Python3-线程
线程
什么是线程
线程的创建开销小
线程与进程的区别
为何要用多线程
多线程的应用举例
开启线程的两种方式
在一个进程下开启多个线程与在一个进程下开启多个子进程的区别
多线程并发的socket服务器
线程相关的其他方法
守护线程
- 同步锁
死锁现象与递归锁
信号量Semaphore
- Event
定时器
线程queue
一 什么是线程
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程
注意:进程是资源分配的最小单位,线程是CPU调度的最小单位.
线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程
车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一个流水线
流水线的工作需要电源,电源就相当于cpu
所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
多线程(即多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。
二 线程的创建开销小
创建一个进程,需要向操作系统申请一块内存空间然后把一些列资源放进去。
创建一个线程,无需向操作系统申请内存空间,直接用进程的资源,所以效率会高很多。
三 线程与进程的区别
1.线程共享创建它的进程的地址空间;进程有自己的地址空间。
2.线程可以直接访问其进程的数据段;进程拥有自己父进程数据段的副本。
3.线程可以直接与其进程的其他线程通信;进程必须使用进程间通信来与兄弟进程通信。
4.新线程很容易创建;新进程则需要复制父进程的数据段。
5.线程可以对同一进程的线程进行相当大的控制;进程只能控制子进程。
6.对主线程的更改(取消,优先级更改等)可能会影响进程的其他线程的行为;对父进程的修改不会影响子进程。
四 为何要用多线程
多线程指的是,在一个进程中开启多个线程,简单的讲:如果多个任务共用一块地址空间,那么必须在一个进程内开启多个线程。详细的讲分为4点:
1. 多线程共享一个进程的地址空间
2. 线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用
3. 若多个线程都是cpu密集型的,那么并不能获得性能上的增强,但是如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而会加快程序执行的速度。
4. 在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(这一条并不适用于python)
五 多线程的应用举例
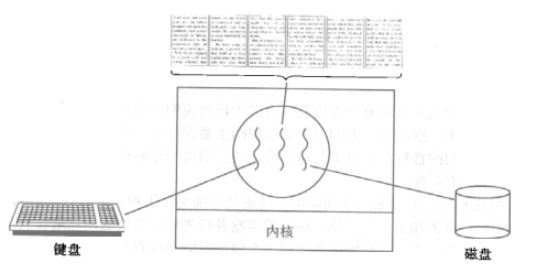
开启一个字处理软件进程,该进程肯定需要办不止一件事情,比如监听键盘输入,处理文字,定时自动将文字保存到硬盘,这三个任务操作的都是同一块数据,因而不能用多进程。只能在一个进程里并发地开启三个线程,如果是单线程,那就只能是,键盘输入时,不能处理文字和自动保存,自动保存时又不能输入和处理文字。
六 开启线程的两种方式
multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性。
#方式一
from threading import Thread
import time
def sayhi(name):
time.sleep()
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
print('主线程')
方式一
from threading import Thread
import time
class Sayhi(Thread):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
time.sleep()
print('%s say hello' % self.name) if __name__ == '__main__':
t = Sayhi('egon')
t.start()
print('主线程')
方式二
七 在一个进程下开启多个线程与在一个进程下开启多个子进程的区别
from threading import Thread
from multiprocessing import Process
import os def work():
print('hello') if __name__ == '__main__':
#在主进程下开启线程
t=Thread(target=work)
t.start()
print('主线程/主进程')
'''
打印结果:
hello
主线程/主进程
''' #在主进程下开启子进程
t=Process(target=work)
t.start()
print('主线程/主进程')
'''
打印结果:
主线程/主进程
hello
'''
1 谁的开启速度快
from threading import Thread
from multiprocessing import Process
import os def work():
print('hello',os.getpid()) if __name__ == '__main__':
#part1:在主进程下开启多个线程,每个线程都跟主进程的pid一样
t1=Thread(target=work)
t2=Thread(target=work)
t1.start()
t2.start()
print('主线程/主进程pid',os.getpid()) #part2:开多个进程,每个进程都有不同的pid
p1=Process(target=work)
p2=Process(target=work)
p1.start()
p2.start()
print('主线程/主进程pid',os.getpid())
2 瞅一瞅pid
from threading import Thread
from multiprocessing import Process
import os
def work():
global n
n= if __name__ == '__main__':
# n=
# p=Process(target=work)
# p.start()
# p.join()
# print('主',n) #毫无疑问子进程p已经将自己的全局的n改成了0,但改的仅仅是它自己的,查看父进程的n仍然为100 n=
t=Thread(target=work)
t.start()
t.join()
print('主',n) #查看结果为0,因为同一进程内的线程之间共享进程内的数据
3 同一进程内的线程共享该进程的数据?
八 多线程并发的socket服务器
#_*_coding:utf-8_*_
#!/usr/bin/env python
import multiprocessing
import threading import socket
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.bind(('127.0.0.1',))
s.listen() def action(conn):
while True:
data=conn.recv()
print(data)
conn.send(data.upper()) if __name__ == '__main__': while True:
conn,addr=s.accept() p=threading.Thread(target=action,args=(conn,))
p.start()
server
#_*_coding:utf-8_*_
#!/usr/bin/env python import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect(('127.0.0.1',)) while True:
msg=input('>>: ').strip()
if not msg:continue s.send(msg.encode('utf-8'))
data=s.recv()
print(data)
client
练习:三个任务,一个接收用户输入,一个将用户输入的内容格式化成大写,一个将格式化后的结果存入文件
from threading import Thread
msg_l=[]
format_l=[]
def talk():
while True:
msg=input('>>: ').strip()
if not msg:continue
msg_l.append(msg) def format_msg():
while True:
if msg_l:
res=msg_l.pop()
format_l.append(res.upper()) def save():
while True:
if format_l:
with open('db.txt','a',encoding='utf-8') as f:
res=format_l.pop()
f.write('%s\n' %res) if __name__ == '__main__':
t1=Thread(target=talk)
t2=Thread(target=format_msg)
t3=Thread(target=save)
t1.start()
t2.start()
t3.start()
练习题
九 线程相关的其他方法
Thread实例对象的方法
# isAlive(): 返回线程是否活动的。
# getName(): 返回线程名。
# setName(): 设置线程名。 threading模块提供的一些方法:
# threading.currentThread(): 返回当前的线程变量。
# threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
# threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
from threading import Thread
import threading
from multiprocessing import Process
import os def work():
import time
time.sleep()
print(threading.current_thread().getName()) if __name__ == '__main__':
#在主进程下开启线程
t=Thread(target=work)
t.start() print(threading.current_thread().getName())
print(threading.current_thread()) #主线程
print(threading.enumerate()) #连同主线程在内有两个运行的线程
print(threading.active_count())
print('主线程/主进程') MainThread
<_MainThread(MainThread, started )>
[<_MainThread(MainThread, started )>, <Thread(Thread-, started )>] 主线程/主进程
Thread-
主线程等待子线程结束
from threading import Thread
import time
def sayhi(name):
time.sleep()
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
t.join()
print('主线程')
print(t.is_alive())
'''
egon say hello
主线程
False
'''
十 守护线程
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁
需要强调的是:运行完毕并非终止运行
#.对主进程来说,运行完毕指的是主进程代码运行完毕 #.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
详细解释:
# 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会终止运行。
# 主线程在其它非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将会被回收,而进程必须保证非守护线程都运行完毕后才能结束。
from threading import Thread
import time
def sayhi(name):
time.sleep()
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.setDaemon(True) #必须在t.start()之前设置
t.start() print('主线程')
print(t.is_alive())
'''
主线程
True
'''
from threading import Thread
import time
def foo():
print()
time.sleep()
print("end123") def bar():
print()
time.sleep()
print("end456") t1=Thread(target=foo)
t2=Thread(target=bar) t1.daemon=True
t1.start()
t2.start()
print("main-------")
迷惑人的例子
main------- end123
end456
十一 同步锁
三个需要注意的点:
#.线程抢的是GIL锁,GIL锁相当于执行权限(拿到Cpython的全局解释器锁,然后把字符串形式的代码当参数传入解释器,解释成机器认识的机器码传给机器去执行),拿到执行权限后才能拿到互斥锁,其他线程也可以抢到GIL,但如果发现Lock仍然没有被释放(Lock里面的内容有IO操作,CPU会把GIL释放出来)则阻塞,即便是拿到执行权限GIL也要立刻交出来。 #.join是等待所有,即整体串行,而锁只是锁住修改共享数据部分,即部分串行,join与互斥锁都剋实现,但是互斥锁的部分串行更加灵活,效率更高
过程分析:所有线程抢的是GIL锁,或者说所有线程抢的是执行权限
线程1抢到GIL锁,拿到执行权限,开始执行,然后加了一把Lock,还没有执行完毕,即线程1还未释放Lock,有可能线程2抢到GIL锁,开始执行,执行过程中发现Lock还没有被线程1释放,于是线程2进入阻塞,被夺走执行权限,有可能线程1拿到GIL,然后正常执行到释放Lock。
问:为什么要抢GIL锁?
因为CPython有个垃圾回收机制的线程
因为Python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序 里的线程和 py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似的问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其它人都不能动,这样就解决了上述的问题, 这可以说是Python早期版本的遗留问题。
垃圾回收线程
锁通常被用来实现对共享资源的同步访问。为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁:
import threading R=threading.Lock() R.acquire()
'''
对公共数据的操作
'''
R.release()
from threading import Thread,Lock
import os,time
def work():
global n
lock.acquire()
temp=n
time.sleep(0.1)
n=temp-
lock.release()
if __name__ == '__main__':
lock=Lock()
n=
l=[]
for i in range():
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join() print(n) #结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全
分析:
#.100个线程去抢GIL锁,即抢执行权限
#. 肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
#. 极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL
#.直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 4的过程 GIL锁与互斥锁综合分析(重点!!!)
GIL锁与互斥锁综合分析(重点!!!)
#不加锁:并发执行,速度快,数据不安全
from threading import current_thread,Thread,Lock
import os,time
def task():
global n
print('%s is running' %current_thread().getName())
temp=n
time.sleep(0.5)
n=temp- if __name__ == '__main__':
n=
lock=Lock()
threads=[]
start_time=time.time()
for i in range():
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join() stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n)) '''
Thread- is running
Thread- is running
......
Thread- is running
主:0.5216062068939209 n:
''' #不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,数据安全
from threading import current_thread,Thread,Lock
import os,time
def task():
#未加锁的代码并发运行
time.sleep()
print('%s start to run' %current_thread().getName())
global n
#加锁的代码串行运行
lock.acquire()
temp=n
time.sleep(0.5)
n=temp-
lock.release() if __name__ == '__main__':
n=
lock=Lock()
threads=[]
start_time=time.time()
for i in range():
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n)) '''
Thread- is running
Thread- is running
......
Thread- is running
主:53.294203758239746 n:
''' #有的同学可能有疑问:既然加锁会让运行变成串行,那么我在start之后立即使用join,就不用加锁了啊,也是串行的效果啊
#没错:在start之后立刻使用jion,肯定会将100个任务的执行变成串行,毫无疑问,最终n的结果也肯定是0,是安全的,但问题是
#start后立即join:任务内的所有代码都是串行执行的,而加锁,只是加锁的部分即修改共享数据的部分是串行的
#单从保证数据安全方面,二者都可以实现,但很明显是加锁的效率更高.
from threading import current_thread,Thread,Lock
import os,time
def task():
time.sleep()
print('%s start to run' %current_thread().getName())
global n
temp=n
time.sleep(0.5)
n=temp- if __name__ == '__main__':
n=
lock=Lock()
start_time=time.time()
for i in range():
t=Thread(target=task)
t.start()
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n)) '''
Thread- start to run
Thread- start to run
......
Thread- start to run
主:350.6937336921692 n: #耗时是多么的恐怖
''' 互斥锁与join的区别(重点!!!)
互斥锁与join的区别(重点!!!)
十二 死锁现象与递归锁
所谓死锁:是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种相互等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态,这些永远在互相等待的进程成为死锁进程。
from threading import Thread,Lock
import time
mutexA=Lock()
mutexB=Lock() class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('\033[41m%s 拿到A锁\033[0m' %self.name) mutexB.acquire()
print('\033[42m%s 拿到B锁\033[0m' %self.name)
mutexB.release() mutexA.release() def func2(self):
mutexB.acquire()
print('\033[43m%s 拿到B锁\033[0m' %self.name)
time.sleep() mutexA.acquire()
print('\033[44m%s 拿到A锁\033[0m' %self.name)
mutexA.release() mutexB.release() if __name__ == '__main__':
for i in range():
t=MyThread()
t.start() '''
Thread- 拿到A锁
Thread- 拿到B锁
Thread- 拿到B锁
Thread- 拿到A锁
然后就卡住,死锁了
'''
死锁现象
解决方法,递归锁,在Python中是为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次acquire。直到一个线程所有的acquire都被release,其他线程才能获取资源。
上面的例子如果使用RLock代替Lock,则不会发生死锁:
from threading import Thread,RLock
import time
mutexB = mutexA = RLock() class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('\033[41m%s 拿到A锁\033[0m' %self.name) mutexB.acquire()
print('\033[42m%s 拿到B锁\033[0m' %self.name)
mutexB.release() mutexA.release() def func2(self):
mutexB.acquire()
print('\033[43m%s 拿到B锁\033[0m' %self.name)
time.sleep() mutexA.acquire()
print('\033[44m%s 拿到A锁\033[0m' %self.name)
mutexA.release() mutexB.release() if __name__ == '__main__':
for i in range():
t=MyThread()
t.start()
递归锁
mutexA=mutexB=threading.RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止
十三 信号量Semaphore
同进程的一样
信号量也是一把锁,可以指定信号量为5,对比互斥锁同一时间只能有一个任务抢到锁去执行,信号量同一时间可以有5个任务拿到锁去执行,如果说互斥锁是合租房屋的人去抢一个厕所,那么信号量就相当于一群路人争抢公共厕所,公共厕所有多个坑位,这意味着同一时间可以有多个人上公共厕所,但公共厕所容纳的人数是一定的,这便是信号量的大小
from threading import Thread,Semaphore
import threading
import time def func():
sm.acquire()
print('%s get sm' %threading.current_thread().getName())
time.sleep()
sm.release() if __name__ == '__main__':
sm=Semaphore()
for i in range():
t=Thread(target=func)
t.start()
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-;
调用release() 时内置计数器+;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
十四 Event
(相当于定义了一个全局变量,需要同步的线程秩序判断一下该全部变量是否为True,为True就执行下面的代码)
同线程一样
线程的一个关键特性是每个线程都是独立运行且状态不可预测
如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。
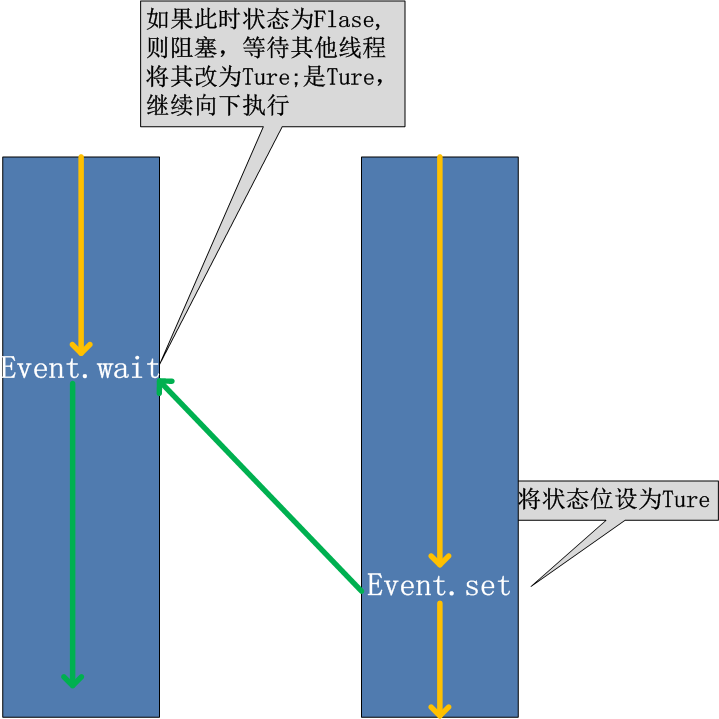
为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
例如,有多个工作线程尝试链接MySQL,我们想要在链接前确保MySQL服务正常才让那些工作线程去连接MySQL服务器,如果连接不成功,都会去尝试重新连接。那么我们就可以采用threading.Event机制来协调各个工作线程的连接操作
from threading import Thread,Event
import threading
import time,random
def conn_mysql():
count=
while not event.is_set():
if count > :
raise TimeoutError('链接超时')
print('<%s>第%s次尝试链接' % (threading.current_thread().getName(), count))
event.wait(0.5)
count+=
print('<%s>链接成功' %threading.current_thread().getName()) def check_mysql():
print('\033[45m[%s]正在检查mysql\033[0m' % threading.current_thread().getName())
time.sleep(random.randint(,))
event.set()
if __name__ == '__main__':
event=Event()
conn1=Thread(target=conn_mysql)
conn2=Thread(target=conn_mysql)
check=Thread(target=check_mysql) conn1.start()
conn2.start()
check.start()
十五 定时器
定时器,指定n秒后执行某操作
from threading import Timer def hello():
print("hello, world") t = Timer(, hello)
t.start() # after seconds, "hello, world" will be printed
from threading import Timer
import random,time class Code:
def __init__(self):
self.make_cache() def make_cache(self,interval=):
self.cache=self.make_code()
print(self.cache)
self.t=Timer(interval,self.make_cache)
self.t.start() def make_code(self,n=):
res=''
for i in range(n):
s1=str(random.randint(,))
s2=chr(random.randint(,))
res+=random.choice([s1,s2])
return res def check(self):
while True:
inp=input('>>: ').strip()
if inp.upper() == self.cache:
print('验证成功',end='\n')
self.t.cancel()
break if __name__ == '__main__':
obj=Code()
obj.check() 验证码定时器
验证码定时器
十六 线程queue
queue队列:使用import queue, 用法与进程Queue一样
当必须在多个线程之间安全地交换信息时,队列在线程编程中特别有用。
class queue.Queue(maxsize=0) #先进先出
import queue q=queue.Queue()
q.put('first')
q.put('second')
q.put('third') print(q.get())
print(q.get())
print(q.get())
'''
结果(先进先出):
first
second
third
'''
class queue.LifoQueue(maxsize=0) #last in fisrt out
import queue q=queue.LifoQueue()
q.put('first')
q.put('second')
q.put('third') print(q.get())
print(q.get())
print(q.get())
'''
结果(后进先出):
third
second
first
'''
class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
import queue q=queue.PriorityQueue()
#put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((,'a'))
q.put((,'b'))
q.put((,'c')) print(q.get())
print(q.get())
print(q.get())
'''
结果(数字越小优先级越高,优先级高的优先出队):
(, 'b')
(, 'a')
(, 'c')
'''
Python3-线程的更多相关文章
- python3 线程 threading.Thread GIL性能详解(2.3)
python3 线程 threading 最基础的线程的使用 import threading, time value = 0 lock = threading.Lock() def change(n ...
- python3线程启动与停止
转自: https://blog.csdn.net/weixin_38125866/article/details/76795462 https://www.cnblogs.com/lcchuguo/ ...
- python3 线程池-threadpool模块与concurrent.futures模块
多种方法实现 python 线程池 一. 既然多线程可以缩短程序运行时间,那么,是不是线程数量越多越好呢? 显然,并不是,每一个线程的从生成到消亡也是需要时间和资源的,太多的线程会占用过多的系统资源( ...
- Python3 线程/进程池 concurrent.futures
python3之concurrent.futures一个多线程多进程的直接对接模块,python3.2有线程池了 Python标准库为我们提供了threading和multiprocessing模块编 ...
- Python SSH爆破以及Python3线程池控制线程数
源自一个朋友的要求,他的要求是只爆破一个ip,结果出来后就停止,如果是爆破多个,完全没必要停止,等他跑完就好 #!usr/bin/env python #!coding=utf-8 __author_ ...
- python3 线程_threading模块
'''并发:同一个时间段内运行多个程序的能力 进程就是一个程序在一个数据集上的一次动态执行过程.进程一般由程序.数据集.进程控制块三部分组成 程序:食谱数据集:鸡蛋.牛奶.糖等进程控制块:记下食谱做到 ...
- python3线程介绍02(线程锁的介绍:互斥、信号、条件、时间、定时器)
#!/usr/bin/env python# -*- coding:utf-8 -*- import threadingimport timeimport random # 1-互斥锁 Lock 同一 ...
- python3线程介绍01(如何启动和调用线程)
#!/usr/bin/env python# -*- coding:utf-8 -*- import osimport time,randomimport threading # 1-进程说明# 进程 ...
- python3 线程调用与GIL 锁机制
转载
- (转)Python3入门之线程threading常用方法
原文:https://www.cnblogs.com/chengd/articles/7770898.html https://blog.csdn.net/sunhuaqiang1/article/d ...
随机推荐
- python 函数基础及装饰器
没有参数的函数及return操作 def test1(): print ("welcome") def test2(): print ("welcomt test2&qu ...
- ASP.NET新建解决方案和网站
新建解决方案和网站 1.打开visual studio,选择新建项目,然后选择解决方案. 2.解决方案建好之后,右键点击解决方案选择新建网站.注意,路径.我在solution1文件夹下面又建了一个si ...
- LeetCode(193. Valid Phone Numbers)(sed用法)
193. Valid Phone Numbers Given a text file file.txt that contains list of phone numbers (one per lin ...
- idea搭建Spring Boot+MyBatis
需要准备的环境: idea 2017.2 jdk1.8.0_144 Maven 3.5.0 请提前将idea与Maven.jdk配置好,本次项目用的都是比较新的. 步骤: 一.首先使用idea新建一个 ...
- 046、创建Docker Machine(2019-03-11 周一)
参考https://www.cnblogs.com/CloudMan6/p/7237420.html 对于Docker Machine来说,属于 Machine 就是运行docker daemon ...
- 【转载】C# 字符串截取
https://blog.csdn.net/maba007/article/details/78424760
- Kudu系列-基础
Apache Kudu 支持Insert/Update/Delete 等写操作(Kudu 随机写效率也很高, 实测对一个窄表做全字段update, 其速度达到了Insert速度的88%, 而verti ...
- 数据建模工具系列 之 让SQL Power Architect支持Vertica
几款数据建模软件评估 下面是流行几款数据建模软件: 软件 特点 支持Vertica? 免费? ERWin 功能强大, 操作较繁琐 不支持Vertica 商业软件,价格高 Power Designer ...
- SQL Server进阶(十二)常用函数
在SQL 2012基础教程中列出子句是按照以下顺序进行逻辑处理. FROM WHERE GROUP BY HAVING SELECT ORDER BY FROM TableName WHERE Use ...
- Docker 空间大小设置 - 十
一.容器启动 默认存储大小: 1.一种在启动项 docker.service 中配置. 2.在启动项配置调用的 docker-storage 配置文件中配置: 二.Docker 容器默认启动文件: / ...