第八节,配置分布式TensorFlow
由于随着神经网络层数的增多,需要训练的参数也会增多,随之而来需要的数据集就会很大,这样会造成需要更大的运算资源,而且还要消耗很长的运算时间。TensorFlow提供了一个可以分布式部署的模式,将一个训练任务拆分成多个小任务,配置到不同的计算机上完成协同运算,这样使用计算机群运算来代替单机运算,可以使训练时间大幅度缩短。
一 分布式TensorFlow角色以及原理
要想配置TensorFlow为分布训练,首先需要了解TensorFlow中关于分布式的角色分配。
- ps:作为分布式训练的服务端,等到各个终端(supervisors)来连接。
- worker:在TensorFlow的代码注释中被称为supervisors,作为分布式训练的运算终端。
- chief supervisors:在众多运算终端中必须选中一个作为主要的运算终端。该终端是在运算终端中最先启动的,它的功能是合并各个终端运算后的学习参数,将其保存再写入。
每个具体角色网络标识都是唯一的,即分布在不同IP的机器上(或者同一主机但不同端口号)。
在实际运行中,各个角色的网络构建部分代码必须完全相同。三者的分工如下:
- 服务器端作为一个多方协调者,等待各个运算终端来连接。
- cheif supervisors会在启动时统一管理全局的学习参数,进行初始化或从模型载入。
- 其它的运算终端只是负责得到其相应的任务并进行计算,并不会保存检查点以及用于TensorBoard可视化的summary日志等任何参数信息。
二 分布部署TensorFlow的具体方法
配置过程中,首先创建一个server,在server中会将ps以及所有worker的ip端口准备好,接着使用tf.train.Supervisor中的managed_seesion来管理打开的session,session只负责运算,而通信协调的事情就都交给Supervisor来管理了。
三 使用TensorFlow实现分布式部署训练
下面开始实现一个分布式训练的网络模型,仍然以线性回归的模型作为原型,并将其改为分布式。使我们需要在本机通过3个端口来建立3个终端,分别是ps,两个worker。代码主要分为以下几部分:
1.为每个角色创建IP地址和端口,创建server
首先创建集群(cluster), ClusterSpec的定义,需要把你要跑这个任务的所有的ps和worker 的节点的ip和端口的信息都包含进去, 所有的角色都要执行这段代码, 就大家互相知道了, 这个集群里面都有哪些成员,不同的成员的类型是什么, 是ps还是worker。
然后创建一个server,在server中会将ps以及所有worker的ip端口准备好,在同一台电脑开三个不同的端口,分别代表ps,chief supervisors和worker。角色的名称用strjob_name表示。从 tf.train.Server这个的定义开始,就每个角色不一样了。 如果角色名字是ps的话, 程序就join到这里,作为参数更新的服务, 等待其他worker角色给它提交参数更新的数据。如果是worker角色,就执行后面的计算任务。以ps为例(先创建ps文件):
'''
(1)为每个角色添加IP地址和端口,创建server
''' '''定义IP和端口号'''
#指定服务器ip和port
strps_hosts = '127.0.0.1:1234'
#指定两个终端的ip和port
strworker_hosts = '127.0.0.1:1235,127.0.0.1:1236' #定义角色名称
strjob_name = 'ps'
task_index = 0
#将字符串转为数组
ps_hosts = strps_hosts.split(',')
worker_hosts = strworker_hosts.split(',') cluster_spec= tf.train.ClusterSpec({'ps':ps_hosts,'worker':worker_hosts}) #创建Server
server = tf.train.Server(
cluster_spec,
job_name = strjob_name,
task_index = task_index)
2.为ps角色添加等待函数
ps角色使用server.join()函数进行线程挂起,开始接受连接消息。
'''
(2) 为ps角色添加等待函数
'''
#ps角色处于监听状态,等待终端连接
if strjob_name == 'ps':
print('waiting....')
server.join()
3.创建网络结构
与正常的程序不同,在创建网络结构时,使用tf.device()函数将全部的节点都放在当前任务下。task:0对应worker1(可以理解为任务0对应着角色1),task:1对应worker2。
在rf.device()函数中的任务是通过tf.train.replica_device_setter()来指定的。
在tf.train.replica_device_setter()中使用worker_device()来定义具体任务名称:使用cluster的配置来指定角色和对应的ip地址,从而实现整个任务下的图节点,
'''
(3) 创建网络结构
'''
#设定训练集数据长度
n_train = 100 #生成x数据,[-1,1]之间,均分成n_train个数据
train_x = np.linspace(-1,1,n_train).reshape(n_train,1) #把x乘以2,在加入(0,0.3)的高斯正太分布
train_y = 2*train_x + np.random.normal(loc=0.0,scale=0.3,size=[n_train,1]) #绘制x,y波形
plt.figure()
plt.plot(train_x,train_y,'ro',label='y=2x') #o使用圆点标记一个点
plt.legend()
plt.show() #创建网络结构时,通过tf.device()函数将全部的节点都放在当前任务下 task:0对应worker1 task:1对应worker2
with tf.device(tf.train.replica_device_setter(
worker_device = '/job:worker/task:{0}'.format(task_index),
cluster = cluster_spec)): '''
前向反馈
'''
#创建占位符
input_x = tf.placeholder(dtype=tf.float32)
input_y = tf.placeholder(dtype=tf.float32) #模型参数
w = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='w') #设置正太分布参数 初始化权重
b = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='b') #设置正太分布参数 初始化偏置 #创建一个global_step变量
global_step = tf.train.get_or_create_global_step() #前向结构
pred = tf.multiply(w,input_x) + b #将预测值以直方图形式显示,给直方图命名为'pred'
tf.summary.histogram('pred',pred) '''
反向传播bp
'''
#定义代价函数 选取二次代价函数
cost = tf.reduce_mean(tf.square(input_y - pred)) #将损失以标量形式显示 该变量命名为loss_function
tf.summary.scalar('loss_function',cost) #设置求解器 采用梯度下降法 学习了设置为0.001 并把global_step变量放到优化器中,这样每运行一次优化器,globle_step就会自动获得当前迭代的次数
train = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(cost,global_step = global_step) saver = tf.train.Saver(max_to_keep = 1) #合并所有的summary
merged_summary_op = tf.summary.merge_all() #初始化所有变量,因此变量需要放在其前面定义
init =tf.global_variables_initializer()
为了使载入检查点文件能够同步循环次数,这里添加了一个global_step变量,将其放到优化器中。这样每运行一次优化器,global_step就会自动加1.
4.创建Supervisor,管理session
'''
(4)创建Supervisor,管理session
'''
training_epochs = 2000
display_step = 20 sv = tf.train.Supervisor(is_chief = (task_index == 0), #0号worker为chief
logdir='./LinearRegression/super/', #检查点和summary文件保存的路径
init_op = init, #初始化所有变量
summary_op = None, #summary_op用于自动保存summary文件,设置为None,表示不自动保存
saver = saver, #将保存检查点的saver对象传入,supervisor会自动保存检查点文件。否则设置为None
global_step = global_step,
save_model_secs = 50 #保存检查点文件的时间间隔
)
- 在tf.train.Supervisor()函数中,is_cheif表明了是否为cheif supervisors角色,这里将task_index = 0的worker设置成chief supervisors。
- logdir:为检查点和summary日志文件的保存路径。不过这个似乎启动就会去这个logdir的目录去看有没有checkpoint的文件, 有的话就自动装载了,没有就用init_op指定的初始化参数。
- init_op:表示使用初始化变量的函数。
- summary_op:将保存summary的对象传入,就会自动保存summary文件。这里设置为None,表示不自动保存。
- saver:将保存检查点的saver对象传入,Supervisor就会自动保存检查点文件。如果不想自动保存,就设置为None。
- global_step:为迭代次数。
- save_model_op:为保存检查点文件的时间间隔,这里设置成50,表明每50秒自动保存一次检查点文件。为了使程序运行时间长一些,我们更改了training_epochs参数。
5.迭代训练
session中的内容和之前的一样,直接迭代训练即可,由于使用了Supervisor管理session,将使用sv.summary_computed函数来保存summary文件,同样,如果想要手动保存监测点文件,也可以使用sv.saver.save()函数。
'''
(5) 迭代训练
'''
#连接目标角色创建session
with sv.managed_session(server.target) as sess:
print("sess ok:")
print(global_step.eval(session=sess))
print('开始迭代:') #存放批次值和代价值
plotdata = {'batch_size':[],'loss':[]} #开始迭代 这里step表示当前执行步数,迭代training_epochs轮 需要执行training_epochs*n_train步
for step in range(training_epochs*n_train):
for (x,y) in zip(train_x,train_y):
#开始执行图 并返回当前步数
_,step = sess.run([train,global_step],feed_dict={input_x:x,input_y:y}) #生成summary
summary_str = sess.run(merged_summary_op,feed_dict={input_x:x,input_y:y})
#将summary写入文件 手动保存summary日志文件
sv.summary_computed(sess,summary_str,global_step = step) #一轮训练完成后 打印输出信息
if step % display_step == 0:
#计算代价值
loss = sess.run(cost,feed_dict={input_x:train_x,input_y:train_y})
print('step {0} cost {1} w {2} b{3}'.format(step,loss,sess.run(w),sess.run(b))) #保存每display_step轮训练后的代价值以及当前迭代轮数
if not loss == np.nan:
plotdata['batch_size'].append(step)
plotdata['loss'].append(loss) print('Finished!')
#手动保存检查点文件
#sv.saver.save(sess,'./LinearRegression/sv/sv.cpkt',global_step = step) sv.stop()
- 在设置了自动保存检查点文件后,手动保存仍然有效。程序里我们在Supervisor对象创建的时候指定了自动保存检查点文件,程序里被我注释掉的最后一行是采用手动保存检查点文件。
- 在Supervisor对象创建的时候指定了不自动保存summary日志文件,我们采用了手动保存,调用了sv.summary_computed()函数。
- 在运行一半后终止,再运行Supervisor时会自动载入模型的参数,不需要手动调用saver.restore()。
- 在session中,不需要再运行tf.global_variables_initializer()函数。因为在Supervisor建立的时候回调用传入的init_op进行初始化,如果加了sess.run(tf.global_variables_initializer()),则会导致所载入模型的变量被二次清空。
6.建立worker文件
将ps.py文件复制两份,一个叫worker1.py,一个叫worker2.py。将角色名称修改为worker,并将worker2.py中的task_index修改为1。同时需要将worker2.py文件中手动保存summary日志的代码注释掉。
worker1.py文件修改如下:
#定义角色名称
strjob_name = 'worker'
task_index = 0
worker2.py文件修改如下:
#定义角色名称
strjob_name = 'worker'
task_index = 1
在这个程序中使用了sv.summary_computed()函数手动将运行时动态的数据保存下来,以便于在TensorBoard中查看,但是在分布式部署的时候,使用该功能还需要注意以下几点:
- worker2文件中不能使用sv.summary_computed()函数,因为worker2不是chief supervisors,在worker2中是不会为Supervisor对象构造默认summary_writer(所有的summary日志信息都要通过该对象进行写)对象的,所以即使程序调用sv.summary_computed()也无法执行下去,程序会报错。
- 手写控制summary日志和检查点文件保存时,需要将chief supervisors以外的worker全部去掉才可以,可以使用Supervisor按时间间隔保存的形式来管理,这样用一套代码就可以解决了。
7.部署运行
在spyder中先将ps.py文件运行起来,选择菜单Consoles->Open an Ipython console,新打开一个Consoles,如下图

在spider面板右下角,可以看到在原有标签为'Console 1/A'标签又多了一个‘Console 2/A’标签,选中这个标签,就激活了这个标签。
运行worker2.py文件。同理,启动'Console 3/A'运行worker1.py文件。

下面我们可以看到worker1.py文件的输出:

我们在程序中设置display_step为20,即迭代20次输出一次信息,我们可能看到这个输出并不是连续的,这是因为跳过的步骤被分配到了worker2中去运算了。
worker2.py文件对应的窗口显示的信息如下:
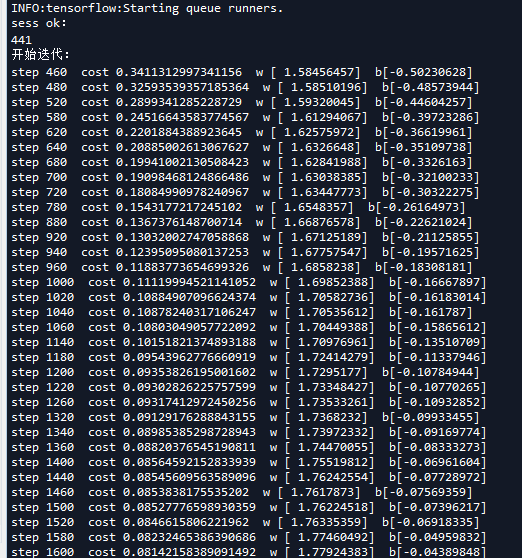
从图中可以看到worker2和chief supervisors的迭代顺序是互补,但也有可能是没有绝对互补的,但是为什么有时候没有绝对互补?可能与Supervisor中的同步算法有关。
分布运算的目的是为了提高整体运算速度,如果同步epoch的准确度需要以牺牲总体运算速度为代价,自然很不合适。所以更合理的推断是因为单机单次运算太快迫使算法使用了更宽松的同步机制。
重要的一点是对于指定步数的学习参数w和b是一致的。即统一迭代论述的值是一样的,这表明两个终端是在相同的起点上进行运算的。
对于ps.py文件,其对应的窗口一直默默的只显示打印的那句话waiting....,因为它只负责连接参与运算。

四 最后再补充一些名词解释
客户端(Client)
- 客户端是一个用于建立TensorFlow计算图并创立与集群进行交互的会话层
tensorflow::Session的程序。一般客户端是通过python或C++实现的。一个独立的客户端进程可以同时与多个TensorFlow的服务端相连 ,同时一个独立的服务端也可以与多个客户端相连。
集群(Cluster)
- 一个TensorFlow的集群里包含了一个或多个作业(job), 每一个作业又可以拆分成一个或多个任务(task)。集群的概念主要用与一个特定的高层次对象中,比如说训练神经网络,并行化操作多台机器等等。集群对象可以通过
tf.train.ClusterSpec来定义。
作业(Job)
- 一个作业可以拆封成多个具有相同目的的任务(task),比如说,一个称之为ps(parameter server,参数服务器)的作业中的任务主要是保存和更新变量,而一个名为worker(工作)的作业一般是管理无状态且主要从事计算的任务。一个作业中的任务可以运行于不同的机器上,作业的角色也是灵活可变的,比如说称之为”worker”的作业可以保存一些状态。
任务(Task)
- 任务相当于是一个特定的TesnsorFlow服务端,其相当于一个独立的进程,该进程属于特定的作业并在作业中拥有对应的序号。
TensorFlow服务端(TensorFlow server) 。
ps.py完整代码:
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 19 08:52:30 2018 @author: zy
""" import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt '''
分布式计算
''' '''
(1)为每个角色添加IP地址和端口,创建server
''' '''定义IP和端口号'''
#指定服务器ip和port
strps_hosts = '127.0.0.1:1234'
#指定两个终端的ip和port
strworker_hosts = '127.0.0.1:1235,127.0.0.1:1236' #定义角色名称
strjob_name = 'ps'
task_index = 0
#将字符串转为数组
ps_hosts = strps_hosts.split(',')
worker_hosts = strworker_hosts.split(',')
cluster_spec = tf.train.ClusterSpec({'ps': ps_hosts,'worker': worker_hosts}) #创建server
server = tf.train.Server(
cluster_spec,
job_name = strjob_name,
task_index = task_index) '''
(2) 为ps角色添加等待函数
'''
#ps角色处于监听状态,等待终端连接
if strjob_name == 'ps':
print('waiting....')
server.join() '''
(3) 创建网络结构
''' #设定训练集数据长度
n_train = 100 #生成x数据,[-1,1]之间,均分成n_train个数据
train_x = np.linspace(-1,1,n_train).reshape(n_train,1) #把x乘以2,在加入(0,0.3)的高斯正太分布
train_y = 2*train_x + np.random.normal(loc=0.0,scale=0.3,size=[n_train,1]) #绘制x,y波形
plt.figure()
plt.plot(train_x,train_y,'ro',label='y=2x') #o使用圆点标记一个点
plt.legend()
plt.show() #创建网络结构时,通过tf.device()函数将全部的节点都放在当前任务下
with tf.device(tf.train.replica_device_setter(
worker_device = '/job:worker/task:{0}'.format(task_index),
cluster = cluster_spec)): '''
前向反馈
'''
#创建占位符
input_x = tf.placeholder(dtype=tf.float32)
input_y = tf.placeholder(dtype=tf.float32) #模型参数
w = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='w') #设置正太分布参数 初始化权重
b = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='b') #设置正太分布参数 初始化偏置 #创建一个global_step变量
global_step = tf.train.get_or_create_global_step() #前向结构
pred = tf.multiply(w,input_x) + b #将预测值以直方图形式显示,给直方图命名为'pred'
tf.summary.histogram('pred',pred) '''
反向传播bp
'''
#定义代价函数 选取二次代价函数
cost = tf.reduce_mean(tf.square(input_y - pred)) #将损失以标量形式显示 该变量命名为loss_function
tf.summary.scalar('loss_function',cost) #设置求解器 采用梯度下降法 学习了设置为0.001 并把global_step变量放到优化器中,这样每运行一次优化器,global_step就会自动获得当前迭代的次数
train = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(cost,global_step = global_step) saver = tf.train.Saver(max_to_keep = 1) #合并所有的summary
merged_summary_op = tf.summary.merge_all() #初始化所有变量,因此变量需要放在其前面定义
init =tf.global_variables_initializer() '''
(4)创建Supervisor,管理session
'''
training_epochs = 2000
display_step = 20 sv = tf.train.Supervisor(is_chief = (task_index == 0), #0号worker为chief
logdir='./LinearRegression/super/', #检查点和summary文件保存的路径
init_op = init, #初始化所有变量
summary_op = None, #summary_op用于自动保存summary文件,设置为None,表示不自动保存
saver = saver, #将保存检查点的saver对象传入,supervisor会自动保存检查点文件。否则设置为None
global_step = global_step,
save_model_secs = 50 #保存检查点文件的时间间隔
) '''
(5) 迭代训练
'''
#连接目标角色创建session
with sv.managed_session(server.target) as sess:
print("sess ok:")
print(global_step.eval(session=sess))
print('开始迭代:') #存放批次值和代价值
plotdata = {'batch_size':[],'loss':[]} #开始迭代 这里step表示当前执行步数,迭代training_epochs轮 需要执行training_epochs*n_train步
for step in range(training_epochs*n_train):
for (x,y) in zip(train_x,train_y):
#开始执行图 并返回当前步数
_,step = sess.run([train,global_step],feed_dict={input_x:x,input_y:y}) #生成summary
summary_str = sess.run(merged_summary_op,feed_dict={input_x:x,input_y:y})
#将summary写入文件 手动保存summary日志文件
sv.summary_computed(sess,summary_str,global_step = step) #一轮训练完成后 打印输出信息
if step % display_step == 0:
#计算代价值
loss = sess.run(cost,feed_dict={input_x:train_x,input_y:train_y})
print('step {0} cost {1} w {2} b{3}'.format(step,loss,sess.run(w),sess.run(b))) #保存每display_step轮训练后的代价值以及当前迭代轮数
if not loss == np.nan:
plotdata['batch_size'].append(step)
plotdata['loss'].append(loss) print('Finished!')
#手动保存检查点文件
#sv.saver.save(sess,'./LinearRegression/sv/sv.cpkt',global_step = step) sv.stop()
worker1.py完整代码:
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 19 08:52:30 2018 @author: zy
""" import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt '''
分布式计算
''' '''
(1)为每个角色添加IP地址和端口,创建worker
''' '''定义IP和端口号'''
#指定服务器ip和port
strps_hosts = '127.0.0.1:1234'
#指定两个终端的ip和port
strworker_hosts = '127.0.0.1:1235,127.0.0.1:1236' #定义角色名称
strjob_name = 'worker'
task_index = 0
#将字符串转为数组
ps_hosts = strps_hosts.split(',')
worker_hosts = strworker_hosts.split(',')
cluster_spec = tf.train.ClusterSpec({'ps': ps_hosts,'worker': worker_hosts}) #创建server
server = tf.train.Server(
cluster_spec,
job_name = strjob_name,
task_index = task_index) '''
(2) 为ps角色添加等待函数
'''
#ps角色处于监听状态,等待终端连接
if strjob_name == 'ps':
print('waiting....')
server.join() '''
(3) 创建网络结构
''' #设定训练集数据长度
n_train = 100 #生成x数据,[-1,1]之间,均分成n_train个数据
train_x = np.linspace(-1,1,n_train).reshape(n_train,1) #把x乘以2,在加入(0,0.3)的高斯正太分布
train_y = 2*train_x + np.random.normal(loc=0.0,scale=0.3,size=[n_train,1]) #绘制x,y波形
plt.figure()
plt.plot(train_x,train_y,'ro',label='y=2x') #o使用圆点标记一个点
plt.legend()
plt.show() #创建网络结构时,通过tf.device()函数将全部的节点都放在当前任务下
with tf.device(tf.train.replica_device_setter(
worker_device = '/job:worker/task:{0}'.format(task_index),
cluster = cluster_spec)): '''
前向反馈
'''
#创建占位符
input_x = tf.placeholder(dtype=tf.float32)
input_y = tf.placeholder(dtype=tf.float32) #模型参数
w = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='w') #设置正太分布参数 初始化权重
b = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='b') #设置正太分布参数 初始化偏置 #创建一个global_step变量
global_step = tf.train.get_or_create_global_step() #前向结构
pred = tf.multiply(w,input_x) + b #将预测值以直方图形式显示,给直方图命名为'pred'
tf.summary.histogram('pred',pred) '''
反向传播bp
'''
#定义代价函数 选取二次代价函数
cost = tf.reduce_mean(tf.square(input_y - pred)) #将损失以标量形式显示 该变量命名为loss_function
tf.summary.scalar('loss_function',cost) #设置求解器 采用梯度下降法 学习了设置为0.001 并把global_step变量放到优化器中,这样每运行一次优化器,global_step就会自动获得当前迭代的次数
train = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(cost,global_step = global_step) saver = tf.train.Saver(max_to_keep = 1) #合并所有的summary
merged_summary_op = tf.summary.merge_all() #初始化所有变量,因此变量需要放在其前面定义
init =tf.global_variables_initializer() '''
(4)创建Supervisor,管理session
'''
training_epochs = 2000
display_step = 20 sv = tf.train.Supervisor(is_chief = (task_index == 0), #0号worker为chief
logdir='./LinearRegression/super/', #检查点和summary文件保存的路径
init_op = init, #初始化所有变量
summary_op = None, #summary_op用于自动保存summary文件,设置为None,表示不自动保存
saver = saver, #将保存检查点的saver对象传入,supervisor会自动保存检查点文件。否则设置为None
global_step = global_step,
save_model_secs = 50 #保存检查点文件的时间间隔
) '''
(5) 迭代训练
'''
#连接目标角色创建session
with sv.managed_session(server.target) as sess:
print("sess ok:")
print(global_step.eval(session=sess))
print('开始迭代:') #存放批次值和代价值
plotdata = {'batch_size':[],'loss':[]} #开始迭代 这里step表示当前执行步数,迭代training_epochs轮 需要执行training_epochs*n_train步
for step in range(training_epochs*n_train):
for (x,y) in zip(train_x,train_y):
#开始执行图 并返回当前步数
_,step = sess.run([train,global_step],feed_dict={input_x:x,input_y:y}) #生成summary
summary_str = sess.run(merged_summary_op,feed_dict={input_x:x,input_y:y})
#将summary写入文件 手动保存summary日志文件
sv.summary_computed(sess,summary_str,global_step = step) #一轮训练完成后 打印输出信息
if step % display_step == 0:
#计算代价值
loss = sess.run(cost,feed_dict={input_x:train_x,input_y:train_y})
print('step {0} cost {1} w {2} b{3}'.format(step,loss,sess.run(w),sess.run(b))) #保存每display_step轮训练后的代价值以及当前迭代轮数
if not loss == np.nan:
plotdata['batch_size'].append(step)
plotdata['loss'].append(loss) print('Finished!')
#手动保存检查点文件
#sv.saver.save(sess,'./LinearRegression/sv/sv.cpkt',global_step = step) sv.stop()
worker2.py完整代码:
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 19 08:52:30 2018 @author: zy
""" import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt '''
分布式计算
''' '''
(1)为每个角色添加IP地址和端口,创建worker
''' '''定义IP和端口号'''
#指定服务器ip和port
strps_hosts = '127.0.0.1:1234'
#指定两个终端的ip和port
strworker_hosts = '127.0.0.1:1235,127.0.0.1:1236' #定义角色名称
strjob_name = 'worker'
task_index = 1
#将字符串转为数组
ps_hosts = strps_hosts.split(',')
worker_hosts = strworker_hosts.split(',')
cluster_spec = tf.train.ClusterSpec({'ps': ps_hosts,'worker': worker_hosts}) #创建server
server = tf.train.Server(
cluster_spec,
job_name = strjob_name,
task_index = task_index) '''
(2) 为ps角色添加等待函数
'''
#ps角色处于监听状态,等待终端连接
if strjob_name == 'ps':
print('waiting....')
server.join() '''
(3) 创建网络结构
''' #设定训练集数据长度
n_train = 100 #生成x数据,[-1,1]之间,均分成n_train个数据
train_x = np.linspace(-1,1,n_train).reshape(n_train,1) #把x乘以2,在加入(0,0.3)的高斯正太分布
train_y = 2*train_x + np.random.normal(loc=0.0,scale=0.3,size=[n_train,1]) #绘制x,y波形
plt.figure()
plt.plot(train_x,train_y,'ro',label='y=2x') #o使用圆点标记一个点
plt.legend()
plt.show() #创建网络结构时,通过tf.device()函数将全部的节点都放在当前任务下
with tf.device(tf.train.replica_device_setter(
worker_device = '/job:worker/task:{0}'.format(task_index),
cluster = cluster_spec)): '''
前向反馈
'''
#创建占位符
input_x = tf.placeholder(dtype=tf.float32)
input_y = tf.placeholder(dtype=tf.float32) #模型参数
w = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='w') #设置正太分布参数 初始化权重
b = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='b') #设置正太分布参数 初始化偏置 #创建一个global_step变量
global_step = tf.train.get_or_create_global_step() #前向结构
pred = tf.multiply(w,input_x) + b #将预测值以直方图形式显示,给直方图命名为'pred'
tf.summary.histogram('pred',pred) '''
反向传播bp
'''
#定义代价函数 选取二次代价函数
cost = tf.reduce_mean(tf.square(input_y - pred)) #将损失以标量形式显示 该变量命名为loss_function
tf.summary.scalar('loss_function',cost) #设置求解器 采用梯度下降法 学习了设置为0.001 并把global_step变量放到优化器中,这样每运行一次优化器,global_step就会自动获得当前迭代的次数
train = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(cost,global_step = global_step) saver = tf.train.Saver(max_to_keep = 1) #合并所有的summary
merged_summary_op = tf.summary.merge_all() #初始化所有变量,因此变量需要放在其前面定义
init =tf.global_variables_initializer() '''
(4)创建Supervisor,管理session
'''
training_epochs = 2000
display_step = 20 sv = tf.train.Supervisor(is_chief = (task_index == 0), #0号worker为chief
logdir='./LinearRegression/super/', #检查点和summary文件保存的路径
init_op = init, #初始化所有变量
summary_op = None, #summary_op用于自动保存summary文件,设置为None,表示不自动保存
saver = saver, #将保存检查点的saver对象传入,supervisor会自动保存检查点文件。否则设置为None
global_step = global_step,
save_model_secs = 50 #保存检查点文件的时间间隔
) '''
(5) 迭代训练
'''
#连接目标角色创建session
with sv.managed_session(server.target) as sess:
print("sess ok:")
print(global_step.eval(session=sess))
print('开始迭代:') #存放批次值和代价值
plotdata = {'batch_size':[],'loss':[]} #开始迭代 这里step表示当前执行步数,迭代training_epochs轮 需要执行training_epochs*n_train步
for step in range(training_epochs*n_train):
for (x,y) in zip(train_x,train_y):
#开始执行图 并返回当前步数
_,step = sess.run([train,global_step],feed_dict={input_x:x,input_y:y}) #生成summary
summary_str = sess.run(merged_summary_op,feed_dict={input_x:x,input_y:y})
#将summary写入文件 手动保存summary日志文件
#sv.summary_computed(sess,summary_str,global_step = step) #一轮训练完成后 打印输出信息
if step % display_step == 0:
#计算代价值
loss = sess.run(cost,feed_dict={input_x:train_x,input_y:train_y})
print('step {0} cost {1} w {2} b{3}'.format(step,loss,sess.run(w),sess.run(b))) #保存每display_step轮训练后的代价值以及当前迭代轮数
if not loss == np.nan:
plotdata['batch_size'].append(step)
plotdata['loss'].append(loss) print('Finished!')
#手动保存检查点文件
#sv.saver.save(sess,'./LinearRegression/sv/sv.cpkt',global_step = step) sv.stop()
第八节,配置分布式TensorFlow的更多相关文章
- 学习笔记TF061:分布式TensorFlow,分布式原理、最佳实践
分布式TensorFlow由高性能gRPC库底层技术支持.Martin Abadi.Ashish Agarwal.Paul Barham论文<TensorFlow:Large-Scale Mac ...
- 【学习笔记】分布式Tensorflow
目录 分布式原理 单机多卡 多机多卡(分布式) 分布式的架构 节点之间的关系 分布式的模式 数据并行 同步更新和异步更新 分布式API 分布式案例 Tensorflow的一个特色就是分布式计算.分布式 ...
- 构建分布式Tensorflow模型系列:CVR预估之ESMM
https://zhuanlan.zhihu.com/p/42214716 本文是“基于Tensorflow高阶API构建大规模分布式深度学习模型系列”的第五篇,旨在通过一个完整的案例巩固一下前面几篇 ...
- 分布式tensorflow
分布式Tensorflow Tensorflow的一个特色就是分布式计算.分布式Tensorflow是由高性能的gRPC框架作为底层技术来支持的.这是一个通信框架gRPC(google remote ...
- 记录:CentOS 7 安装配置分布式文件系统 FastDFS 5.1.1
CentOS 7 安装配置分布式文件系统 FastDFS 5.1.1 软件下载:http://download.csdn.net/download/qingchunwuxian1993/9897458 ...
- 深度学习_1_神经网络_4_分布式Tensorflow
分布式Tensorflow 单机多卡(gpu) 多级多卡(分布式) 自实现分布式 API: 1,创建一个tf.train.ClusterSpec,用于对集群的所有任务进行描述,该描述对于所有任务相 ...
- 分布式TensorFlow集群local server使用详解
通过local server理解分布式TensorFlow集群的应用与实现. 简介 TensorFlow从0.8版本开始,支持分布式集群,并且自带了local server方便测试. Local ...
- 理解和实现分布式TensorFlow集群完整教程
手把手教你搭建分布式集群,进入生产环境的TensorFlow 分布式TensorFlow简介 前一篇<分布式TensorFlow集群local server使用详解>我们介绍了分布式Ten ...
- Tensorflow学习笔记4:分布式Tensorflow
简介 Tensorflow API提供了Cluster.Server以及Supervisor来支持模型的分布式训练. 关于Tensorflow的分布式训练介绍可以参考Distributed Tenso ...
随机推荐
- 【Python练习题】程序5
#题目:输入三个整数x,y,z,请把这三个数由小到大输出. # a = input('请输入整数: \n') # # b = input('请输入整数: \n') # # c = input('请输入 ...
- codeforces703B
Mishka and trip CodeForces - 703B 小米什卡是一个伟大的旅行者,她访问了许多国家.在这次考虑去哪里旅行之后,她选择了XXX--这个美丽,但鲜为人知的北方国家. 以下是关 ...
- iPhone
电报交流***vpnpay app不能用了,只要能下载就可以用,谨慎卸载 升级.网络链接不成功的,多试几次,毕竟程序不会运行你的错误操作 ,重新添加链接服务器,继续搞!耐心的进行下面操作即可链接,如有 ...
- Qt QLineEdit
//lineEdit显示文字 QLineEdit *lineEdit = new QLineEdit(widget); lineEdit->setObjectName(QString()); l ...
- Spring 使用介绍(四)—— SpEL
一.SpEL介绍 Spring表达式语言全称为“Spring Expression Language”,缩写为“SpEL”,可在运行时构建复杂表达式 使用步骤: 1)创建解析器:ExpressionP ...
- controller修改response返回值
1.responseBodyAdvice2. aop3.过滤器.拦截器
- zabbix 自定义 windows 监控项
zabbix获取windows服务器上数据C:\zabbix_agents\conf\zabbix_agentd.win.confUserParameter=conncount,d:\\tools\\ ...
- BZOJ 3514: Codechef MARCH14 GERALD07加强版(LCT + 主席树)
题意 \(N\) 个点 \(M\) 条边的无向图,询问保留图中编号在 \([l,r]\) 的边的时候图中的联通块个数. \(K\) 次询问强制在线. \(1\le N,M,K \le 200,000\ ...
- IDEA+Springboot+JRebel热部署实现
步骤一:在IDEA中安装JRebel插件(File->settings->plugins->search in repositories),如下图 步骤二:安装完成之后,重启idea ...
- Leetcode 345. 反转字符串中的元音字母 By Python
编写一个函数,以字符串作为输入,反转该字符串中的元音字母. 示例 1: 输入: "hello" 输出: "holle" 示例 2: 输入: "leet ...