Matplotlib学习---用matplotlib画折线图(line chart)
这里利用Jake Vanderplas所著的《Python数据科学手册》一书中的数据,学习画图。
数据地址:https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv
准备工作:先导入matplotlib和pandas,用pandas读取csv文件,然后创建一个图像和一个坐标轴
import pandas as pd
from matplotlib import pyplot as plt
birth=pd.read_csv(r"https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv")
fig,ax=plt.subplots()
我们想要画一个反映每天平均出生人数的折线图,看看节假日是否对出生人数有影响。
折线图: ax.plot(x,y,marker="-",color="black")
这个数据文件比较大,在用print(birth.head())和print(birth.tail())分别查看前后5行数据后,发现day这一列的数据中有null字样。
用print(birth[birth["day"]!="null"])命令查看没有null字样的数据(此处只截取部分):
year month day gender births
0 1969 1 1 F 4046
1 1969 1 1 M 4440
2 1969 1 2 F 4454
3 1969 1 2 M 4548
4 1969 1 3 F 4548
5 1969 1 3 M 4994
6 1969 1 4 F 4440
7 1969 1 4 M 4520
8 1969 1 5 F 4192
9 1969 1 5 M 4198
10 1969 1 6 F 4710
11 1969 1 6 M 4850
12 1969 1 7 F 4646
13 1969 1 7 M 5092
14 1969 1 8 F 4800
15 1969 1 8 M 4934
16 1969 1 9 F 4592
17 1969 1 9 M 4842
用print(birth[birth["day"]=="null"])命令查看有null字样的数据(此处只截取部分):
year month day gender births
15067 1989 1 null F 156749
15068 1989 1 null M 164052
15069 1989 2 null F 146710
15070 1989 2 null M 154047
15071 1989 3 null F 165889
15072 1989 3 null M 174433
15073 1989 4 null F 155689
15074 1989 4 null M 163432
15075 1989 5 null F 163800
15076 1989 5 null M 172892
15077 1989 6 null F 165525
15078 1989 6 null M 173823
15079 1989 7 null F 174054
15080 1989 7 null M 183063
15081 1989 8 null F 178986
15082 1989 8 null M 188074
15083 1989 9 null F 174808
15084 1989 9 null M 182962
可以看出,从1989年开始,数据画风突变,此前记录的是每天的数据,后面记录的是每个月的数据。
这里我们先把1969年-1988年的数据提取出来进行统计:birth=birth.iloc[:15067],然后用birth.info()命令查看各列数据的类型,发现day这一列数据类型是object,因此需要转换其数据类型:
birth["day"]=birth["day"].astype(int)
接下来把year,month和day这三列的数据结合起来,用pd.to_datetime()转化为时间序列格式。结果发生了错误:
ValueError: cannot assemble the datetimes: 'int' object is unsliceable
网上查找原因,在Stackoverflow上有人解答说是因为日期可能超出了允许的范围:
The valid day range is between 1 and 31. Check your data again make sure all the columns are within allowable range.
现在需要把超标的地方找出来,看一看究竟是什么错误。用print(birth[birth["day"]>31])命令查看day超过31的地方,结果发现有好多(此处只截取部分):
year month day gender births
62 1969 1 99 F 26
63 1969 1 99 M 38
126 1969 2 99 F 42
127 1969 2 99 M 48
190 1969 3 99 F 64
191 1969 3 99 M 50
254 1969 4 99 F 50
255 1969 4 99 M 66
318 1969 5 99 F 54
319 1969 5 99 M 52
382 1969 6 99 F 54
383 1969 6 99 M 48
446 1969 7 99 F 24
447 1969 7 99 M 44
不清楚是什么情况,在这里先把这些超标数据去除:birth=birth[birth["day"]<=31]。结果发现还是不对,把数据再调出来看了之后,发现还有一些day超标,比如说2月份还有29号和30号。干脆在pd.to_datetime()命令中加上errors='coerce'参数,这样在数据超标的地方,时间序列就会变成NaT:
birth["date"]=pd.to_datetime({"year":birth["year"],"month":birth["month"],"day":birth["day"]},errors='coerce')
运行上述命令--->给birth数据文件添加了一列---“date”,记录时间序列。
再次查看birth数据后,发现在day超标的地方,date一列已经标上了NaT(此处只截取部分):
year month day gender births date
0 1969 1 1 F 4046 1969-01-01
1 1969 1 1 M 4440 1969-01-01
2 1969 1 2 F 4454 1969-01-02
.. ... ... ... ... ... ...
190 1969 3 99 F 64 NaT
191 1969 3 99 M 50 NaT
现在把date一列中不是null的值提取出来:
birth=birth[birth["date"].notnull()]
接下来制作一个透视表,把1969年-1988年之间各天出生人数的平均数计算出来(此处需要导入numpy):
birth_by_date=pd.pivot_table(birth,values="births",index=["month","day"],aggfunc=np.mean)
birth_by_date透视表如下(此处只截取部分):
births
month day
1 1 4009.225
2 4247.400
3 4500.900
4 4571.350
5 4603.625
6 4668.150
7 4706.925
8 4629.650
9 4537.775
...
12 2 4830.300
3 4758.500
4 4718.725
5 4734.675
6 4683.050
7 4704.325
8 4803.800
9 4793.825
接下来把透视表的index改为时间序列格式,由于只需要month和day这两项,year先随便填一个:
birth_by_date.index=pd.DatetimeIndex([pd.datetime(2000,month,day) for (month,day) in birth_by_date.index])
现在透视表如下(此处只截取部分):
births
2000-01-01 4009.225
2000-01-02 4247.400
2000-01-03 4500.900
2000-01-04 4571.350
2000-01-05 4603.625
2000-01-06 4668.150
2000-01-07 4706.925
2000-01-08 4629.650
2000-01-09 4537.775
终于大功告成!真不敢相信,图还没画,处理数据已经花了那么多功夫。但在实际工作中,这其实是很常见的,数据的清洗通常需要花费大部分时间。
接下来以透视表的index为x轴,values为y轴,画折线图:
ax.plot(birth_by_date.index,birth_by_date.values,"-")
图像如下:
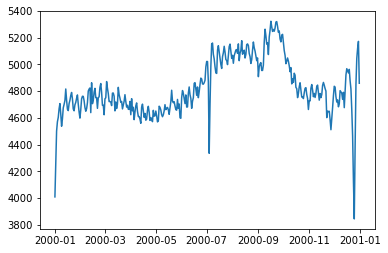
可以看出有几处日期,出生人数骤降,因此需要在这几个地方进行标注。同时,x轴的刻度值要改成12个月份,y轴要加上标签,整个图再拉长一点,再加上标题。这样,这个折线图就基本完美了。
完整代码如下:
import numpy as np
import pandas as pd
import matplotlib as mpl
from matplotlib import pyplot as plt
birth=pd.read_csv(r"https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv")
fig,ax=plt.subplots(figsize=(12,4)) birth=birth.iloc[:15067]
birth["day"]=birth["day"].astype(int) birth["date"]=pd.to_datetime({"year":birth["year"],"month":birth["month"],"day":birth["day"]},errors='coerce')
birth=birth[birth["date"].notnull()] birth_by_date=pd.pivot_table(birth,values="births",index=["month","day"],aggfunc=np.mean) birth_by_date.index=pd.DatetimeIndex([pd.datetime(2000,month,day) for (month,day) in birth_by_date.index]) ax.plot(birth_by_date.index,birth_by_date.values,"-")
ax.set(ylabel="average daily births",title="USA births by day of year (1969-1988)",xlim=("2000-01","2001-01"))
ax.grid(True) #显示网格 t=birth_by_date.stack() #把透视表展开 #在相应的地方标上节日名称
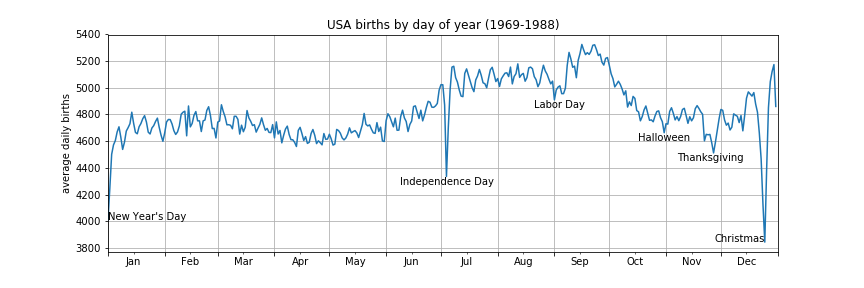
ax.text("2000-01-01",t["2000-01-01"],"New Year's Day")
ax.text("2000-07-04",t["2000-07-04"]-60,"Independence Day",ha="center")
ax.text("2000-09-04",t["2000-09-01"]-60,"Labor Day",ha="center")
ax.text("2000-10-31",t["2000-10-31"]-60,"Halloween",ha="center")
ax.text("2000-11-25",t["2000-11-27"]-60,"Thanksgiving",ha="center")
ax.text("2000-12-25",t["2000-12-25"],"Christmas",ha="right") #设置x轴刻度值为月份,并使其居中
ax.xaxis.set_major_locator(mpl.dates.MonthLocator())
ax.xaxis.set_minor_locator(mpl.dates.MonthLocator(bymonthday=15))
ax.xaxis.set_major_formatter(plt.NullFormatter())
ax.xaxis.set_minor_formatter(mpl.dates.DateFormatter('%h')) plt.show()
最终图像如下:
Matplotlib学习---用matplotlib画折线图(line chart)的更多相关文章
- Matplotlib学习---用seaborn画矩阵图(pair plot)
矩阵图非常有用,人们经常用它来查看多个变量之间的联系. 下面用著名的鸢尾花数据来画一个矩阵图.从sklearn导入鸢尾花数据,然后将其转换成pandas的DataFrame类型,最后用seaborn画 ...
- Matplotlib学习---用matplotlib画箱线图(boxplot)
箱线图通过数据的四分位数来展示数据的分布情况.例如:数据的中心位置,数据间的离散程度,是否有异常值等. 把数据从小到大进行排列并等分成四份,第一分位数(Q1),第二分位数(Q2)和第三分位数(Q3)分 ...
- python中matplotlib画折线图实例(坐标轴数字、字符串混搭及标题中文显示)
最近在用python中的matplotlib画折线图,遇到了坐标轴 "数字+刻度" 混合显示.标题中文显示.批量处理等诸多问题.通过学习解决了,来记录下.如有错误或不足之处,望请指 ...
- Matplotlib学习---用matplotlib画直方图/密度图(histogram, density plot)
直方图用于展示数据的分布情况,x轴是一个连续变量,y轴是该变量的频次. 下面利用Nathan Yau所著的<鲜活的数据:数据可视化指南>一书中的数据,学习画图. 数据地址:http://d ...
- 利用pandas读取Excel表格,用matplotlib.pyplot绘制直方图、折线图、饼图
利用pandas读取Excel表格,用matplotlib.pyplot绘制直方图.折线图.饼图 数据: 折线图代码: import pandas as pdimport matplotlib. ...
- echars画折线图的一种数据处理方式
echars画折线图的一种数据处理方式 <!DOCTYPE html> <html> <head> <meta charset="utf-8&quo ...
- SAS 画折线图PROC GPLOT
虽然最后做成PPT里的图表会被要求用EXCEL画,但当我们只是在分析的过程中,想看看数据的走势,直接在SAS里画会比EXCEL画便捷的多. 修改起来也会更加的简单,,不用不断的修改程序然后刷新EXCE ...
- 使用OpenCV画折线图
使用OpenCV画直方图是一件轻松的事情,画折线图就没有那么Easy了,还是使用一个库吧: GraphUtils 源代码添加入工程 原文链接:http://www.360doc.com/content ...
- python用matplotlib画折线图
折线图: import matplotlib.pyplot as plt y1=[10,13,5,40,30,60,70,12,55,25] x1=range(0,10) x2=range(0,10) ...
随机推荐
- Bootstrap 栅格 样式 组件 插件
-----------------------------起先是我们造成习惯,后来是习惯造成我们. day 51 Bootstrap 官方网站: bootcss.com/ <!DOCTYP ...
- python代码风格指南:pep8 中文版
本文档所提供的编码规范,适用于主要的Python发行版中组成标准库的Python代码.请参阅PEP关于Python的C实现的C编码风格指南的描述. 本文档和PEP257(文档字符串规范)改编自Guid ...
- github/gitlab同时管理多个ssh key
之前一直用github,但是github有一个不好的地方,要是创建私有的项目的话需要付费,而gitlab上则可以免费创建管理私有的项目.由于最近想把自己论文的一些东西整理一下,很多东西还是不方便公开, ...
- Python—os模块介绍
OS模块 我们平时工作中很常用到的一个模块,通过os模块调用系统命令,获得路径,获取操作系统的类型等都是使用该模块.os 模块提供了很多允许你的程序与操作系统直接交互的功能 得到当前工作目录,即当前P ...
- MyEclipse和eclipse的区别
对于新手来说,MyEclipse和eclipse来说的区别可能就是MyEclipse比eclipse多了my,MyEclipse主要为JavaEE开发,而Eclipse主要为Java开发..那么MyE ...
- eclipes个人配置
设置字体:https://jingyan.baidu.com/article/f96699bb9442f3894e3c1b15.html general->appearance->colo ...
- duxing201606的原味鸡树
链接 [http://murphyc.fun/problem/4011] 题意 描述 众所周知,duxing哥非常喜欢原味鸡.众所周知,原味鸡是长在原味鸡树上的. duxing哥因为是水产巨子,所以就 ...
- iOS 快速集成ijkplayer视频直播与录播框架
最近由于需求的变动,项目内把最初最简单的原生直播框架变成了B站开源的ijkplayer框架,下面把具体的过程总结一下整个过程都比较简单,重要的是理解的过程,集成完毕之后,视频的用户体验比苹果原生好了很 ...
- p9半幺群
如何不理解划红线的地方?第二个划红线地方,请举一个例子 1.0不是幺元 2.f(1)=2, f(2)=1, f(3)=3, g(1)=2, g(2)=3, g(3)=1 fg不等于gf
- 使用ThreadLocal管理Mybatis中SqlSession对象
转自http://blog.csdn.net/qq_29227939/article/details/52029065 public class MybatisUtil { private stati ...