Hadoop伪分布式模式安装
一.Hadoop介绍
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。Hadoop的框架最核心的设计就是:HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算。
二.安装Hadoop
环境:Docker(17.04.0-ce)、镜像Ubuntu(16.04.3)、Hadoop(3.1.1)、JDK(1.8.0_144)
1.运行dockeer容器,指定IP
faramita2016@linux-l9e6:~> docker run -id --hostname lab-bd --net br0 --ip 10.0.0.3 ubuntu:ssh
2.在容器中执行,安装ssh、vim
root@lab-bd:~# apt-get update
root@lab-bd:~# apt-get install -y ssh vim
3.新建bigdata用户(作为hadoop用户)
root@lab-bd:~# useradd bigdata -m -g root -c /bin/bash
root@lab-bd:~# passwd bigdata
root@lab-bd:~# su - bigdata
4.解压Jdk和Hadoop
bigdata@lab-bd:~$ tar -xf jdk-8u144-linux-x64.tar.gz
bigdata@lab-bd:~$ tar -xf hadoop-3.1..tar.gz
5.编辑.bashrc文件,配置Java环境
export JAVA_HOME=/home/bigdata/jdk1..0_144
export PATH=$JAVA_HOME/bin:$PATH
6.激活Java环境变量
bigdata@lab-bd:~$ source .bashrc
7.编辑etc/hadoop/hadoop-env.sh文件,配置Java环境
export JAVA_HOME=/home/bigdata/jdk1..0_144
8.配置ssh免密登录
bigdata@lab-bd:~$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
bigdata@lab-bd:~$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
bigdata@lab-bd:~$ ssh localhost
9.编辑etc/hadoop/core-site.xml文件,添加如下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
10.编辑etc/hadoop/hdfs-site.xml文件,添加如下配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
11.格式化文件系统
bigdata@lab-bd:~$ hadoop-3.1./bin/hdfs namenode -format
12.启动hdfs服务
bigdata@lab-bd:~$ hadoop-3.1./sbin/start-dfs.sh
13.浏览器访问http://10.0.0.3:9870
三.配置Yarn
1.创建bigdata用户默认文件夹
bigdata@lab-bd:~$ hadoop-3.1./bin/hdfs dfs -mkdir -p /user/bigdata
2.编辑etc/hadoop/mapred-site.xml文件,添加如下配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
3.编辑etc/hadoop/yarn-site.xml文件,添加如下配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
4.启动Yarn服务
bigdata@lab-bd:~$ hadoop-3.1./sbin/start-yarn.sh
5.浏览器访问http://10.0.0.3:8088

四.运行任务
1.创建hadoop任务输入文件夹
bigdata@lab-bd:~$ hadoop-3.1./bin/hdfs dfs -mkdir /user/bigdata/input
2.添加xml文件做为输入文本
bigdata@lab-bd:~$ hadoop-3.1./bin/hdfs dfs -put hadoop-3.1./etc/hadoop/*.xml /user/bigdata/input
3.执行单词统计示例任务,input输入文件夹,output输出文件夹(自动创建)
bigdata@lab-bd:~$ hadoop-3.1./bin/hadoop jar hadoop-3.1./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1..jar grep input output 'had[a-z.]+'
4.查看单词统计输出结果
bigdata@lab-bd:~$ hadoop-3.1./bin/hdfs dfs -cat /user/bigdata/output/part-r- 
五.HDFS命令
1) ls 显示目录下的所有文件或者文件夹
示例: hdfs dfs –ls /
显示目录下的所有文件可以加 -R 选项
示例: hdfs dfs -ls -R /
2) cat 查看文件内容
示例: hdfs dfs -cat /user/bigdata/test.txt
3) mkdir 创建目录
示例: hdfs dfs –mkdir /user/bigdata/a
创建多级目录 加上 –p
示例: hdfs dfs –mkdir -p /user/bigdata/a/b/c
4) rm 删除目录或者文件
示例: hdfs dfs -rm /user/bigdata/test.txt
删除文件夹加上 -r
示例: hdfs dfs -rm -r /user/bigdata/a/b/c
5) put 将文件复制到hdfs系统中,
示例:hdfs dfs -put /tmp/test.txt /user/bigdata
6) cp 复制系统内文件
示例:hdfs dfs -cp /user/bigdata/test.txt /user/bigdata/a/
7) get 复制文件到本地系统
示例:hdfs dfs -get /user/bigdata/test.txt /tmp
8) mv 将文件从源路径移动到目标路径。
示例:hdfs dfs -mv /user/bigdata/a/test.txt /user/bigdata/b/test.txt
9) du 显示目录中所有文件的大小
示例: hdfs dfs -du /
显示当前目录或者文件夹的大小可加选项 -s
示例: hdfs dfs -du -s /user/bigdata
六.运行异常
running …… beyond the 'VIRTUAL' memory limit异常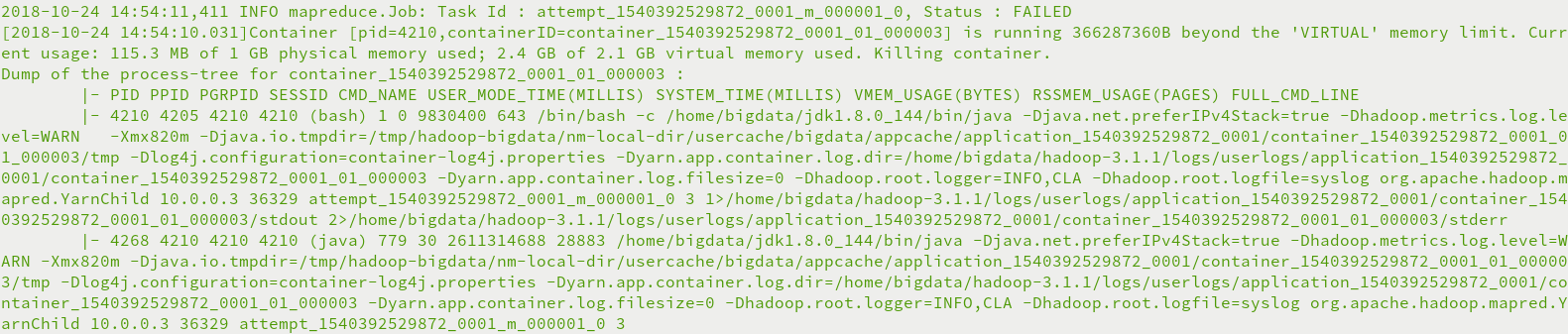
虚拟内存分配不够,Yarn直接杀死进程,需要禁止内存检查
编辑etc/hadoop/yarn-site.xml文件,添加如下配置
<configuration>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
Hadoop伪分布式模式安装的更多相关文章
- 初学者值得拥有【Hadoop伪分布式模式安装部署】
目录 1.了解单机模式与伪分布模式有何区别 2.安装好单机模式的Hadoop 3.修改Hadoop配置文件---五个核心配置文件 (1)hadoop-env.sh 1.到hadoop目录中 2.修 ...
- VMware workstation 下Hadoop伪分布式模式安装
详细过程: 1.VMware安装: 2.centos 6 安装 3.jdk下载安装配置 4.Hadoop 安装配置 1.VMware Workstation 安装: https://www.vmwar ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- HBase入门基础教程之单机模式与伪分布式模式安装(转)
原文链接:HBase入门基础教程 在本篇文章中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建HBase伪分布式环境的前提是我们已经搭建好了Had ...
- Hadoop伪分布式模式搭建
title: Hadoop伪分布式模式搭建 Quitters never win and winners never quit. 运行环境: Ubuntu18.10-server版镜像:ubuntu- ...
- Hadoop完全分布式模式安装部署
在Linux上搭建Hadoop系列:1.Hadoop环境搭建流程图2.搭建Hadoop单机模式3.搭建Hadoop伪分布式模式4.搭建Hadoop完全分布式模式 注:此教程皆是以范例讲述的,当然你可以 ...
- Hadoop Single Node Setup(hadoop本地模式和伪分布式模式安装-官方文档翻译 2.7.3)
Purpose(目标) This document describes how to set up and configure a single-node Hadoop installation so ...
- HBase入门基础教程 HBase之单机模式与伪分布式模式安装
在本篇文章中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建HBase伪分布式环境的前提是我们已经搭建好了Hadoop完全分布式环境,搭建Hado ...
- 【HBase基础教程】1、HBase之单机模式与伪分布式模式安装(转)
在这篇blog中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建hbase伪分布式环境的前提是我们已经搭建好了hadoop完全分布式环境,搭建ha ...
随机推荐
- .NET 单元测试的利剑——模拟框架Moq(简述篇)
.NET 单元测试的利剑--模拟框架Moq 前言 这篇文章是翻译文,因为通过自己参与的项目,越发觉得单元测试的重要性,特别是当跟业务数据打交道的时候的,Moq就如雪中送炭,所以想学习这个框架,就从这篇 ...
- [android] 在不同的activity之间传递数据
新建一个activity,继承Activity 清单文件中进行配置,添加<activity/>节点 设置名称 android:name=”.类名” 点 代表的是当前包名,也可以不写 新建一 ...
- 29.C++- 异常处理
C++内置了异常处理的语法元素 try catch try语句处理正常代码逻辑 当try语句发现异常时,则通过throw语句抛出异常,并退出try语句 catch语句处理异常情况 当throw语句抛出 ...
- Runnable和Callable接口辨析
突然发现和启动一个线程有关的有三函数,run(), call(), start(),有点小乱,所以特别梳理一下 首先说一下start(),这个是最好说的,感觉start()和run()这俩名字是真的有 ...
- a dive in react lifecycle
背景:我在react文档里找生命周期的图,居然没有,不敢相信我是在推特上找到的... 正文 react v16.3 新生命周期: static getDerivedStateFromProps get ...
- 课程作业——Python基础之使用turtle库画出红旗
代码如下: import turtle # 设置画笔和背景颜色 turtle.color('yellow') turtle.bgcolor('red') # 通过偏移量和尺寸大小画星星 def dra ...
- #WEB安全基础:HTML/CSS | 0x0 我的第一个网页
#WEB安全基础:HTML/CSS系列,本系列采用第二人称以免你不知道我在对着你说话,以朋友的视角和你交流 HTML的中文名叫做超文本标记语言,CSS叫做层叠样式表 用HTML设计你的第一个网页,你需 ...
- loj#2483. 「CEOI2017」Building Bridges(dp cdq 凸包)
题意 题目链接 Sol \[f[i], f[j] + (h[i] - h[j])^2 + (w[i - 1] - w[j]))\] 然后直接套路斜率优化,发现\(k, x\)都不单调 写个cdq就过了 ...
- AI在汽车中的应用:实用深度学习
https://mp.weixin.qq.com/s/NIza8E5clC18eMF_4GMwDw 深度学习的“深度”层面源于输入层和输出层之间实现的隐含层数目,隐含层利用数学方法处理(筛选/卷积)各 ...
- JDCP连接池连接数据库报错:java.lang.AbstractMethodError: com.mysql.jdbc.Connection.isValid(I)Z
完整报错是这样的: 小编的情况: 使用mysql的jar包版本: 使用的jdcp的相关jar包版本: 报错的原因: mysql的jar包版本过低. 更新到最新版mysql的jar包即可. 小编更新后的 ...