Coursera Deep Learning笔记 改善深层神经网络:超参数调试 Batch归一化 Softmax
摘抄:https://xienaoban.github.io/posts/2106.html
1. 调试(Tuning)
| 超参数 | 取值 |
|---|---|
| #学习速率:\(\alpha\) | |
| Momentum:\(\beta\) | 0.9:相当于10个值中计算平均值;0.999相当于1000个值中计算平均值 |
| Adam:\(\beta_1\) | 0.9 |
| Adam:\(\beta_2\) | 0.999 |
| Adam:\(\varepsilon\) | \(10^{-8}\) |
| #layers | |
| #hidden unit | |
| #mini-batch size |
参数选择有以下一些方法:
随机选择点。例如现在有 \(α\) 与 Adam 的 \(ε\) 两个超参数要调试。在参数取值范围内随机选择若干点, 可以发现哪个超参数更重要,影响更大.
由粗糙到精细的策略。由1, 发现在某个点效果最好,可以预测在该点附近效果也很好,于是放大这块区域, 更密集地取值.
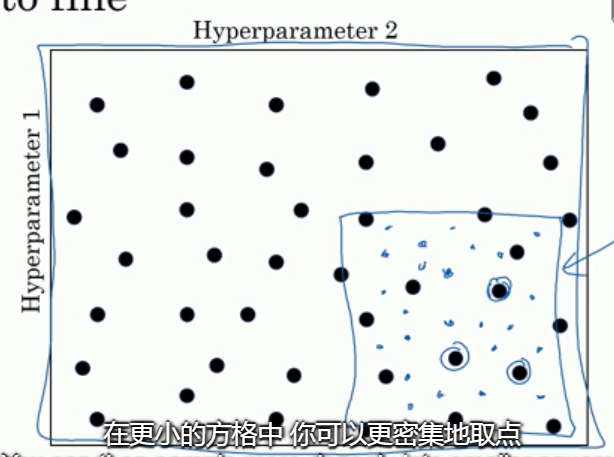
随机选择点时,有些参数不适合均匀(在线性轴上)的随机选择. 例如 \(\alpha\),我们希望其在对数轴上随机取点(0.0001, 0.001, 0.01, 0.1, 1),我们可以
a = 10**(-4*np.random.rand()),即可得到 \(a\in[10^{−4},10^0]\)对 \(\beta\) 取点,比如 \(\beta\)=0.9...0.999,\(1-\beta\) = 0.1...0.001, \(1-\beta\in[10^{−3},10^{-1}]\)
2. Batch 归一化(Batch Norm)
会使你的参数搜索问题变的容易,使神经网络对超参数的选择更加稳定,超参数的范围会更庞大,学习算法运行速度更快
2.1 实现
训练 Logistic 回归时, 归一化 \(X\) 可以加快学习过程. 现在我们希望对隐藏层的 \(Z\) 归一化. (或者 \(A\))
对每一层的\(z\), \(a\) 做如下操作:
方差:\sigma^2 = \frac{1}{m} \sum_i (z^{(i)} - \mu)^2 \\
z_{\text{norm}}^{(i)} = \frac{z^{(i)} - \mu}{\sqrt{\sigma^2 + \varepsilon}} \\
\widetilde{z}^{(i)} = \gamma z_{\text{norm}}^{(i)} + \beta
\]
(ε是为了防止分母为0.)
\(z_{norm}\) 就是标准化的 \(z\), \(z\)的每一个分量都含有 平均值为0, 方差为1。
不想让隐藏单元总是含有平均值0和方差1(也许隐藏单元有了不同的分布会有意义), 计算 \(\widetilde{z}\).
\(\gamma\) 与 \(\beta\) 是模型的学习参数, 梯度下降时会像更新神经网络的权重一样更新 \(\gamma\) 和 \(\beta\)。\(\gamma\) 与 \(\beta\) 的作用是:可以随意设置 \(\widetilde{z}^{(i)}\) 的平均值。当 \(\gamma = \sqrt{\sigma^2+\varepsilon}\) 且 \(\beta = \mu\) 时,\(\widetilde{z}^{(i)} = z^{(i)}\), 通过赋予 \(\gamma\) 和 \(\beta\) 其他值,可以使你构造含其他 平均值 和 方差 的隐藏单元值。
Batch归一化的作用:是它适合的归一化过程不只是输入层, 同样适用于神经网络中的深度隐藏层。Batch归一化了一些隐藏单元值中的平均值和方差。
2.2 将Batch Norm拟合进神经网络
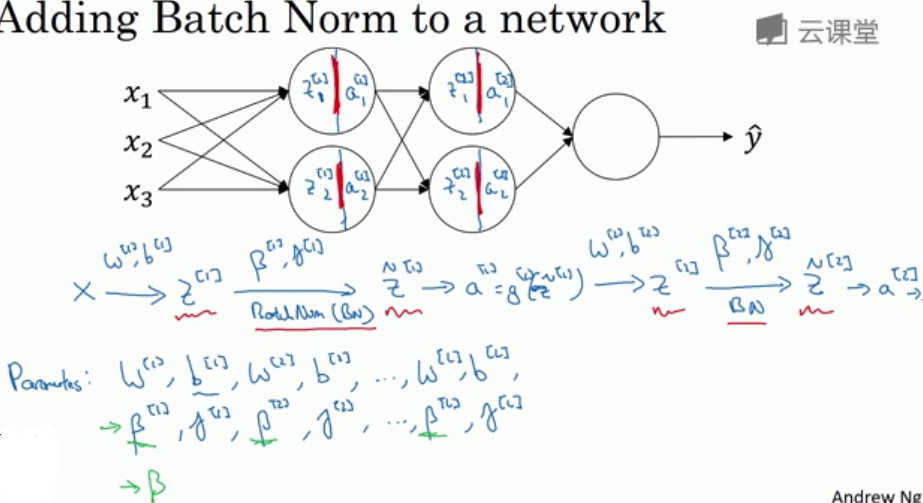


- 使用该方法时, 参数 w 和 b 中的 b 可以不设立, 毕竟 b 总是会被归一化减去. 于是参数只剩下了 \(w\), \(\beta\), \(\gamma\).
2.3 Batch Norm为什么奏效?
Batch 归一化减少了输入值改变的问题, 它使这些值变得更稳定,(例如:无论\(z^{[1]}\),\(z^{[2]}\)如何变化,他们的均值和方差保持不变),它减弱了 前层参数的作用 与 后层参数的作用 之间的联系, 它使得网络每层都可以自己学习, 稍稍独立于其它层, 有助于加速整个网络的学习.
另外, 每个 mini-batch 子数据集的均值和方差均有一些噪音, 而 Batch 归一化将 \(z\) 缩放到 \(\widetilde{z}\) 的过程也有噪音, 因此有轻微的正则化效果.
训练时,\(\mu\) 和 \(\sigma^2\) 是在整个 mini-batch 上计算出来的(包含了像是64或28或其他一定数量的样本);测试时,你可能需要逐一处理样本,方法是根据你的训练集估算 \(\mu\) 和 \(\sigma^2\),通常运用 指数加权平均 来追踪在训练过程中的 \(\mu\) 和 \(\sigma^2\)。
- 在测试时, 我们很可能只想测一个样本, 此时 均值 \(\mu\) 和 方差 \(\sigma\) 没有意义. 因此我们要使用估算的 \(\mu\) 和 \(\sigma\) 进行测试.
3. Softmax 回归
类似 Logistic 回归, 但 Softmax 回归能识别多个分类. 因此 \(\hat{y}\) 是 C×1 维的向量, 给出 C 个分类的概率,所有概率加起来应该为1.
在神经网络的最后一层, 我们像往常一样计算各层的线性部分, 当计算了 \(z^{[L]} = W^{[L]}a^{[L-1]}+b^{[L]}\) 之后, 使用 Softmax 激活函数.
\]
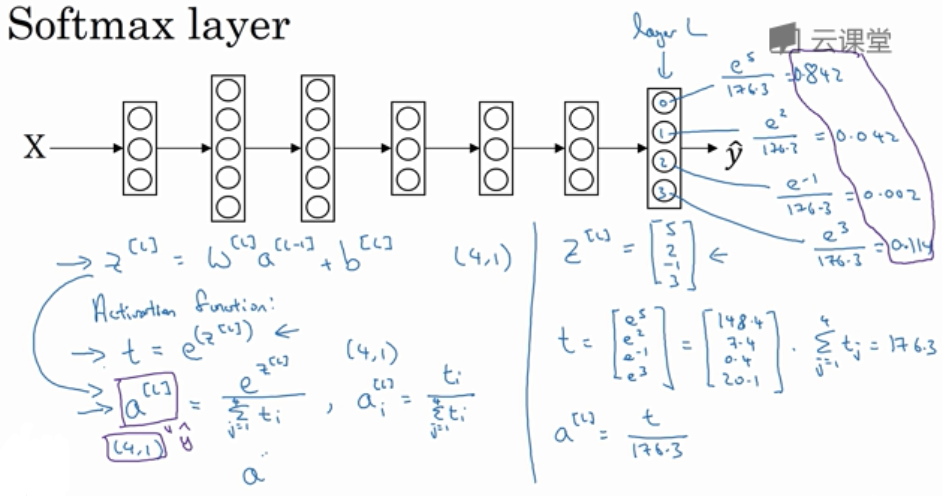
Softmax 分类中, 一般使用的损失函数及反向传播的导数是
J(w^{[1]}, b^{[1]}, ...) = \frac{1}{m} \sum_{i=1}^m L(\hat{y}^{(i)}, y^{(i)}) \\
\frac{\partial J}{\partial z^{[L]}} = \hat{y} - y
\]
Softmax 给出的是每个分类的概率. 而对应的 Hardmax 则是将最大的元素输出为 1, 其余元素置 0.
Coursera Deep Learning笔记 改善深层神经网络:超参数调试 Batch归一化 Softmax的更多相关文章
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 正则化以及梯度相关
笔记:Andrew Ng's Deeping Learning视频 参考:https://xienaoban.github.io/posts/41302.html 参考:https://blog.cs ...
- Coursera Deep Learning笔记 改善深层神经网络:优化算法
笔记:Andrew Ng's Deeping Learning视频 摘抄:https://xienaoban.github.io/posts/58457.html 本章介绍了优化算法,让神经网络运行的 ...
- 跟我学算法-吴恩达老师(超参数调试, batch归一化, softmax使用,tensorflow框架举例)
1. 在我们学习中,调试超参数是非常重要的. 超参数的调试可以是a学习率,(β1和β2,ε)在Adam梯度下降中使用, layers层数, hidden units 隐藏层的数目, learning_ ...
- Coursera Deep Learning笔记 卷积神经网络基础
参考1 参考2 1. 计算机视觉 使用传统神经网络处理机器视觉的一个主要问题是输入层维度很大.例如一张64x64x3的图片,神经网络输入层的维度为12288. 如果图片尺寸较大,例如一张1000x10 ...
- Deeplearning.ai课程笔记-改善深层神经网络
目录 一. 改善过拟合问题 Bias/Variance 正则化Regularization 1. L2 regularization 2. Dropout正则化 其他方法 1. 数据变形 2. Ear ...
- Coursera Deep Learning笔记 逻辑回归典型的训练过程
Deep Learning 用逻辑回归训练图片的典型步骤. 笔记摘自:https://xienaoban.github.io/posts/59595.html 1. 处理数据 1.1 向量化(Vect ...
- Coursera Deep Learning笔记 结构化机器学习项目 (下)
参考:https://blog.csdn.net/red_stone1/article/details/78600255https://blog.csdn.net/red_stone1/article ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.10_1.12/梯度消失/梯度爆炸/权重初始化
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.10 梯度消失和梯度爆炸 当训练神经网络,尤其是深度神经网络时,经常会出现的问题是梯度消失或者梯度爆炸,也就是说当你训练深度网络时,导数或坡 ...
随机推荐
- 第07课:GDB 常用命令详解(下)
本课的核心内容: disassemble 命令 set args 和 show args 命令 tbreak 命令 watch 命令 display 命令 disassemble 命令 当进行一些高级 ...
- 第06课:GDB 常用命令详解(中)
本课的核心内容: info 和 thread 命令 next.step.util.finish.return 和 jump 命令 info 和 thread 命令 在前面使用 info break 命 ...
- iframe 内容适用高度
HTML: <div class="content"> <iframe id="frameObj" src="链接" fr ...
- jQuery判断多种数据类型
1.判断是否为数组类型 var obj=[0]; alert((typeof obj=='object')&&obj.constructor==Array) 2. 判断是否为字符串 ...
- MySQL索引、事务、存储引擎
一.MySQL 索引 1.索引的概念 ●索引是一个排序的列表,在这个列表中存储着索引的值和包含这个值的数据所在行的物理地址(类似于C语言的链表通过指针指向数据记录的内存地址).●使用索引后可以不用扫描 ...
- JDK 1.7 正式发布,Oracle 官宣免费提供!“新版任你发,我用JDK 8”或成历史?
Oracle公司JDK 17正式发布,JDK 17属于长期支持(LTS)版本,也就是获得8年的技术支持,自2021年9月至2029年9月截止. JDK 17版本更新了很多比较实用的新特性,关于此版本的 ...
- [第一篇]——Docker 教程之Spring Cloud直播商城 b2b2c电子商务技术总结
Docker 教程 Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源. Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级.可移植的容器中,然 ...
- MySQL查询结果集字符串操作之多行合并与单行分割
前言 我们在做项目写sql语句的时候,是否会遇到这样的场景,就是需要把查询出来的多列,按照字符串分割合并成一列显示,或者把存在数据库里面用逗号分隔的一列,查询分成多列呢,常见场景有,文章标签,需要吧查 ...
- 昭山欢node资料学习笔记
以前学过一片node工作没有用,忘了,趁这个春节在整理一片 第一章 快速塔建一个局哉网服务器 const http = require("http");var server = h ...
- 取得get参数 从url
1. getUrlParam.js define(function() { // url参数 var data, index; (function init() { data = []; index ...