GBK 和 UTF8
首先来看一下常用的编码有哪些,截图自Notepad++。其中ANSI在中国大陆即为GBK(以前是GB2312),最常用的是 GBK 和 UTF8无BOM 编码格式。后面三个都是有BOM头的文本格式,UCS-2即为人们常说的Unicode编码,又分为大端、小端。
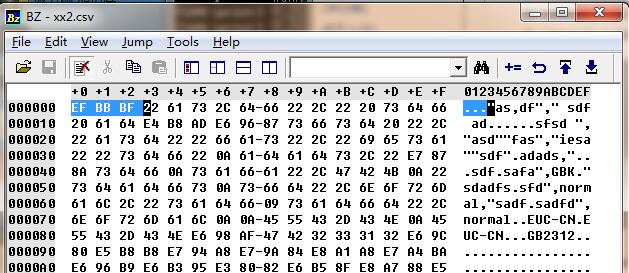
所谓BOM头(Byte Order Mark)就是文本文件中开始的几个并不表示任何字符的字节,用二进制编辑器(如bz.exe)就能看到了。
- UTF8的BOM头为 0xEF 0xBB 0xBF
- Unicode大端模式为 0xFE 0xFF
- Unicode小端模式为 0xFF 0xFE
何为GBK,何为GB2312,与区位码有何渊源?
区位码是早些年(1980)中国制定的一个编码标准,如果有玩过小霸王学习机的话,应该会记得有个叫做“区位”的输入法(没记错的话是按F4选择)。就是打四个数字然后就出来汉字了,什么原理呢。请看下面的区位码表,每一个字符都有对应一个编号。其中前两位为“区”,后两位为“位”,中文汉字的编号区号是从16开始的,位号从1开始。前面的区号有一些符号、数字、字母、注音符号(台)、制表符、日文等等。
而GB2312编码就是基于区位码的,用双字节编码表示中文和中文符号。一般编码方式是:0xA0+区号,0xA0+位号。如下表中的 “安”,区位号是1618(十进制),那么“安”字的GB2312编码就是 0xA0+16 0xA0+18 也就是 0xB0 0xB2 。根据区位码表,GB2312的汉字编码范围是0xB0A1~0xF7FE


可能大家注意到了,区位码里有英文和数字,按道理说是不是也应该是双字节的呢。而一般情况下,我们见到的英文和数字是单字节的,以ASCII编码,也就是说现代的GBK编码是兼容ASCII编码的。比如一个数字2,对应的二进制是0x32,而不是 0xA3 0xB2。那么问题来了,0xA3 0xB2 又对应到什么呢?还是2(笑)。注意看了,这里的2跟2是不是有点不太一样?!确实是不一样的。这里的双字节2是全角的二,ASCII的2是半角的二,一般输入法里的切换全角半角就是这里不同。
如果留意过早些年的手机(功能机),会发现人名中常见的“燊”字是打不出来的。为什么呢?因为早期的区位码表里面并没有这些字,也就是说早期的GB2312也是没有这些字的。到后来的GBK(1995)才补充了大量的汉字进去,当然现在的安卓苹果应该都是GBK字库了。再看看这些补充的汉字的字节码 燊 0x9F 0xF6 。和前面说到的GB2312不同,有的字的编码比 0xA0 0xA0 还小,难道新补充的区位号还能是负的??其实不然,这次的补充只补充了计算机编码表,并没有补充区位码表。也就是说区位码表并没有更新,用区位码打字法还是打不出这些字,而网上的反向区位码表查询也只是按照GBK的编码计算,并不代表字与区位号完全对应。时代的发展,区位码表早已经是进入博物馆的东西了。
Big5是与GB2312同时期的一种台湾地区繁体字的编码格式。后来GBK编码的制定,把Big5用的繁体字也包含进来(但编码不兼容),还增加了一些其它的中文字符。细心的朋友可能还会发现,台湾香港用的繁体字(如KTV里的字幕)跟大陆用的繁体字还有点笔画上的不一样,其实这跟编码无关,是字体的不同,大陆一般用的是宋体楷体黑体,港澳台常用的是明体(鸟哥Linux私房菜用的是新細明體)。GBK总体编码范围为0x8140~0xFEFE,首字节在 0x81~0xFE 之间,尾字节在 0x40~0xFE 之间,剔除 xx7F 一条线。详细编码表可以参考这个列表。微软Windows安排给GBK的code page(代码页)是CP936,所以有时候看到编码格式是CP936,其实就是GBK的意思。2000年和2005年,国家又先后两次发布了GB18030编码标准,兼容GBK,新增四字节的编码,但比较少见。
同一个编码文件里,怎么区分ASCII和中文编码呢?从ASCII表我们知道标准ASCII只有128个字符,0~127即0x00~0x7F(0111 1111)。所以区分的方法就是,高字节的最高位为0则为ASCII,为1则为中文。
UTF8编码 与 Unicode编码
GBK是中国标准,只在中国使用,并没有表示大多数其它国家的编码;而各国又陆续推出各自的编码标准,互不兼容,非常不利于全球化发展。于是后来国际组织发行了一个全球统一编码表,把全球各国文字都统一在一个编码标准里,名为Unicode。很多人都很疑惑,到底UTF8与Unicode两者有什么关系?如果要类比的话,UTF8相当于GB2312,Unicode相当于区位码表,不同的是它们之间的编号范围和转换公式。那什么是原始的Unicode编码呢?如果你用过PHP的话,json_encode函数默认会把中文编码成为Unicode,比如“首发于博客园”就会转码成“\u9996\u53d1\u4e8e\u535a\u5ba2\u56ed”。可以看到每个字都变成了 \uXXXX 的形式,这个就是文字的对应Unicode编码,\u表示Unicode的意思,网上也有用U+表示unicode。现行的Unicode编码标准里,绝大多数程序语言只支持双字节。英文字母、标点也收纳在Unicode编码中。有兴趣的可以在站长工具里尝试“中文转Unicode”,可以得到你输入文字的Unicode编码。
因为英文字符也全部使用双字节,存储成本和流量会大大地增加,所以Unicode编码大多数情况并没有被原始地使用,而是被转换编码成UTF8。下表就是其转换公式:

第一种:Unicode从 0x0000 到 0x007F 范围的,是不是有点熟悉?对,其实就是标准ASCII码里面的内容,所以直接去掉前面那个字节 0x00,使用其第二个字节(与ASCII码相同)作为其编码,即为单字节UTF8。
第二种:Unicode从 0x0080 到 0x07FF 范围的,转换成双字节UTF8。
第三种:Unicode从 0x8000 到 0xFFFF 范围的,转换成三字节UTF8,一般中文都是在这个范围里。
第四种:超过双字节的Unicode目前还没有广泛支持,仅见emoji表情在此范围。
例如“博”字的Unicode编码是\u535a。0x535A在0x0800~0xFFFF之间,所以用3字节模板 1110yyyy 10yyyyxx 10xxxxxx。将535A写成二进制是:0101 0011 0101 1010,高八位分别代替y,低八位分别代替x,得到 11100101 10001101 10011010,也就是 0xE58D9A ,这就是博字的UTF8编码。
前面提到,GBK的编码里英文字符有全角和半角之分,全角为GBK的标准编码过的双字节2,半角为ASCII的单字节2。那现在UTF8是全部用一个公式,理论上只有半角的2的,怎么支持全角的2呢?哈哈,结果是Unicode为中国特色的全角英文字符也单独分配了编码,简单粗暴。比如全角的2的Unicode编码是 \uFF12,转换到UTF8就是 0xEFBC92。
文章开头有说到 UCS-2,其实UCS-2就是原始的双字节Unicode编码,用二进制编辑器打开UCS-2大端模式的文本文件,从左往右看,看到的就是每个字符的Unicode编码了。至于什么是大端小端,就是字节的存放顺序不同,这一般是嵌入式编程的范畴。
如何区分一个文本是无BOM的UTF8还是GBK
前面说到的几种编码,其中有的是有BOM头的,可以直接根据BOM头区分出其编码。有两个是没有BOM头的,UTF8和GBK,那么两者怎么区分呢?答案是,只能按大量的编码分析来区分。目前识别准确率很高的有:Notepad++等一些常用的IDE,PHP的mb_系列函数,python的chardet库及其它语言衍生版如jchardet,jschardet等(请自行github)。
那么这些库是怎么区分这些编码的呢?那就是词库,你会看到库的源码里有大量的数组,其实就是对应一个编码里的常见词组编码组合。同样的文件字节流在一个词组库里的匹配程度越高,就越有可能是该编码,判断的准确率就越大。而文件中的中文越少越零散,判断的准确率就越低。
关于ASCII
文中多次提及ASCII编码,其实这应该是每个程序员都非常熟悉、认真了解的东西。对于嵌入式开发的人来说,应该能随时在字符与ASCII码中转换,就像十六进制与二进制之间的转换一样。标准ASCII是128个,范围是0x00~0x7F (0000 0000~0111 0000) ,最高位为0。也有一个扩展ASCII码规则,把最高位也用上了,变成256个,但是这个扩展标准争议很大,没有得到推广,应该以后不会得到推广。因为无论是GBK还是UTF8,如果ASCII字符编码最高位能为1都会造成混乱无法解析。
以GBK为例,如果ASCII的字符最高位也能是1,那么是应该截取一个解析为ASCII呢?还是截取两个解析为中文字符?这根本无法判断。UTF8也是同理,遇到 0xxx 开头则截取一个(即为标准ASCII), 遇到 110x 开头则截取两个,遇到 1110 开头则截取三个,如果ASCII包含1开头的,则无法确定何时截取多少个。
在哪里还能一睹扩展ASCII的真容呢?其实很简单,只要把网页的meta改成ASCII就行了 <meta charset="ASCII" /> 。又或者浏览器的编码选择“西方”,即可见到与平常所见不同的乱码。(截图为火狐)

转自:https://www.cnblogs.com/hehheai/p/6510879.html
GBK 和 UTF8的更多相关文章
- 彻底搞懂编码 GBK 和 UTF8
常用编码格式一览 首先来看一下常用的编码有哪些,截图自Notepad++.其中ANSI在中国大陆即为GBK(以前是GB2312),最常用的是 GBK 和 UTF8无BOM 编码格式.后面三个都是有BO ...
- gbk与utf-8转换
linux: #include <iconv.h> int code_convert(char *from_charset,char *to_charset,char *inbuf,int ...
- 字符集GBK升级UTF8
在生产环境中,数据库字符集因为各种原因需要升级,比如为了支持汉字,从latin1字符集升级到GBK,后面为了支持多个语言文字,需要将GBK升级到UTF8等.迁移过程网上有很多,我今天主要想讲下字符集转 ...
- GB2312、GBK和UTF-8三种编码以及QT中文显示乱码问题
1.GB2312.GBK和UTF-8三种编码的简要说明 GB2312.GBK和UTF-8都是一种字符编码,除此之外,还有好多字符编码.只是对于我们中国人的应用来说,用这三种编码 比较多.简单的说一下, ...
- Java 中文字符串编码之GBK转UTF-8
写过两篇关于编码的文章了,以为自己比较了解编码了呢?! 结果今天又结结实实的上了一课. 以前转来转去解决的问题终归还是简单的情形.即iso-8859-1转utf-8,或者iso-8859-1转gbk, ...
- iconv命令 gbk 转 UTF-8
-----linux gbk 转 UTF-8-------- iconv 用法 iconv -f "gbk" -t "utf-8" < infile &g ...
- ASCII、Unicode、GBK和UTF-8字符编码的区别联系(转载)
ASCII.Unicode.GBK和UTF-8字符编码的区别联系 转载自:http://dengo.org/archives/901 很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同 ...
- 字符编码GB2312、GBK、UTF-8的区别
本文来自:javaeye网站 UTF8是国际编码,它的通用性比较好,外国人也可以浏览论坛 GBK是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBK大~ 提示:如果您的网站客户群体主要是面 ...
- 项目乱码 GBK转UTF-8工具
项目乱码 GBK转UTF-8工具 链接:http://pan.baidu.com/s/1pLw1mMB 密码:rj6c
- 网络编码 GB2312、GBK与UTF-8的区别
GB2312.GBK与UTF-8的区别 这是一个异常经典的问题,有无数的新手站长每天都在百度这个问题,而我,作为一个“伪老手”站长,在明白这个这个问题的基础上,有必要详细的解答一下. 首先,我们要 ...
随机推荐
- Protocol Buffer序列化Java框架-Protostuff
了解Protocol Buffer 首先要知道什么是Protocol Buffer,在编程过程中,当涉及数据交换时,我们往往需要将对象进行序列化然后再传输.常见的序列化的格式有JSON,XML等,这些 ...
- 【.NET 6】使用.NET 6开发minimal api以及依赖注入的实现、VS2022热重载和自动反编译功能的演示
前言: .net 6 LTS版本发布已经有若干天了.此处做一个关于使用.net 6 开发精简版webapi(minimal api)的入门教程,以及VS2022 上面的两个强大的新技能(热重载.代码自 ...
- Codeforces 526G - Spiders Evil Plan(长链剖分+直径+找性质)
Codeforces 题目传送门 & 洛谷题目传送门 %%%%% 这题也太神了吧 storz 57072 %%%%% 首先容易注意到我们选择的这 \(y\) 条路径的端点一定是叶子节点,否则我 ...
- [Ocean Modelling for Begineers] Ch4. Long Waves in a Channel
Ch4. Long Waves in a Channel 简介 本章主要介绍明渠中分层流体模拟.练习包括浅水表面波,风暴潮.内波和分层流体模拟. 4.1 有限差分法详细介绍 4.1.1 泰勒公式 4. ...
- GWAS与GS模型介绍与比较
目录 1.GWAS模型 1.1卡方检验 1.2 相关性系数的t检验 1.3 一般线性模型GLM 1.4 混合线性模型MLM 1.5 压缩混合线性模型CMLM 1.6 SUPER 1.7 FarmCPU ...
- SNPEFF snp注释 (添加自己基因组)
之间介绍过annovar进行对snp注释,今天介绍snpEFF SnpEff is a variant annotation and effect prediction tool. It annota ...
- 关于写SpringBoot+Mybatisplus+Shiro项目的经验分享一:简单介绍
这次我尝试写一个原创的项目 the_game 框架选择: SpringBoot+Mybatisplus+Shiro 首先是简单的介绍(素材灵感来自英雄联盟) 5个关键的表: admin(管理员): l ...
- 学习java 7.10
学习内容: List 集合:有序集合,用户可以精确控制列表中每个元素的插入位置 List 集合特点:有序:存储和取出的元素顺序一致 可重复:存储的元素可以重复 增强for循环:简化数组和 Collec ...
- Learning Spark中文版--第四章--使用键值对(2)
Actions Available on Pair RDDs (键值对RDD可用的action) 和transformation(转换)一样,键值对RDD也可以使用基础RDD上的action(开工 ...
- C语言产生随机数(伪)
C语言的获取随机数的函数为rand(), 可以获得一个非负整数的随机数.要调用rand需要引用头文件stdlib.h.要让随机数限定在一个范围,可以采用模除加加法的方式.要产生随机数r, 其范围为 m ...