Learning to Sample
此处主要提出几个疑问和想法:
疑问:
- 为什么需要这个匹配过程?虽然G可能不是P的子集,但是为什么一定需要他是子集呢?
- 如果一定要匹配的话,匹配过程是没法反向传播的,所以只可以在推理阶段使用,那么这个推理阶段起到了什么作用呢?训练一个针对
fixed task的S-NET么? 那么在推理阶段这个匹配就可以反向传播从而更新S-NET了么?和训练阶段有什么区别? - 但是看分类任务的数据的话,这个
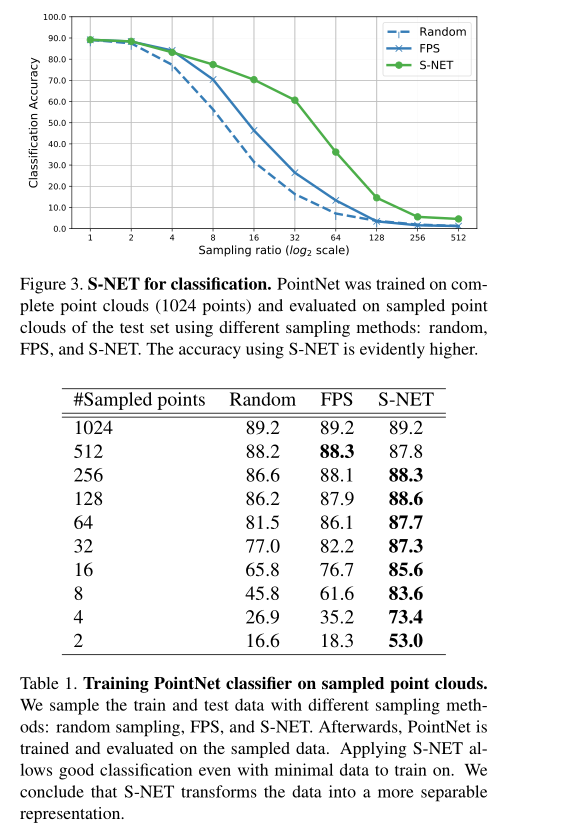
S-NET确实提取出了更重要的点, - 他的采样到底有没有收到下游任务的影响,从而进行针对性的采样?如果有的话那个采样的不可微不是已经断了么?\(\color{red}{这里有解决方法。}\)链接为:https://www.cnblogs.com/A-FM/p/15694906.html
- 在几何结构信息复杂的地方多采样一些点,几何信息简单的地方可以少放一点点,并且把
point relation加进去然后做采样,再想想办法把半监督啥的放进去?因为只要这样做了采样,点很少的情况下,效果也会很不错的,这样可以借助这个优势去扩大半监督的优势?
Abstract
处理大型的点云是一项很有挑战性的任务,因此,我们将点云采样到一个合适的size去更方便的处理。
- 目前流行的采样方法是FPS,但是FPS对于下游任务是不可知的,如在反向传播啥的,他们之间是没有交互的。
- 我们证明了通过dl去学习如何采样是更好的,因此提出了一个深度网络来简化三维点云。其被称为
S-NET。 - 该方法可以解决第一点,也就是针对特定任务进行优化。
Introduction
- FPS等这些方法考虑了点云的结构,选取一组彼此相距最远的点。
- 这些采样方法和文献中其他方法一样,都是根据非学习的预定规则进行操作的。
S-NET学习生成更小的点云,该点云采样可以为下游任务进行针对性优化。
简化之后的点云必须平衡两个相互冲突的方面:
- 希望它保持和原始形状的相似性,
- 希望他可以优化到后续任务。
我们通过训练网络生成一组满足两个目标的点来解决这个问题:采样损失和任务损失。 - 采样损失驱动生成的点的形状接近输入点云。
- 任务损失确保点对任务有优化。
FPS的一个优点是他采样得到的集合是原始点的子集,但是S-NET生成的简化点云并不能保证是输入点云的子集。
- 这个方法可以被视为是一种特征选择机制,每个点都是基础形状的一个特征,此处试图找出对任务贡献最大的点。
- 它也可以被解释为是视觉注意力的一种形式,将后续的任务网络集中在重要的点上。
贡献:
- 针对特定任务数据驱动采样方法
- 一种递进的抽样方法,根据点与任务的相关性进行排序
相关工作
点云的采样和简化
相关的方法,都是在优化各种抽样目标,然而他们没有考虑到所执行的任务的目标。
Method
问题描述:给定一个点集\(P=\{p_i\in\mathbb{R}^3,i=1,\dots,n\}\),采样大小为\(k\leq n\)和一个任务网络\(T\),找出\(k\)个点的子集\(S^*\),使任务网络的目标函数\(f\)最小化。
\]
\(\color{red}{这个问题带来了一个挑战就是采样看起来类似于池化,但是采样是无法反向传播的,但是池化可以,因此可以计算池化的梯度。}\)
然而离散采样就像arg-pooling,传播的值不能增量的更新。因此抽样操作不可以直接进行训练。因此,我们将生成的点和原始点云进行匹配,得到输入点的子集,即采样点。如下图
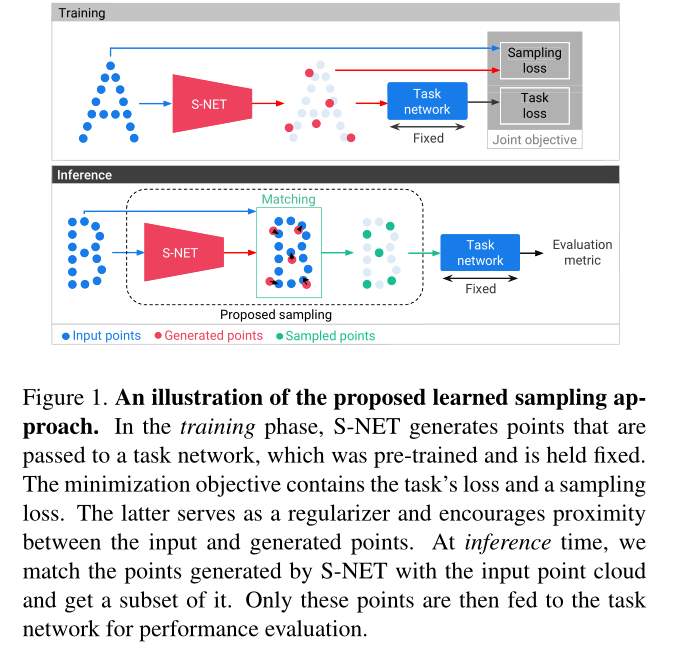
S-NET的输入是\(n\)个三维坐标的集合,代表一个三维形状。S-NET的输出是\(k\)个生成的点。S-NET后面是一个任务网络。输入\(n\)个点对任务网络进行预训练,在点云上执行给定的任务。S-NET在训练和测试的过程中保持固定,这确保了采样是针对任务进行优化的,而不是针对任意抽样进行优化的任务。
在训练阶段,生成的点被送到任务网络当中,这些点通过最小化任务损失来优化手头的任务。并且使用第二个损失项,鼓励生成的每个点靠近输入点的位置,并迫使生成的点在输入点云的分布中扩散。
在推理阶段的时候,将生成的点和输入点云进行匹配以获得其子集。这些采样点就是我们的最终输出采样点,这些点通过网络并对其性能进行评估。
此处提供了两个采样版本:S-NET和ProgressiveNet。在第一个版本中,我们根据样本大小训练不同的采样网络。在第二个版本中,它可以产生任何大小的 小于输入样本的采样样本。
S-NET
S-NET的结构使用的是PointNet的方法。输入点经过一组\(1\times 1\)的卷积层,得到每个点的特征向量。然后使用对称的特征最大池来获得全局特征向量。最后,我们使用几个完全连接的层,最后一层的输出是生成的点集。
我们将生成的点集表示为\(G\),输入的点集表示为\(P\),我们构造一个采样正则化损失,它由三个项组成:
\]
\]
\]
\(L_f\)和\(L_m\)在平均和最差的情况下,让\(G\)尽量可能的接近\(P\)。\(L_b\)保证生成的点尽量均匀的分布在输入点上。我们可以将上述公式转化为:
\]
此外我们使用\(L_{task}\)表示任务网络损失,最终S-NET的损失函数为:
\]
S-NET的输出是\(k \times 3\)的矩阵,\(k\)是采样样本的点数,接下来我们就对这\(k\)个点进行训练。
Matching
生成的点G不能保证是输入点\(P\)的子集,为了得到输入点的子集,我们将生成的点匹配到输入点云。
一个广泛使用的匹配两个点集的方法是EMD,它可以在集合之间找到一个bijection,使对应的点的距离最小,但是它要求这两个点集有相同的数量。但是在这里我们的两个点集的大小是不同的。
我们测试两种匹配方法。第一种方法是将EMD适用于不均匀点集。第二种是基于最近邻匹配的问题。这里我们使用的是第二种,它可以产生更好的效果。在基于最近邻的匹配中,每个点\(x\in G\)被替代为欧几里得空间内最近的点\(y^*\in P\):
\]
由于\(G\)中的几个点可能会接近于\(P\)中的同一个点,所以采样点的数量可能会小于需要点的数量。因此我们去掉重复的点并且得到一个初始的采样集合。然后我们通过FPS完成这个集合,我们每一步都从P中添加一个距离当前点集最远的点
匹配过程我们仅仅在推理时使用,作为推理的最后一步。在训练阶段当中,生成的点由任务网络按照原样处理,因为匹配是不可微的,不能将任务损失传播回S-NET
ProgressiveNet: sampling as ordering
S-NET被训练来采样单一,预训练过的尺寸大小的点。但是如果我们需要很多个采样大小呢?那么就需要对应数量的S-NET被训练。如果我们想训练一个可以产出任意大小的采样算法要怎么做的,然后这里提出了ProgressiveNet。ProgressiveNet的训练输入是给定大小的点云,输出是同样大小的点云,虽然输入点的顺序是任意的,但是输出点的顺序是根据他们与任务的相关性排序的。这样就允许我们对任意大小的样本进行抽样,我们只需要获取ProgressiveNet输出的前\(k\)个点云,然后丢弃其他样本。ProgressiveNet的结构和S-NET的相同,最后一个全连接层的大小等于输入点云的大小。
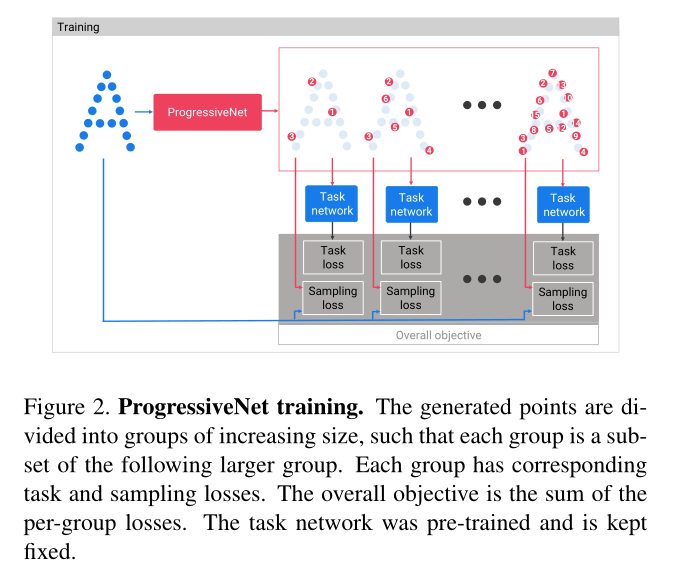
为了训练ProgressiveNet我们定义一个集合\(C_s=\{2^1,2^2,\dots,2^{log_2(n)}\}\)。对于每一个大小\(c\in C_s\)我们计算任务损失项和一个采样正则化损失项,使ProgressiveNet的总损失变为:
\]
其中的\(L^{S-NET}\)是方程6定义的公式,\(G_c\)是ProgressiveNet生成的点的前\(c\)个点
不继续看了, 这个没啥东西。 就是为了可变采样大小,通过给采样点排序的方法。
实验
Learning to Sample的更多相关文章
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- 小样本学习最新综述 A Survey on Few-shot Learning | Introduction and Overview
目录 01 Introduction Bridging this gap between AI and humans is an important direction. FSL can also h ...
- (转)Let’s make a DQN 系列
Let's make a DQN 系列 Let's make a DQN: Theory September 27, 2016DQN This article is part of series Le ...
- 线性、逻辑回归的java实现
线性回归和逻辑回归的实现大体一致,将其抽象出一个抽象类Regression,包含整体流程,其中有三个抽象函数,将在线性回归和逻辑回归中重写. 将样本设为Sample类,其中采用数组作为特征的存储形式. ...
- scikit-learn:3.3. Model evaluation: quantifying the quality of predictions
參考:http://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter 三种方法评估模型的预測质量: Est ...
- 一、【python】机器学习基础
专有名词 机器学习 (machine learning) 预测分析 (predictive analytics) 统计学习 (statistical learning) 监督学习 (supervise ...
- SampleNet: Differentiable Point Cloud Sampling
Abstract 经典的采样方法(FPS)之类的没有考虑到下游任务. 改组上一篇工作没有解决不可微性,而是提供了变通的方法. 本文提出了解决不可微性的方法 可微松弛点云采样,近似采样点作为一个混合点在 ...
- 【PSMA】Progressive Sample Mining and Representation Learning for One-Shot Re-ID
目录 主要挑战 主要的贡献和创新点 提出的方法 总体框架与算法 Vanilla pseudo label sampling (PLS) PLS with adversarial learning Tr ...
- Deep learning:五十一(CNN的反向求导及练习)
前言: CNN作为DL中最成功的模型之一,有必要对其更进一步研究它.虽然在前面的博文Stacked CNN简单介绍中有大概介绍过CNN的使用,不过那是有个前提的:CNN中的参数必须已提前学习好.而本文 ...
随机推荐
- C/C++ Qt TableDelegate 自定义代理组件
TableDelegate 自定义代理组件的主要作用是对原有表格进行调整,例如默认情况下Table中的缺省代理就是一个编辑框,我们只能够在编辑框内输入数据,而有时我们想选择数据而不是输入,此时就需要重 ...
- HDU 6987 - Cycle Binary(找性质+杜教筛)
题面传送门 首先 mol 一发现场 AC 的 csy 神仙 为什么这题现场这么多人过啊啊啊啊啊啊 继续搬运官方题解( 首先对于题目中的 \(k,P\),我们有若存在字符串 \(k,P,P'\) 满 ...
- urllib的基本使用介绍
1. urllib中urlopen的基本使用介绍 1 ### urllib中urlopen的基本使用介绍 2 3 ## urlopen的基本用法(GET请求) 4 import urllib.requ ...
- svn简单上传下载文件命令
上传命令: svn import 本地文件或目录 远程服务端目录 --username '用户名' --password '密码' -m '添加描述(可为空)' 下载命令: svn export 远程 ...
- 12-Add Digits
寻找一个数的数根,用了暴力破解的方式,时间复杂度比较高 暂未想到O(1)的方式 Given a non-negative integer num, repeatedly add all its dig ...
- PC端申请表
公司项目需求中要做用html做一个PDF申请表的样式出来.有点意思,贴上来大家看看. 先上效果图: 附上源代码: HTML:<div id="form"> <h2 ...
- 在C++的map类型中按value排序
1.将map转化为vector类型 2.使用sort函数对vector进行排序,写出compare比较器函数 3.比较器中指明按照第几个元素来排序 1 #include <iostream> ...
- 双向循环链表模板类(C++)
双向链表又称为双链表,使用双向链表的目的是为了解决在链表中访问直接前驱和后继的问题.其设置前驱后继指针的目的,就是为了节省其时间开销,也就是用空间换时间. 在双向链表的每个节点中应有两个链接指针作为它 ...
- C语言中的使用内存的三段
1.正文段即代码和赋值数据段 一般存放二进制代码和常量 2.数据堆段 动态分配的存储区在数据堆段 3.数据栈段 临时使用的变量在数据栈段 典例 若一个进程实体由PCB.共享正文段.数据堆段和数据栈段组 ...
- Netty实现Socket
Netty实现Socket 从Java1.4开始, Java引入了non-blocking IO,简称NIO.NIO与传统socket最大的不同就是引入了Channel和多路复用selector的概念 ...