CCF-CSP 第三题字符串整理(模拟大法好)
URL映射
- 规则的相邻两项之间用‘/’分开,所以我们先把所有项分开,然后依次把两个字符串的对应项匹配即可。
- 分离字符串这里用字符串流(stringstream)处理,先把所有的‘/’变为空格,然后一个一个把各项分开。
- 在把‘/’变为空格的时候,要注意行末的‘/’,比如:
/okokokok 与 /okokokok/是无法匹配成功的。同样的:/<str>/ 与/okokok也无法匹配成功。 - 模拟,注意细节和边界即可。
#include<iostream>
#include<sstream>
#include<cstring>
#include<string>
#include<cstdio>
#include<vector>
#include<algorithm>
#define LL unsigned long long
using namespace std;
const int maxn=;
int cnt1[maxn],isp,sp[maxn]; //cnt1[i]--第i个字符串的项数,isp--待查询的字符串末尾是否为‘/’,sp[i]--第i个字符串末尾是否为‘/’
string str[maxn],str1[maxn],str2; //str[i]--第i个字符串的配置信息,str1[i]--第i个映射规则,str2--当前需要被查询的字符串
string sp1[maxn][maxn],sp2[maxn]; //sp1[i]--保存第i个字符串的所有项,sp2--保存当前被查询字符串的所有项。
string is_num(string s){ //判断某一项是否为整数:是--去掉前导0并返回整数;不是--返回“-”
int ok=;
string ss="";
int len=s.length();
for(int i=;i<len;i++){
if(s[i]<''||s[i]>'')return "-";
if(ok||s[i]!='')ss+=s[i],ok=;
}
if(ss=="")ss="";
return ss;
}
void getinfo(string s,string s1[],int &f,int &t){ //分离并保存一个字符串的所有项,标记末尾是否为‘/’
f=t=;
int len=s.length();
if(s[len-]=='/')f=;
for(int p=;p<len;p++){
if(s[p]=='/')s[p]=' ';
}
string ss;
stringstream in(s);
while(in>>ss)s1[t++]=ss;
}
bool match(int t,int j,string &s){ //判断被查询字符串与第j个规则是否能匹配
s="";
int p1=,p2=;
while(p1<t&&p2<cnt1[j]){
if(sp2[p1]==sp1[j][p2]);
else if(sp1[j][p2]=="<int>"){
string f=is_num(sp2[p1]);
if(f=="-"){return ;}
s+=" "+f;
}
else if(sp1[j][p2]=="<str>"){s+=" "+sp2[p1];}
else if(sp1[j][p2]=="<path>"){ //<path>直接全部加上
s+=" "+sp2[p1++];
while(p1<t)s+="/"+sp2[p1++];
if(isp)s+='/';
return ;
}
else return ;
p1++;p2++;
}
if(isp^sp[j])return ; //末尾判断--同时有‘/’或同时无‘/’才能匹配
if(p1!=t||p2!=cnt1[j])return ; //完全匹配
return ;
}
int main(){
freopen("in.txt","r",stdin);
int n,m;
cin>>n>>m;
for(int i=;i<n;i++){
cin>>str1[i]>>str[i];
getinfo(str1[i],sp1[i],sp[i],cnt1[i]); //string, split, 末尾是否'/', 字符串数量
}
for(int i=;i<m;i++){
string ans;
int cnt=;isp=;
cin>>str2;
getinfo(str2,sp2,isp,cnt);
bool ok=;
for(int j=;j<n;j++){
if(match(cnt,j,ans)){
cout<<str[j]<<ans<<endl;;
ok=;break;
}
}
if(!ok)cout<<<<endl;
}
return ;
}
路径解析
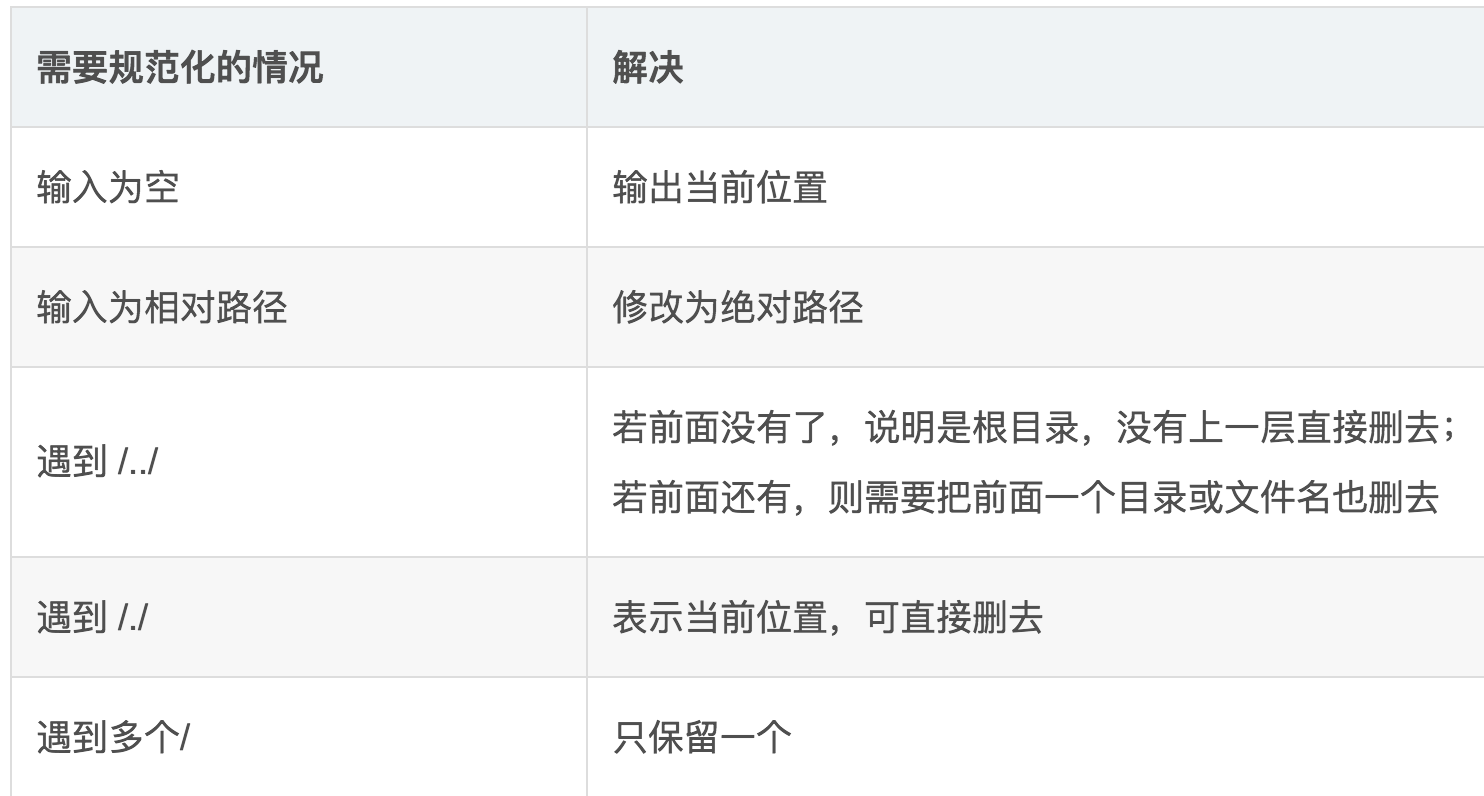
以及末尾有/
#include<iostream>
#include <string>
#include <vector>
using namespace std;
int main()
{
int num,pos,pos1;
string curDir,line;
cin >> num >> curDir;
getchar(); // 使用getline要注意处理回车符
while (num--)
{
getline(cin, line); // 读空字符串 if (line.empty())line = curDir; //
else if (line[] != '/')line = curDir + "/" + line; // 1.首位不为'/'的情况,将相对路径转化为绝对路径 while ((pos = line.find("//")) != -) line.erase(pos, );// 2.出现/// while ((pos = line.find("/../")) != -) // 3.出现/../
{
if (!pos)line.erase(, );
else{
pos1 = line.rfind("/", pos - );
line.erase(pos1, pos - pos1 + );
}
}
while ((pos = line.find("/./")) != -)line.erase(pos, );// 4.出现/./ if (line.size()> && line[line.size() - ] == '/')line.erase(line.size() - , );// 5.末尾有/ cout << line << endl;
}
return ;
}、
——如果用cin>>line的方式输入string类型的line,会导致不能判断为空的输入,所以采用getline。在while循环之前还需要添加getchar(),吸收换行。否则90分;
——c++中单双引号的区别:
""是字符串,C风格字符串后面有一个'\0';''是一个字符,一共就一字节。
单引号表示是字符变量值,字母的本质也是数字。双引号表示字符串变量值,给字符串赋值时系统会自动给字符串变量后面加上一个\0来表示字符串结尾。
string::rfind(string, pos) 是从头开始找,到pos为止,最后一次出现string的位置。
权限查询
map的灵活运行,给出集合A和集合B,集合B和集合C的关系,计算集合C和集合A的关系,因为会出现重叠的元素,所以要遍历所有的A集合中的元素,取最大。
用到知识点:
map<string, map<string, int>>
map::count() 返回0,1
map<string, int>::iterator it--it->first, it->second
string::substr(start, len)--s.substr(0,3)
string::find(string)返回找到的pos,-1
#include <iostream>
#include <vector>
#include <string>
#include <map>
using namespace std; map<string,int> cate;
map<string,map<string, int> > rol;
map<string,map<string,int> > usr; void find(string u, string role, int level){
if(usr.count(u)>&&usr[u].count(role)>)
{
int lev = usr[u][role];
if(level==-)
{
if(lev>-)cout<<lev<<endl;
else cout<<"true"<<endl;
}
else
{
if(lev<level)cout<< "false"<<endl;
else cout<<"true"<<endl;
}
}
else cout<<"false"<<endl;
} int to_int(string s,int pos)
{
int ans=;
for(int i=pos;i<s.size();i++)
{
ans = ans* + s[i]-'';
}
return ans;
} int main()
{
int p,r,u,q;
cin>>p;
string s;
int level;
size_t pos;
for(int i=;i<p;i++) {
cin >> s;
if ((pos = s.find(":")) != -)
{
level = to_int(s,pos+);
s = s.substr(,pos);
cate[s]=max(cate[s],level);
}
else cate[s]=-;
} cin>>r;
int cnt;
string role;
for(int i=;i<r;i++)
{
cin>>role>>cnt;
for(int j=;j<cnt;j++)
{
cin>>s;
if ((pos = s.find(":")) != -)
{
level = to_int(s,pos+);
s = s.substr(,pos);
rol[role][s]=max(rol[role][s],level);
}
else rol[role][s]=-;
}
}
cin>>u;
for(int i =;i<u;i++) // 直接和cate通过role关联
{
string name;
cin>>name>>cnt;
for(int j=;j<cnt;j++)
{
cin>>s;
map<string,int>::iterator it = rol[s].begin();
while(it!=rol[s].end())
{
if(usr[name].count(it->first)>)// 这里必须要区分是否存在,否则默认的0会覆盖-1
{
usr[name][it->first]=max(usr[name][it->first],it->second);
}
else
usr[name][it->first] = it->second;
it++;
}
}
}
cin>>q;
while(q--)
{
string x;
cin>>s>>x;
size_t pos=x.find(":");
if(pos==string::npos) find(s,x,-);
else find(s,x.substr(,pos),x[pos+]-'');//string_to_int的另一种写法
}
return ;
}
JSON查询
解法转自meelo
json是一个递归数据结构,因此可以使用函数的递归调用来进行解析。
每一类数据对应一个解析函数,代码中parseString实现解析字符串的功能,parseObject实现解析对象的功能。
解析函数的主体功能就是依次遍历每一个字符,根据字符判断是否是字符串的开始、对象的开始……并进行相应的处理。
json是一个键值对的结构,因此可以用map存储。map的键可以用查询的格式,用小数点.来分隔多层的键。
#include <iostream>
#include <cassert>
#include <map>
using namespace std; string parseString(string &str, int &i) {
string tmp;
if(str[i] == '"') i++;
else assert(); while(i < str.size()) {
if(str[i] == '\\') {
i++;
tmp += str[i];
i++;
}
else if(str[i] == '"') {
break;
}
else {
tmp += str[i];
i++;
}
} if(str[i] == '"') i++;
else assert(); return tmp;
} void parseObject(string &str, string prefix, map<string, string> &dict, int &i) {
if(str[i] == '{') i++;
else assert(); string key, value;
bool strType = false; // 标志 false:key, true:value
while(i < str.size()) {
if(str[i] == '"') {
string tmp = parseString(str, i);
if(strType) { // value
value = tmp;
dict[key] = value;
}
else { // key
key = prefix + (prefix==""?"":".") + tmp;
}
}
else if(str[i] == ':') {
strType = true;
i++;
}
else if(str[i] == ',') {
strType = false;
i++;
}
else if(str[i] == '{') {
dict[key] = "";
parseObject(str, key, dict, i);
}
else if(str[i] == '}') {
i++;
break;
}
else {
i++;
}
}
} int main() {
int N, M;
cin >> N >> M;
string json;
if(cin.peek()=='\n') cin.ignore();
for(int n=; n<N; n++) { // 输入用getline(保留空格,空)连成一个string
string tmp;
getline(cin, tmp);
json += tmp;
}
map<string, string> dict; // 存储所有候选键值对
int i = ;
parseObject(json, "", dict, i); // json是一个递归结构,递归解析
string query;
for(int m=; m<M; m++) {
getline(cin, query);
if(dict.find(query) == dict.end()) {
cout << "NOTEXIST\n";
}
else {
if(dict[query] == "") {
cout << "OBJECT\n";
}
else {
cout << "STRING " << dict[query] << "\n";
}
}
}
return ;
}
MarkDown
解法转自:meelo 逻辑异常清晰,这老哥写的代码会说话2333
#include <iostream>
#include <vector>
#include <string>
#include <cassert> using namespace std; string to_string(int i) {
char buffer[];
return string(itoa(i, buffer, ));
} string parseEmphasize(string text) {
string result;
result += "<em>";
result += text;
result += "</em>";
return result;
} string parseLink(string text, string link) {
string result;
result += "<a href=\"";
result += link;
result += "\">";
result += text;
result += "</a>";
return result;
} string parseLine(string line) { // 行内解析,包含递归调用
string result;
int i = ;
while(i<line.size()) {
if(line[i]=='[') {
string text, link;
int j = i+;
while(line[j] != ']') j++;
text = line.substr(i+, j-i-);
i = j+;
assert(line[i]=='(');
while(line[j]!=')') j++;
link = line.substr(i+, j-i-); text = parseLine(text);
link = parseLine(link);
result += parseLink(text, link);
i = j+;
}
else if(line[i]=='_') {
string text;
int j = i+;
while(line[j]!='_') j++;
text = line.substr(i+, j-i-); text = parseLine(text);
result += parseEmphasize(text);
i = j + ;
}
else {
result += line[i];
i++;
}
}
return result;
} string parseHeading(vector<string> &contents) {
assert(contents.size()==);
int level = ;
int i = ;
string heading = parseLine(contents[]); while(heading[i] == '#') i++;
level = i;
while(heading[i] == ' ') i++; string result;
result += "<h";
result += to_string(level);
result += '>';
result += heading.substr(i,-);
result += "</h";
result += to_string(level);
result += ">\n";
return result;
} string parseParagraph(vector<string> &contents) {
string result;
result += "<p>";
for(int i=; i<contents.size(); i++) {
result += parseLine(contents[i]);
if(contents.size() != && i != contents.size()-) result += '\n';
}
result += "</p>\n";
return result;
} string parseUnorderedList(vector<string> &contents) {
string result;
result += "<ul>\n";
int j;
for(int i=; i<contents.size(); i++) {
result += "<li>";
j = ;
while(contents[i][j] == ' ') j++;
result += parseLine(contents[i].substr(j,-));
result += "</li>\n";
}
result += "</ul>\n";
return result;
} int main() {
string line;
vector<string> contents;
int blockType; // 0:empty, 1:paragraph, 2:heading, 3:unordered list
string result;
while(getline(cin, line) || contents.size()>) { // getline空行的时候注意
if(line.empty()) { // 结束的标志
if(blockType != ) {
switch(blockType) {
case : result += parseParagraph(contents); break;
case : result += parseHeading(contents); break;
case : result += parseUnorderedList(contents); break;
}
contents.resize();
blockType = ;
}
}
else if(line[] == '#') {
contents.push_back(line);
blockType = ;
}
else if(line[] == '*') {
contents.push_back(line);
blockType = ;
}
else {
contents.push_back(line);
blockType = ;
}
line = "";
}
cout << result;
}
CCF-CSP 第三题字符串整理(模拟大法好)的更多相关文章
- ytu 1064: 输入三个字符串,按由小到大的顺序输出(水题,字符串处理)
1064: 输入三个字符串,按由小到大的顺序输出 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 471 Solved: 188[Submit][Sta ...
- 2016/1/12 第一题 输出 i 出现次数 第二题 用for循环和if条件句去除字符串中空格 第三题不用endwith 实现尾端字符查询
import java.util.Scanner; public class Number { private static Object i; /* *第一题 mingrikejijavabu中字符 ...
- CCF CSP/CCSP报名费优惠的方法以及常见疑问
目录 1. 本文地址 2. 认证作用 2.1. 高校认可 2.2. 赛事认可 2.3. 企业认可 3. 报名费价格及获取优惠的方法 3.1. CCF CSP 3.2. CCF CCSP 4. 语言与I ...
- NOIP2008提高组(前三题) -SilverN
此处为前三题,第四题将单独发布 火柴棒等式 题目描述 给你n根火柴棍,你可以拼出多少个形如“A+B=C”的等式?等式中的A.B.C是用火柴棍拼出的整数(若该数非零,则最高位不能是0).用火柴棍拼数字0 ...
- CCF CSP 201703
CCF CSP 2017·03 做了一段时间的CCF CSP试题,个人感觉是这样分布的 A.B题基本纯暴力可满分 B题留心数据范围 C题是个大模拟,留心即可 D题更倾向于图论?(个人做到的D题基本都是 ...
- CCF CSP 201609-3 炉石传说
CCF计算机职业资格认证考试题解系列文章为meelo原创,请务必以链接形式注明本文地址 CCF CSP 201609-3 炉石传说 问题描述 <炉石传说:魔兽英雄传>(Hearthston ...
- CCF CSP 201403-3 命令行选项
CCF计算机职业资格认证考试题解系列文章为meelo原创,请务必以链接形式注明本文地址 CCF CSP 201403-3 命令行选项 问题描述 请你写一个命令行分析程序,用以分析给定的命令行里包含哪些 ...
- CCF CSP 201609-4 交通规划
CCF计算机职业资格认证考试题解系列文章为meelo原创,请务必以链接形式注明本文地址 CCF CSP 201609-4 交通规划 问题描述 G国国王来中国参观后,被中国的高速铁路深深的震撼,决定为自 ...
- CCF CSP 201703-2 学生排队
博客中的文章均为meelo原创,请务必以链接形式注明本文地址 CCF CSP 201703-2 学生排队 问题描述 体育老师小明要将自己班上的学生按顺序排队.他首先让学生按学号从小到大的顺序排成一排, ...
随机推荐
- ADO中最重要的对象有三个:Connection、Recordset和Command
ConnectionPtr: _ConnectionPtr m_pConnection; HRESULT hr; try{ hr = m_pConnection.CreateInstance(_uui ...
- VS2013 VS2015 VS2017调试出现无法启动iis express web服务器
最近老是遇到这个问题,天天如此,烦死人,网上答案繁多,但是都解决不了,也是由于各种环境不同导致的,这里把几种解决方法都记录下 一.其他项目都可以,就这么一个不行 因为其他项目都可以,就这么一个不行,所 ...
- Fiddler对https抓包时,提示"HTTPS decryption is disabled."
安装了fiddlercertmaker.exe 后,对 https://www.baidu.com 进行抓包时,右侧界面提示"HTTPS decryption is disabled.&qu ...
- 转-C语言中.h和.c文件解析
C语言中.h和.c文件解析(很精彩) 简单的说其实要理解C文件与头文件(即.h)有什么不同之处,首先需要弄明白编译器的工作过程,一般说来编译器会做以下几个过程: 1.预处理阶段 2.词 ...
- sqlserver记录去重
,[emp_name] ,[gender] ,[department] ,[salary] from [employee] select * from ( select ROW_NUMBER() ov ...
- form表单公用
<?php /** * 后台总控制器 */ namespace app\common\controller; use think\Controller; use app\common\servi ...
- input错误提示,点击提交,提示有未填项,屏幕滑到input未填项的位置
function errorInfo(parm) { //获取文本框值 var $val = parm.val(); if ($val==""||undefined||null){ ...
- Python-面向对象(组合、封装与多态)
一.组合 什么是组合? 就是一个类的属性 的类型 是另一个自定义类的 类型,也可以说是某一个对象拥有一个属性,该属性的值是另一个类的对象. 通过为某一个对象添加属性(这里的属性是另一个类的对象)的方式 ...
- CSS弹性(flexible)盒子
弹性盒子 弹性盒子由弹性容器(Flex container)和弹性子元素(Flex item)组成 弹性容器通过display:flex | inline-flex将其定义为弹性容器 ...
- 数据结构HashMap(Android SparseArray 和ArrayMap)
HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在.在HashMap中,key-value总是会当做一个整体来处理,系统会根据 ...