ML - 特征选择
1. 决策树中的特征选择
分类决策树是一种描述对实例进行分类的树型结构,决策树学习本质上就是从训练数据集中归纳出一组分类规则,而二叉决策树类似于if-else规则。决策树的构建也是非常的简单,首先依据某种特征选择手段对每一特征对分类的贡献性大小排序,然后从根节点开始依次取出剩下特征中对分类贡献最大的特征,用其作为当前节点的分类准则,进一步构造其叶子结点,然后重复此过程,直到特征用光或满足了预先设定的要求终止决策树的构建。由此可见,特征选择作为决策树构建的核心技术而存在,那么下面我们就来讨论一下决策树中常用的特征选择技术有哪些:
1.1 信息增益与信息增益比
一个特征所包含的信息量可以通过看这个特征对整体稳定性的影响大小来确定。举个例子,
假设我问你:今年冬天会下雪?
你会反问:你说的哪呀?南方和北方会一样么?你说的话一点信息量都没有!
我又问:海南,今年冬天会下雪么?
你会说:那肯定不会下呀,气温都到不了0下!
从这对话中我们看到,就冬天会不会下雪这个问题开始时会有两个等可能的判断,这时候是最让我们摸不着头脑的,如果我们接着为其添加一个地域的约束也就是上面的A,此时我们的问题就一下子明朗起来,可见地域信息为我们这个问题的判断提供了非常大的信息参考。除了地域这个特征,也许还有其他一些信息会影响我们对下雪这个问题的判断,那么在这个问题我们该如何比较中的各个特征的信息量大小呢?没错,就是信息增益。 信息增益衡量的是在得知某一特征A的信息后而使得类Y的不确定性减少的程度,公式如下:

这里,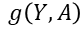 表示特征A对类别Y的信息增益,而随机事件的不确定性可以通过熵来衡量,故
表示特征A对类别Y的信息增益,而随机事件的不确定性可以通过熵来衡量,故 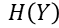 表示类别Y的熵(不确定性),
表示类别Y的熵(不确定性), 表示在得知特征A后类别Y的熵。可见信息增益是基于熵提出的!那么问题来了,熵如何衡量事件不确定性的呢?我们首先从公式说起:
表示在得知特征A后类别Y的熵。可见信息增益是基于熵提出的!那么问题来了,熵如何衡量事件不确定性的呢?我们首先从公式说起:
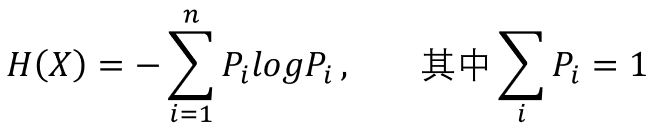
用拉格朗日乘子法,我们可以解得当 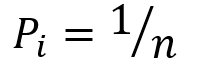 时,熵是最大的(证明过程参见)。对于一次伯努利实验的结果其熵的分布满足:
时,熵是最大的(证明过程参见)。对于一次伯努利实验的结果其熵的分布满足:
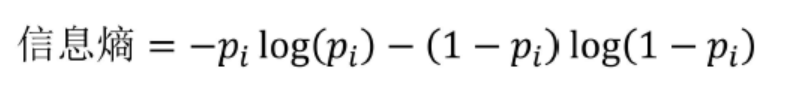
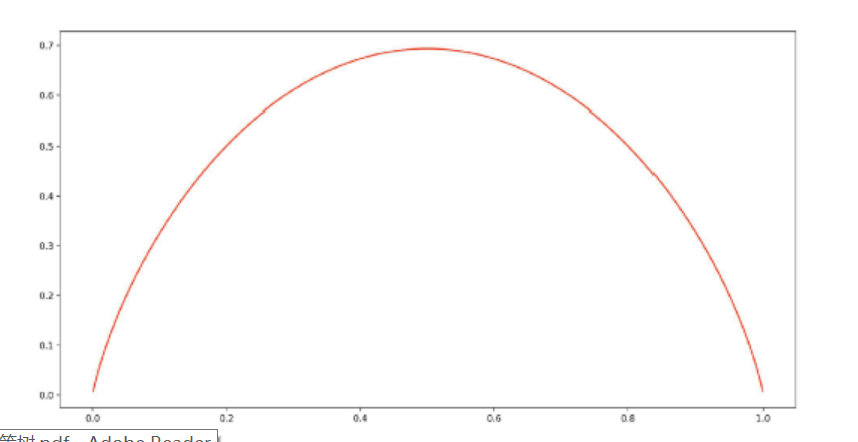
可见,在事件最不确定的时候,其熵值最大,也就是说熵是不确定性的单调递增函数。那么问题又来了,为什么熵的公式是这样的?具体参考可以参见知乎问答。
有时候信息增益并不能很好的度量两个特征哪个特征对分类的贡献大。借用一下李航老师统计学习方法中的贷款申请的例子:
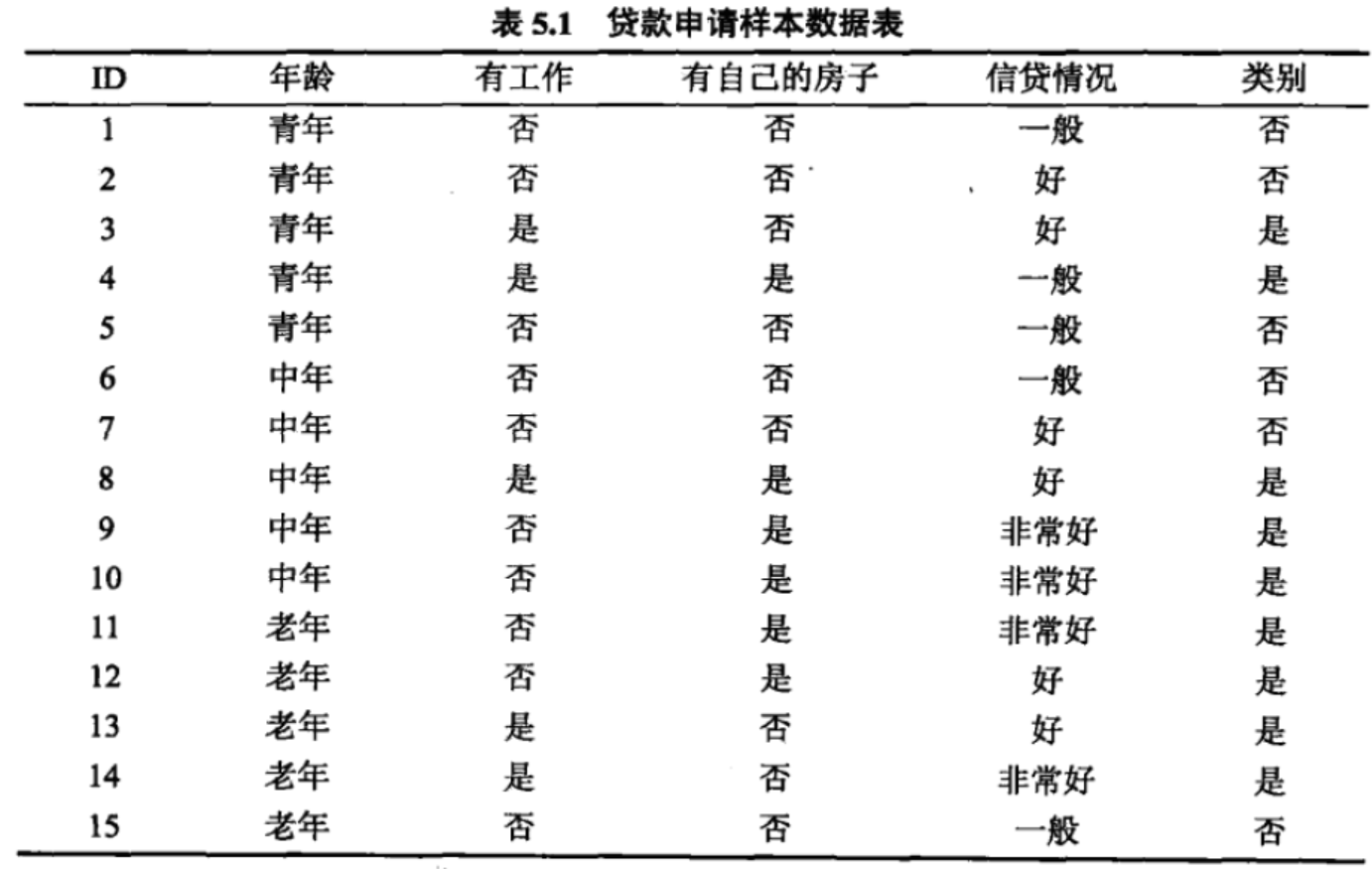
类别有6个“否”、9个“是”,那么数据集D的熵为:
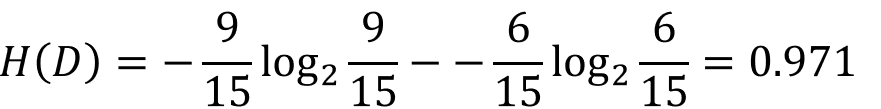
而对于四种特征它们的信息增益分别是:
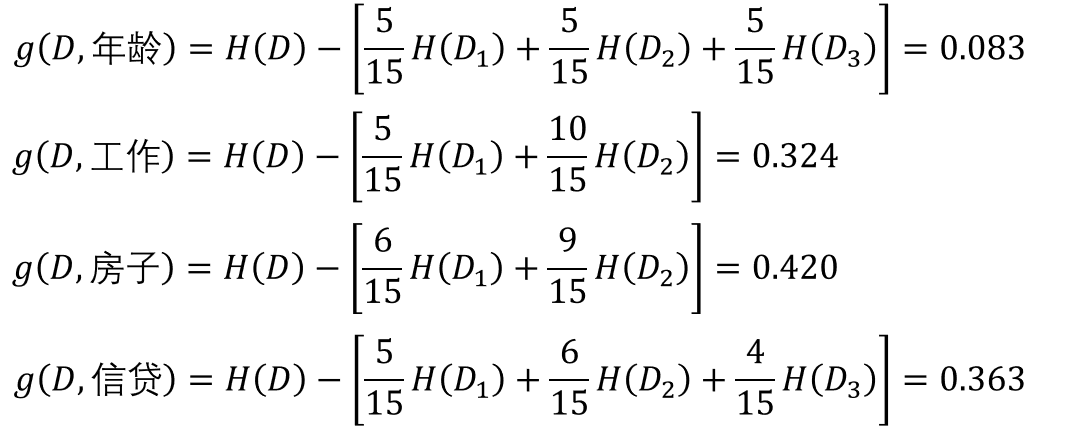
到这里看着似乎没什么问题,那么我们将创造一个问题,把ID也当成一个特征,看看它的信息增益是多少:

到这里我们发现了ID的信息增益最大呀!那ID就是最好的特征么?开玩笑吧!总的来说,信息增益倾向于选择特征取值多的特征,和上面的例子一样,把ID当作最好的特征,是不是很傻。所以为了克服它的这种缺陷,信息增益比就诞生了。信息增益比相当于对每个特征的信息增益加了一个权值,抵消了特征取值数对信息增益的影响,这样就把信息增益归一到同一量级,更加方便比较它们的大小。
特征A对于训练数据集D的信息增益比定义为:
 ,其中n为特征A的取值个数。
,其中n为特征A的取值个数。
1.2 基尼系数
CART分类树中会用到基尼指数作为样本不确定性的度量,同熵代表的含义相同:基尼系数越大,代表了随机变量越不确定,也就是随机变量越随机。分类问题中,假设有K个类,样本属于第k类的概率为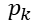 ,那么该概率分布的基尼指数为
,那么该概率分布的基尼指数为

CART构造的是一颗二叉分类树,那么一般我们将一特征集切分成两部分,故得到在特征A给定的条件下,集合D的基尼指数定义为
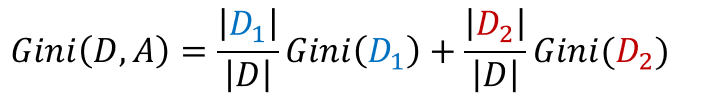
2. Sklearn中的特征选择
特征选择并不只是用于决策树的构建,特征选择也是机器学习中经常用到的一门技术。特征选择技术出现的原因是:我们要知道在一个机器学习任务中,并不是我们获取的所有特征都对模型构建有着积极的影响,即使都有积极的效益,我们可能也要权衡特征项数与建模效率之间的关系。而特征选择可以非常有效的解决这些问题。特征选择技术可以帮助我们筛选出对建模最有用的特征,把可有可无的特征项去除,不仅可以加速我们模型的训练,还可以有效清除噪声特征对模型的影响。下面将简单过一下sklearn中特征选择,然后选一些自己曾经见过的技术,研究一下它的用法:


2.1 基于卡方统计量的特征选择
what is 卡方检验统计量:卡方统计量是用于检验实际分布与理论分布配合程度,也可以说成统计样本的实际观测值与理论推断值之间的偏差程度的统计量。若卡方值越大,说明偏差越大,越不符合实际;而卡方值越小,说明偏差越小,越是符合实际情况;若卡方值为0,说明理论完全符合实际!下面是卡方统计量的公式:

其中,  表示实际观测次数,
表示实际观测次数,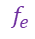 表示理论观测次数。因为卡方检验可以用于检测随机变量之间的依赖关系,因此我们可以用它来清除那些最有可能与类别不想关的特征,来减少噪音特征对分类的影响。
表示理论观测次数。因为卡方检验可以用于检测随机变量之间的依赖关系,因此我们可以用它来清除那些最有可能与类别不想关的特征,来减少噪音特征对分类的影响。
sklearn.feature_selection.chi2(X, y)
"""
参数
---
X: 特征矩阵 (n_samples * n_features_in 维)
y: 标签向量 (n_samples * 1 维) 返回值
---
chi2:每个特征的卡方统计量(n_features * 1 维)
pval :每个特征的p-value (n_features * 1 维) 算法时间复杂度O(n_samples * n_features_in)
"""
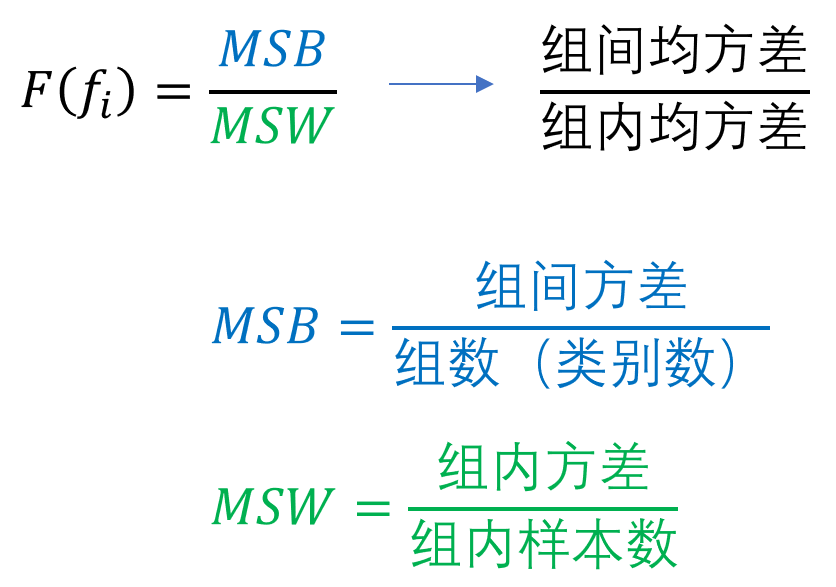
2.2 基于方差分析的特征选择
方差是描述随机变量离散程度的统计量,其公式为:

而分差分析基本思想认为不同特征对分类模型的贡献程度之所以不同,主要源自于各个特征在组内与组间离散程度存在差异,于是F-score就出现了:
sklearn.feature_selection.f_classif(X, y)
"""
参数
---
X: 特征矩阵 (n_samples * n_features_in 维)
y: 标签向量 (n_samples * 1 维) 返回值
---
F:每个特征的卡方统计量(n_features * 1 维)
pval :每个特征的p-value (n_features * 1 维) 算法时间复杂度O(n_samples * n_features_in)
"""
ML - 特征选择的更多相关文章
- ML技术 - 特征选择
1. 决策树中的特征选择 分类决策树是一种描述对实例进行分类的树型结构,决策树学习本质上就是从训练数据集中归纳出一组分类规则,而二叉决策树类似于if-else规则.决策树的构建也是非常的简单,首先依据 ...
- Spark2 ML 学习札记
摘要: 1.pipeline 模式 1.1相关概念 1.2代码示例 2.特征提取,转换以及特征选择 2.1特征提取 2.2特征转换 2.3特征选择 3.模型选择与参数选择 3.1 交叉验证 3.2 训 ...
- 浅谈关于特征选择算法与Relief的实现
一. 背景 1) 问题 在机器学习的实际应用中,特征数量可能较多,其中可能存在不相关的特征,特征之间也可能存在相关性,容易导致如下的后果: 1. 特征个数越多,分析特征.训练模型所需的时间就越 ...
- 推荐系统那点事 —— 基于Spark MLlib的特征选择
在机器学习中,一般都会按照下面几个步骤:特征提取.数据预处理.特征选择.模型训练.检验优化.那么特征的选择就很关键了,一般模型最后效果的好坏往往都是跟特征的选择有关系的,因为模型本身的参数并没有太多优 ...
- ML学习分享系列(2)_计算广告小窥[中]
原作:面包包包包包包 改动:寒小阳 && 龙心尘 时间:2016年2月 出处:http://blog.csdn.net/Breada/article/details/50697030 ...
- 使用spark ml pipeline进行机器学习
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
- 如何应用ML的建议-上
本博资料来自andrew ng的13年的ML视频中10_X._Advice_for_Applying_Machine_Learning. 遇到问题-部分(一) 错误统计-部分(二) 正确的选取数据集- ...
- StanFord ML 笔记 第八部分
第八部分内容: 1.正则化Regularization 2.在线学习(Online Learning) 3.ML 经验 1.正则化Regularization 1.1通俗解释 引用知乎作者:刑无刀 ...
- spark ml 的例子
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
随机推荐
- SqlSever 使用 CROSS APPLY 与 OUTER APPLY 连接查询
前言 日常开发中遇到多表查询时,首先会想到 INNER JOIN 或 LEFT OUTER JOIN 等等,但是这两种查询有时候不能满足需求.比如,左表一条关联右表多条记录时,我需要控制右表的某一条或 ...
- 安装jdk1.8导致eclipse显示问题
安装jdk1.8后新建workspace(mars)后eclipse的toolbar和主题显示有问题 例如: 修改步骤 1.设置主题window->Preferences->General ...
- 开发HR人事考试系统介绍
确定好需要开发的模块以及功能 一套人事考试系统主要模块: 1)组织管理:公司部门成员信息 2)人事管理:人事信息,离职管理,职务管理,岗位管理: 3)考勤管理:班次设置,停工放假,假日设置,刷卡记录, ...
- Unity2018 VS2017打开CS脚本,提示全红及无法加载工程等问题解决
VS2017用的比较老的版本,因为当时下载了离线文件,所以可以离线安装,现在看来是没有必要的,占硬盘空间不说,不更新VS IDE,Unity高版本还有问题. 主要问题在于,我之前一直用Unity201 ...
- [转]BSD系统正在死亡?一些安全研究人员这样认为
摘要:在代码安全上被关注太少,漏洞没有被报告修补,FreeBSD.OpenBSD和NetBSD还能活下来吗? 在德国莱比齐的34c3网站上,IOActive的渗透测试主管Ilja von Sprund ...
- c语言构建哈希表
/*哈希查找 *哈希函数的构造方法常用的有5种.分别是: *数字分析法 *平方取中法 *分段叠加 *伪随机数 *除留取余法 *这里面除留取余法比较常用 *避免哈希冲突常用的方法有4种: *开放定址法( ...
- Z-Stack - Modification of Zigbee Device Object for better network access management
写一份赏心悦目的工程文档,是很困难的事情.若想写得完善,不仅得用对工具(use the right tools),注重文笔,还得投入大把时间,真心是一件难度颇高的事情.但,若是真写好了,也是善莫大焉: ...
- Teradata Delete Database and Drop Database
DELETE DATABASE and DELETE USER statements delete all data tables, views, and macros from a database ...
- MQTT协议学习总结
一.MQTT介绍 MQTT(Message Queuing Telemetry Transport,消息队列遥测传输协议),是一种基于发布/订阅(publish/subscribe)模式的“轻量级”通 ...
- Readme.txt
进入大学,越来越发现自学确实很重要,在学习计算机上,老师上课讲的远远不够,光凭理论是不够的.第一个接触的是VC++6.0这个老版的软件,一节理论课可以过三章内容着实惊吓,现在发现Vscode 可以将代 ...