10分钟学会使用YOLO及Opencv实现目标检测(下)|附源码
将YOLO应用于视频流对象检测
首先打开 yolo_video.py文件并插入以下代码:
# import the necessary packages
import numpy as np
import argparse
import imutils
import time
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input video")
ap.add_argument("-o", "--output", required=True,
help="path to output video")
ap.add_argument("-y", "--yolo", required=True,
help="base path to YOLO directory")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
ap.add_argument("-t", "--threshold", type=float, default=0.3,
help="threshold when applyong non-maxima suppression")
args = vars(ap.parse_args())同样,首先从导入相关数据包和命令行参数开始。与之前不同的是,此脚本没有-- image参数,取而代之的是量个视频路径:
-- input:输入视频文件的路径;-- output:输出视频文件的路径;
视频的输入可以是手机拍摄的短视频或者是网上搜索到的视频。另外,也可以通过将多张照片合成为一个短视频也可以。本博客使用的是在PyImageSearch上找到来自imutils的VideoStream类的 示例。
下面的代码与处理图形时候相同:
# load the COCO class labels our YOLO model was trained on
labelsPath = os.path.sep.join([args["yolo"], "coco.names"])
LABELS = open(labelsPath).read().strip().split("\n")
# initialize a list of colors to represent each possible class label
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
dtype="uint8")
# derive the paths to the YOLO weights and model configuration
weightsPath = os.path.sep.join([args["yolo"], "yolov3.weights"])
configPath = os.path.sep.join([args["yolo"], "yolov3.cfg"])
# load our YOLO object detector trained on COCO dataset (80 classes)
# and determine only the *output* layer names that we need from YOLO
print("[INFO] loading YOLO from disk...")
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]在这里,加载标签并生成相应的颜色,然后加载YOLO模型并确定输出层名称。
接下来,将处理一些特定于视频的任务:
# initialize the video stream, pointer to output video file, and
# frame dimensions
vs = cv2.VideoCapture(args["input"])
writer = None
(W, H) = (None, None)
# try to determine the total number of frames in the video file
try:
prop = cv2.cv.CV_CAP_PROP_FRAME_COUNT if imutils.is_cv2() \
else cv2.CAP_PROP_FRAME_COUNT
total = int(vs.get(prop))
print("[INFO] {} total frames in video".format(total))
# an error occurred while trying to determine the total
# number of frames in the video file
except:
print("[INFO] could not determine # of frames in video")
print("[INFO] no approx. completion time can be provided")
total = -1在上述代码块中:
- 打开一个指向视频文件的文件指针,循环读取帧;
- 初始化视频编写器 (
writer)和帧尺寸; - 尝试确定视频文件中的总帧数(
total),以便估计整个视频的处理时间;
之后逐个处理帧:
# loop over frames from the video file stream
while True:
# read the next frame from the file
(grabbed, frame) = vs.read()
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
# if the frame dimensions are empty, grab them
if W is None or H is None:
(H, W) = frame.shape[:2]上述定义了一个 while循环, 然后从第一帧开始进行处理,并且会检查它是否是视频的最后一帧。接下来,如果尚未知道帧的尺寸,就会获取一下对应的尺寸。
接下来,使用当前帧作为输入执行YOLO的前向传递 :
ect Detection with OpenCVPython
# construct a blob from the input frame and then perform a forward
# pass of the YOLO object detector, giving us our bounding boxes
# and associated probabilities
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416),
swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
layerOutputs = net.forward(ln)
end = time.time()
# initialize our lists of detected bounding boxes, confidences,
# and class IDs, respectively
boxes = []
confidences = []
classIDs = []在这里,构建一个 blob 并将其传递通过网络,从而获得预测。然后继续初始化之前在图像目标检测中使用过的三个列表: boxes 、 confidences、classIDs :
# loop over each of the layer outputs
for output in layerOutputs:
# loop over each of the detections
for detection in output:
# extract the class ID and confidence (i.e., probability)
# of the current object detection
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# filter out weak predictions by ensuring the detected
# probability is greater than the minimum probability
if confidence > args["confidence"]:
# scale the bounding box coordinates back relative to
# the size of the image, keeping in mind that YOLO
# actually returns the center (x, y)-coordinates of
# the bounding box followed by the boxes' width and
# height
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# use the center (x, y)-coordinates to derive the top
# and and left corner of the bounding box
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# update our list of bounding box coordinates,
# confidences, and class IDs
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)在上述代码中,与图像目标检测相同的有:
- 循环输出层和检测;
- 提取
classID并过滤掉弱预测; - 计算边界框坐标;
- 更新各自的列表;
接下来,将应用非最大值抑制:
# apply non-maxima suppression to suppress weak, overlapping
# bounding boxes
idxs = cv2.dnn.NMSBoxes(boxes, confidences, args["confidence"],
args["threshold"])
# ensure at least one detection exists
if len(idxs) > 0:
# loop over the indexes we are keeping
for i in idxs.flatten():
# extract the bounding box coordinates
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
# draw a bounding box rectangle and label on the frame
color = [int(c) for c in COLORS[classIDs[i]]]
cv2.rectangle(frame, (x, y), (x + w, y + h), color, 2)
text = "{}: {:.4f}".format(LABELS[classIDs[i]],
confidences[i])
cv2.putText(frame, text, (x, y - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)同样的,在上述代码中与图像目标检测相同的有:
- 使用
cv2.dnn.NMSBoxes函数用于抑制弱的重叠边界框,可以在此处阅读有关非最大值抑制的更多信息; - 循环遍历由NMS计算的
idx,并绘制相应的边界框+标签;
最终的部分代码如下:
# check if the video writer is None
if writer is None:
# initialize our video writer
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
# some information on processing single frame
if total > 0:
elap = (end - start)
print("[INFO] single frame took {:.4f} seconds".format(elap))
print("[INFO] estimated total time to finish: {:.4f}".format(
elap * total))
# write the output frame to disk
writer.write(frame)
# release the file pointers
print("[INFO] cleaning up...")
writer.release()
vs.release()总结一下:
- 初始化视频编写器(
writer),一般在循环的第一次迭代被初始化; - 打印出对处理视频所需时间的估计;
- 将帧(
frame)写入输出视频文件; - 清理和释放指针;
现在,打开一个终端并执行以下命令:
$ python yolo_video.py --input videos/car_chase_01.mp4 \
--output output/car_chase_01.avi --yolo yolo-coco
[INFO] loading YOLO from disk...
[INFO] 583 total frames in video
[INFO] single frame took 0.3500 seconds
[INFO] estimated total time to finish: 204.0238
[INFO] cleaning up...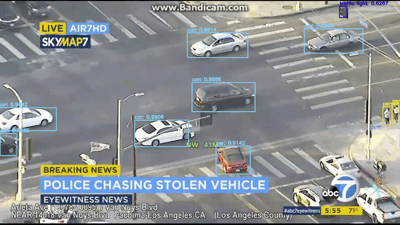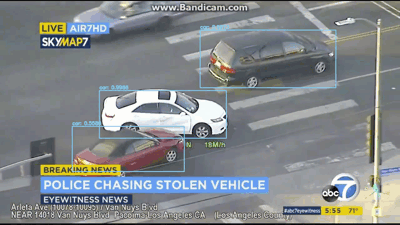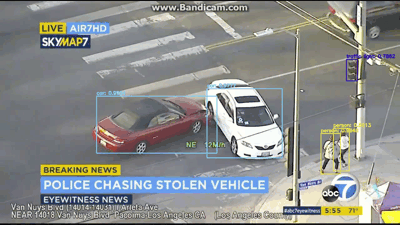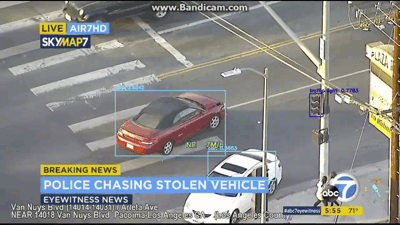
图6:YOLO应用于车祸视频对象检测
在视频/ GIF中,你不仅可以看到被检测到的车辆,还可以检测到人员以及交通信号灯!
YOLO目标检测器在该视频中表现相当不错。让现在尝试同一车追逐视频中的不同视频:
$ python yolo_video.py --input videos/car_chase_02.mp4 \
--output output/car_chase_02.avi --yolo yolo-coco
[INFO] loading YOLO from disk...
[INFO] 3132 total frames in video
[INFO] single frame took 0.3455 seconds
[INFO] estimated total time to finish: 1082.0806
[INFO] cleaning up...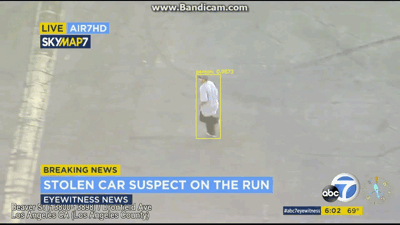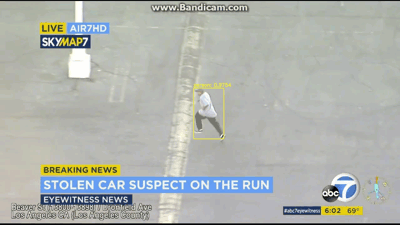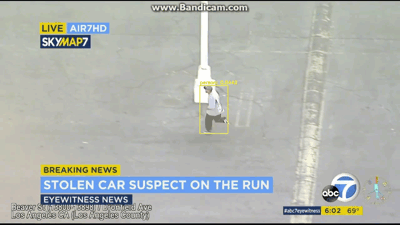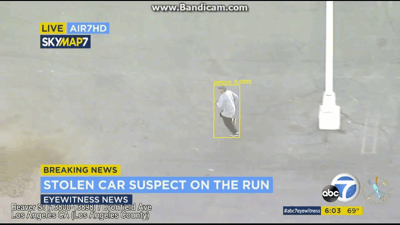
图7:在该视频中,使用OpenCV和YOLO对象检测来找到该嫌疑人,嫌疑人现在已经逃离汽车并正位于停车场
YOLO再一次能够检测到行人!或者嫌疑人回到他们的车中并继续追逐:
$ python yolo_video.py --input videos/car_chase_03.mp4 \
--output output/car_chase_03.avi --yolo yolo-coco
[INFO] loading YOLO from disk...
[INFO] 749 total frames in video
[INFO] single frame took 0.3442 seconds
[INFO] estimated total time to finish: 257.8418
[INFO] cleaning up...
图8: YOLO是一种快速深度学习对象检测器,能够在使用GPU的情况下用于实时视频
最后一个例子,让我们看看如何使用YOLO作为构建流量计数器:
$ python yolo_video.py --input videos/overpass.mp4 \
--output output/overpass.avi --yolo yolo-coco
[INFO] loading YOLO from disk...
[INFO] 812 total frames in video
[INFO] single frame took 0.3534 seconds
[INFO] estimated total time to finish: 286.9583
[INFO] cleaning up...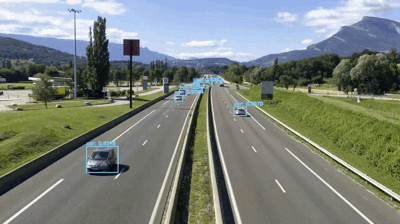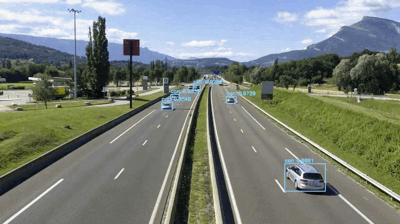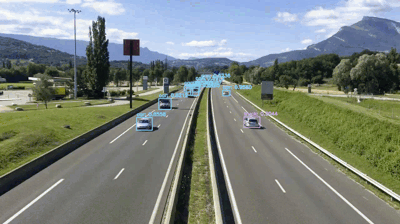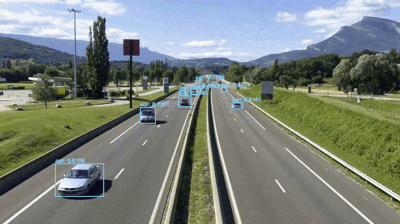
图9:立交桥交通视频表明,YOLO和OpenCV可准确、快速地检测汽车
下面汇总YOLO视频对象检测完整视频:
YOLO目标检测器的局限和缺点
YOLO目标检测器的最大限制和缺点是:
- 它并不总能很好地处理小物体;
- 它尤其不适合处理密集的对象;
限制的原因是由于YOLO算法其本身:
- YOLO对象检测器将输入图像划分为
SxS网格,其中网格中的每个单元格仅预测单个对象; - 如果单个单元格中存在多个小对象,则YOLO将无法检测到它们,最终导致错过对象检测;
因此,如果你的数据集是由许多靠近在一起的小对象组成时,那么就不应该使用YOLO算法。就小物体而言,更快的R-CNN往往效果最好,但是其速度也最慢。在这里也可以使用SSD算法, SSD通常在速度和准确性方面也有很好的权衡。
值得注意的是,在本教程中,YOLO比SSD运行速度慢,大约慢一个数量级。因此,如果你正在使用预先训练的深度学习对象检测器供OpenCV使用,可能需要考虑使用SSD算法而不是YOLO算法。
因此,在针对给定问题选择对象检测器时,我倾向于使用以下准则:
- 如果知道需要检测的是小物体并且速度方面不作求,我倾向于使用faster R-CNN算法;
- 如果速度是最重要的,我倾向于使用YOLO算法;
- 如果需要一个平衡的表现,我倾向于使用SSD算法;
想要训练自己的深度学习目标检测器?
图10:在我的书“使用Python进行计算机视觉的深度学习”中,我介绍了多种对象检测算法,包括faster R-CNN、SSD、RetinaNet。书中讲述了如何创建对象检测图像数据集、训练对象检测器并进行预测。
在本教程中,使用的YOLO模型是在COCO数据集上预先训练的.。但是,如果想在自己的数据集上训练深度学习对象检测器,该如何操作呢?
大体思路是自己标注数据集,按照darknet网站上的指示及网上博客自己更改相应的参数训练即可。或者在我的书“深度学习计算机视觉与Python”中,详细讲述了如何将faster R-CNN、SSD和RetinaNet应用于:
- 检测图像中的徽标;
- 检测交通标志;
- 检测车辆的前视图和后视图(用于构建自动驾驶汽车应用);
- 检测图像和视频流中武器;
书中的所有目标检测章节都包含对算法和代码的详细说明,确保你能够成功训练自己的对象检测器。
总结
在本教程中,我们学习了如何使用Deep Learning、OpenCV和Python完成YOLO对象检测。然后,我们简要讨论了YOLO架构,并用Python实现:
- 将YOLO对象检测应用于单个图像;
- 将YOLO对象检测应用于视频流;
在配备的3GHz Intel Xeon W处理器的机器上,YOLO的单次前向传输耗时约0.3秒; 但是,使用单次检测器(SSD),检测耗时只需0.03秒,速度提升了一个数量级。对于使用OpenCV和Python在CPU上进行基于实时深度学习的对象检测,你可能需要考虑使用SSD算法。
如果你有兴趣在自己的自定义数据集上训练深度学习对象检测器,请务必参阅写的“使用Python进行计算机视觉深度学习”,其中提供了有关如何成功训练自己的检测器的详细指南。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
10分钟学会使用YOLO及Opencv实现目标检测(下)|附源码的更多相关文章
- C# 30分钟完成百度人脸识别——进阶篇(文末附源码)
距离上次入门篇时隔两个月才出这进阶篇,小编惭愧,对不住关注我的卡哇伊的小伙伴们,为此小编用这篇博来谢罪. 前面的准备工作我就不说了,注册百度账号api,创建web网站项目,引入动态链接库引入. 不了解 ...
- 10分钟学会Linux
10分钟学会Linux有点夸张,可是能够让一个新手初步熟悉Linux中最重要最主要的知识,本文翻译的英文网页在众多Linux入门学习的资料中还是很不错的. 英文地址:http://freeengine ...
- 10分钟学会搭建Android开发环境 Eclipse: The import android.support cannot be resolved
10分钟学会搭建Android开发环境_隋雨辰 http://v.youku.com/v_show/id_XNTE2OTI5Njg0.html?from=s1.8-1-1.2 The import a ...
- 10分钟学会VS NuGet包私有化部署
前言 我们之前实现了打包发布NuGet,但是发布后的引用是公有的,谁都可以访问,显然这种方式是不可取的. 命令版本:10分钟学会Visual Studio将自己创建的类库打包到NuGet进行引用(ne ...
- 一文带你学会使用YOLO及Opencv完成图像及视频流目标检测(上)|附源码
计算机视觉领域中,目标检测一直是工业应用上比较热门且成熟的应用领域,比如人脸识别.行人检测等,国内的旷视科技.商汤科技等公司在该领域占据行业领先地位.相对于图像分类任务而言,目标检测会更加复杂一些,不 ...
- YOLT:将YOLO用于卫星图像目标检测
之前作者用滑动窗口和HOG来进行船体监测,在开放水域和港湾取得了不错的成绩,但是对于不一致的复杂背景,这个方法的性能会下降.为了解决这个缺点,作者使用YOLO作为物体检测的流水线,这个方法相比于HOG ...
- Web 开发中很实用的10个效果【附源码下载】
在工作中,我们可能会用到各种交互效果.而这些效果在平常翻看文章的时候碰到很多,但是一时半会又想不起来在哪,所以养成知识整理的习惯是很有必要的.这篇文章给大家推荐10个在 Web 开发中很有用的效果,记 ...
- Android上掌纹识别第一步:基于OpenCV的6种肤色分割 源码和效果图
Android上掌纹识别第一步:基于OpenCV的6种肤色分割 源码和效果图 分类: OpenCV图像处理2013-02-21 21:35 6459人阅读 评论(8) 收藏 举报 原文链接 ht ...
- 基于YOLO和PSPNet的目标检测与语义分割系统(python)
基于YOLO和PSPNet的目标检测与语义分割系统 源代码地址 概述 这是我的本科毕业设计 它的主要功能是通过YOLOv5进行目标检测,并使用PSPNet进行语义分割. 本项目YOLOv5部分代码基于 ...
随机推荐
- web安全系列4:google语法
这是web安全的第四篇,欢迎翻看前面几篇. 前面我们介绍了一些和HTTP有关知识,那么一个疑问就是黑客要做的第一件是什么?其实很简单,确定一个目标,然后搜集信息. 这很容易理解,我们无论做什么都得先有 ...
- .net读取excel数据到DataSet中
Dim objExcelFile As Excel.Application Dim objWorkBook As Excel.Workbook Dim objSheet As Excel.Worksh ...
- JAVA中执行JavaScript代码并获取返回值
JAVA中执行JavaScript代码并获取返回值 场景描述 实现思路 技术要点 代码实现 测试方法 运行结果 改进空间 场景描述 今天在CSDN上偶然看到一个帖子对于一段字符串 “var p=‘xx ...
- JS模块化工具require.js教程(一):初识require.js
随着网站功能逐渐丰富,网页中的js也变得越来越复杂和臃肿,原有通过script标签来导入一个个的js文件这种方式已经不能满足现在互联网开发模式,我们需要团队协作.模块复用.单元测试等等一系列复杂的需求 ...
- HTTP 初步探究
网络上存在很多资源,也持续不断地生成新的资源.为了新建.获取和操作这些资源,引来了两个问题:如何定位资源,如何对他们进行操作.第一个问题引申出了 URI / URL 即 uniform resourc ...
- 可遇不可求的Question之MySql4.0前版本不支持union与批量SQL提交
批量SQL提交 参考 21.2.6. Connector/NET Connection String Options Reference . Allow Batch true When true, m ...
- grep,sed,awk用法整理
grep -c 打印出符合要求的行数 -i 忽略大小写 ignore -n 连同符号一起输出 num -v 打印出不符合要求的行 -A2 本行及下面两行 - ...
- 小程序 mpvue自定义底部导航栏
1.在compontents新建文件放入 <template> <section class="tabBar-wrap"> <article clas ...
- Leetcode35 Search Insert Position 解题思路(python)
本人编程小白,如果有写的不对.或者能更完善的地方请个位批评指正! 这个是leetcode的第35题,这道题的tag是数组,python里面叫list,需要用到二分搜索法 35. Search Inse ...
- Django关联数据库时报错TypeError: __init__() missing 1 required positional argument: 'on_delete'
sgrade = models.ForeignKey("Grades",) 执行python manage.py makemigrations后出现TypeError: __ini ...