(数据科学学习手札129)geopandas 0.10版本重要新特性一览
本文示例代码及文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
就在前不久,我们非常熟悉的Python地理空间分析库geopandas更新到了0.10.0版本,而伴随最近一段时间其针对新版本的一些潜在bug进行的修复,写作本文时最新的正式版本为0.10.2。此次0.10.x版本为我们带来了诸多令人兴奋的新功能新特性,本文就将带大家一睹其中一些比较重要的内容。

2 geopandas 0.10版本重要新特性一览
如果你已经安装了旧版本的geopandas,那么推荐执行下列命令进行geopandas的更新:
conda update geopandas -c https://mirrors.sjtug.sjtu.edu.cn/anaconda/cloud/conda-forge -y
而如果你还没有安装geopandas,那么下面的安装方式是最稳妥的:
conda install geopandas=0.10.2 -c https://mirrors.sjtug.sjtu.edu.cn/anaconda/cloud/conda-forge -y
pip uninstall rtree -y
pip install rtree -i https://pypi.douban.com/simple/
pip install pygeos -i https://pypi.douban.com/simple/
安装/更新完成后,检验一下geopandas是否被正确安装:

下面我们就来看看这次版本更新中有哪些重要新变动吧~
2.1 新增空间最近连接方法sjoin_nearest()
我们都知道利用geopandas中的sjoin(),可以完成基于多种空间拓扑关系的空间连接操作。
但有些时候我们需要判断的并不是左右两表中矢量列相交、包含等直接的拓扑关系,而是左右两表矢量列之间距离至少xx米这类的空间距离关系判断,这在旧版本的geopandas中,通常可以左右两边分别做缓冲区后进行常规空间连接来实现。
而这次新增的sjoin_nearest()就可以支持我们开展上述分析计算功能,它的主要参数有:
- left_df:连接对应的左
GeoDataFrame - right_df:连接对应的右
GeoDataFrame - how:设置连接方式,可选的有
'left'、'right'及'inner',默认为'inner' - max_distance:重要参数,用于设置最大搜索距离阈值,当矢量间的距离小于此阈值时才会进行连接
- lsuffix:设置左表重名字段后缀文字,默认为
'left' - rsuffix:设置右表重名字段后缀文字,默认为
'right' - distance_col:设置连接结果表中记录对应矢量间距离的字段名称,默认不设置时不会在结果表中添加距离信息
下面我们来通过一个简单的例子来体验这个功能:
import geopandas as gpd
from shapely.geometry import Point
# 构造示例点要素表1
gdf1 = gpd.GeoDataFrame(
{
'id1': list('abc'),
'geometry': [
Point(0, 0),
Point(1, 0),
Point(-1, 0)
]
}
)
# 构造示例点要素表2
gdf2 = gpd.GeoDataFrame(
{
'id2': list('def'),
'geometry': [
Point(0.4, 0),
Point(1.2, 0),
Point(-1.3, 0)
]
}
)
ax = gdf1.plot(color='red')
ax = gdf2.plot(color='green', ax=ax)
ax.axis('equal');
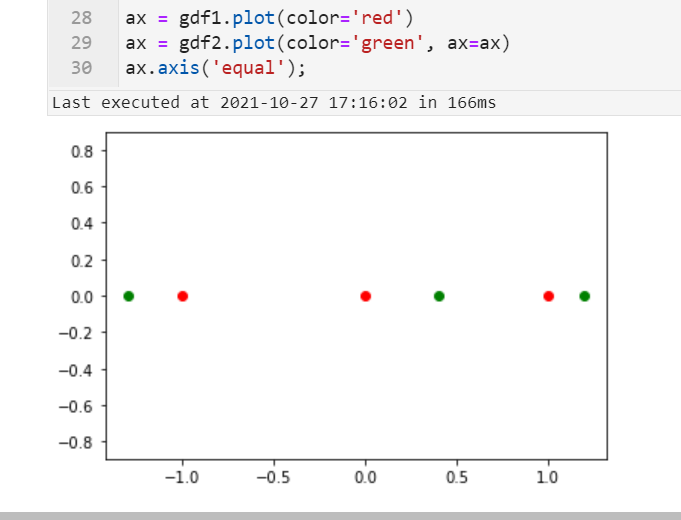
颜色即用来区分我们的左右表对应矢量点位置,下面直接运用sjoin_nearest()进行空间最近连接,设置的距离阈值为0.35:
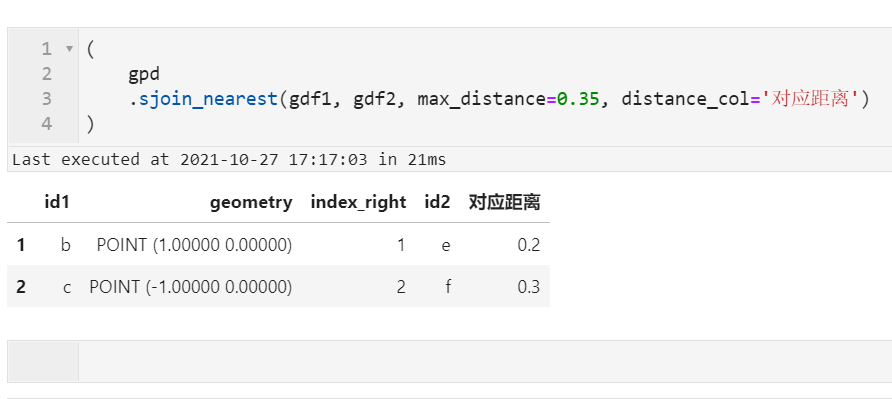
(
gpd
.sjoin_nearest(gdf1, gdf2, max_distance=0.35, distance_col='对应距离')
)
非常的方便快捷:
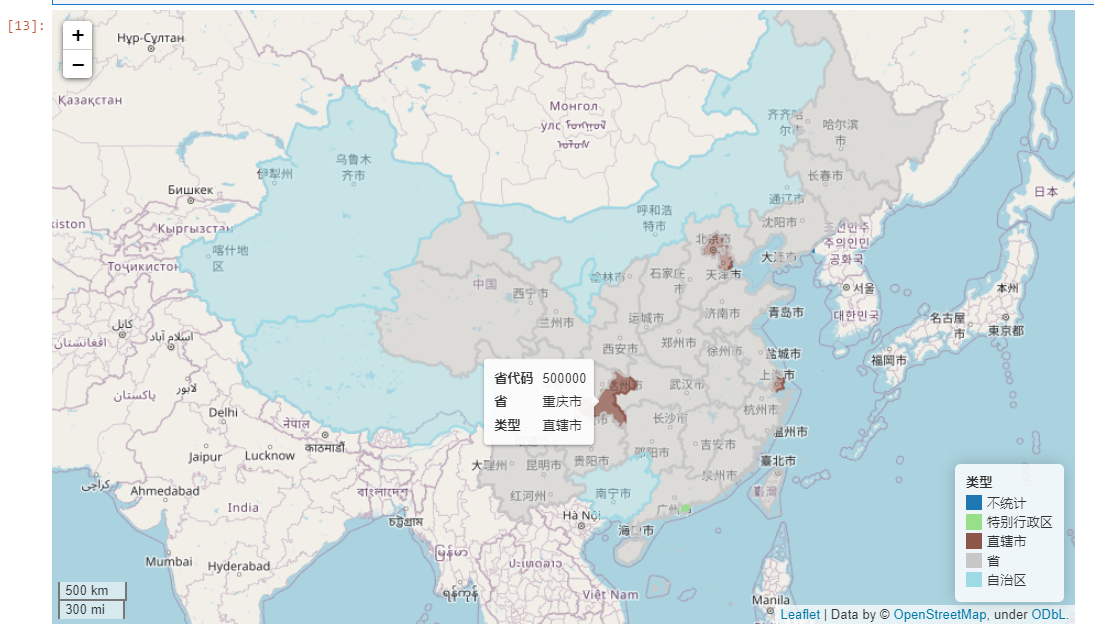
2.2 新增交互地图式数据探索方法explore()
很多人都知道著名的在线地图可视化组件leaflet在Python中有对应的库folium,而在这次新版本中,geopandas为GeoDataFrame及GeoSeries对象新增交互式地图可视化方法explore(),你可以理解为交互式版本的plot()方法。
其参数设置较为丰富,我之后会单独写一篇文章来为大家介绍,下面展示一个简单易懂的例子(注意,如果你的矢量数据非常大,请不要用此方法绘图,在线地图方式适合较小的矢量数据):
provinces = gpd.read_file('省.shp')
provinces.head(3)
...
provinces.explore(
column='类型',
zoom_start=4
)
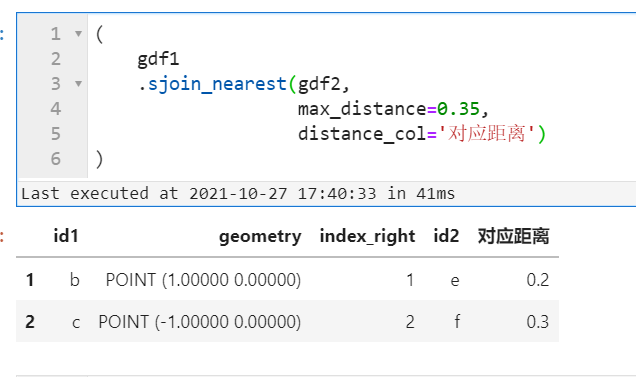
2.3 sjoin()、sjoin_nearest()、overlay()和clip()亦可作为GeoDataFrame的方法来使用
在以前的版本中,我们只能使用gpd.XXX()的方式来使用sjoin()、overlay()、clip()等方法,而在这次新版本更新中,我们可以像pandas里的merge()、join()那样作为方法使用,好处就是可以更好的书写链式运算过程啦!以上文介绍的sjoin_nearest()为例,只需向sjoin_nearest()方法中传入右表即可:
(
gdf1
.sjoin_nearest(gdf2,
max_distance=0.35,
distance_col='对应距离')
)
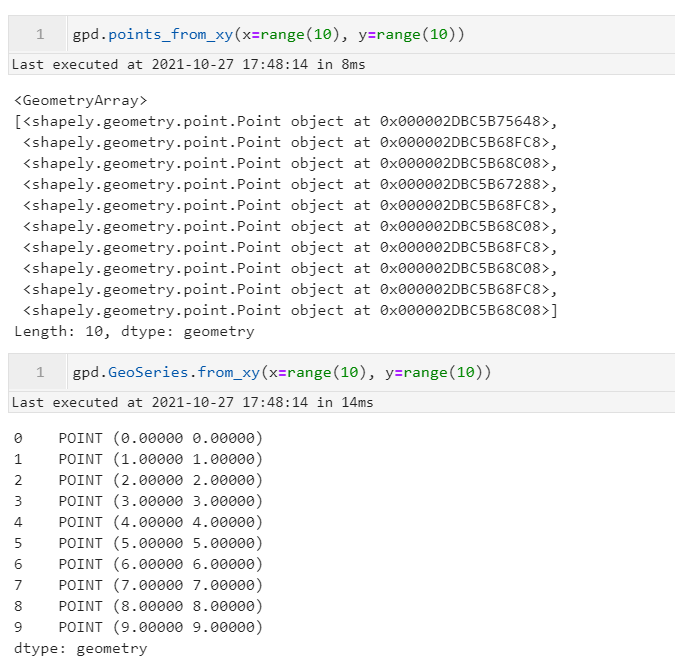
2.4 GeoSeries新增批量XY转点方法from_xy()
新版本中为GeoSeries对象新增了from_xy()方法来快速实现坐标转点,下面与gpd.points_from_xy()的效果进行对比:
gpd.points_from_xy(x=range(10), y=range(10))
...
gpd.GeoSeries.from_xy(x=range(10), y=range(10))
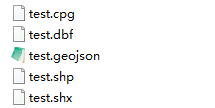
2.5 to_file()方法在driver参数缺省时可自动识别导出文件类型
在新版本中,若未在to_file()中指定driver参数,geopandas会自动根据文件后缀名来自动推断要导出的矢量文件类型:
import os
gdf1.to_file('test.shp')
gdf1.to_file('test.geojson')
[file for file in os.listdir() if 'test.' in file]

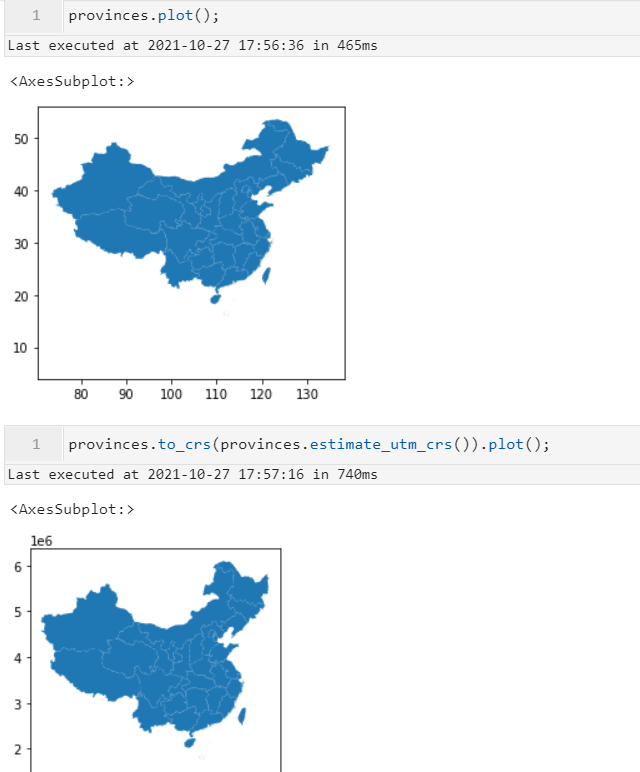
2.6 支持对矢量数据自动推断合适的横轴墨卡托坐标参考系
其实这个特性在0.9版本中就已加入,但是还有一些小问题,而新版本中这个功能更加完善,效果如下:
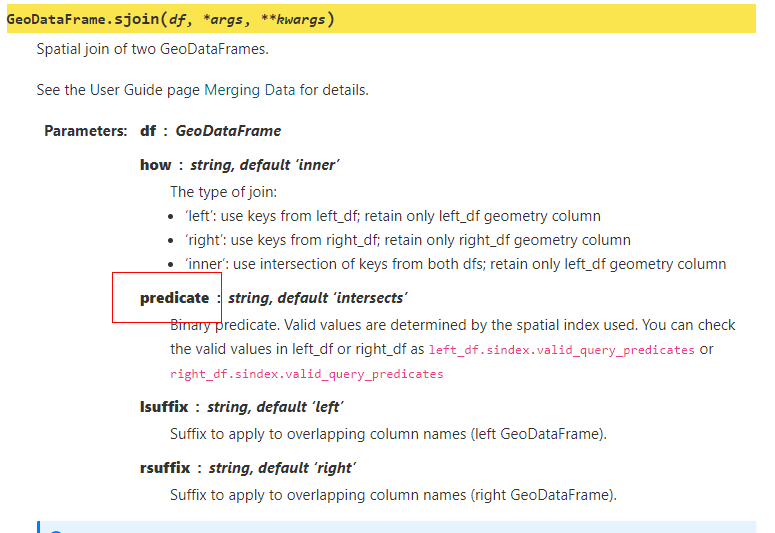
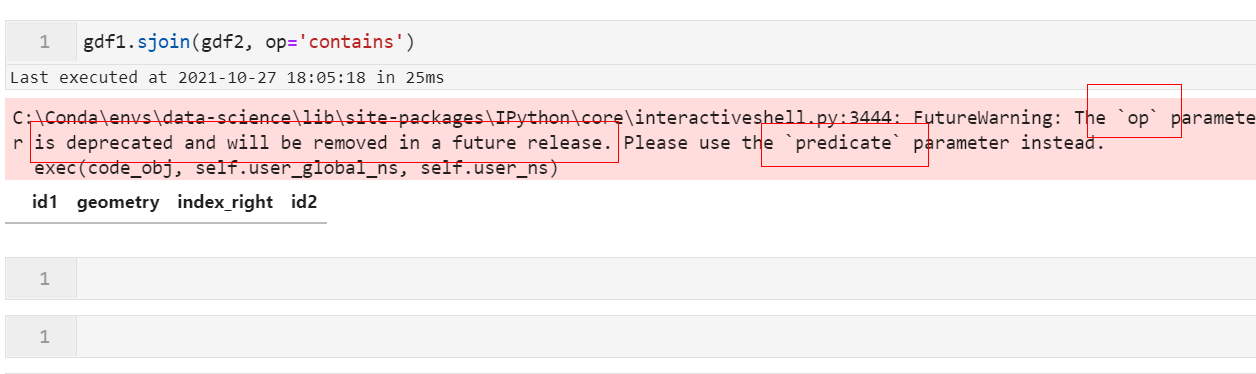
2.7 sjoin()中的op参数改名为predicate
为了让参数名更加的贴切,在以前版本sjoin()中用于设置拓扑关系的参数op在这次新版本中被改名为predicate,大家在使用时要留意:
大家在了解到这些新功能和变动后,在使用新版geopandas时,如果遇到未知bug,欢迎在https://github.com/geopandas/geopandas/issues及时提交说明,一起帮助geopandas变得更加好用和完善。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札129)geopandas 0.10版本重要新特性一览的更多相关文章
- (数据科学学习手札139)geopandas 0.11版本重要新特性一览
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,就在几天前,geopandas ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札130)利用geopandas快捷绘制在线地图
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中,我为大家介绍了不久前发布的 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
随机推荐
- java版gRPC实战之二:服务发布和调用
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- TCL、华星光电和中环股份,如何在一条生态链上领跑?
聚众智.汇众力.采众长. "我们决心用五年时间,将TCL科技和TCL实业做到真正的世界500强,将智能终端.半导体显示.半导体光伏三大核心产业力争做到全球领先,将半导体材料等其他产业做到中国 ...
- [第十五篇]——Swarm 集群管理之Spring Cloud直播商城 b2b2c电子商务技术总结
Swarm 集群管理 简介 Docker Swarm 是 Docker 的集群管理工具.它将 Docker 主机池转变为单个虚拟 Docker 主机. Docker Swarm 提供了标准的 Dock ...
- Centos6.5时间服务器NTP搭建
NTP时间服务器安装与配置 第1章 Server端的安装与配置 1.1 查看系统是否已经安装ntp服务组件 rpm -qa | grep "ntp" #<==查看是否已经安装 ...
- webgl 图像处理 加速计算
webgl 图像处理 webgl 不仅仅可以用来进行图形可视化, 它还能进行图像处理 图像处理1---数据传输 webgl 进行图形处理的第一步: 传输数据到 GPU 下图为传输点数据到 GPU 并进 ...
- Hyper-V + WSL2与 VirtualBox 共存
Hyper-V + WSL2与 VirtualBox 共存 这样的教程网上有很多,我先简单复述一下.真正麻烦的是我遇到的问题--开启 Hyper-V 后我的电脑会多出几个删不掉的虚拟显示器来,会在文章 ...
- linux centos windows服务器修改数据库最大连接数的方法
1.可查询数据库最大连接数 show variables like '%max_connections%'; 2.修改数据库最大连接数,最大限制上限为16384. 找到数据库配置文件my.cnf,在配 ...
- Chrome插件 - Modify Headers for Google Chrome(IP欺骗)
前景: 该篇随笔的由来:公司某项目(B/S架构)最近新加了一个后台日志功能,需要抓取到访问项目的主机IP,记录目标主机的操作,因此就需要不同得IP访问.并且项目专用浏览器是Chrome内核. Modi ...
- (原创)一步步优化业务代码之——从数据库获取DataTable并绑定到List<Class>
一,前言 现实业务当中,有一个很常见的流程:从数据库获取数据到DataTable,然后将DataTable绑定到实体类集合上,一般是List<Class>,代码写起来也简单:遍历+赋值就可 ...
- 微信小程序 创建自己的第一个小程序
* 成为微信公众平台的开发者 注册 https://mp.weixin.qq.com * 登录 https://open.weixin.qq.com/ * 开发者工具下载 https://develo ...