Go语言类型(布尔、整型、数组、切片、map等)
1.基本类型
布尔类型:bool
注意:布尔类型不能接受其他类型的赋值,不支持自动或强制的类型转换。
整型:int8、byte(uint8)、int16、int、uint、uintptr
int、uint 、uintptr 长度同平台有关
int和int32等 不是同一种类型,可以强制类型转换,但要注意精度丢失。

C#代码:两个不同类型的整型数不能直接比较,比如int8类型的数和int类型的数不能直接比较,但各种类型的整型变量都可以直接与字面常量(literal)进行比较:
Int32 i = ;
Int64 j = ;
if (i == j) { //编译通过
Console.WriteLine("i and j are equal.");
}
if (i == || j == ) {
Console.WriteLine("i and j are equal.");
}
Go代码:
var i int32
var j int64
i, j = ,
if i == j { //编译失败
fmt.Println("i and j are equal.")
}
if i == || j == {
fmt.Println("i and j are equal.")
}
浮点类型:float32、float64
float64类型=double类型
复数类型:complex64、complex128
作用?傅里叶变换?
字符串:string
引入标准库strings包,可以使用更多字符串操作。
字符串有两种遍历方式:
①按照数组下标的方式
str := "Hello,世界"
n := len(str)
for i := ; i < n; i++ {
ch := str[i] // 依据下标取字符串中的字符,类型为byte
fmt.Println(i, ch)
}
结果:
②按照Unicode字符遍历
str := "Hello,世界"
for i, ch := range str {
fmt.Println(i, ch) //ch的类型为rune
}
字符类型:rune
结果:
区别:
一个是byte(实际上是uint8的别名),代表UTF-8字符串的单个字节的值;
另一个是rune,代表单个Unicode字符
2.复合类型
指针:pointer
在类型的前面加上*就是指针类型了,取变量的地址用&符合
例如:*int是int类型的指针类型,**int是int指针的指针类型
Go语言的指针不支持加减去读写任意内存
数组:array
①定义时候指定长度,不能更改,可以用Go语言的内置函数len()来获取长度
②Go语言中数组是一个值类型(value type)。就是当做参数传递的时候,传入的是数组的复制,而不是本身,那么也就是说在一个函数内改变了外部的数组中的某个值也是没有用的。这点和C#不太一样,C#的引用类型,改了会影响到外部。
Go数组是值类型,传递都是用复制的!!!!
2018/08/13补充
内存布局是连续的,所以数组是效率很高的数据结构。在访问数组里任意元素的时候,这种高效都是数组的优势。
数组的复制
数组变量的类型包括数组长度和每个元素的类型。只有这两部分都相同的数组,才是类型相同的数组,才能互相赋值。
什么是指针数组?
声明一个所有元素都是指针的数组。使用*运算符就可以访问元素指针所指向的值
例如:
声明包含5 个元素的指向整数的数组
用整型指针初始化索引为0 和1 的数组元素
array := []*int{: new(int), : new(int)}
为索引为0 和1 的元素赋值
*array[] =
*array[] =
什么是数组指针?
简单讲就是指向数组的指针。 *[x] int 指向整型数组的指针。
根据内存和性能来看,在函数间传递数组是一个开销很大的操作。在函数之间传递变量时,总是以值的方式传递的。如果这个变量是一个数组,意味着整个数组,不管有多长,都会完整复制,并传递给函数。
例如:
// 分配一个需要8 MB 的数组
var array [1e6]int
// 将数组的地址传递给函数foo(&取地址符号)
foo(&array)
// 函数foo 接受一个指向100 万个整型值的数组的指针
func foo(array *[1e6]int) {
...
}
切片:slice
作为数组的补充,可以理解成一个可变长度的数组
切片的数据结构可以抽象为以下3个变量:
一个指向原生数组的指针;
数组切片中的元素个数;
数组切片已分配的存储空间。
①创建
a.直接创建
Go语言提供的内置函数make()可以用于灵活地创建数组切片。
创建一个初始元素个数为5的数组切片,元素初始值为0:
mySlice1 := make([]int, )
创建一个初始元素个数为5的数组切片,元素初始值为0,并预留10个元素的存储空间:
mySlice2 := make([]int, , )
直接创建并初始化包含5个元素的数组切片:(数量和容量都是5)
mySlice3 := []int{, , , , }
b.基于数组 (前闭后开)
// 先定义一个数组
var myArray []int = []int{, , , , , , , , , }
// 基于数组创建一个数组切片,取了前5个元素
var mySlice []int = myArray[:]
myArray[x:y]可以使用这样的方式指定数组的范围。
c.基于切片
oldSlice := []int{, , , , }
newSlice := oldSlice[:3] // 基于oldSlice的前3个元素构建新数组切片
这里有个地方注意,基于切片创建的切片,可以超过切片元素的个数
newSlice := oldSlice[:6],超出的部分会填0
2018/08/13 补充
nil 和空切片
// 创建nil 整型切片
var slice []int
// 使用make 创建空的整型切片
slice := make([]int, )
// 使用切片字面量创建空的整型切片
slice := []int{}

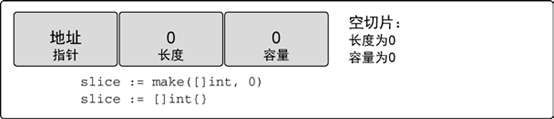
nil切片指针是nil,但是空切片指针存在
计算切片的长度和容量
对底层数组容量是k 的切片slice[i:j]来说
长度: j - i
容量: k - i
举例:对底层数组容量是5 的切片slice[1:3]来说
长度: 3 - 1 = 2
容量: 5 - 1 = 4
可以用另一种方法来描述这几个值。第一个值表示新切片开始的元素的索引位置,这个例子
中是1。第二个值表示开始的索引位置(1),加上希望包含的元素的个数(2),1+2 的结果是3,
所以第二个值就是3。容量是与该切片相关联的所有元素的数量。(我对容量的理解:这里的4是因为和容量为5的切片共用了底层的切片,所以容量就一直到5那个最大的地方5-1=4)

结果:

②对比
与数组相比,数组切片多了一个存储能力(capacity)的概念,即元素个数和分配的空间可以是两个不同的值。元素个数和分配的空间可以是两个不同的值。(声明了5个位置,但是实际大于5, make([]int, 5, 10) 个数是5,但是能存10个)
注:每次位置不够了需要重新的申请空间,但是频繁的申请空间比较消耗性能,所以要合理的安排空间。
③常用方法
cap()函数 可以查看分配的空间。
len()函数 可以查看元素的个数
append()函数 可以添加元素,可以添加元素也可以添加一个数组切片
要使用 append,需要一个被操作的切片和一个要追加的值,当append 调用返回时,会返回一个包含修改结果的新切片,函数append 总是会增加新切片的长度,而容量有可能会改变,也可能不会改变,这取决于被操作的切片的可用容量。
可以看下面的两个例子
例1 切片容量足够的情况,也是以后在用的时候也要注意的,如果一个slice从和另一个共用了一个底层的slice,要注意值的改变:
// 创建一个整型切片
// 其长度和容量都是5 个元素
slice := []int{, , , , }
// 创建一个新切片
// 其长度为2 个元素,容量为4 个元素
newSlice := slice[:]
// 使用原有的容量来分配一个新元素
// 将新元素赋值为60
newSlice = append(newSlice, )

上面可以看到60这个元素被插在了原来slice的3号位置上。
例2 容量不足的情况
// 创建一个整型切片
// 其长度和容量都是4 个元素
slice := []int{, , , }
// 向切片追加一个新元素
// 将新元素赋值为50
newSlice := append(slice, )
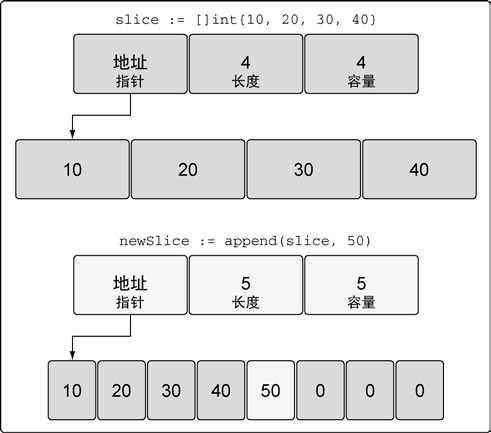
如上图所示,50这个元素放在原来的后面,并且容量翻倍了!
函数append 会智能地处理底层数组的容量增长。在切片的容量小于1000 个元素时,总是
会成倍地增加容量。一旦元素个数超过1000,容量的增长因子会设为1.25,也就是会每次增加25%
的容量。随着语言的演化,这种增长算法可能会有所改变。
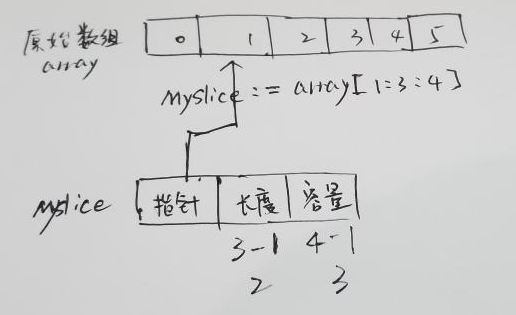
使用第三个索引值限制切片的容量
假设有一个5个元素的切片
mySlice := []int{1, 2, 3, 4, 5}
使用两个索引 slice := mySlice [2:3] 表示,从index=2开始取3-2=1个元素,
根据上面的公式
长度 = 3-2 =1
容量 = 5-2 =3
也就是实际上 如果我append一个值会将原来的切片中的5修改掉
{3,4,x} x将取代5
如下如果使用第三个索引,那么就限制了该切片的容量为4(这一块有点绕,应该描述为限制旧的为4)
slice := mySlice [2:3:4]
长度: j – i 或3 - 2 = 1
容量: k – i 或4 - 2 = 2
书上还有另外一种解释
和之前一样,第一个值表示新切片开始的元素的索引位置,这个例子中是2。第二个值表示
开始的索引位置(2)加上希望包括的元素的个数(1),2+1 的结果是3,所以第二个值就是3。为
了设置容量,从索引位置2 开始,加上希望容量中包含的元素的个数(2),就得到了第三个值4。
在函数间传递切片 、
上面数组的时候说了,数组是值传递的,复制了一个副本,这样的效率太低。所以一般使用地址进行传递。
切片传递,其实就是地址传递,所以函数间传递直接传递就行了。
切片可以理解就是一个 指针+长度+容量
// 分配包含100 万个整型值的切片
slice := make([]int, 1e6)
// 将slice 传递到函数foo
slice = foo(slice)
// 函数foo 接收一个整型切片,并返回这个切片
func foo(slice []int) []int {
...
return slice
}

但是要注意:
给mySlice后面添加另一个数组切片,必须添加"...",因为mySlice中的元素类型为int,所以直接传递mySlice2是行不通的。加上省略号相当于把mySlice2包含的所有元素打散后传入。
mySlice = append(mySlice, mySlice2...)
copy()函数,主要用于复制
slice1 := []int{, , , , }
slice2 := []int{, , }
copy(slice2, slice1) // 只会复制slice1的前3个元素到slice2中
copy(slice1, slice2) // 只会复制slice2的3个元素到slice1的前3个位置
附上:我认为比较好的 https://www.jianshu.com/p/030aba2bff41 slice讲解
这个对于切片的定义特别好!
切片本身并不是动态数组或者数组指针。它内部实现的数据结构通过指针引用底层数组,设定相关属性将数据读写操作限定在指定的区域内。
切片本身是一个只读对象,其工作机制类似数组指针的一种封装。
字典:map
map是一堆键值对的未排序集合,在C#中是Dictionary<>
[]里面是key键,外面是值value
①声明:
var myMap map[keyType] valueType
map[keyType] valueType 这是类型
②创建:
声明之后不能直接使用,需要用make方法开辟空间
myMap = make(map[keyType] ValueType)
myMap = make(map[keyType] ValueType, ) 指定了大小的map
③赋值:
myMap["key"] = ValueType{"xxxx", "yyy", "zzzz"}
④删除(delete方法):
delete(myMap, "")
⑤查找:
Go语言的查找很有意思
我们在C#语言中,比如要做一个查找map中是否存在某个key的操作,存在的话取出这个这个值
我们一般会这么写
var dic = new Dictionary<string,string>();
dic.Add("","");
dic.Add("","");
var key = "";
if (dic.ContainsKey(key))
{
var value = dic[key];
}
else
{
//Do Something
}
我们会先判断存在不存在,然后取出值
但是Go语言中一行代码就解决了
value, ok := myMap["key"]
其中ok就代表了元素存在不存在的判断结果。
2018/08/15 补充
在函数间传递映射
在函数间传递映射并不会制造出该映射的一个副本。
package main import(
"fmt"
)
// removeColor 将指定映射里的键删除
func removeColor(colors map[string]string, key string) {
delete(colors, key)
} func main() {
// 创建一个映射,存储颜色以及颜色对应的十六进制代码
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
"DarkGray": "#a9a9a9",
"ForestGreen": "#228b22",
}
// 显示映射里的所有颜色
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
}
// 调用函数来移除指定的键
removeColor(colors, "Coral")
fmt.Println("=======删除之后=========")
// 显示映射里的所有颜色
for key, value := range colors {
fmt.Printf("Key: %s Value: %s\n", key, value)
} }
结果:
结果:
Key: AliceBlue Value: #f0f8ff
Key: Coral Value: #ff7F50
Key: DarkGray Value: #a9a9a9
Key: ForestGreen Value: #228b22
=======删除之后=========
Key: AliceBlue Value: #f0f8ff
Key: DarkGray Value: #a9a9a9
Key: ForestGreen Value: #228b22
结构体:struct
声明
type Student struct {
Name string
Age int
}
定义赋值
std := Student{"BigOrange",26}
使用
fmt.Println("Name:", std.Name, "Age:",std.Age)
接口:interface
后面专门详细展开
通道:chan
后面专门详细展开
错误类型:error
后面专门详细展开
综上我来总结一下:
1.Go语言的类型分为值类型和引用类型。
值类型:布尔类型、整型、浮点型、字符串类型、数组等,主要传递通过复制
引用类型:切片、映射等 主要通过传指针
2.整型中 不同位数的也看做不同类型,不能直接比较int8 int16不能用 if x==y 做比较
3.字符串有两种遍历方式 for 和 for range 出来的结果稍微不同,一个是byte(实际上是uint8的别名),代表UTF-8字符串的单个字节的值;另一个是rune,代表单个Unicode字符。
4.数组是值类型,保存相同类型的数据,不能动态扩展,函数间传递是值传递,大数组传递效率比较低,使用传地址的方式传递。
5.切片是引用类型,保存相同类型数据,可以扩充,实际上是一种数组的封装,有指针、长度和容量。
6.切片创建的时候有三个索引值slice[x:y:z]
x: 新切片开始的元素的索引位置,上面的slice1[1:3:4]中的1就是起始索引
y: 新切片希望包含的元素个数,上面的slice1[1:3:4],希望长度是2,那么y= 1+2 =3
z: 限定新切片的容量大小,上面的slice1[1:3:4],例如限定容量是3, z=1+3 = 4
画图简单
综上我来总结一下:
1.Go语言的类型分为值类型和引用类型。
值类型:布尔类型、整型、浮点型、字符串类型、数组等,主要传递通过复制
引用类型:切片、映射等 主要通过传指针
2.整型中 不同位数的也看做不同类型,不能直接比较int8 int16不能用 if x==y 做比较
3.字符串有两种遍历方式 for 和 for range 出来的结果稍微不同,一个是byte(实际上是uint8的别名),代表UTF-8字符串的单个字节的值;另一个是rune,代表单个Unicode字符。
4.数组是值类型,保存相同类型的数据,不能动态扩展,函数间传递是值传递,大数组传递效率比较低,使用传地址的方式传递。
5.切片是引用类型,保存相同类型数据,可以扩充,实际上是一种数组的封装,有指针、长度和容量。
6.切片创建的时候有三个索引值slice[x:y:z]
x: 新切片开始的元素的索引位置,上面的slice1[1:3:4]中的1就是起始索引
y: 新切片希望包含的元素个数,上面的slice1[1:3:4],希望长度是2,那么y= 1+2 =3
z: 限定新切片的容量大小,上面的slice1[1:3:4],例如限定容量是3, z=1+3 = 4
画图简单
func main() {
array:=[]int{,,,,,}
myslice:=array[::]
var lens = len(myslice)
var caps = cap(myslice)
fmt.Println("长度:",lens)
fmt.Println("容量:",caps)
}
结果:
长度:
容量:
7.创建新的切片需要,将容量进行限定,因为如果两个切片共用一个底层的数组,不限定容量,可能会导致数值的变化
func main() {
array:=[]int{,,,,,}
myslice:=array[::]
myslice2:=array[::]
var lens1 = len(myslice)
var caps1 = cap(myslice)
var lens2 = len(myslice2)
var caps2 = cap(myslice2)
fmt.Println("长度:",lens1)
fmt.Println("容量:",caps1)
fmt.Println("长度:",lens2)
fmt.Println("容量:",caps2)
fmt.Println("修改前myslice[0]",myslice[])
fmt.Println("修改前myslice[1]",myslice[])
fmt.Println("修改前myslice2[0]",myslice2[])
fmt.Println("修改前myslice2[1]",myslice2[])
myslice = append(myslice,,)
fmt.Println("修改后myslice[0]",myslice[])
fmt.Println("修改后myslice[1]",myslice[])
fmt.Println("修改后append数据 myslice[2]",myslice[])
fmt.Println("修改后append数据 myslice[3]",myslice[])
fmt.Println("修改后myslice2[0]",myslice2[])
fmt.Println("修改后myslice2[1]",myslice2[])
}
结果:
长度:
容量:
长度:
容量:
修改前myslice[]
修改前myslice[]
修改前myslice2[]
修改前myslice2[]
修改后myslice[]
修改后myslice[]
修改后append数据 myslice[]
修改后append数据 myslice[]
修改后myslice2[]
修改后myslice2[]
从结果里面可以看出来,mySlice2这里的值被修改了。
//限定长度和容量一样
myslice:=array[::]
myslice2:=array[::]
结果:
长度:
容量:
长度:
容量:
修改前myslice[]
修改前myslice[]
修改前myslice2[]
修改前myslice2[]
修改后myslice[]
修改后myslice[]
修改后append数据 myslice[]
修改后append数据 myslice[]
修改后myslice2[]
修改后myslice2[]
从结果里面可以看出来,mySlice2这里的值没有变。
限定过后,将长度和容量改为一致,会重新申请新的内存,不会改以前的,
Go语言类型(布尔、整型、数组、切片、map等)的更多相关文章
- Python基础:1.数据类型(空、布尔类型、整型、长整型、浮点型、字符串)
提示:python版本2.7,windows系统 Python提供的基本数据类型:空.布尔类型.整型.长整型.浮点型.字符串.列表.元组.字典.日期 1.空(None) None,是一个特殊的值,不能 ...
- Docs-.NET-C#-指南-语言参考-关键字-内置类型-值类型:整型数值类型
ylbtech-Docs-.NET-C#-指南-语言参考-关键字-内置类型-值类型:整型数值类型 1.返回顶部 1. 整型数值类型(C# 参考) 2019/10/22 “整型数值类型”是“简单类型”的 ...
- 在主方法中定义一个大小为50的一维整型数组,数组i名为x,数组中存放着{1,3,5,…,99}输出这个数组中的所有元素,每输出十个换一行
package hanqi; import java.util.Scanner; public class Test7 { public static void main(String[] args) ...
- 整型数组与vector对象之间的相互初始化
#include<iostream> #include<vector> #include<string> using namespace std; int main ...
- [原]Java面试题-输入一个整型数组,找出最大值、最小值,并交换。
[Date]2013-09-19 [Author]wintys (wintys@gmail.com) http://wintys.cnblogs.com [Content]: 1.面试题 输入一个整型 ...
- java程序中默认整形值常量是什么类型的?如何区分不同类型的整型数值常量?
java程序中默认整形值常量是什么类型的?如何区分不同类型的整型数值常量? 整数值默认就是int类型,只有在数值常量后面加“L”或“l”才表明该常量是long型
- Python变量类型(l整型,长整形,浮点型,复数,列表,元组,字典)学习
#coding=utf-8 __author__ = 'Administrator' #Python变量类型 #Python数字,python支持四种不同的数据类型 int整型 long长整型 flo ...
- Go语言学习笔记(三)数组 & 切片 & map
加 Golang学习 QQ群共同学习进步成家立业工作 ^-^ 群号:96933959 数组 Arrays 数组是同一种数据类型的固定长度的序列. 数组是值类型,因此改变副本的值,不会改变本身的值: 当 ...
- Go语言学习之4 递归&闭包&数组切片&map&锁
主要内容: 1. 内置函数.递归函数.闭包2. 数组与切片3. map数据结构4. package介绍 5. 排序相关 1. 内置函数.递归函数.闭包 1)内置函数 (1). close:主要用来关闭 ...
- MySQL各种日期类型与整型(转)
日期类型 存储空间 日期格式 日期范围 datetime 8 bytes YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 t ...
随机推荐
- Nginx学习之如何搭建文件防盗链服务
前言 大家都知道现在很多站点下载资料都是要收费的,无论是积分还是金币,想免费只能说很少很少了,那么这些网站是如何做到资源防盗链的呢? 这里推荐一款比较容易上手的神器,Nginx本身提供了secure_ ...
- [翻译] C# 8.0 新特性
原文: Building C# 8.0 [译注:原文主标题如此,但内容大部分为新特性介绍,所以意译标题为 "C# 8.0 新特性"] C# 的下一个主要版本是 8.0.我们已经为它 ...
- ASP.NET MVC必须知道的那些事!
MVC的由来: 在MVC模式之前,View界面的呈现.用户交互操作的捕捉与相应.业务流程的执行以及数据的存储等都是在一起的,这种设计模式叫自治视图. 这重设计模式主要存在三大弊端: 重用性:业务逻辑与 ...
- RabbitMQ总结
消息队列 三个业务场景:解耦.异步.削峰 带来问题 系统可用性降低:外部依赖越多,越容易挂掉. 系统复杂性提高:重复消费,消息丢失,消息传递的顺序性 一致性问题: 一.如何保证消息的可靠性传输(如何处 ...
- LCT维护删除时间最晚生成树
用来做动态图问题. 维护一棵删除时间最晚的生成树,这样好处是加入一条非树边时可以直接判断加还是不加,没有现在不加入而之后再加入的情况.要是我比你先被删,那我就完全没必要加.否则你现在就可以被删除掉.
- 1003: [ZJOI2006]物流运输 = DP+SBFA
题意就是告诉你有n个点,e条边,m天,每天都会从起点到终点走一次最短路,但是有些点在某些时间段是不可走的,因此在某些天需要改变路径,每次改变路径的成本是K,总成本=n天运输路线长度之和+K*改变运输路 ...
- D - Nature Reserve(cf514,div2)
题意:给出n(n<=1e5)个点,求一个最小的圆,与x轴相切,并且包含这n个点 思路:我第一想到的是,这个圆一定会经过一个点,再根据与x轴相切,我们可以找到最小的圆,让它包含其余的点,但是如何判 ...
- C#跨进程读取listview控件中的数据
http://www.cnblogs.com/Charltsing/p/slv32.html 欢迎交流:QQ564955427 读取标准的32位listview控件中的数据,网上已经有很多代码了.今天 ...
- VO和DO转换(四) MapStruct
VO和DO转换(一) 工具汇总 VO和DO转换(二) BeanUtils VO和DO转换(三) Dozer VO和DO转换(四) MapStruct MapStruct
- PAT L2-013 红色警报
https://pintia.cn/problem-sets/994805046380707840/problems/994805063963230208 战争中保持各个城市间的连通性非常重要.本题要 ...