JVM学习(一)、垃圾收集器简介

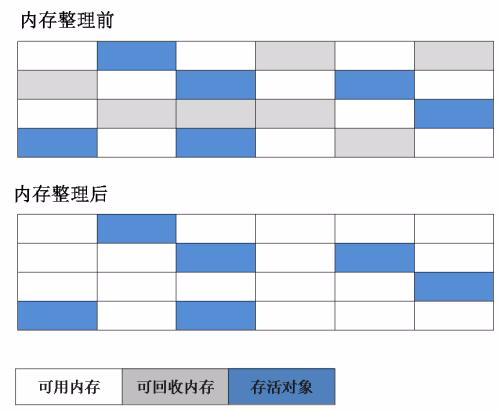
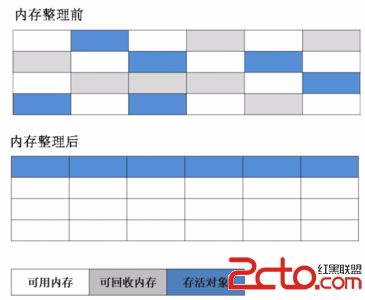
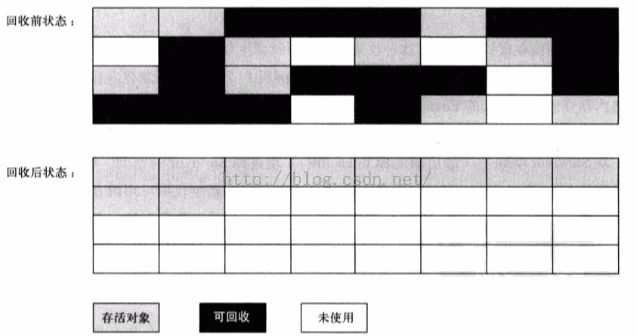

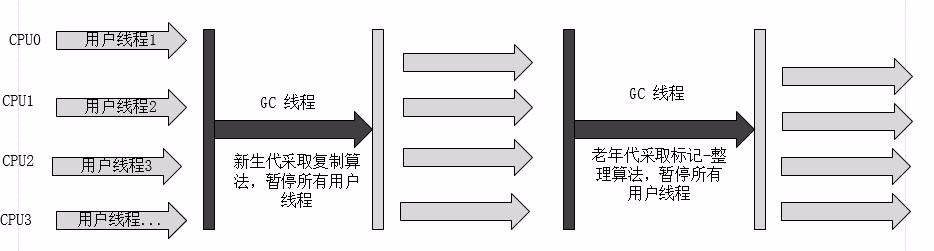

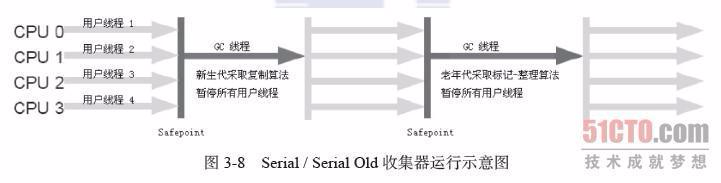
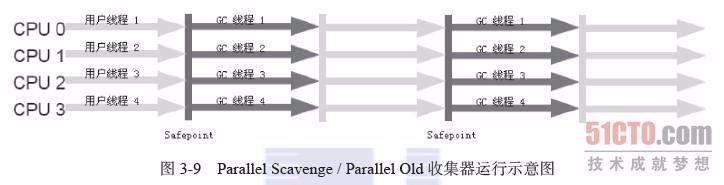
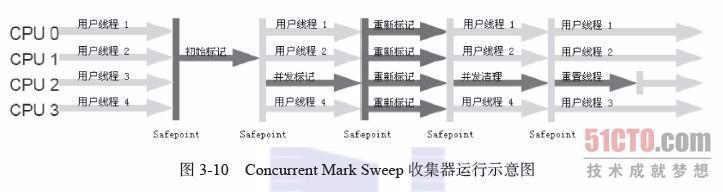
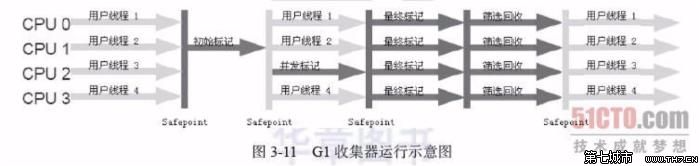
(7)G1收集器(Garbage-First):是当今收集器技术发展的最前沿的成果之一,G1是一款面向服务器端应用的垃圾收集器。与其他GC收集器相比,G1具备如下特点:
33.125:[GC [DefNew:3324K->152K(3712K),0.0025925secs] 3324K->152K(11904K),0.0031680 secs] 100.667:[FullGC [Tenured:0K->210K(10240K),0.0149142secs] 4603K->210K(19456K),[Perm:2999K->2999K(21248K)],0.0150007 secs]
[Times:user=0.01 sys=0.00,real=0.02 secs]
| GC日志区域名 | 对应GC收集器名 |
| [DefNew (Default New Generation) | Serial收集器 |
| [ParNew (Parallel New Generation) | ParNew收集器 |
| [PSYoungGen | Parallel Scavenge收集器 |
| [ParOldGen | Parallel Old收集器 |
而在方括号之外的“3324K->152K(11904K)”表示“GC前Java堆已使用容量->GC后Java堆已使用容量(Java堆总容量)”。
四、GC收集器参数
注意,这里的参数分类不是指只能在指定收集器类型配置。
1、 Serial串行收集器相关的参数
|
-XX:+UseSerialGC |
虚拟机运行在Client模式下的默认值,打开此开关后,使用Serial + Serial Old的收集器组合进行内存回收 |
|
-XX:SurvivorRatio |
新生代中设置eden区大小和survivior区大小的比例。默认为8,代表Eden:Survivor =8:1 |
|
-XX:PretenureSizeThreshold |
设置大对象直接进入老年代的阈值。当对象的大小超过这个值时,将直接在老年代分配。 |
|
-XX:MaxTenuringThreshold |
晋升到老年代的对象年龄。每个对象在坚持过一次Minor GC之后,年龄增加1,当超过这个参数值时就进入老年代 |
注意:当GC发生在新生代时,称为Minor GC,次收集;当GC发生在年老代时,称为Major GC,主收集。 一般的,Minor GC的发生频率要比Major GC高很多。
2、 ParNew并行收集器相关的参数
|
-XX:+UseParNewGC |
打开此开关后,使用ParNew + Serial Old的收集器组合进行内存回收 |
|
-XX:+UseParallelGC |
虚拟机运行在Server模式下的默认值,打开此开关后,使用Parallel Scavenge + Serial Old(PS Mark Sweep)的收集器组合进行内存回收 |
|
-XX:+UseParallelOldGC |
打开此开关后,使用Parallel Scavenge + Parallel Old的收集器组合进行内存回收 |
|
-XX:ParallelGCThreads |
设置用于垃圾回收的线程数。通常情况下可以和CPU数量相等,但在CPU数量比较多的情况下,设置相·对较小的数值也是合理的。 |
|
-XX:MaxGCPauseMills |
设置最大垃圾收集停顿时间。它的值是一个大于0的正数。收集器在工作时,会调整java堆大小或者其他一些参数,尽可能地把停顿时间控制在MaxGCPauseMills以内。 仅在Parallel Scavenge收集器时生效 |
|
-XX:GCTimeRatio |
设置吞吐量大小,即GC时间占总时间的比率。它的值是一个0到100之间的整数。假设GCTimeRatio的值为n,那么系统将花费不超过1/(1+n)的时间用于垃圾收集。默认值为99,即允许1%的GC时间,仅在Parallel Scavenge收集器时生效 |
|
-XX:+UseAdaptiveSizePolicy |
打开自适应GC策略。在这种模式下,新生代的大小、eden和survivior的比例、晋升老年代的对象年龄等参数会被自动调整,以达到在堆大小、吞吐量和停顿时间之间的平衡点。 |
| -XX:HandlePromotionFailure | 是否允许分配担保失败,即老年代的剩余空间不足以应付新生代的整个Eden和Survivor区的所有对象都存活的极端情况 |
3、 CMS 收集器相关的参数
|
-XX:+UseConcMarkSweepGC |
打开此开关后,使用ParNew + CMS —— Serial Old的收集器组合进行内存回收。Serial Old收集器是CMS收集器出现Concurrent Mode Failure失败后的备用收集器 |
|
-XX:ParallelCMSThreads |
设定CMS的线程数量。 |
|
-XX:CMSInitiatingOccupancyFraction |
设置CMS收集器在老年代空间被使用多少后触发,默认为68%。 仅在CMS收集器时生效 |
|
-XX:+UseCMSCompactAtFullCollection |
设置CMS收集器在完成垃圾收集后是否要进行一次内存碎片整理。 仅在CMS收集器时生效 |
|
-XX:CMSFullGCsBeforeCompaction |
设定进行多少次CMS垃圾回收后,进行一次内存压缩(碎片整理)。 仅在CMS收集器时生效 |
|
-XX:+CMSClassUnloadingEnabled |
允许对类元数据区进行回收。 |
|
-XX:CMSInitiatingPermOccupancyFraction |
当永久区占用率达到这一百分比时,启动CMS回收(前提是-XX:+CMSClassUnloadingEnabled激活了)。 |
|
-XX:CMSInitiatingPermOccupancyOnly |
表示只在到达阈值的时候才进行CMS回收。 |
|
-XX:+CMSIncrementalMode |
使用增量模式,比较适合单CPU。增量模式在JDK8中标记为废弃,并且将在JDK9中彻底移除。 |
4、 G1收集器相关的参数
|
-XX:+UseG1GC |
使用G1回收器。 |
|
-XX:MaxGCPauseMillis |
设置最大垃圾收集停顿时间。 |
|
-XX:GCPauseIntervalMillis |
设置停顿间隔时间。 |
JVM学习(一)、垃圾收集器简介的更多相关文章
- JVM学习记录-垃圾收集器
先回顾一下上一篇介绍的JVM中常见几种垃圾收集算法: 标记-清除算法(Mark-Sweep). 复制算法(Copying). 标记整理算法(Mark-Compact). 分代收集算法(Generati ...
- Java虚拟机JVM学习05 类加载器的父委托机制
Java虚拟机JVM学习05 类加载器的父委托机制 类加载器 类加载器用来把类加载到Java虚拟机中. 类加载器的类型 有两种类型的类加载器: 1.JVM自带的加载器: 根类加载器(Bootstrap ...
- 【JVM】JVM中的垃圾收集器
垃圾收集器组合 Serial+Serial Old Serial+CMS ParNew+CMS ParNew+Serial Old Paralle Scavenge + Serial Old Para ...
- Spark学习之路 (十四)SparkCore的调优之资源调优JVM的GC垃圾收集器
一.概述 垃圾收集 Garbage Collection 通常被称为“GC”,它诞生于1960年 MIT 的 Lisp 语言,经过半个多世纪,目前已经十分成熟了. jvm 中,程序计数器.虚拟机栈.本 ...
- jvm系列 (二) ---垃圾收集器与内存分配策略
垃圾收集器与内存分配策略 前言:本文基于<深入java虚拟机>再加上个人的理解以及其他相关资料,对内容进行整理浓缩总结.本文中的图来自网络,感谢图的作者.如果有不正确的地方,欢迎指出. 目 ...
- JVM笔记(三) 垃圾收集器(2)收集算法
垃圾收集器2:收集算法 主要通过阅读<深入了解Java虚拟机>(周志明 著)和网络资源汇集而成,为本人学习JVM的笔记.同时,本文理论基于JDK 1.7版本,暂不考虑 1.8和1.9 的新 ...
- JVM笔记(二) 垃圾收集器(1)
垃圾收集器 主要通过阅读<深入了解Java虚拟机>(周志明 著)和网络资源汇集而成,为本人学习JVM的笔记.同时,本文理论基于JDK 1.7版本,暂不考虑 1.8和1.9 的新特性,但可能 ...
- JVM优化之垃圾收集器以及内存分配
在jvm中,实现了多种垃圾收集器,包括:串行垃圾收集器.并行垃圾收集器.CMS(并发)垃圾收集器.G1垃圾收集器,接下来,我们一个个的了解学习. 串行垃圾收集器 串行垃圾收集器,是指使用单线程进行垃圾 ...
- 💕《给产品经理讲JVM》:垃圾收集器
前言 在上篇中,我们把 JVM 中的垃圾收集算法有了一个大概的了解,又是一个阴雨连绵的周末,宅在家里的我们又开始了新一轮的学习: 产品大大:上周末我们说了垃圾收集算法,下面是不是要讲一下这些算法的应用 ...
随机推荐
- Acceptance Test - Business Readable Acceptance Test using - Specflow
Agenda Benefits Living document Frameworks specflow supports How to integrate it in development cycl ...
- Redis的启动及配置
在redis已经安装完成的情况下,进入redis/bin目录下,输入命令: ./redis-server,就可以直接启动redis了,效果如图所示: 但是此时终端无法进行任何操作,按CTRL+c命令, ...
- Mybatis MapperScannerConfigurer 自动扫描 将Mapper接口生成代理注入到Spring
Mybatis MapperScannerConfigurer 自动扫描 将Mapper接口生成代理注入到Spring 非原创[只为记录],原博文地址:https://www.cnblogs.com/ ...
- PHP与Excel 笔记
一: PHP将数据导出Excel表中(投机型) 二: PHPExcel: Github上可以下载此插件包,用法如下: 前端: //上传阅卷员Excel文件 $("#upload_memb ...
- LCD调试1.0
所谓调lcd timing就是去调lcd时序,一般是6个部分:HFPD(在一行扫描以前需要多少个像素时钟),HBPD(一行扫描结束到下一行扫描开始需要多少个像素时钟),VFPD(一帧开始之前需要多少个 ...
- thinkphp5省市区三级联动例子
数据库 数据库下载地址:https://files.cnblogs.com/files/fan-bk/packet_region.zip php <?php namespace app\inde ...
- eclipse中补齐代码的快捷键
Shift+Alt+L比如我输入new TextView(this);按这个快捷键能自动生成TextView textView=new TextView(this); 例子: 代码将会变成如下:
- Python的list循环遍历中,删除数据的正确方法
在遍历list,删除符合条件的数据时,总是报异常,代码如下: num_list = [1, 2, 3, 4, 5] print(num_list) for i in range(len(num_lis ...
- Django开发目录
Django开发[第一章]:Django基础和基本使用 Django开发[第二章]:Django URLConf 进阶 Django开发[第三章]:Django View 进阶 Django开发[第四 ...
- day_8文件的操作
首先昨天讲的内容有 类型转换 1:数字类型: int () bool() float() 2:str 与int: int('10') | int('-10') | int('0') | fl ...