深入浅出KMP
前言:曾经有次在阿里的面试中遇到这个基础的问题,当时知道有这么回事,可是时间久了便
想不起来,可能是不怎么用到,基本调用库什么的,还有个是理解不深刻,不能得到show
me the code 的程度,才会使得遗忘,现在从新翻出来,参看一下大家已经造的轮子,发现理解
更加深刻,这也就是写博客的魅力所在。
字符串匹配是计算机的基本任务之一。
举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?
许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。它以三个发明者命名,起头的那个K就是著名科学家Donald
Knuth。

这种算法不太容易理解,网上有很多解释,但读起来都很费劲。直到读到Jake
Boxer的文章,我才真正理解这种算法。下面,我用自己的语言,试图写一篇比较好懂的KMP算法解释。
1.

首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
7.
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.

因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
15.
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
16.
"部分匹配"的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
看到这应该对next数组的含义是清楚了,可是你依然发现教科书next数组求解程序简短抽象还是难以理解:
我们来看看下面的解释你或许就明白了:
2.next数组的求解思路
通过上文完全可以对kmp算法的原理有个清晰的了解,那么下一步就是编程实现了,其中最重要的就是如何根据待匹配的模版字符串求出对应每一位的最大相同前后缀的长度。先给出代码:

1 void makeNext(const char P[],int next[])
2 {
3 int q,k;//q:模版字符串下标;k:最大前后缀长度
4 int m = strlen(P);//模版字符串长度
5 next[0] = 0;//模版字符串的第一个字符的最大前后缀长度为0
6 for (q = 1,k = 0; q < m; ++q)//for循环,从第二个字符开始,依次计算每一个字符对应的next值
7 {
8 while(k > 0 && P[q] != P[k])//递归的求出P[0]···P[q]的最大的相同的前后缀长度k
9 k = next[k-1]; //不理解没关系看下面的分析,这个while循环是整段代码的精髓所在,确实不好理解
10 if (P[q] == P[k])//如果相等,那么最大相同前后缀长度加1
11 {
12 k++;
13 }
14 next[q] = k;
15 }
16 }
现在我着重讲解一下while循环所做的工作:
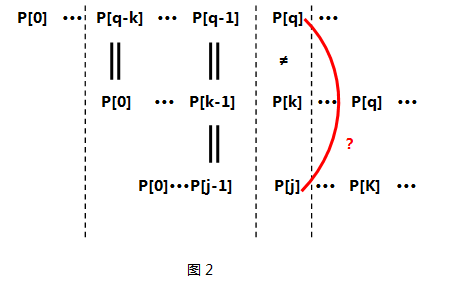
- 已知前一步计算时最大相同的前后缀长度为k(k>0),即P[0]···P[k-1];
- 此时比较第k项P[k]与P[q],如图1所示
- 如果P[K]等于P[q],那么很简单跳出while循环;
- 关键!关键有木有!关键如果不等呢???那么我们应该利用已经得到的next[0]···next[k-1]来求P[0]···P[k-1]这个子串中最大相同前后缀,可能有同学要问了——为什么要求P[0]···P[k-1]的最大相同前后缀呢???是啊!为什么呢? 原因在于P[k]已经和P[q]失配了,而且P[q-k]
··· P[q-1]又与P[0] ···P[k-1]相同,看来P[0]···P[k-1]这么长的子串是用不了了,那么我要找个同样也是P[0]打头、P[k-1]结尾的子串即P[0]···P[j-1](j==next[k-1]),看看它的下一项P[j]是否能和P[q]匹配。如图2所示

深入浅出KMP的更多相关文章
- KMP算法-->深入浅出
说明: 在网上查了各种资料,终于对KMP算法有了透彻的了解,都说KMP特简单,我咋没有察觉呢?难道是智商不在线?或许都是骗纸? 还是进入正题吧,整理整理大佬的blog KMP算法简介: KMP算法是一 ...
- 【深入浅出jQuery】源码浅析--整体架构
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- KMP算法求解
// KMP.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include<iostream> using namespac ...
- 简单有效的kmp算法
以前看过kmp算法,当时接触后总感觉好深奥啊,抱着数据结构的数啃了一中午,最终才大致看懂,后来提起kmp也只剩下“奥,它是做模式匹配的”这点干货.最近有空,翻出来算法导论看看,原来就是这么简单(先不说 ...
- 【深入浅出jQuery】源码浅析2--奇技淫巧
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- 深入浅出Struts2+Spring+Hibernate框架
一.深入浅出Struts2 什么是Struts2? struts2是一种基于MVC的轻量级的WEB应用框架.有了这个框架我们就可以在这个框架的基础上做起,这样就大大的提高了我们的开发效率和质量,为公司 ...
- DOM 事件深入浅出(二)
在DOM事件深入浅出(一)中,我主要给大家讲解了不同DOM级别下的事件处理程序,同时介绍了事件冒泡和捕获的触发原理和方法.本文将继续介绍DOM事件中的知识点,主要侧重于DOM事件中Event对象的属性 ...
- DOM 事件深入浅出(一)
在项目开发时,我们时常需要考虑用户在使用产品时产生的各种各样的交互事件,比如鼠标点击事件.敲击键盘事件等.这样的事件行为都是前端DOM事件的组成部分,不同的DOM事件会有不同的触发条件和触发效果.本文 ...
- KMP算法
KMP算法是字符串模式匹配当中最经典的算法,原来大二学数据结构的有讲,但是当时只是记住了原理,但不知道代码实现,今天终于是完成了KMP的代码实现.原理KMP的原理其实很简单,给定一个字符串和一个模式串 ...
随机推荐
- Noip模拟17 2021.7.16
我愿称这场考试为STL专练 T1 世界线 巧妙使用$bitset$当作vis数组使用,内存不会炸,操作还方便,的确是极好的. 但是这个题如果不开一半的$bitset$是会炸内存的,因为他能开得很大,但 ...
- 2021.8.21考试总结[NOIP模拟45]
T1 打表 由归纳法可以发现其实就是所有情况的总和. $\frac{\sum_{j=1}^{1<<k}(v_j-v_{ans})}{2^k}$ $code:$ 1 #include< ...
- Spring IOC(控制反转)和DI(依赖注入)原理
一.Spring IoC容器和bean简介 Spring Framework实现了控制反转(IoC)原理,IoC也称为依赖注入(DI). 这是一个过程,通过这个过程,对象定义它们的依赖关系,即它们使用 ...
- 『学了就忘』Linux基础 — 13、Linux系统的分区和格式化
目录 1.Linux系统的分区 (1)磁盘分区定义 (2)两种分区表形式 (3)MBR分区类型 2.Linux系统的格式化 (1)格式化定义 (2)格式化说明 1.Linux系统的分区 (1)磁盘分区 ...
- Linux的inode与block
1,inode包含文件的元信息,具体来说有以下内容: 文件的字节数 文件拥有者的User ID 文件的Group ID 文件的读.写.执行权限 文件的时间戳,共有三个:ctime指inode上次文件属 ...
- Linux&C ——信号以及信号处理
linux信号的简单介绍 信号的捕捉和处理 信号处理函数的返回 信号的发送 信号的屏蔽 一:linux信号的简单介绍. 信号提供给我们一种异步处理事件的方法,由于进程之间彼此的地址空间是独立的,所以进 ...
- 【java+selenium3】自动化基础小结+selenium原理揭秘 (十七)
一.自动化实现原理 1.创建驱动对象 (1) 首先加载浏览器安装目录下的exe文件 (2) 其次是加载可执行驱动的exe文件,监听等待客户端发送的web service请求. 底层原理如下: 1. ...
- 前端调试工具DevTools处理网络请求
DevTools处理网络请求 位置:network 1.是否启用网络处理功能 2.清除历史 3.过滤器,自定义筛选 4.是否保留先前的历史,因为每次刷新会删除历史重新加载,选中后新老请求都在可做对比 ...
- 带你理解MST性质
写在前面 最小生成树的引出 假设要在n个城市之间建立通信联络网,则连通n个城市需要n-1条线路.在这种情况下,我们自然需要考虑一个问题,如何在最节省经费的条件下建立这个网络? 很自然地我们会想到,将各 ...
- Windows内核中的CPU架构-8-任务段TSS(task state segment)
Windows内核中的CPU架构-8-任务段TSS(task state segment) 任务段tss(task state segment)是针对于CPU的一个概念. 举一个简单的例子,你一个电脑 ...