【原创】Thinking in BigData (1)大数据简介
提到大数据,就不得不提到Hadoop,提到Hadoop,就不得不提到Google公布的3篇研究论文:GFS、MapReduce、BigTable,Google确实是一家伟大的公司,开启了全球的大数据时代,
在《后谷歌时代:大数据的没落与区块链经济的崛起》中如此说道:
googol一词的意思是10的100次方--一个大到不可思议的数字。
...
随着岁月的流逝,谷歌几乎数字化了世界上所有可以获取的图书(2005),数字化了世界语言这个大织锦挂毯上的所有语言及其翻译(2010),数字化了这个星球的地形(谷歌地图和谷歌地球,2007),甚至细致到了各个街道的面貌和结构(街景)以及其交通状况(位智,2016),它甚至在其数字面部识别软件中(2006年,现在已大规模升级,是谷歌照片的一部分),将整个世界的面部表情都数字化了。2006年,随着YouTube的来袭,谷歌指挥了异常爆炸性的、不断扩大的数字表演,其内容囊括了世界上大部分图像、音乐和访谈。
将地球表面了无定型的混乱的表面、声音、图像、账目、歌曲、演讲、道路、建筑物、文件、信息和叙事都统一到一个行星式的数字工具中,这是一个举世无双、价值连城的伟大壮举。
...
谷歌的成功几乎不可思议。
...
除了少数微小却至关重要的领域,谷歌向其客户提供的一切都免费。
...
免费地图以惊人的覆盖范围和分辨率使谷歌成为移动和本地服务大师;免费YouTube以惊人的质量和多样性正在成为互联网影音的首选载体;免费电子邮件,优雅简洁和略带神秘的垃圾邮件过滤器,方便的附件和数以百兆的存储空间,还能免费链接查看日历和联系人列表;免费的安卓应用,免费的游戏,免费的搜索带来了速度,提高了效率。免费,免费,免费。免费的假期幻灯片,免费的道德提升,免费的世界文学经典,免费的答案。你的一切心血来潮,都来自谷歌的大脑。
先回到一开始,Google是做搜索引擎(Search Engine)起家的,搜索引擎简而言之,首先需要一堆爬虫按照一定的规则将全网的网页全部爬取下来,然后需要对这些网页进行内容提取,然后对内容进行分词并建倒排索引;当用户搜索时将用户的搜索关键词分词然后查倒排索引并结合一些权重将结果排序后分页返回给用户。
这里其实忽略了很多细节,比如爬虫爬取后要存储所有的原始网页数据,就需要分布式文件存储,于是GFS出现了;在GFS中需要解决分布式一致性问题,于是Chubby出现了;在结果排序时需要参考页面权重,也就是计算PageRank,于是计算模型MapReduce出现了;网页数据需要保留历史版本、支持海量实时写入、支持实时随机访问,比如网页快照功能,于是BigTable出现了。。。
下面是我整理的一个简单的对照表,如有谬误欢迎指出,左侧是Google的原创,右侧是开源版:
| OpenSource | |
|---|---|
| GSA | Lucene、Elastic Search |
| Chubby | Zookeeper |
| GFS | Hadoop HDFS |
| MapReduce | Hadoop MapReduce |
| BigTable | HBase |
| Dremel | Drill、Impala |
| Pregel | Giraph |
| MillWheel | Storm、Spark Streaming、Flink、Samza |
| Spanner | |
| Beam | |
| TensorFlow | |
| Kubernetes |
当前大数据开源领域组件眼花缭乱

一 常用的开源组件列表
| Zookeeper | 分布式一致性,常用于其他组件的master主从切换 | http://zookeeper.apache.org/ | |
| Kafka | MessageQueue,日志汇总 | http://kafka.apache.org | |
| Hadoop | HDFS | 分布式文件系统 | |
| Yarn | 资源(CPU/Memory)调度 | ||
| MapReduce | 现在基本没有人直接用了,但是其他组件比如hive、oozie等还在用 | ||
| Hive | 数据仓库、离线SQL查询 | ||
| Flume | 日志收集,agent部署在各个终端节点 | ||
| Sqoop | 数据在Hadoop生态内外导入导出,比如hive<->mysql | ||
| Gobblin | ETL工具,比如Kafka->HDFS | ||
| Spark | Spark | 离线计算 | |
| SparkSQL | 离线SQL查询 | ||
| SparkStreaming | 实时计算 | ||
| SparkStructuredStreaming | SQL式实时计算 | ||
| SparkML | 机器学习 | ||
| HBase | 海量KV数据库 | ||
|
Oozie Azkaban Quartz |
任务调度 | ||
|
Parquet ORC Kudu |
数据存储格式,列式存储 | ||
|
ProtocolBuffer Thrift Avro Json |
数据序列化 | ||
| Scala | 编程语言,通吃函数式编程和面向对象编程,代码简洁 | ||
|
ElasticSearch Lucene |
倒排索引搜索 | ||
| Cassandra | 海量KV数据库,比Hbase要快 | ||
| Kylin | 实时查询,利用Hbase空间换时间 | ||
| Druid | |||
|
Impala Drill |
实时查询 | ||
| Hue | Hadoop UI,集成Hadoop生态多个组件的页面UI | ||
| Ambari | 大数据集群快速部署工具、监控工具 | ||
| Nagios | 监控工具 | ||
| Ranger | 权限控制 | ||
| Kerberos | 安全认证 | ||
| Kubernetes | 容器集群管理 |
(内容陆续补充中)
二 发行版
开源组件通常有3个发行版:
1 Apache
基础发行版
2 CDH(Cloudera's Distribution, including Apache Hadoop)
https://www.cloudera.com/products/open-source/apache-hadoop/key-cdh-components.html
CDH is Cloudera’s 100% open source platform distribution, including Apache Hadoop and built specifically to meet enterprise demands. CDH delivers everything you need for enterprise use right out of the box. By integrating Hadoop with more than a dozen other critical open source projects, Cloudera has created a functionally advanced system that helps you perform end-to-end Big Data workflows.
3 HDP(Hortonworks Data Platform)

HDP is the industry's only true secure, enterprise-ready open source Apache™ Hadoop® distribution based on a centralized architecture (YARN). HDP addresses the complete needs of data-at-rest, powers real-time customer applications and delivers robust big data analytics that accelerate decision making and innovation.
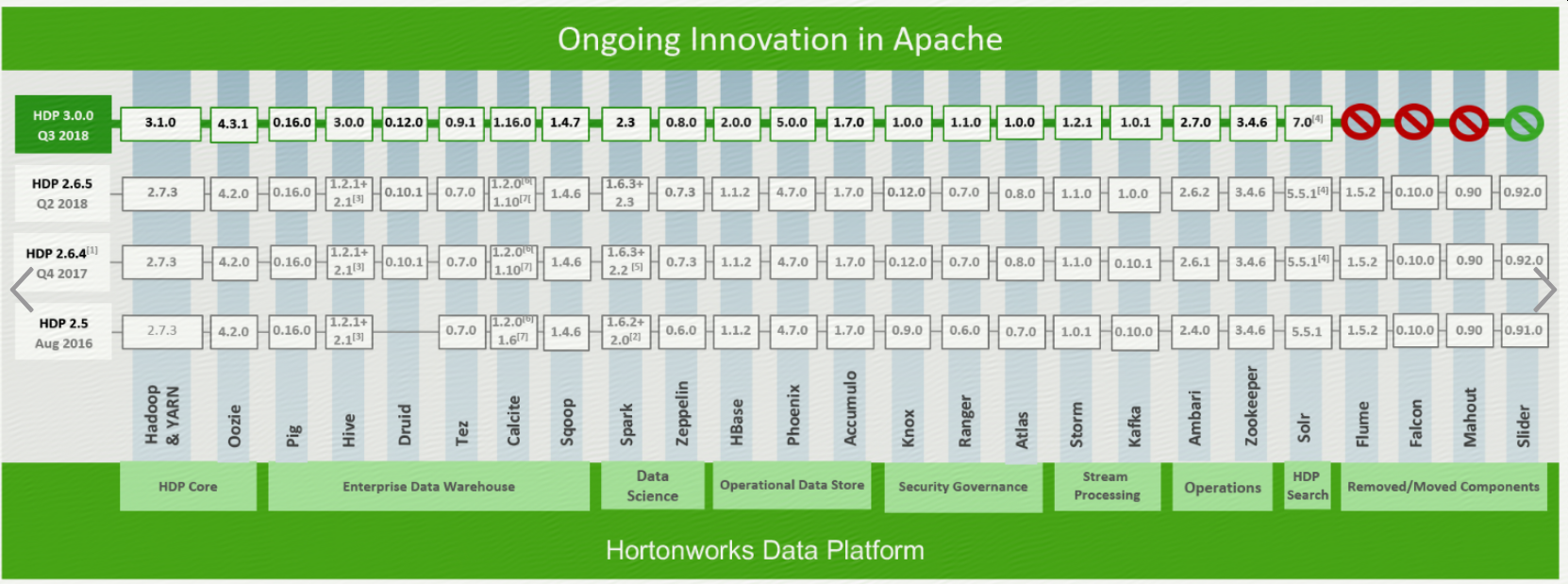
为什么会有这么多发行版,简单来说,CDH和HDP都是基于Apache而来的,直接用Apache的话,各个组件的版本是随意选择的,很容易发生版本兼容问题,CDH和HDP相当于对一系列版本兼容的组件打了一个包并且命名了一个新的版本,更新相对滞后;另外会有一些独有的组件,比如CDH的Cloudera Manager、Hue、Impala等,HDP的Ambari等,方便集群的搭建、管理、监控等工作;
Ambari更开放一些,支持安装第三方组件,比如ElasticSearch、Airflow、Impala、Hue等,详见:https://www.cnblogs.com/barneywill/p/10268501.html
ps:最近Cloudera和Hortonworks两家公司合并了,未来CDH和HDP也可能进一步整合。
【原创】Thinking in BigData (1)大数据简介的更多相关文章
- Spark记录-大数据简介
什么是大数据 大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需要新处理模式才能具有更强的决策力.洞察发现力和流程优化能力的海量.高增长率和多样化的信 ...
- NoSQL数据库技术实战-第1章 NoSQL与大数据简介 NoSQL数据库的类型
键值存储数据库临时性:如Memcached.临时性的键值数据库把数据存储在内存中,在两种情况下会造成上数据的丢失,一是断电,而是数据内容超出内存大小.这种处理的好处是非常快.永久型:如Tokyo Ty ...
- NoSQL数据库技术实战-第1章 NoSQL与大数据简介 NoSQL产生的原因
NoSQL产生的原因: 关系型数据库不擅长的操作,是NoSQL应运而生的原因: 大量的数据写入操作书上写的是“大量数据的写入操作“,我理解的应该是“大量的数据写入操作”,因为大量的数据写入操作才会引起 ...
- 《零起点,python大数据与量化交易》
<零起点,python大数据与量化交易>,这应该是国内第一部,关于python量化交易的书籍. 有出版社约稿,写本量化交易与大数据的书籍,因为好几年没写书了,再加上近期"前海智库 ...
- [转载] 使用 Twitter Storm 处理实时的大数据
转载自http://www.ibm.com/developerworks/cn/opensource/os-twitterstorm/ 流式处理大数据简介 Storm 是一个开源的.大数据处理系统,与 ...
- 大数据的前世今生【Hadoop、Spark】
一.大数据简介 大数据是一个很热门的话题,但它是什么时候开始兴起的呢? 大数据[big data]这个词最早在UNIX用户协会的会议上被使用,来自SGI公司的科学家在其文章“大数据与下一代基础架构 ...
- 保姆级教程,带你认识大数据,从0到1搭建 Hadoop 集群
大数据简介,概念部分 概念部分,建议之前没有任何大数据相关知识的朋友阅读 大数据概论 什么是大数据 大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需 ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
随机推荐
- windows平台在tomcat中启动cas报错解决
windows平台在tomcat中启动cas报错: Caused by: java.lang.UnsatisfiedLinkError: Could not load library. Reasons ...
- 使用二分查找判断某个数在某个区间中--如何判断某个IP地址所属的地区
一,问题描述 给定100万个区间对,假设这些区间对是互不重叠的,如何判断某个数属于哪个区间? 首先需要对区间的特性进行分析:区间是不是有序的?有序是指:后一个区间的起始位置要大于前一个区间的终点位置. ...
- 【由浅入深理解java集合】(二)——集合 Set
上一篇文章介绍了Set集合的通用知识.Set集合中包含了三个比较重要的实现类:HashSet.TreeSet和EnumSet.本篇文章将重点介绍这三个类. 一.HashSet类 HashSet简介 H ...
- springboot(十三):springboot结合mybatis generator逆向工程自动生成代码
错信息generate failed: Exception getting JDBC Driver: com.mysql.jdbc.Driver 上网查了一下,发现原来是generator这个插件在运 ...
- OZCode
OZCode是一款辅助调试工具,调试linq很方便有点重量级,导致整个项目运行很慢,但是功能很强大. OZCode界面如下:
- interactivePopGestureRecognizer --- iOS侧滑的问题
苹果一直都在人机交互中尽力做到极致,在iOS7中,新增加了一个小小的功能,也就是这个api:self.navigationController.interactivePopGestureRecogni ...
- luogu P4774 [NOI2018]屠龙勇士
传送门 这题真的是送温暖啊qwq,而且最重要的是yyb巨佬在Day2前几天正好学了crt,还写了博客 然而我都没仔细看,结果我就同步赛打铁了QAQ 我们可以先根据题意,使用set维护,求出每次的攻击力 ...
- php 调试的常用方法
1. php 页面直接输出错误, 根据错误进行调试 2.无法通过php页面捕获到错误,通过查看apache2的日志错误进行排查, 像通过系统命令进行操作失败时,就需要日志进行查看
- Protobuf学习
https://www.jianshu.com/p/2265f56805fa https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/index.ht ...
- 在maven项目中引用ueditor报错问题
遇到的问题:将pom.xml中引入 <dependency> <groupId>com.baidu</groupId> <artifactId>uedi ...