ElasticSearch是如何实现分布式的?
面试题
es 的分布式架构原理能说一下么(es 是如何实现分布式的啊)?
面试官心理分析
在搜索这块,lucene 是最流行的搜索库。几年前业内一般都问,你了解 lucene 吗?你知道倒排索引的原理吗?现在早已经 out 了,因为现在很多项目都是直接用基于 lucene 的分布式搜索引擎—— ElasticSearch,简称为 es。
而现在分布式搜索基本已经成为大部分互联网行业的 Java 系统的标配,其中尤为流行的就是 es,前几年 es 没火的时候,大家一般用 solr。但是这两年基本大部分企业和项目都开始转向 es 了。
所以互联网面试,肯定会跟你聊聊分布式搜索引擎,也就一定会聊聊 es,如果你确实不知道,那你真的就 out 了。
如果面试官问你第一个问题,确实一般都会问你 es 的分布式架构设计能介绍一下么?就看看你对分布式搜索引擎架构的一个基本理解。
面试题剖析
ElasticSearch 设计的理念就是分布式搜索引擎,底层其实还是基于 lucene 的。核心思想就是在多台机器上启动多个 es 进程实例,组成了一个 es 集群。
es 中存储数据的基本单位是索引,比如说你现在要在 es 中存储一些订单数据,你就应该在 es 中创建一个索引 order_idx,所有的订单数据就都写到这个索引里面去,一个索引差不多就是相当于是 mysql 里的一张表。
index -> type -> mapping -> document -> field。
这样吧,为了做个更直白的介绍,我在这里做个类比。但是切记,不要划等号,类比只是为了便于理解。
index 相当于 mysql 里的一张表。而 type 没法跟 mysql 里去对比,一个 index 里可以有多个 type,每个 type 的字段都是差不多的,但是有一些略微的差别。假设有一个 index,是订单 index,里面专门是放订单数据的。就好比说你在 mysql 中建表,有些订单是实物商品的订单,比如一件衣服、一双鞋子;有些订单是虚拟商品的订单,比如游戏点卡,话费充值。就两种订单大部分字段是一样的,但是少部分字段可能有略微的一些差别。
所以就会在订单 index 里,建两个 type,一个是实物商品订单 type,一个是虚拟商品订单 type,这两个 type 大部分字段是一样的,少部分字段是不一样的。
很多情况下,一个 index 里可能就一个 type,但是确实如果说是一个 index 里有多个 type 的情况(注意,mapping types 这个概念在 ElasticSearch 7.X 已被完全移除,详细说明可以参考官方文档),你可以认为 index 是一个类别的表,具体的每个 type 代表了 mysql 中的一个表。每个 type 有一个 mapping,如果你认为一个 type 是具体的一个表,index 就代表多个 type 同属于的一个类型,而 mapping 就是这个 type 的表结构定义,你在 mysql 中创建一个表,肯定是要定义表结构的,里面有哪些字段,每个字段是什么类型。实际上你往 index 里的一个 type 里面写的一条数据,叫做一条 document,一条 document 就代表了 mysql 中某个表里的一行,每个 document 有多个 field,每个 field 就代表了这个 document 中的一个字段的值。
你搞一个索引,这个索引可以拆分成多个 shard,每个 shard 存储部分数据。拆分多个 shard 是有好处的,一是支持横向扩展,比如你数据量是 3T,3 个 shard,每个 shard 就 1T 的数据,若现在数据量增加到 4T,怎么扩展,很简单,重新建一个有 4 个 shard 的索引,将数据导进去;二是提高性能,数据分布在多个 shard,即多台服务器上,所有的操作,都会在多台机器上并行分布式执行,提高了吞吐量和性能。
接着就是这个 shard 的数据实际是有多个备份,就是说每个 shard 都有一个 primary shard,负责写入数据,但是还有几个 replica shard。primary shard 写入数据之后,会将数据同步到其他几个 replica shard 上去。
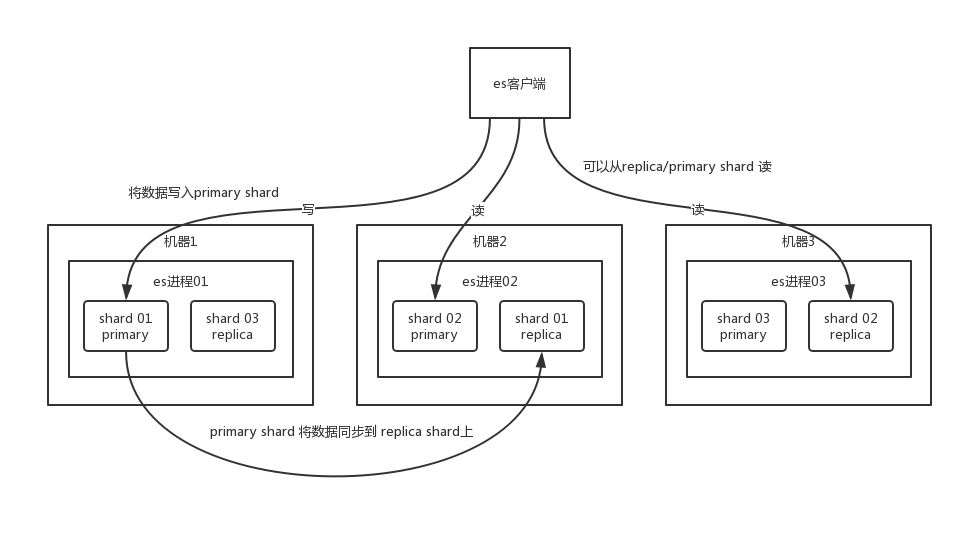
通过这个 replica 的方案,每个 shard 的数据都有多个备份,如果某个机器宕机了,没关系啊,还有别的数据副本在别的机器上呢。高可用了吧。
es 集群多个节点,会自动选举一个节点为 master 节点,这个 master 节点其实就是干一些管理的工作的,比如维护索引元数据、负责切换 primary shard 和 replica shard 身份等。要是 master 节点宕机了,那么会重新选举一个节点为 master 节点。
如果是非 master节点宕机了,那么会由 master 节点,让那个宕机节点上的 primary shard 的身份转移到其他机器上的 replica shard。接着你要是修复了那个宕机机器,重启了之后,master 节点会控制将缺失的 replica shard 分配过去,同步后续修改的数据之类的,让集群恢复正常。
说得更简单一点,就是说如果某个非 master 节点宕机了。那么此节点上的 primary shard 不就没了。那好,master 会让 primary shard 对应的 replica shard(在其他机器上)切换为 primary shard。如果宕机的机器修复了,修复后的节点也不再是 primary shard,而是 replica shard。
其实上述就是 ElasticSearch 作为分布式搜索引擎最基本的一个架构设计。
免费Java资料需要自己领取,涵盖了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo/Kafka、Hadoop、Hbase、Flink等高并发分布式、大数据、机器学习等技术。
传送门:https://mp.weixin.qq.com/s/JzddfH-7yNudmkjT0IRL8Q
ElasticSearch是如何实现分布式的?的更多相关文章
- ElasticSearch 5学习(7)——分布式集群学习分享2
前面主要学习了ElasticSearch分布式集群的存储过程中集群.节点和分片的知识(ElasticSearch 5学习(6)--分布式集群学习分享1),下面主要分享应对故障的一些实践. 应对故障 前 ...
- ElasticSearch 5学习(6)——分布式集群学习分享1
在使用中我们把文档存入ElasticSearch,但是如果能够了解ElasticSearch内部是如何存储的,将会对我们学习ElasticSearch有很清晰的认识.本文中的所使用的ElasticSe ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- ElasticSearch 5学习(8)——分布式文档存储(wait_for_active_shards新参数分析)
学完ES分布式集群的工作原理以及一些基本的将数据放入索引然后检索它们的所有方法,我们可以继续学习在分布式系统中,每个分片的文档是被如何索引和查询的. 路由 首先,我们需要明白,文档和分片之间是如何匹配 ...
- ELK( ElasticSearch+ Logstash+ Kibana)分布式日志系统部署文档
开始在公司实施的小应用,慢慢完善之~~~~~~~~文档制作 了好作运维同事之间的前期普及.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 软件下载地址: https://www.e ...
- ElasticSearch文档及分布式文档存储
1.什么是文档? 文档由索引(_index),类型(_type),唯一标识(_id) 组成,我们为 _index(索引) 分配相关逻辑地址分片,该索引下的数据会根据索引以及类型计算哈希来分配数据存储的 ...
- ELK6.0部署:Elasticsearch+Logstash+Kibana搭建分布式日志平台
一.前言 1.ELK简介 ELK是Elasticsearch+Logstash+Kibana的简称 ElasticSearch是一个基于Lucene的分布式全文搜索引擎,提供 RESTful API进 ...
- Elasticsearch+Logstash+Kibana搭建分布式日志平台
一.前言 编译安装 1.ELK简介 下载相关安装包地址:https://www.elastic.co/cn/downloads ELK是Elasticsearch+Logstash+Kibana的简称 ...
- mac 下搭建Elasticsearch 5.4.3分布式集群
一.集群角色 多机集群中的节点可以分为master nodes和data nodes,在配置文件中使用Zen发现(Zen discovery)机制来管理不同节点.Zen发现是ES自带的默认发现机制,使 ...
随机推荐
- django settings配置文件ALLOWED_HOSTS
ALLOWED_HOSTS列表为了防止黑客入侵,只允许列表中的ip地址访问 填写上“*”可以使所有的网址都能访问Django项目了,项目测试的时候,可以这么做.这样就失去了保护
- github ignore 规范
转自:https://www.cnblogs.com/xuld gitignore 应该包含 5 块内容: 当前项目需要忽略的文件 项目性质需要忽略的文件(比如是 nodejs 项目,有些文件就需要忽 ...
- H5基础
<html> <head lang="en"> <meta charset="utf_8"> ...
- Mad Libs游戏
一. 简单的输入输出 输入代码 name1=input('请输入姓名:') name2=input('请输入一个句子:') name3=input('请输入一个地点:') name4=input('请 ...
- 根据select出来的数据进行update
update t_tbl_desc set num=b.num from t_tbl_desc a, (select distinct(name) as name,count(name) num fr ...
- AX_DataSource
for (custInvoiceJourLocal = custInvoiceJour_ds.getFirst(true) ? custInvoiceJour_ds.getFirst(true) : ...
- Sublime Text 3安装emmet(ZenCoding)
1.安装 Package Ctrol: 使用 ctrl + - 打开控制台,输入以下代码 import urllib.request,os; pf = 'Package Control.sublime ...
- CRT-常用命令
1 目录操作 mkdir a ;(新建文件夹) mkdir -p a/b;(新建多及目录文件夹) Rmdir a (a只能是空目录) Rmdir -p a (a可以是多级目录) 2 文件操作 touc ...
- 【机器学习】随机森林 Random Forest 得到模型后,评估参数重要性
在得出random forest 模型后,评估参数重要性 importance() 示例如下 特征重要性评价标准 %IncMSE 是 increase in MSE.就是对每一个变量 比如 X1 随机 ...
- 描点的改进:运用chart画图。
主要是利用Chart画图: 通过选中一部分曲线进行图像的放大和缩小,最小值为1格. 先计算最大值和最小差值.然后赋值给AxisY.Minimum 和AxisY.Maximum.x轴初始显示数目:Axi ...