pandas数据结构之DataFrame操作
这一次我的学习笔记就不直接用官方文档的形式来写了了,而是写成类似于“知识图谱”的形式,以供日后参考。
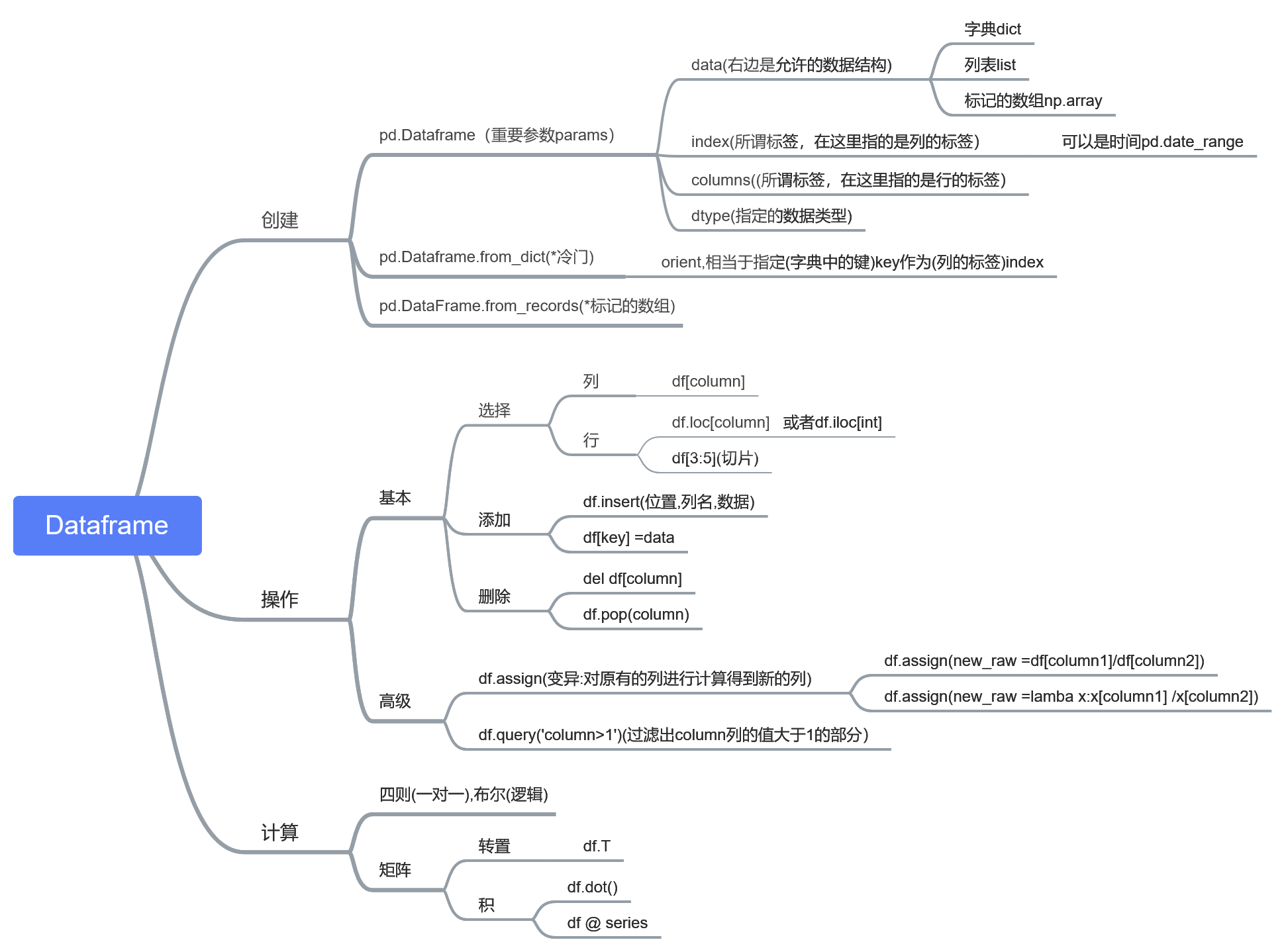
原来写的地方是,那儿的代码看起来会舒服很多: https://www.yuque.com/u86460/dgt6mu/tlywuc
>>> import pandas as pd
>>> #由series构成
>>> d ={'a':pd.Series([1,2,3,4]),'b':pd.Series([4,3,2,1,0])}
>>> df =pd.DataFrame(d)
>>> df
a b
0 1.0 4
1 2.0 3
2 3.0 2
3 4.0 1
4 NaN 0
>>> #指定Series的index(标签)
>>> d ={'a':pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
'b':pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])}
>>> pd.DataFrame(d)
a b
a 1.0 4
b 2.0 3
c 3.0 2
d 4.0 1
f NaN 0
>>> #指定Dataframe的index(列标签)
>>> pd.DataFrame(d,index =['a', 'b', 'c','d','f'])
a b
a 1.0 4
b 2.0 3
c 3.0 2
d 4.0 1
f NaN 0
>>> #指定Dataframe的columns(行标签)
>>> pd.DataFrame(d,index =['a', 'b', 'c','d','f'],columns=['b','c'])
b c
a 4 NaN
b 3 NaN
c 2 NaN
d 1 NaN
f 0 NaN
>>> d ={'a':[1,2,3,4],'b':[4,3,2,1]}
>>> pd.DataFrame(d,index=['a', 'b', 'c','d'])
a b
a 1 4
b 2 3
c 3 2
d 4 1
>>> pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},
('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},
('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},
('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},
('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})
a b
b a c a b
A B 1.0 4.0 5.0 8.0 10.0
C 2.0 3.0 6.0 7.0 NaN
D NaN NaN NaN NaN 9.0
>>> d = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
>>> pd.DataFrame(d)
a b c
0 1 2 NaN
1 5 10 20.0
>>> d =[pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])]
>>> pd.DataFrame(d)
a b c d f
0 1.0 2.0 3.0 4.0 NaN
1 4.0 3.0 2.0 1.0 0.0
>>> pd.DataFrame(d,index =['a','b'])
a b c d f
a 1.0 2.0 3.0 4.0 NaN
b 4.0 3.0 2.0 1.0 0.0
>>> #每一个series就是一行
>>> import numpy as np
>>> #指定数组每一列的数据类型,相当于创建一个模板
>>> data = np.zeros((2,), dtype=[('A', 'i4'),('B', 'f4'),('C', 'a10')])
>>> #为模板赋值
>>> data[:] = [(1,2.,'Hello'), (2,3.,"World")]
>>> pd.DataFrame(data)
A B C
0 1 2.0 b'Hello'
1 2 3.0 b'World'
>>> pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]))
A B
0 1 4
1 2 5
2 3 6
>>> pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]),
orient='index', columns=['one', 'two', 'three'])
one two three
A 1 2 3
B 4 5 6
#orient,相当于指定(字典中的键)key作为(列的标签)index
>>> pd.DataFrame.from_records(data, index='C')
A B
C
b'Hello' 1 2.0
b'World' 2 3.0
import pandas as pd
import numpy as np
#**创建部分
#df.Dataframe(data,index)
'类型是字典'
#由series构成
d ={'a':pd.Series([1,2,3,4]),'b':pd.Series([4,3,2,1,0])}
d ={'a':pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
'b':pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])} #指定Series的index(标签)
pd.DataFrame(d,index =['a', 'b', 'c','d','f']) #指定Dataframe的index(列标签)
pd.DataFrame(d,index =pd.date_range('2000/1/1',periods=2)) #指定标签为日期
pd.DataFrame(d,index =['a', 'b', 'c','d','f'],columns=['b','c']) #指定Dataframe的columns(行标签)
#字典由列表或数组构成
d ={'a':[1,2,3,4],'b':[4,3,2,1]}
pd.DataFrame(d,index=['a', 'b', 'c','d'])
#字典的键由元组构成
pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},
('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},
('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},
('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},
('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})
'类型是list'
#多个的字典构成的列表
d = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
#多个series构成的列表
d =[pd.Series([1,2,3,4],index=['a', 'b', 'c','d']),
pd.Series([4,3,2,1,0],index=['a', 'b', 'c','d','f'])]
'类型是标记的数组'
data = np.zeros((2,), dtype=[('A', 'i4'),('B', 'f4'),('C', 'a10')]) #指定数组每一列的数据类型,相当于创建一个模板
data[:] = [(1,2.,'Hello'), (2,3.,"World")] #为模板赋值
#pd.DataFrame.from_dict(dict)
pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]))
pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]),
orient='index', columns=['one', 'two', 'three'])
#orient,相当于指定(字典中的键)key作为(列的标签)index
#DataFrame.from_records
df =pd.DataFrame.from_records(data, index='C')
#**操作部分
'选择'
#选择列
df['A']
#选择行
df.loc[b'Hello']
df.iloc[0]
df['d'] =df['A'] *df['B'] #生成新列
df['e'] =df['A'] >2
df['f'] =df['A'][:1] #切片
'添加'
df.insert(1,'dd',df['B']) #位置,column,值
'删除'
del df['A']
df.pop('B')
'变异'
df =pd.DataFrame(d)
df1 =df.assign(new =df['a'] +df['b'])
df1 =df.assign(new =lambda x:x['a'] *x['b'])
'过滤'
df1=df.query('a>1').assign(new =df['a'] +df['b'])
#**计算部分
'四则,布尔:+-*/,|&^ 都是点对点形式'
'矩阵'
df.T #转置
df.T@df
df.T.dot(df) #积
#输出部分
df.to_string()
#pd.set_option('display.max_colwidth',30)
#pd.set_option('display.width', 40) # default is 80
pandas数据结构之DataFrame操作的更多相关文章
- pandas 学习(2): pandas 数据结构之DataFrame
DataFrame 类型类似于数据库表结构的数据结构,其含有行索引和列索引,可以将DataFrame 想成是由相同索引的Series组成的Dict类型.在其底层是通过二维以及一维的数据块实现. 1. ...
- pandas数据结构之Dataframe
Dataframe DataFrame是一个[表格型]的数据结构,可以看做是[由Series组成的字典](多个series共用同一个索引).DataFrame由按一定顺序排列的多列数据组成.设计初衷是 ...
- pandas数据结构之DataFrame笔记
DataFrame输出的为表的形式,由于要把输出的表格贴上来比较麻烦,在此就不在贴出相关输出结果,代码在jupyter notebook可以顺利运行代码中有相关解释用来加深理解方便记忆 import ...
- pandas数据结构之series操作
阅读之前假定你已经有了python内置的list和dict的基础.这里内容几乎是官方文档的翻译版本. 概览: 原来的文档是在一个地方,那边的代码看起来舒服些 https://www.y ...
- 03. Pandas数据结构
03. Pandas数据结构 Series DataFrame 从DataFrame中查询出Series 1. Series Series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一 ...
- pandas数据结构:Series/DataFrame;python函数:range/arange
1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index). 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会 ...
- pandas基础:Series与DataFrame操作
pandas包 # 引入包 import pandas as pd import numpy as np import matplotlib.pyplot as plt Series Series 是 ...
- [转]python中pandas库中DataFrame对行和列的操作使用方法
转自:http://blog.csdn.net/u011089523/article/details/60341016 用pandas中的DataFrame时选取行或列: import numpy a ...
- Pandas 数据结构Dataframe:基本概念及创建
"二维数组"Dataframe:是一个表格型的数据结构,包含一组有序的列,其列的值类型可以是数值.字符串.布尔值等. Dataframe中的数据以一个或多个二维块存放,不是列表.字 ...
随机推荐
- Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks-paper
Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks 作者信息:Kai Shen ...
- SpringBoot框架中,使用过滤器进行加密解密操作(一)
一.基本说明 1.请求方式:POST请求.注解@PostMapping 2.入参格式:json串 3.出参格式:json串(整体加密) 4.使用Base64进行加密解密.具体的加密方式,可以根据需求自 ...
- Maven,gradle的搭建工具
Glassfish安装.基本使用 一.glassfish简介 glassfish是一款web应用服务器,和tomcat一样,也是一款优秀的Servlet容器. 二.glassfish知识点 1.dom ...
- 顺序栈代码实现&&stack库
#include<iostream> using namespace std; ; typedef int Elemtype; struct SqStack { Elemtype *bas ...
- ubuntu 安装 pycharm
添加源: $ sudo add-apt-repository ppa:mystic-mirage/pycharm 安装收费的专业版: $ sudo apt update $ sudo apt in ...
- Yii2.0 RESTful API 基础配置教程
创建api应用 通过拷贝原有的应用,重命名得到新的应用 安装完 Composer,运行下面的命令来安装 Composer Asset 插件: php composer.phar global req ...
- Ansible 之动态Inventory文件(二)
上篇主要讲解了Ansible 的安装和配置,并且根据不同的业务场景将服务器的信息存放在Ansible的Inventory中,其实存放这样的数据每次更新都需要我们自动的添加和删除,这样对于我们维护起来很 ...
- ecmobile-页面空白,也没异常提示,一般就是这个问题
分类页空白了://2018年09月07日14:55:21 四:页面空白 将ON_WILL_APPEAR中有关页面布局方法写在ON_DID_APPEAR方法中.例如:
- html限制文本框只能输入数字和一个小数点
近期在做一个前台页面,有一个文本框是用来输入充值金额的,就想到了限制用户只能输入纯数字的数据且只能包含一个小数点.下面就是我实现的代码 $(function() { //阻止数字键以外的按键输入 $( ...
- Winform外包团队 项目案例展示
北京动点飞扬软件开发团队 C# WInform项目案例展示 长年承接WInForm C#项目开发,商业案例欢迎联系我们索取 有相关项目外包定制开发 欢迎联系我们 qq372900288 Tel 139 ...