一次线上服务高 CPU 占用优化实践 (转)
线上有一个非常繁忙的服务的 JVM 进程 CPU 经常跑到 100% 以上,下面写了一下排查的过程。通过阅读这篇文章你会了解到下面这些知识。
- Java 程序 CPU 占用高的排查思路
- 可能造成线上服务大量异常的 log4j 假异步
- Kafka 异步发送的优化
- On-CPU 火焰图的原理和解读
- 使用 Trie 前缀树来优化 Spring 的路径匹配
开始尝试
JVM CPU 占用高,第一反应是找出 CPU 占用最高的线程,看这个线程在执行什么,使用 top 命令可以查看进程中所有线程占用的 CPU 情况,命令如下所示。
top -Hp you_pid输出如下:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
48 root 20 0 30.367g 2.636g 12940 S 12.7 2.9 36:15.18 java
2365 root 20 0 30.367g 2.636g 12940 R 1.3 2.9 2:33.64 java
2380 root 20 0 30.367g 2.636g 12940 S 1.3 2.9 2:33.10 java
2381 root 20 0 30.367g 2.636g 12940 S 1.3 2.9 2:33.41 java
10079 root 20 0 30.367g 2.636g 12940 S 1.3 2.9 0:30.73 java
10 root 20 0 30.367g 2.636g 12940 S 1.0 2.9 4:08.54 java
11 root 20 0 30.367g 2.636g 12940 S 1.0 2.9 4:08.55 java
92 root 20 0 30.367g 2.636g 12940 S 1.0 2.9 2:53.71 java
681 root 20 0 30.367g 2.636g 12940 S 1.0 2.9 2:52.56 java
683 root 20 0 30.367g 2.636g 12940 S 1.0 2.9 2:56.81 java
690 root 20 0 30.367g 2.636g 12940 S 1.0 2.9 3:34.24 java可以看到占用 CPU 最高的线程 PID 为 48(0x30),使用 jstack 输出当前线程堆栈,然后 grep 一下 0x30,如下所示。
jstack 1 | grep -A 10 "0x30 "输出结果如下。
"kafka-producer-network-thread | producer-1" #35 daemon prio=5 os_prio=0 tid=0x00007f9ac4fc7000 nid=0x30 runnable [0x00007f9ac9b88000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x0000000094ef70c8> (a sun.nio.ch.Util$3)
- locked <0x0000000094ef70e0> (a java.util.Collections$UnmodifiableSet)
- locked <0x000000009642bbb8> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at org.apache.kafka.common.network.Selector.select(Selector.java:686)可以看到这是一个 kafka 的发送线程。我们的日志打印是使用 log4j2 的 kafka 插件将日志文件写入到 kafka,日志写入量非常大。接下来先来优化这个 kafka 发送线程的 CPU 占用。
Log4j2 下 KafkaAppender 优化
KafkaAppender 中封装了 KafkaProducer,经过测试与 KafkaProducer 发送频率有很大关系的有这几个参数 batch.size、linger.ms。接下来看看这里几个参数有什么实际的作用。
linger.ms
KafkaProducer 在 batch 缓冲区满或者 linger.ms 时间到达时,会讲消息发送出去。 linger.ms 用来指定发送端在 batch 缓冲池被填满之前最多等待多长时间,相当于 TCP 协议的 Nagle 算法。
这个值默认为 0,只要有数据 Sender 线程就会一直发,不会等待,就算 batch 缓冲区只有一条数据也会立即发送。这样消息发送的延迟确实很低,但是吞吐量会变得很差。
设置一个大于 0 的值,可以让发送端在缓冲区没有满的情况下等待一段时间,累积 linger.ms 时间的数据一起发送。这样可以减少请求的数量,避免频繁发送太多小包,不会立即发送数据。这样增加了消息的时延(latency),但是提高了吞吐量(throughput)。
batch.size
KafkaProducer 在发送多条消息时,会把发往同一个 partition 的的消息当做一个 batch 批量发送。
batch.size 用于指定批量发送缓存内存区域的大小,注意这里不是条数,默认值是 16384(16KB)
当 batch 缓冲区满,缓冲区中所有的消息会被发送出去。这并不意味着 KafkaProducer 会等到 batch 满才会发,不然只有一条消息时,消息就一直发不出去了。linger.ms 和 batch.size 都会影响 KafkaProducer 的发送行为。
batch.size 值设置太小会降低吞吐量,太大会浪费内存。
我们线上的配置这两个值都没配置,会按 linger.ms=0,batch.size 为 16KB 的配置运行,因为日志产生的非常频繁,Sender 线程几乎不会闲下来,一直在处理发送数据包。
log4j2 的异步 Appender 潜在的坑
在做 Kafka 发送端的参数调整之前有一个风险点,log4j2 的异步 Appender 潜在的坑需要提前避免,否则会造成线上业务接口的大量超时。
log4j2 的异步 Appender 原理上是在本地利用了本地的一个 ArrayBlockingQueue 存储应用层发过来的消息,这个 queue 的大小默认值在 2.7 版本的 log4j2 中是 128,在高版本中,这个值已经被调为了 1024。如果 KafkaAppender 处理的比较慢,很快这个队列就填满,如下图所示。
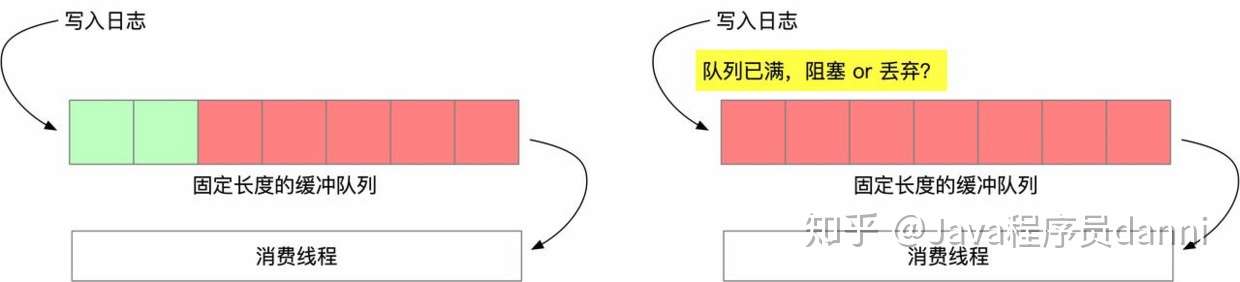
填满以后就涉及到是 blocking 等待,还是丢弃后面加入的日志的问题,比较坑的是 log4j2 的默认配置是 DefaultAsyncQueueFullPolicy,这个策略是同步阻塞等待当前线程。我们可以选择将这个值设置为丢弃,以保证不管底层的日志写入慢不慢,都不能影响上层的业务接口,大不了就丢弃部分日志。log4j 提供了配置项,将系统属性 log4j2.AsyncQueueFullPolicy 设置为 Discard 即可。
这还没完,设置了队列满的策略为 Discard 后,log4j 默认只会舍弃 INFO 及以下级别的日志。如果系统大量产生 WARN、ERROR 级别的日志,就算策略是 Discard 还是会造成阻塞上游线程,需要将 log4j2.DiscardThreshold 设置为 ERROR 或者 FATAL。
修改了 KafkaProducer 和 log4j 的参数以后,kafka 发送线程的 CPU 占用降低到了 5% 以下,整体的 CPU 负载依旧是比较高的,接下来继续排查。
万能的火焰图
一开始本来想用 perf、dtrace、systemtap 等工具来生成火焰图,无奈在 Docker 容器中没有 privileged 权限,我一一尝试了都无法运行上面的所有命令,好在是 Arthas 提供了火焰图生成的命令 profiler,它的原理是利用 async-profiler 对应用采样,生成火焰图。
使用 arthas Attach 上 JVM 进程以后,使用 profiler start 开始进行采样,运行一段时间后执行 profiler stop 就可以生成火焰图 svg 了,部分如下图所示。
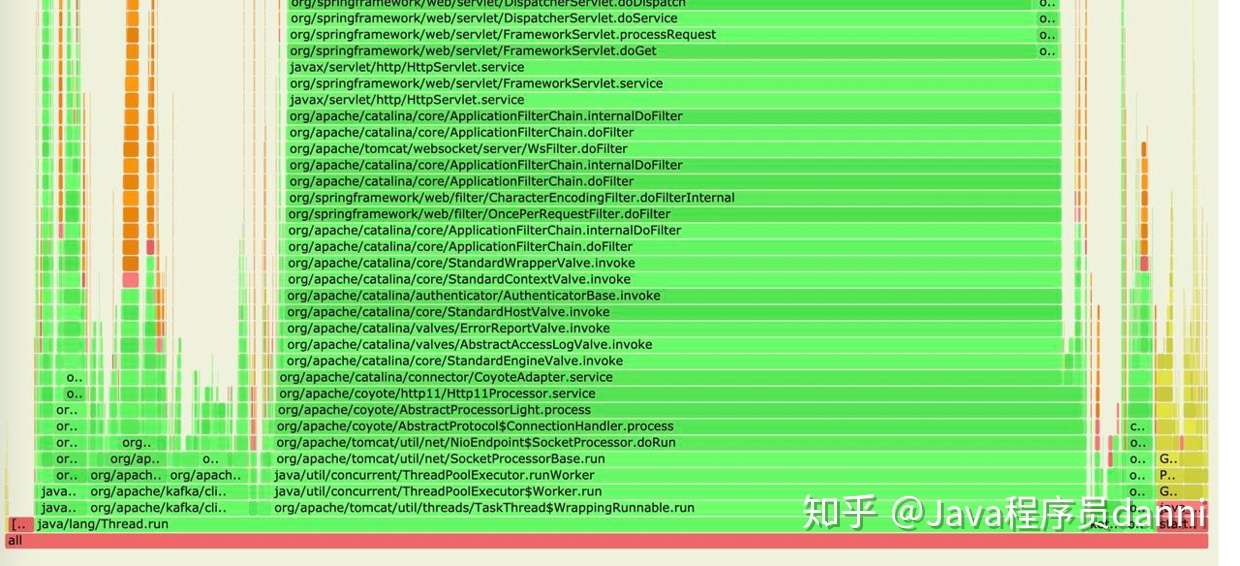
火焰图有几个特征:
- 每个框代表栈里的一个函数;
- Y 轴表示函数调用栈的深度,下层函数是上层函数的父调用。调用栈越深,火焰越高;
- X 轴不是表示时间的流逝,而是表示抽样数,一个函数在 X 轴的宽度越宽,表示它在采样中被抽到的次数越多,执行时间越长。
从上面的图可以看到 kafka 和 Spring 函数执行的 CPU 占用最多,kafka 的问题上面的内容可以优化,接下来我们来看 Spring 函数相关调用栈。
log4j 行号计算的代价
把 svg 放大,可以看到有一个顶一直都平很高,函数是 Log4jLogEvent.calcLocation,也就是 log4j 生成日志打印行数的计算的地方,如下图所示。

计算行号的原理实际上是通过获取当前调用堆栈来实现的,这个计算性能很差,具体有多慢,网上有很多 benchmark 的例子可以实测一下。
我们把 log4j 的行号输出关掉,CPU 占用又小了一点点,这个平顶的调用也不见了。
使用 Trie 前缀树来优化 Spring 本身的性能问题
继续分析占用高函数调用。因为历史的原因,我们在 url 设计上没有能提前考虑将不需要走鉴权的 url 放在同一个前缀路径下,导致 interceptor 的 exclude-mapping 配置有一百多个,如下所示。
<mvc:interceptors>
<mvc:interceptor>
<mvc:mapping path="/**"/>
<mvc:exclude-mapping path="/login"/>
<mvc:exclude-mapping path="/*/login"/>
<mvc:exclude-mapping path="/*/activity/teacher"/>
<mvc:exclude-mapping path="/masaike/dynamic/**"/>
...下面还有一百多个这样的 exclude...
<mvc:exclude-mapping path="/masaike/aaaa/**"/>
<mvc:exclude-mapping path="/masaike/**/hello"/>
<bean class="com.masaike.AuthenticationHandlerInterceptor"/>
</mvc:interceptor>
</mvc:interceptors>Spring MVC 处理这一段的逻辑在 org.springframework.web.servlet.handler.MappedInterceptor
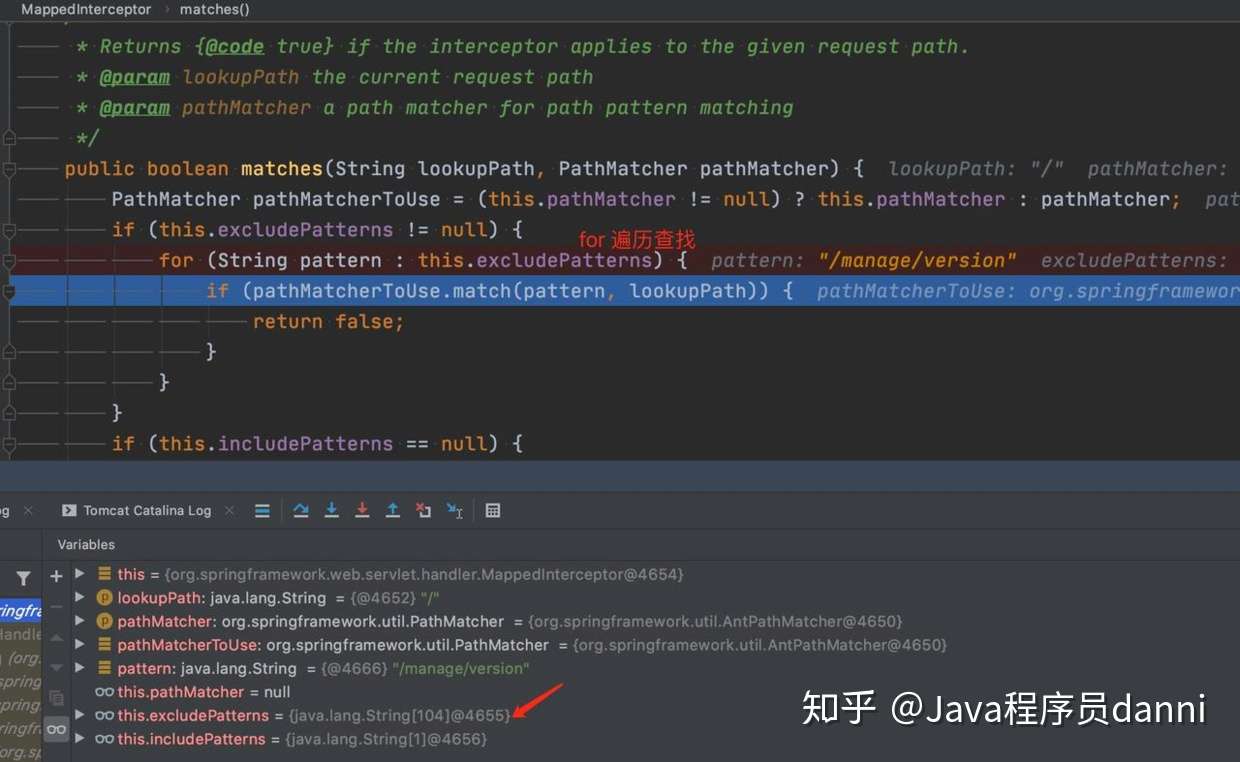
- 对于一个需要鉴权的接口,它会遍历整个 excludePatterns 列表
- 对于一个的确不需要鉴权的接口,for 循环会在中间 break。最坏的情况下,也需要遍历完所有的 excludePatterns 列表
这样效率太低了,我们完全可以优化这段逻辑,使用 trie 树来实现路径的匹配,与普通 trie 树有区别的地方在于,这里的 trie 树需要能支持中间带通配符 * 和 ** 的格式。
假如我们有下面这些路径:
"/api/*/login"
, "/wildcard/**"
, "/wildcard/**/hello"
, "/v2/hello/"
, "/v2/user/info/"
, "/v2/user/feed/"
, "/v2/user/feed2/"生成的 trie 树如下所示。
.
└──api
└──*
└──login
└──v2
└──hello
└──user
└──feed
└──feed2
└──info
└──wildcard
└──**实现倒是非常简单,每个 node 节点都有包含一个 map 表示的 child 列表,这样在查找的时候就非常快。
/**
* @author Arthur.Zhang (zhangya@imlizhi.com)
* 用于匹配 /a/b/c, *, ** 这种格式的前缀匹配
* 参考了 ZooKeeper 和 lucene 的 trie 实现
*/
public class PathTrie {
private Node root = new Node(emptyList(), null); public PathTrie() {
} public void insert(String path, String obj) {
List<String> parts = getPathSegments(path);
insert(parts, obj);
} public void insert(List<String> parts, String o) {
if (parts.isEmpty()) {
root.obj = o;
return;
}
root.insert(parts, o);
} private static List<String> getPathSegments(String path) {
return Splitter.on('/').splitToList(path).stream().filter(it -> !it.isEmpty()).collect(Collectors.toList());
} public boolean existsPath(String path) {
return root.exists(getPathSegments(path), 0);
} public void dump() {
if (root != null) root.dump();
} private static class Node {
String name;
Map<String, Node> children;
String obj; // 标识是否是叶子节点 Node(List<String> path, String obj) {
if (path.isEmpty()) {
this.obj = obj;
return;
}
name = path.get(0);
} private synchronized void insert(List<String> parts, String o) {
String part = parts.get(0);
Node matchedChild; // 如果是 **,后面的路径节点不用再插入了
if ("**".equals(name)) {
return;
}
if (children == null) children = new ConcurrentHashMap<>(); matchedChild = children.get(part);
if (matchedChild == null) {
matchedChild = new Node(parts, o);
children.put(part, matchedChild);
} // 移除已处理的
parts.remove(0);
if (parts.isEmpty()) { // 如果已经到底,将最后一个 child 的 obj 赋值
matchedChild.obj = o;
} else {
matchedChild.insert(parts, o); //还没有到底,继续递归插入
} } /**
* @param pathSegments 路径分割以后的 word 列表,比如 /a/b/c -> 'a' , 'b' , 'c'
* @param level 当前路径遍历的 level 深度,比如 /a/b/c -> 0='a' 1='b' 2='c'
*/
public boolean exists(List<String> pathSegments, int level) {
// 如果已经把传入的 path 遍历完了
if (pathSegments.size() < level + 1) {
// 如果当前 trie 树不是叶子节点
if (obj == null) {
// 获取叶子节点是否包含 **,如果包含的话,则匹配到
Node n = children.get("**");
if (n != null) {
return true;
}
}
return obj != null;
}
if (children == null) {
return false;
}
String pathSegment = pathSegments.get(level); // 1、首先找绝对匹配的
Node n = children.get(pathSegment);
// 2、如果不存在,则找是否包含 * 的
if (n == null) {
n = children.get("*");
}
// 3、如果还不存在,则找是否包含 ** 的
if (n == null) {
n = children.get("**");
if (n != null) {
return true;
}
}
// 4、如果这些都没有找到,则返回 false
if (n == null) {
return false;
}
// 5、如果找到了一个 node,则继续递归查找
return n.exists(pathSegments, level + 1);
} @Override
public String toString() {
return "Node{" +
"name='" + name + '\'' +
", children=" + children +
'}';
} /**
* 使用类似 tree 命令的输出格式打印这棵前缀数
* .
* └──api
* └──*
* └──login
* └──v2
* └──hello
* └──user
* └──feed
* └──feed2
* └──info
* └──wildcard
* └──**
*/
public void dump() {
dump(0);
} public void dump(int level) {
if (level == 0) {
System.out.println(".");
} else {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < level - 1; i++) {
sb.append("\t");
}
sb.append("└──").append(name);
System.out.println(sb.toString());
}
if (children != null && !children.isEmpty()) {
for (Map.Entry<String, Node> item : children.entrySet()) {
item.getValue().dump(level + 1);
}
}
}
}
}
采用 Trie 的实现之后,平均的 CPU 占比消耗降低了 5% 左右。
小结
整体优化以后,高峰期间的 CPU 占用从 100% 左右下降到了 35%,效果还是比较明显的。
性能优化是一个全栈的工程,能发现问题就已经解决了一大半了。另外光会命令是不够的,理解底层原理才能真正的有的放矢,发现问题的核心所在。
原文:https://zhuanlan.zhihu.com/p/138540082
一次线上服务高 CPU 占用优化实践 (转)的更多相关文章
- Linux(2)---记录一次线上服务 CPU 100%的排查过程
Linux(2)---记录一次线上服务 CPU 100%的排查过程 当时产生CPU飙升接近100%的原因是因为项目中的websocket时时断开又重连导致CPU飙升接近100% .如何排查的呢 是通过 ...
- 记一次线上服务CPU 100%的处理过程
告警 正在开会,突然钉钉告警声响个不停,同时市场人员反馈客户在投诉系统登不进了,报504错误.查看钉钉上的告警信息,几台业务服务器节点全部报CPU超过告警阈值,达100%. 赶紧从会上下来,SSH登录 ...
- 线上服务内存OOM问题定位[转自58沈剑]
相信大家都有感触,线上服务内存OOM的问题,是最难定位的问题,不过归根结底,最常见的原因: 本身资源不够 申请的太多 资源耗尽 58到家架构部,运维部,58速运技术部联合进行了一次线上服务内存OOM问 ...
- 线上服务CPU100%问题快速定位实战
功能问题,通过日志,单步调试相对比较好定位. 性能问题,例如线上服务器CPU100%,如何找到相关服务,如何定位问题代码,更考验技术人的功底. 58到家架构部,运维部,58速运技术部联合进行了一次线上 ...
- 线上服务CPU100%问题快速定位实战--转
来自微信公众号 架构师之路 功能问题,通过日志,单步调试相对比较好定位. 性能问题,例如线上服务器CPU100%,如何找到相关服务,如何定位问题代码,更考验技术人的功底. 58到家架构部,运维部,58 ...
- 线上服务的FGC问题排查,看这篇就够了!
线上服务的GC问题,是Java程序非常典型的一类问题,非常考验工程师排查问题的能力.同时,几乎是面试必考题,但是能真正答好此题的人并不多,要么原理没吃透,要么缺乏实战经验. 过去半年时间里,我们的广告 ...
- 线上服务的FGC问题排查
转载:https://blog.csdn.net/g6U8W7p06dCO99fQ3/article/details/106088467 线上服务的GC问题,是Java程序非常典型的一类问题,非常考验 ...
- 线上服务宕机,码农试用期被毕业,原因竟是给MySQL加个字段
1. 问题:怎么给线上表加字段? 工作中最常遇到的问题,怎么给线上频繁使用的大表添加字段? 比如:给下面的用户表(user)添加年龄(age)字段. CREATE TABLE `user` ( `id ...
- 线上服务内存OOM问题定位
转自:架构师之路,http://mp.weixin.qq.com/s/iOC1fiKDItn3QY5abWIelg 相信大家都有感触,线上服务内存OOM的问题,是最难定位的问题,不过归根结底,最常见的 ...
随机推荐
- oracle中connect by prior的使用
作用 connect by主要用于父子,祖孙,上下级等层级关系的查询 语法 { CONNECT BY [ NOCYCLE ] condition [AND condition]... [ START ...
- [opencv]拟合vector<Mat>集合区域接近的元素
vector<Rect> PublicCardFrameDetection::fitrect(vector<Rect> rects){ int size = rects.siz ...
- Java初学者作业——编写Java程序,在控制台中输入一个数字,要求定义方法实现找出能够整除该数字的所有数字。
返回本章节 返回作业目录 需求说明: 编写Java程序,在控制台中输入一个数字,要求定义方法实现找出能够整除该数字的所有数字. 实现思路: 定义方法findNums(),用于实现查找所有能够整除指定数 ...
- 中文字体css编码转换
各大网站的字体选择 网站 字体 腾讯 font: 12px "宋体","Arial Narrow",HELVETICA; 淘宝 font: 12px/1.5 t ...
- ECMA-262规范定义的七种错误类型
第一种:Error 所有错误的基本类型,实际上不会被抛出. 第二种:EvalError 执行eval错误时抛出. 第三种:ReferenceError 对象不存在是抛出. 第四种: ...
- spring-Ioc学习笔记
spring 是面向Bean的编程 Ioc (Inversion of Control) 控制反转/依赖注入(DI:Dependency Injection) Aop(Aspect Oriented ...
- store在模块化后,获取state中的值时undefined
目录结构 用this.$store.getters.showNotif ,加上模块名this.$store.getters.apply.showNotif都取不到值, 控制台打印store,发现这样的 ...
- 新增访客数量MR统计之数据库准备
关注公众号:分享电脑学习回复"百度云盘" 可以免费获取所有学习文档的代码(不定期更新)云盘目录说明:tools目录是安装包res 目录是每一个课件对应的代码和资源等doc 目录是一 ...
- Eclipse配置Maven3.5
原文: https://www.toutiao.com/i6494558327622599181/ 配置Maven 首先保证Java环境是有的(Maven 3.1以上 要求 JDK 1.6 或以上版本 ...
- vue中使用window.resize并去抖动优化
this.clientWidth = document.documentElement.clientWidth window.onresize = () => { this.clientWidt ...