCode有可能相等;
- 重写equals方法,一定要重写hashCode方法
静态与非静态
- 静态变量:由static修饰,在JVM中,静态变量的加载顺序在对象之前,因此静态变量不依附于对象存在,可以在不实例化类的情况下直接使用静态变量
- 实例变量(非静态):必须依附于对象存在,只有实例化类后才可以使用此类中的实例变量。
static关键字
这个问题更多的可以引向static关键字来解答,从static中我们就能看出静态与非静态大致的区别
- static 修饰表示静态或全局,被修饰的属性和方法属于类,可以用类名.静态属性 / 方法名 访问
- static 修饰的代码块表示静态代码块,当 Java 虚拟机(JVM)加载类时,就会执行该代码块,只会被执行一次
- static 修饰的属性,也就是类变量,是在类加载时被创建并进行初始化,只会被创建一次
- static 修饰的变量可以重新赋值
- static 方法中不能用 this 和 super 关键字
- static 方法必须被实现,而不能是抽象的abstract
- static 方法不能被重写
注解
注解的本质就是一个继承了 Annotation 接口的接口,用来将任何的信息或元数据(metadata)与程序元素(类、方法、成员变量等)进行关联。程序可以通过反射获取标注内容。
注解的作用
代替繁杂的配置文件,简化开发。
定义注解
public @interface MyAnnotation {
String value();
int value1();
}
// 使用注解MyAnnotation,可以设置属性
@MyAnnotation(value1=100,value="hello")
public class MyClass {
}
从代码可以看出,定义注解使用的是@interface,可以在方法内部定义属性。
元注解
元注解的作用就是负责注解其他注解。Java中提供了4个元注解。
- @Target:说明注解所修饰的对象范围
源码如下:
public @interface Target {
ElementType[] value();
}
public enum ElementType {
TYPE,FIELD,METHOD,PARAMETED,CONSTRUCTOR,LOCAL_VARIABLE,ANNOCATION_TYPE,PACKAGE,TYPE_PARAMETER,TYPE_USE
}
用例
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface MyAnnotation {
}
说明: 这表明MyAnnotation只能作用域类/接口和方法上。
- @Retention:(保留策略): 保留策略定义了该注解被保留的时间长短。
源码如下:
public @interface Retention {
RetentionPolicy value();
}
public enum RetentionPolicy {
SOURCE, CLASS, RUNTIME
}
说明: SOURCE:表示在源文件中有效(即源文件保留);CLASS:表示在class文件中有效(即class保留);RUNTIME:表示在运行时有效(即运行时保留)
- @Documented: 声明注解能够被javadoc等识别
- @Inherited: 声明子类可以继承此注解,如果一个类A使用此注解,则类A的子类也继承此注解
反射
反射机制是指在运行中,对于任意一个类,都能够知道这个类的所有属性和方法。对于任意一个对象,都能够调用它的任意一个方法和属性。即动态获取信息和动态调用对象方法的功能称为反射机制。
Java反射机制提供的功能
- 在运行时判断任意一个对象所属的类
- 在运行时构造任意一个类的对象
- 在运行时判断或调用任意一个类所具有的成员变量和方法
- 在运行时获取泛型信息
- 在运行时处理注解
- 生成动态代理
Java反射优点和缺点
优点:可以实现动态创建对象和编译,体现出很大的灵活性
缺点:对性能有影响,使用反射基本上是一种解释操作,我们可以告诉JVM,我们希望做什么并且它满足我们的要求。这类操作总是慢于直接执行相同的操作。
反射相关的主要API
- java.lang.Class:代表一个类
- java.lang.reflect.Method :代表类的方法
- java.lang.reflect.Field :代表类的成员变量
- java.lang.reflect.Constructor :代表类的构造器
如下例子:
package com.reflection;
public class Demo01 {
public static void main(String[] args) throws ClassNotFoundException {
/*通过反射获取类的Class对象,
*一个类只有一个Class对象,所以c1,c2,c3的hashcode相同
*一个类被加载后,整个类的结构都会被封装在Class对象中
*/
Class c1 = Class.forName("com.reflection.User");
System.out.println(c1.getName());//com.reflection.User
Class c2 = Class.forName("com.reflection.User");
System.out.println(c2.hashCode());
Class c3 = Class.forName("com.reflection.User");
System.out.println(c3.hashCode());
}
}
//实体类:pojo,entity,只有属性
class User{
private String name;
private int age;
public User(){
}
public User(String name,int age){
this.age = age;
this.name = name;
}
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
得到的结果入下:
com.reflection.User
356573597
356573597
说明: 通过反射获取类的Class对象,一个类只有一个Class对象,所以c1,c2,c3的hashcode相同,一个类被加载后,整个类的结构都会被封装在Class对象中。
获取Class类的实例
- 若已知具体的类, 通过类的class属性获取, 该访法最为安全可靠,程序性能最高。
Class class = Person.class; - 已知某个类的实例, 调用该实例的getClass()方法获取Class对象.
Class class = person.getClass(); - 已知一 个类的全类名,且该类在类路径下,可通过Class类的静态方法forName()获取.
Class class = Class forName("demo01. Student"); - 内置基本数据类型可以直接用类名.Type
Class c4 = Integer.TYPE;
调用指定的方法
通过反射,调用类中的方法,通过Method类完成。
- 通过Class类的getMethod(String name,Clas…parameterTypes)方法取得一个Method对象,并设置此方法操作时所需要的参数类型。
- 之后使用Object invoke(Object obj, Object[] args)进行调用,并向方法中传递要设置的obj对象的参数信息。
java异常体系
异常主要分为Exception和Error
Throwable 是 Java 语言中所有错误与异常的超类。Throwable 包含两个子类:Error(错误)和 Exception(异常),它们通常用于指示发生了异常情况。
Exception和Error有什么区别?
- Exception是程序正常运行中预料到可能会出现的错误,并且应该被捕获并进行相应的处理,是一种异常现象.Exception又分为了运行时异常和编译时异常。
- 编译时异常(受检异常): 表示当前调用的方法体内部抛出了一个异常,所以编译器检测到这段代码在运行时可能会出异常,所以要求我们必须对异常进行相应的处理,可以捕获异常或者抛给上层调用方。
- 运行时异常(非受检异常): 表示在运行时出现的异常,常见的运行时异常包括:空指针异常,数组越界异常,数字转换异常以及算术异常等。
- Error是正常情况下不可能发生的错误,Error会导致JVM处于一种不可恢复的状态
NoClassDefFoundError 和 ClassNotFoundException 区别?
- NoClassDefFoundError 是一个 Error 类型的异常,是由 JVM 引起的,不应该尝试捕获这个异常。引起该异常的原因是 JVM 或 ClassLoader 尝试加载某类时在内存中找不到该类的定义,该动作发生在运行期间,即编译时该类存在,但是在运行时却找不到了,可能是变异后被删除了等原因导致;
- ClassNotFoundException 是一个受查异常,需要显式地使用 try-catch 对其进行捕获和处理,或在方法签名中用 throws 关键字进行声明。当使用 Class.forName, ClassLoader.loadClass 或 ClassLoader.findSystemClass 动态加载类到内存的时候,通过传入的类路径参数没有找到该类,就会抛出该异常;另一种抛出该异常的可能原因是某个类已经由一个类加载器加载至内存中,另一个加载器又尝试去加载它。
捕获异常应该遵循哪些原则
- 不要使用Exception捕获,而是尽可能详细的写出要捕获的异常;
- 使用日志记录,方便以后排查;
- 不要使用try-catch去包住一块很大的代码块,这不利于排查问题;
java异常处理关键字
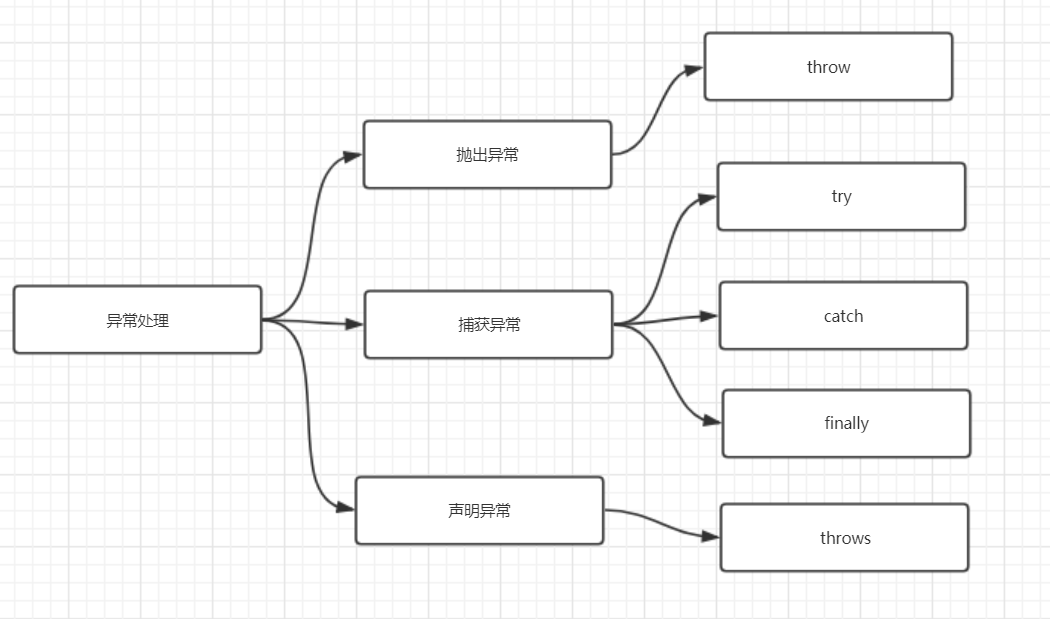
throw 和 throws 的区别是什么?
- throw 关键字用在方法内部,只能用于抛出一种异常,用来抛出方法或代码块中的异常,受查异常和非受查异常都可以被抛出。
- throws 关键字用在方法声明上,可以抛出多个异常,用来标识该方法可能抛出的异常列表。一个方法用 throws 标识了可能抛出的异常列表,调用该方法的方法中必须包含可处理异常的代码,否则也要在方法签名中用 throws 关键字声明相应的异常。
Java中的值传递和引用传递
- 值传递,意味着传递了对象的一个副本,即使副本被改变,也不会影响源对象。
- 引用传递,意味着传递的并不是实际的对象,而是对象的引用。因此,外部对引用对象的改变会反映到所有的对象上。
值传递的例子
public class Test {
public static void main(String[] args) {
int x=0;
change(x);
System.out.println(x);
}
static void change(int i){
i=7;
}
}
众所周知,结果是0。
因为如果参数是基本数据类型,那么是属于值传递的范畴,传递的其实是源对象的一个copy副本,不会影响源对象的值。
再来看看一个引用传递的例子
public class Test {
public static void main(String[] args) {
StringBuffer x = new StringBuffer("Hello");
change(x);
System.out.println(x);
}
static void change(StringBuffer i) {
i.append(" world!");
}
}
输出为Hello world!
为什么不是输出Hello了?
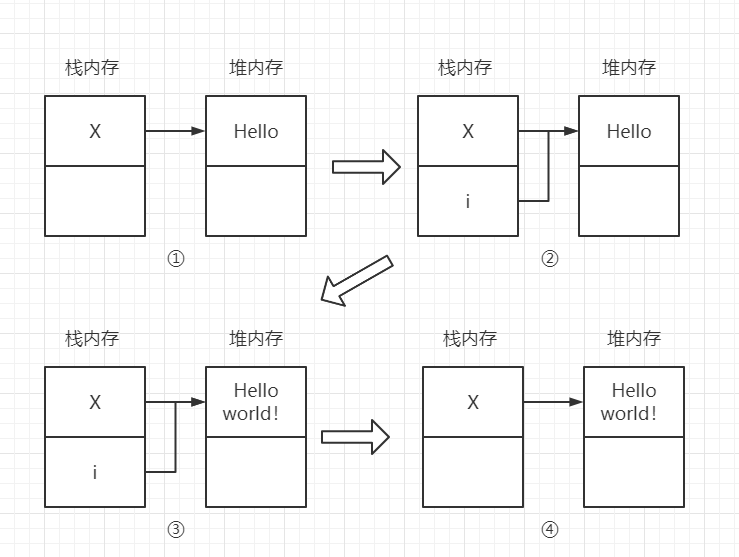
- 在①中,x指向的是堆内存,存放hello
- 在②中,i也指向了堆内存的hello
- 在③中,x和i指向了同样的内存地址,所以append操作将直接修改了内存地址里边的值
- 在④中,方法结束,局部变量i消失
再看一个例子
public class Test {
public static void main(String[] args) {
StringBuffer x = new StringBuffer("Hello");
change2(x);
System.out.println(x);
}
static void change2(StringBuffer i) {
i = new StringBuffer("hi");
i.append(" world!");
}
}
输出是Hello,我们同样通过图来分析
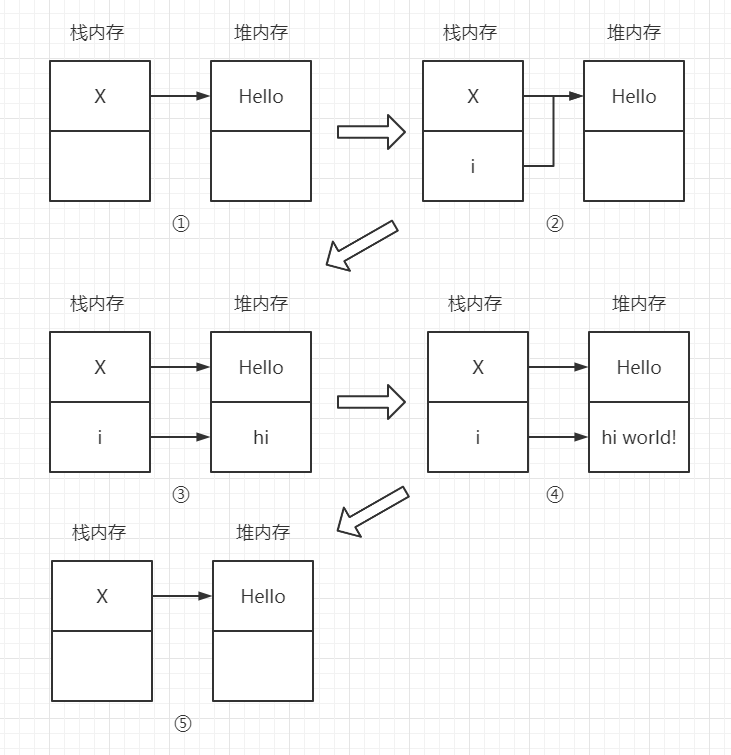
如上图所示,在函数change2中将引用变量i重新指向了堆内存中另一块区域,下边都是对另一块区域进行修改,所以输出是Hello。
最后再看一个例子
public class Test {
public static void main(String[] args) {
StringBuffer sb = new StringBuffer("Hello ");
System.out.println("Before change, sb = " + sb);
changeData(sb);
System.out.println("After change, sb = " + sb);
}
public static void changeData(StringBuffer strBuf) {
StringBuffer sb2 = new StringBuffer("Hi,I am ");
strBuf = sb2;
sb2.append("World!");
}
}
两者都是输出sb = Hello
before change我相信大家都知道为什么。
after change中,首先strBuf是指向堆内存中的Hello的,但是由于sb2指向了堆内存中的Hi I am,之后strBuf = sb2,导致strBuf指向了堆内存中的Hi I am,这对sb指向的堆内存没有什么改变,因此最后输出sb依然是Hello。
String、StringBuffer与StringBuilder
三者运行速度不同
String(遍历一百万次)
String aa = "";
long startTime = System.currentTimeMillis();
for(int i=0;i<100*100*10;i++){
//字符串拼接
aa = aa + "aa";
}
long endTime = System.currentTimeMillis();
System.out.println("耗时:"+String.valueOf(endTime - startTime));
运行结果:
耗时:7614
StringBuffer(遍历一亿次)
StringBuffer aa = new StringBuffer();
String ss = "ss";
long startTime = System.currentTimeMillis();
for(int i=0;i<100*100*100*100;i++){
//字符串拼接
aa.append(ss);
}
long endTime = System.currentTimeMillis();
System.out.println("耗时:"+String.valueOf(endTime - startTime));
运行结果:
耗时:3128
StringBuilder(遍历一亿次)
StringBuilder aa = new StringBuilder();
String ss = "ss";
long startTime = System.currentTimeMillis();
for(int i=0;i<100*100*100*100;i++){
//字符串拼接
aa.append(ss);
}
long endTime = System.currentTimeMillis();
System.out.println("耗时:"+String.valueOf(endTime - startTime));
运行结果:
耗时:1240
速度比较:String < StringBuffer < StringBuilder,且String的处理速度比StringBuffer、StringBuilder要慢的多
分析String的处理速度为什么要比StringBuffer、StringBuilder慢的多?
- String是不可变的对象
- StringBuffer和StringBuilder是可变对象
(1)String本身就是一个对象,因为String不可变对象,所以,每次遍历对字符串做拼接操作,都会重新创建一个对象,循环100万次就是创建100万个对象,非常的消耗内存空间,而且创建对象本身就是一个耗时操作,创建100万次对象就相当的耗时了。
(2)StringBuffer和StringBuilder只需要创建一个StringBuffer或StringBuilder对象,然后用append拼接字符串,就算拼接一亿次,仍然只有一个对象。
是不是可以抛弃使用String,转而使用StringBuffer和StringBuilder呢?
不行!
(1)String遍历代码:一开始定义一个String常量(创建一个String对象), 再开始遍历;
(2)StringBuffer代码:一开始定义一个String常量(创建一个String对象)和一个创建StringBuffer对象,再开始遍历;
(3)StringBuiler代码:一开始定义一个String常量(创建一个String对象)和一个创建StringBuiler对象,再开始遍历;
(2)和(3)比(1)多了一个创建对象流程,所以,如果数据量比较小的情况建议使用String。
说说StringBuffer和StringBuilder的区别?
- StringBuffer是线程安全的
- StringBuilder是非线程安全的, 这也是速度比StringBuffer快的原因
使用场景?
(1)如果要操作少量的数据用 String
(2)单线程操作字符串缓冲区 下操作大量数据 StringBuilder
(3)多线程操作字符串缓冲区 下操作大量数据 StringBuffer
泛型
泛型就是参数化类型,在不创建新的数据类型情况下,通过泛型控制具体不同类型的形参。泛型最常用的场景就是在集合中,能够简化开发,并且能够保证代码质量。泛型是在编译期间有效,在运行阶段就会去泛型化,也就是将泛型信息抹掉,这也是不支持泛型数组的原因。
- 通过泛型的语法定义,编译器可以在编译期提供一定的类型安全检查,过滤掉大部分因为类型不符而导致的运行时异常。
- 泛型可以让程序代码的可读性更高,并且由于本身只是一个语法糖,所以对于 JVM 运行时的性能是没有任何影响的。
序列化与反序列化
序列化中的关键字transient,被他修饰的变量在序列化对象的过程中不会被序列化。
序列化的意思就是将对象的状态转化成字节流,以后可以通过这些值再生成相同状态的对象。对象序列化是对象持久化的一种实现方法,它是将对象的属性和方法转化为一种序列化的形式用于存储和传输。反序列化就是根据这些保存的信息重建对象的过程。
序列化:将java对象转化为字节序列的过程。
反序列化:将字节序列转化为java对象的过程。
优点:
a、实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上(通常存放在文件里)
b、利用序列化实现远程通信,即在网络上传送对象的字节序列。
反序列化失败的场景:
序列化ID:serialVersionUID不一致的时候,导致反序列化失败
Java 对象在 JVM 退出时会全部销毁,如果需要将对象持久化就要通过序列化实现,将内存中的对象保存在二进制流中,需要时再将二进制流反序列化为对象。对象序列化保存的是对象的状态,属于类属性的静态变量不会被序列化。
常见的序列化有三种:① Java 原生序列化,实现 Serializabale 标记接口,兼容性最好,但不支持跨语言,性能一般。序列化和反序列化必须保持序列化 ID 的一致,一般使用 private static final long serialVersionUID 定义序列化 ID,如果不设置编译器会根据类的内部实现自动生成该值。② Hessian 序列化,支持动态类型、跨语言。③ JSON 序列化,将数据对象转换为 JSON 字符串,抛弃了类型信息,反序列化时只有提供类型信息才能准确进行。相比前两种方式可读性更好。
序列化通常使用网络传输对象,容易遭受攻击,因此不需要进行序列化的敏感属性应加上 transient 关键字,把变量生命周期仅限于内存,不会写到磁盘。
详细解析请看:
java基础---->Serializable的使用
java后端知识点梳理——java基础的更多相关文章
- java后端知识点梳理——java集合
集合概览 Java中的集合,从上层接口上看分为了两类,Map和Collection.Map是和Collection并列的集合上层接口,没有继承关系. Java中的常见集合可以概括如下. Map接口和C ...
- java后端知识点梳理——多线程与高并发
进程与线程 进程是一个"执行中的程序",是系统进行资源分配和调度的一个独立单位 线程是进程的一个实体,一个进程中一般拥有多个线程. 线程和进程的区别 进程是操作系统分配资源的最小单 ...
- java后端知识点梳理——Spring
开篇:感谢我是祖国的花朵,java3y,三太子敖丙等优秀博主!他们的文章为我学习java提供了莫大的帮助,膜拜大神! Spring的优点有哪些呢? Spring的依赖注入将对象之间的依赖关系交给了框架 ...
- java后端知识点梳理——JVM
可以先看看我的深入理解java虚拟机笔记 深入理解java虚拟机笔记Chapter2 深入理解java虚拟机笔记Chapter3-垃圾收集器 深入理解java虚拟机笔记Chapter3-内存分配策略 ...
- java后端知识点梳理——web安全
跨域 当浏览器执行脚本时会检查是否同源,只有同源的脚本才会执行,如果不同源即为跨域. 这里的同源指访问的协议.域名.端口都相同. 同源策略是由 Netscape 提出的著名安全策略,是浏览器最核心.基 ...
- java后端知识点梳理——Redis
redis都支持哪些数据类型?应用场景有哪些? redis支持五种数据类型作为其Value,redis的Key都是字符串类型的. string:redis 中字符串 value 最大可为512M.可以 ...
- java后端知识点梳理——MySQL
MySQL的索引 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息,就像一本书的目录一样,可以加快查询速度.InnoDB 存储引擎的索引模型底层实现数据结构为 ...
- Java 面试知识点解析(一)——基础知识篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- Java编程知识点梳理
1. elementAt() temp.elementAt(0) 返回temp这个vector里面存放的第一个元素--->也是一个vector类型. 2. 字符串空格分割 String [] ...
随机推荐
- Python多线程_thread和Threading
目录 多线程 _thread模块 使用 _thread模块创建线程 threading 使用 threading模块创建线程 线程同步 在讲多线程之前,我们先看一个单线程的例子: import _th ...
- Netcat瑞士军刀的简单使用
目录 Netcat 常用参数: 常见的用法: 端口扫描: 聊天 文件传输 反弹shell 蜜罐 Netcat Netcat 常称为 nc,拥有"瑞士军刀"的美誉.nc 小巧强悍,可 ...
- json对象的获取
<script type="text/javascript"> var person = { //json对象定义开始 name:'tom', //字符串 age:24 ...
- 【死磕JVM】用Arthas排查JVM内存 真爽!我从小用到大
Arthas是啥 当我们系统遇到JVM或者内存溢出等问题的时候,如何对我们的程序进行有效的监控和排查,就发现了几个比较常用的工具,比如JDK自带的 jconsole.jvisualvm还有一个最好用的 ...
- Codeforces Beta Round #107(Div2)
B.Phone Numbers 思路:就是简单的结构体排序,只是这里有一个技巧,就是结构体存储的时候,直接存各种类型的电话的数量是多少就行,在读入电话的时候,既然号码是一定的,那么就直接按照格式%c读 ...
- Dom树,什么是dom树?
相信很多初学前端的小伙伴,学了html,css,js之后,欣喜之余还有一丝小傲娇,没有想到那些大佬们口中又 提到了DOM树.你两眼一抹黑,年轻人总是要接受社会的爱(du)护(da). DOM 是 Do ...
- 【Azure Redis 缓存】Azure Cache for Redis服务中,除开放端口6379,6380外,对13000,13001,15000,15001 为什么也是开放的呢?
问题描述 在使用安全检测工具对Azure Redis服务端口进行扫描时,发现Redis对外开放了13001, 13000,15000,15001端口.非常不理解的是,在门户上只开放了6379,6380 ...
- J2SE基础题
J2SE基础 八种基本数据类型的大小,以及他们的封装类.(有的也说是9中基本数据类型,包括了void) 基本类型 大小(字节) 默认值 封装类 byte 1 (byte)0 Byte short 2 ...
- mouseenter mouseleave鼠标悬浮离开事件
- Java并发-显式锁篇【可重入锁+读写锁】
作者:汤圆 个人博客:javalover.cc 前言 在前面并发的开篇,我们介绍过内置锁synchronized: 这节我们再介绍下显式锁Lock 显式锁包括:可重入锁ReentrantLock.读写 ...