论文阅读笔记十九:PIXEL DECONVOLUTIONAL NETWORKS(CVPR2017)

论文源址:https://arxiv.org/abs/1705.06820
tensorflow(github): https://github.com/HongyangGao/PixelDCN
基于PixelDCL分割实验:https://github.com/fourmi1995/IronsegExperiment-PixelDCL
摘要
反卷积被广泛用于深度学习的上采样过程中,包括语义分割的编码-解码网络与无监督学习的深度生成网络。反卷积的一个缺点是生成的特征图类似于棋盘状,相邻元素之间的关系无法较好的确定。为解决此问题,该文提出PixelDCL层,用于建立上采样输出的feature map中相邻像素之间的联系。该文对常规的反卷积进行重新解释。该网络可以应用于其他网络中,同时,并不会增加网络学习的参数量,其分割性能在准确率上会有所损失,但可以通过一些调参技巧进行克服。实验发现PixelDCL层相比常规的反卷积层,可以获得更多的形状及边等空间信息,进而得到更好的分割效果。
说明
通过反卷积实现上采样得到的feature map可以看作是通过独立的卷积核对多个隐藏层的feature map阶段性混合运算的结果。因此,feature map中相邻像素之间没有直接联系,从而产生“棋盘”问题。针对此问题,该文提出Pixel DCL层神经网络层,在这一层网络中的feature map是连续生成的,因此,后面生成的feature map依赖于先前生成的feature map,通过这种方式,建立起相邻像素之间直接联系.PixelDCL与基于概率密度评估的自恢复方法(PixelRNNs,PixelCNNs)相比,训练速度要快很多。虽然在PixelDCL中会有部分计算性能上的降低,但可以通过调参等技巧进行改善。

方法
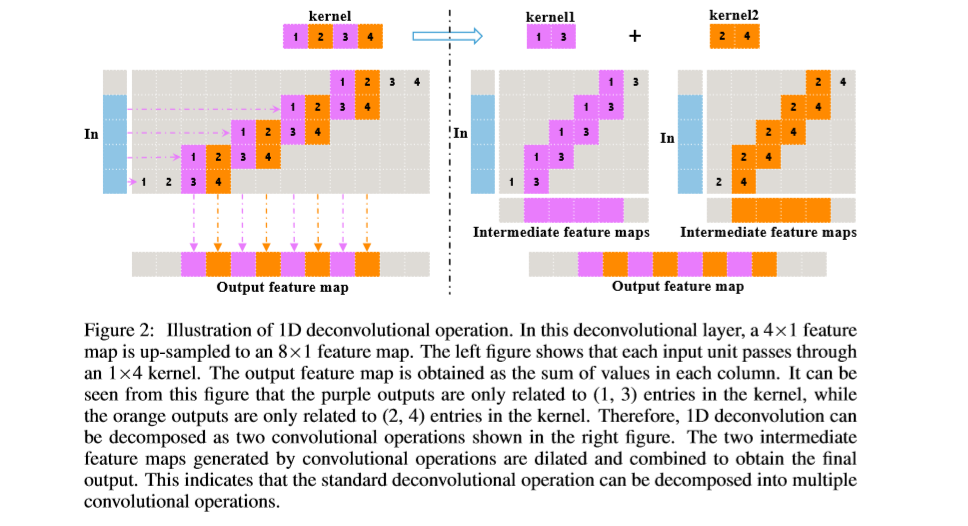
反卷积:1D,2D卷积图如下,标准的反卷积操作可以分解为几个依赖于上采样因子的卷积操作。本文默认上采样因子为2。

通过如下操作可以计算得到上采样的输出,
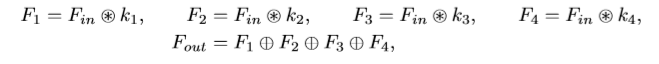
 代表卷积操作,
代表卷积操作,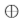 代表阶段性的混搭操作,在常规的反卷积中,由于中间的feature map是由独立的卷积核得到的,因此中间过程的feature map像素中没有直接关联的信息。由于,相邻两个像素可能来自不同的卷积核的结果,因此,像素值会有所不同,进而会产生“棋盘”现象。如下图,通过后处理的方法进行平滑操作会造成额外的计算资源的消耗,增加网络的复杂度,同时无法进行end-to-end的训练。该文通过添加PixelDCL层给中间隐层feature map添加依赖信息。
代表阶段性的混搭操作,在常规的反卷积中,由于中间的feature map是由独立的卷积核得到的,因此中间过程的feature map像素中没有直接关联的信息。由于,相邻两个像素可能来自不同的卷积核的结果,因此,像素值会有所不同,进而会产生“棋盘”现象。如下图,通过后处理的方法进行平滑操作会造成额外的计算资源的消耗,增加网络的复杂度,同时无法进行end-to-end的训练。该文通过添加PixelDCL层给中间隐层feature map添加依赖信息。
 像素级反卷积层:
像素级反卷积层:
由于常规反卷积操作得到的feature map中相邻像素来自不同卷积核得到的feature map,之间并无关联,该文提出PixelDCL,用于建立不同中间隐层特征的关联。中间隐层特征图是按序列生成,而不是同时生成。后一个feature map的生成依赖与上一个feature map的生成。PixelDCL的操作过程如下
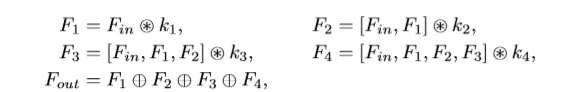
后期生成的feature map可以依赖于前面部分或者全部的feature maps。
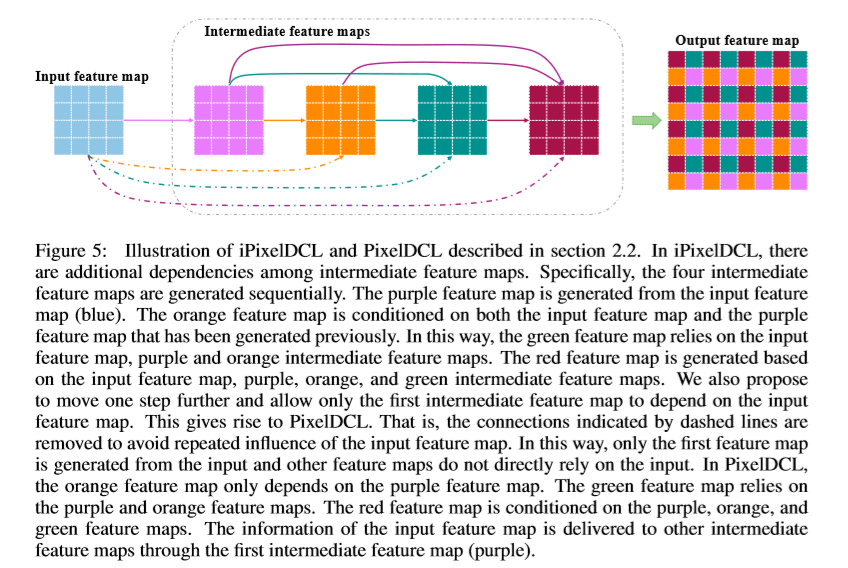
由于输入的feature map被重复利用,降低了计算的性能。因此,进行改进,使输入的feature map只与第一个feature map相关。操作过程如下:

像素级反卷积网络:

实验
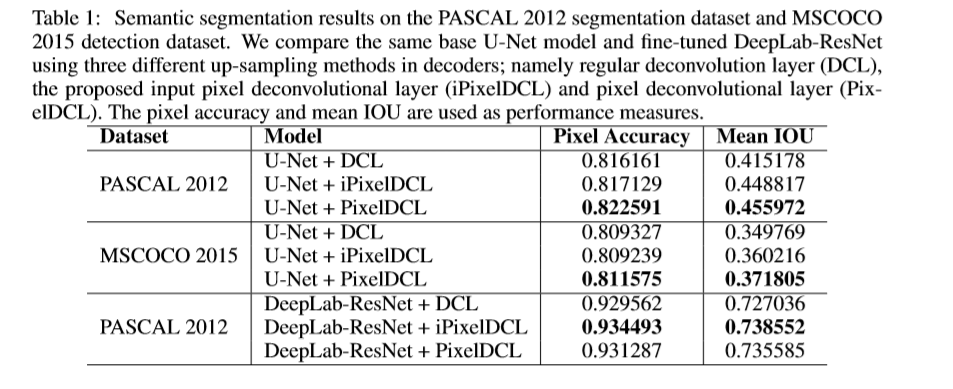
图像分割


图像生成

时间比较

Reference
[1] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv:1606.00915, 2016.
[2] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2): 303–338, 2010.
[3] Mathieu Germain, Karol Gregor, Iain Murray, and Hugo Larochelle. Made: Masked autoencoder for distribution estimation. In Proceedings of The 32nd International Conference on Machine Learning, pp. 881–889, 2015.
论文阅读笔记十九:PIXEL DECONVOLUTIONAL NETWORKS(CVPR2017)的更多相关文章
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)
论文源址:https://arxiv.org/abs/1606.02147 tensorflow github: https://github.com/kwotsin/TensorFlow-ENet ...
- 论文阅读笔记十六:DeconvNet:Learning Deconvolution Network for Semantic Segmentation(ICCV2015)
论文源址:https://arxiv.org/abs/1505.04366 tensorflow代码:https://github.com/fabianbormann/Tensorflow-Decon ...
- 论文阅读笔记十五:Pyramid Scene Parsing Network(CVPR2016)
论文源址:https://arxiv.org/pdf/1612.01105.pdf tensorflow代码:https://github.com/hellochick/PSPNet-tensorfl ...
- 论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)
论文链接:https://arxiv.org/abs/1506.04924 摘要 该文提出了基于混合标签的半监督分割网络.与当前基于区域分类的单任务的分割方法不同,Decoupled 网络将分割与分类 ...
- 论文阅读笔记十:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (DeepLabv2)(CVPR2016)
论文链接:https://arxiv.org/pdf/1606.00915.pdf 摘要 该文主要对基于深度学习的分割任务做了三个贡献,(1)使用空洞卷积来进行上采样来进行密集的预测任务.空洞卷积可以 ...
- 论文阅读笔记六十一:Selective Kernel Networks(SKNet CVPR2019)
论文原址:https://arxiv.org/pdf/1903.06586.pdf github: https://github.com/implus/SKNet 摘要 在标准的卷积网络中,每层网络中 ...
- 论文阅读笔记(九)【TIFS2020】:True-Color and Grayscale Video Person Re-Identification
Introduction (1)Motivation:在现实场景中,摄像头会因为故障呈现灰白色,或者为了节省视频的存储空间而人工设置为灰白色.灰度图像(grayscale images)由8位存储,而 ...
- 论文阅读笔记十二:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(CVPR2018)
论文链接:https://arxiv.org/abs/1802.02611 tensorflow 官方实现: https: //github.com/tensorflow/models/tree/ma ...
随机推荐
- java基础梳理--朝花夕拾(一)
简介: Java是一种撰写跨平台应用软件的面向对象语言,1995年由Sun Microsystems公司推出. 2009年04月20日,甲骨文74亿美元收购Sun,取得java的版权. 2011年7月 ...
- Javascript - ExtJs - GridPanel组件 - 编辑
GridPanel组件 - 编辑 Ext.grid.plugin.Editing 如果要对表格使用列编辑器控件,则需要完成以下几步 1.将columns中需要编辑的列设为editor并提供编辑列时所要 ...
- MFC调用libyara遇到的问题
测试结果 如果调用yara非要变成共享DLL的形式,加那么多的DLL,不如直接调用EXE文件.反而依赖vcruntime运行库的DLL会少很多... 调用libyara 调用libraya和C++调用 ...
- 工作流程引挈 https://www.flowable.org/
工作流程引挈 : https://www.flowable.org/ 起源:JBPM,Activiti
- pt-table-checksum 使用方法【转】
27. pt-table-checksum27.1 pt-table-checksum 作用 主要用来检查主从数据是否一致,原理即在主库执行把表每行的列通过concat函数进行拼接,然后对拼接的值进行 ...
- python3+selenium框架设计04-封装测试基类
在完成了日志类封装之后,那我们就要对测试基类进行实现,在其中对一些请求再次封装,在项目下新建一个framework文件夹,在文件夹下新建Base_Page.py文件,这是用来写测试基类的文件.在项目下 ...
- 题解-AtCoder-agc003F Fraction of Fractal(非矩阵快速幂解法)
Problem AtCoder-agc003F 题意:给出\(n\)行\(m\)列的01矩阵,一开始所有 \(1\) 连通,称此为\(1\)级分形,定义\(i\)级分形为\(i-1\)级分形中每个标示 ...
- 【HAOI2008】硬币购物
既然没人写扩欧,那我就来一发吧. 扩欧也还好,就是跑的有点慢,然后写的时候还有点烦,不过还是卡过去了. 考场上看到这道题又蒙了...怎么回事第一题又要爆零了? 然后我打了个暴力测了一下极限数据根本过不 ...
- 洛谷 [USACO17OPEN]Bovine Genomics G奶牛基因组(金) ———— 1道骗人的二分+trie树(其实是差分算法)
题目 :Bovine Genomics G奶牛基因组 传送门: 洛谷P3667 题目描述 Farmer John owns NN cows with spots and NN cows without ...
- 3-html 缩写-地址-文字方向-引用块-题注的格式
HTML Quotation and Citation Elements Tag Description <abbr> Defines an abbreviation or acronym ...