Kaldi中的L2正则化
steps/nnet3/train_dnn.py
--l2-regularize-factor
影响模型参数的l2正则化强度的因子。要进行l2正则化,主要方法是在配置文件中使用'l2-regularize'进行配置。l2正则化因子将乘以组件中的l2正则化值,并且可用于通过模型平均化以校正与并行化带来的影响。
(float,默认值= 1)
src/nnet3/nnet-utils.cc:2030
void ApplyL2Regularization(const Nnet &nnet, BaseFloat l2_regularize_scale, Nnet *delta_nnet) { /*...*/
//nnet是更新前的神经网络
const Component *src_component_in = nnet.GetComponent(c);
//delta_nnet是进行更新后的神经网络
UpdatableComponent *dest_component =
dynamic_cast<UpdatableComponent*>(delta_nnet->
GetComponent(c));
//delta_nnet->c -= 2.0 * l2_regularize_scale * alpha * eta * nnet.c
// alpha为L2正则化常数
// eta为学习率
// nnet.c为该nnet的component(应该是权重)
// l2_regularize来自于L2Regularization(),该函数返回UpdatableComponent中的L2正则化常量(通常由配置文件设定)。
// 根据steps/libs/nnet3/xconfig/basic_layers.py:471
// 可以xconfig中指定l2-regularize(默认为0.0)
// 一般通过ApplyL2Regularization()而非组件层的代码读取该常量。ApplyL2Regularization(),声明于nnet-utils.h(训练工作流的一部分)。
BaseFloat scale = -2.0 * l2_regularize_scale * lrate * l2_regularize;
// nnet3/nnet-simple-component.cc:1027
// linear_params_.AddMat(alpha, other->linear_params_);
// bias_params_.AddVec(alpha, other->bias_params_);
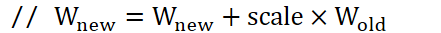

/*...*/}
//输出的统计数值
CuVector<double> value_sum_;
//非线性(神经元)的微分的统计数值(只适用于以向量元素为单位的非线性,不适用于Softmax)
CuVector<double> deriv_sum_;
//objective derivative function sum square
//目标函数微分的平方和,用于诊断
CuVector<double> oderiv_sumsq_;
//oderiv_sumsq_中stats数量
double oderiv_count_;
对于神经网络中的每个可更新组件c,假设它在组件中设定了l2正则化常量alpha(请参阅UpdatableComponent::L2Regularization())和学习率eta,那么此函数为(伪代码):

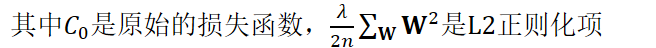
对求W偏导:

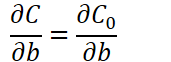
可以发现L2正则化项对b的更新没有影响,但是对于w的更新有影响:
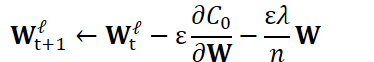

delta_nnet-> c -= 2.0 * l2_regularize_scale * alpha * eta * nnet.c
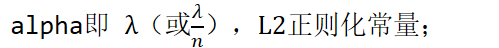
nnet.c即w;
eta为学习率
因子-1.0(-=,减等于)是为了最大化正则化项;

因子2.0来自参数平方的导数。该函数使用了"l2_regularize_scale"因子,请参阅下面的说明。
注意:由于与自然梯度的相互作用,Kaldi的L2正则化是普通方法的近似。问题在于普通梯度乘以经过近似化、平滑化、比例缩放的Fisher矩阵的逆,但是l2梯度不是。这意味着我们正在优化的不是常规的"目标函数 + L2正则化项"这种形式,我们可以将其视为"常规目标函数 + L2正则化项
× Fisher矩阵"
,前提是
参数变化量不受到Fisher矩阵缩放的影响,所以这不会影响L2的整体强度,只会影响是方向(direction-wise)权重。实际上,在大的Fisher矩阵的变换方向上,相对于梯度,L2项的贡献将更大。这可能并不理想,但如果没有实验就很难判断。无论如何,L2的影响足够小,并且Fisher矩阵根据identity进行了充分的平滑,我怀疑这会产生很大的差别。
要为nnet3设定L2正则化,可以调用nnet3/xconfig_to_configs.py:

Kaldi中的L2正则化的更多相关文章
- 从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化
从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化 神经网络在训练过程中,为应对过拟合问题,可以采用正则化方法(regularization),一种常用的正则化方法是L2正则化. 神经网络中 ...
- TensorFlow中的L2正则化函数:tf.nn.l2_loss()与tf.contrib.layers.l2_regularizerd()的用法与异同
tf.nn.l2_loss()与tf.contrib.layers.l2_regularizerd()都是TensorFlow中的L2正则化函数,tf.contrib.layers.l2_regula ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- tensorflow中添加L2正则化损失
方法有几种,总结一下方便后面使用. 1. tensorflow自动维护一个tf.GraphKeys.WEIGHTS集合,手动在集合里面添加(tf.add_to_collection())想要进行正则化 ...
- TensorFlow L2正则化
TensorFlow L2正则化 L2正则化在机器学习和深度学习非常常用,在TensorFlow中使用L2正则化非常方便,仅需将下面的运算结果加到损失函数后面即可 reg = tf.contrib.l ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- tensorflow 中的L1和L2正则化
import tensorflow as tf weights = tf.constant([[1.0, -2.0],[-3.0 , 4.0]]) >>> sess.run(tf.c ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
随机推荐
- CF1140E Palindrome-less Arrays
我觉得这道题非常有前途....... 题意:给定一个填了一半的数组,你要把它补完,使之不存在奇回文串,求方案数.字符集为k. n,k<=20w 解:不能有长为三的回文串.也就是不能有两个相隔1的 ...
- JMeter关联(正则表达式提取器)
正则表达式总结 关联:与系统交互过程中,系统返回的内容,需要在接下来的交互中用到,如防止csrf攻击而生成的token. 从前一个请求中取,用Regular Expression Extractor ...
- C++ template一些体悟(3)
其实没啥体悟,因为还没有感受到这些例子的作用,记一下先 #include <iostream> using namespace std; class alloc { }; template ...
- hdu 4333"Revolving Digits"(KMP求字符串最小循环节+拓展KMP)
传送门 题意: 此题意很好理解,便不在此赘述: 题解: 解题思路:KMP求字符串最小循环节+拓展KMP ①首先,根据KMP求字符串最小循环节的算法求出字符串s的最小循环节的长度,记为 k: ②根据拓展 ...
- msvcp100d.dll文件丢失,解决找不到msvcp100d.dll的问题
http://www.jb51.net/dll/msvcp100d.dll.html msvcp100d.dll控件常规安装方法(仅供参考): 一.如果在运行某软件或编译程序时提示缺少.找不到msvc ...
- MooFest POJ - 1990 (树状数组)
Every year, Farmer John's N (1 <= N <= 20,000) cows attend "MooFest",a social gather ...
- 位掩码(BitMask)的介绍与使用
一.前言 位运算在我们实际开发中用得很少,主要原因还是它对于我们而言不好读.不好懂.也不好计算,如果不经常实践,很容易就生疏了.但实际上,位运算是一种很好的运算思想,它的优点自然是计算快,代码更少. ...
- Kafka技术内幕 读书笔记之(二) 生产者——新生产者客户端
消息系统通常由生产者(producer ). 消费者( consumer )和消息代理( broker ) 三大部分组成,生产者会将消息写入消息代理,消费者会从消息代理中读取消息 . 对于消息代理而言 ...
- ES6 In Depth: Arrow functions
Arrows <script language="javascript"> <!-- document.bgColor = "brown"; ...
- 当php邂逅windows通用上传缺陷
早上逛乌云发现了PKAV大牛的一篇文章,针对php和windows文件上传的分析,思路很YD,果断转之与大家分享. 虽然此文可能有许多的限制条件,但是如果你认真阅读会发现,其实还是比较实用的. 另外一 ...