Decision Trees:机器学习根据大量数据,已知年龄、收入、是否上海人、私家车价格的人,预测Ta是否有真实购买上海黄浦区楼房的能力—Jason niu
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO allElectronicsData = open(r'F:/AI/DL_month1201/01DTree/niu.csv', 'rt')
reader = csv.reader(allElectronicsData)
headers = next(reader)
print(headers)
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row)-1]) rowDict = {}
for i in range(1, len(row)-1):
rowDict[headers[i]] = row[i] featureList.append(rowDict) print(featureList) vec = DictVectorizer()
dummyX = vec.fit_transform(featureList) .toarray() print("dummyX: " + str(dummyX))
print(vec.get_feature_names()) print("labelList: " + str(labelList)) lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY)) clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf)) with open("niu.dot", 'w') as f:
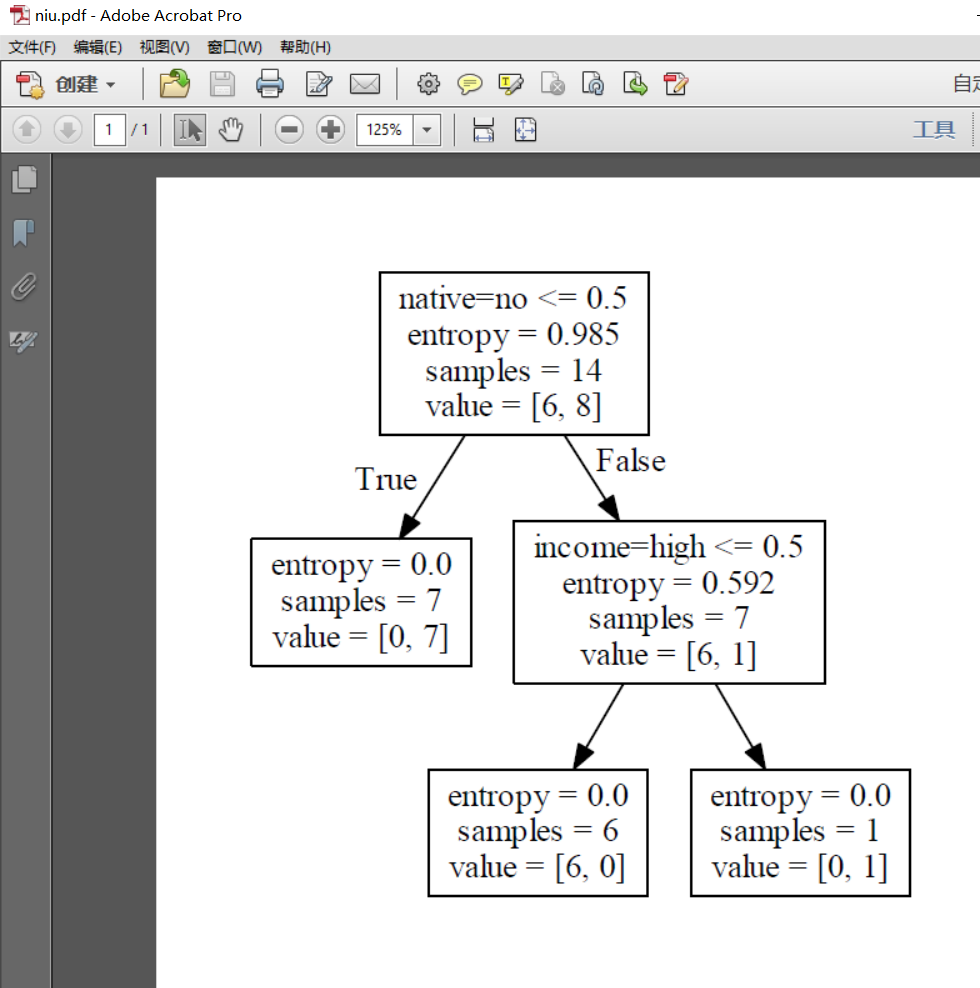
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f) oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX)) newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX)) predictedY = clf.predict([newRowX])
print("predictedY: " + str(predictedY))
Decision Trees:机器学习根据大量数据,已知年龄、收入、是否上海人、私家车价格的人,预测Ta是否有真实购买上海黄浦区楼房的能力—Jason niu的更多相关文章
- 机器学习算法 --- Decision Trees Algorithms
一.Decision Trees Agorithms的简介 决策树算法(Decision Trees Agorithms),是如今最流行的机器学习算法之一,它即能做分类又做回归(不像之前介绍的其他学习 ...
- 如何利用AI识别未知——加入未知类(不太靠谱),检测待识别数据和已知样本数据的匹配程度(例如使用CNN降维,再用knn类似距离来实现),将问题转化为特征搜索问题而非决策问题,使用HTM算法(记忆+模式匹配预测就是智能),GAN异常检测,RBF
https://www.researchgate.net/post/How_to_determine_unknown_class_using_neural_network 里面有讨论,说是用rbf神经 ...
- WCF数据契约代理和已知类型的使用
using Bll; using System; using System.CodeDom; using System.Collections.Generic; using System.Collec ...
- 机器学习算法 --- Pruning (decision trees) & Random Forest Algorithm
一.Table for Content 在之前的文章中我们介绍了Decision Trees Agorithms,然而这个学习算法有一个很大的弊端,就是很容易出现Overfitting,为了解决此问题 ...
- 《大数据日知录》读书笔记-ch15机器学习:范型与架构
机器学习算法特点:迭代运算 损失函数最小化训练过程中,在巨大参数空间中迭代寻找最优解 比如:主题模型.回归.矩阵分解.SVM.深度学习 分布式机器学习的挑战: - 网络通信效率 - 不同节点执行速度不 ...
- HDU - 6096 :String (AC自动机,已知前后缀,匹配单词,弱数据)
Bob has a dictionary with N words in it. Now there is a list of words in which the middle part of th ...
- sql 先查出已知的数据或者需要的数据再筛选
sql 先查出已知的数据或者需要的数据再筛选
- Logistic Regression vs Decision Trees vs SVM: Part II
This is the 2nd part of the series. Read the first part here: Logistic Regression Vs Decision Trees ...
- SIGAI机器学习第九集 数据降维2
讲授LDA基本思想,寻找最佳投影矩阵,PCA与LDA的比较,LDA的实际应用 大纲: 非线性降维算法流形的概念流形学习的概念局部线性嵌入拉普拉斯特征映射局部保持投影等距映射实验环节 非线性降维算法: ...
随机推荐
- 判断js数据类型的四种方法,以及各自的优缺点(转)
转载地址:https://blog.csdn.net/lhjuejiang/article/details/79623973 数据类型分为基本类型和引用类型: 基本类型:String.Number.B ...
- linux之ab压力测试工具
等待... https://www.cnblogs.com/myvic/p/7703973.html
- 用json获取拉钩网的信息
class LaoGo(object): def __init__(self): self.url="http://www.lagou.com/lbs/getAllCitySearchLab ...
- poj3107树的重心
/*树的重心求法:两次dfs,第一次dfs处理出每个结点的size,以此求每个结点大儿子的size,第二次dfs将每个结点大儿子的size和余下结点数进行比较,所有结点里两个值之间差值最小的那个点就是 ...
- Nginx详解二十:Nginx深度学习篇之HTTPS的原理和作用、配置及优化
一.HTTPS原理和作用: 1.为什么需要HTTPS?原因:HTTP不安全1.传输数据被中间人盗用.信息泄露2.数据内容劫持.篡改 2.HTTPS协议的实现对传输内容进行加密以及身份验证 对称加密:加 ...
- vue 在.vue文件里监听路由
监听路由 watch $route vue项目中的App.vue 文件 <template> <div id="app"> <!--includ ...
- Python获取当前时间及时间转换(datetime)
datetime是Python处理日期和时间的标准库 获取当前时间 import datetime day = datetime.datetime.now() day2 = datetime.date ...
- selenium 操作复选框
场景 从上一节的例子中可以看出,webdriver可以很方便的使用findElement方法来定位某个特定的对象,不过有时候我们却需要定位一组对象, 这时候就需要使用findElements方法. 定 ...
- win(64位)环境下oracle11g的安装方法
将压缩文件解压到一个目录中,该目录结构如下: 安装步骤(摘自网络): 1.进入数据库解压目录,双击其中的“setup.exe”文件,稍等片刻出现如下“配置安全更新“界面,取消“我希望通过My Orac ...
- hdu 5183(Hash处理区间问题)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5183 题意:给出一个n个元素的数组,现在要求判断 a1-a2+a3-a4+.....+/-an 中是否 ...