Hive中笔记 :三种去重方法,distinct,group by与ROW_Number()窗口函数
一、distinct,group by与ROW_Number()窗口函数使用方法
1. Distinct用法:对select 后面所有字段去重,并不能只对一列去重。
(1)当distinct应用到多个字段的时候,distinct必须放在开头,其应用的范围是其后面的所有字段,而不只是紧挨着它的一个字段,而且distinct只能放到所有字段的前面
(2)distinct对NULL是不进行过滤的,即返回的结果中是包含NULL值的
(3)聚合函数中的DISTINCT,如 COUNT( ) 会过滤掉为NULL 的项
2.group by用法:对group by 后面所有字段去重,并不能只对一列去重。
3. ROW_Number() over()窗口函数
注意:ROW_Number() over (partition by id order by time DESC) 给每个id加一列按时间倒叙的rank值,取rank=1
select m.id,m.gender,m.age,m.rank
from (select id,gender,age,ROW_Number() over(partition by id order by id) rank
from temp.control_201804to201806
where id!='NA' and gender!='' or age!=''
) m
where m.rank=1
二、案例:
1.表中有两列:id ,superid,按照superid倒序排序选出前100条不同的id,如下:
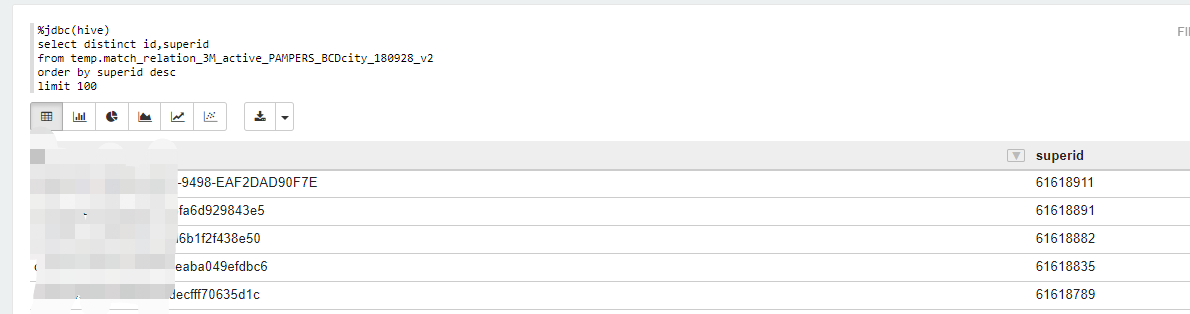
1.方案一:
子查询中对id,superid同时去重,可能存在一个id对应的superid不同,id这一列有重复的id,但 是结果只需要一列不同的id,如果时不限制数量,则可以选择这种方法
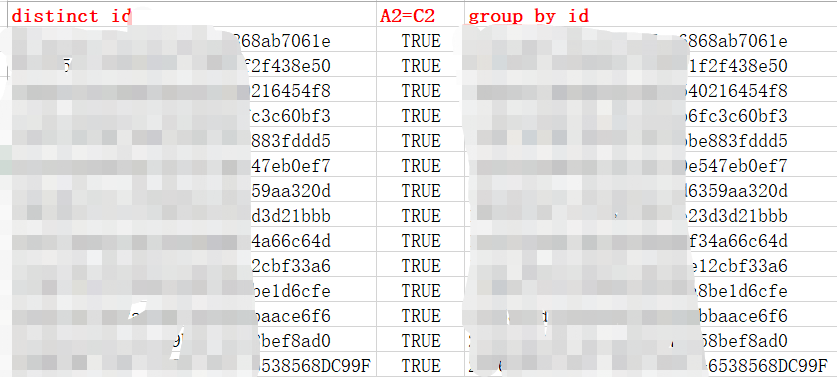
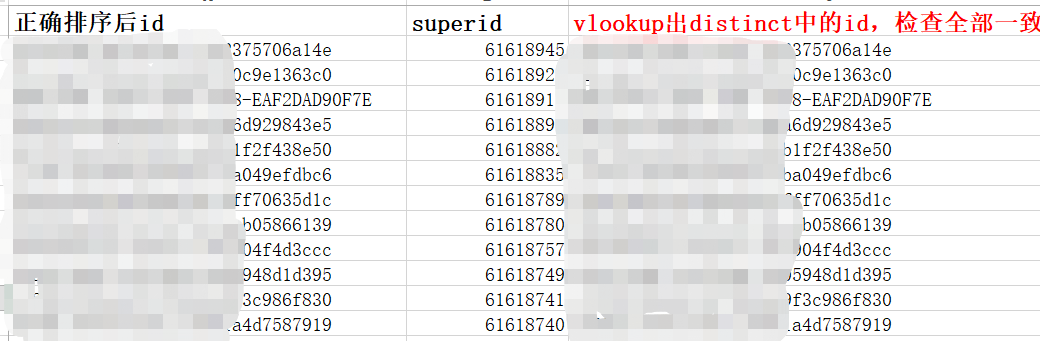
方案二:
因为要求按照superid倒序排序选出,而一个id对应的superid不同,必有大有小,选出最大的那一个,即可。 同理若是按照superid正序排列,可以选出最小的一列
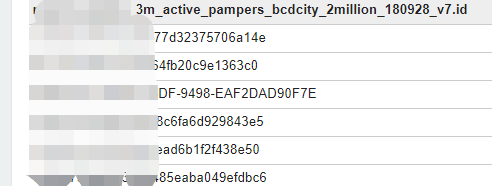
方案三:
首先利用窗口函数ROW_Number() over()窗口函数对id这一列去重,不能用distinct或者group by对id,superid同时去重

Hive中笔记 :三种去重方法,distinct,group by与ROW_Number()窗口函数的更多相关文章
- 061 hive中的三种join与数据倾斜
一:hive中的三种join 1.map join 应用场景:小表join大表 一:设置mapjoin的方式: )如果有一张表是小表,小表将自动执行map join. 默认是true. <pro ...
- JS中的五种去重方法
JS中的五种去重方法 第一种方法: 第二种方法: 第三种方法: 第四种方法: 第五种方法:优化遍历数组法 思路:获取没重复的最右一值放入新数组 * 方法的实现代码相当酷炫,* 实现思路:获取没重复的 ...
- SuperDiamond在JAVA项目中的三种应用方法实践总结
SuperDiamond在JAVA项目中的三种应用方法实践总结 1.直接读取如下: @Test public static void test_simple(){ PropertiesConfigur ...
- Hive中的三种不同的数据导出方式介绍
问题导读:1.导出本地文件系统和hdfs文件系统区别是什么?2.带有local命令是指导出本地还是hdfs文件系统?3.hive中,使用的insert与传统数据库insert的区别是什么?4.导出数据 ...
- js oop中的三种继承方法
JS OOP 中的三种继承方法: 很多读者关于js opp的继承比较模糊,本文总结了oop中的三种继承方法,以助于读者进行区分. <继承使用一个子类继承另一个父类,子类可以自动拥有父类的属性和方 ...
- java数组中的三种排序方法中的冒泡排序方法
我记得我大学学java的时候,怎么就是搞不明白这三种排序方法,也一直不会,现在我有发过来学习下这三种方法并记录下来. 首先说说冒泡排序方法:冒泡排序方法就是把数组中的每一个元素进行比较,如果第i个元素 ...
- Hive总结(八)Hive数据导出三种方式
今天我们再谈谈Hive中的三种不同的数据导出方式. 依据导出的地方不一样,将这些方式分为三种: (1).导出到本地文件系统. (2).导出到HDFS中: (3).导出到Hive的还有一个表中. 为了避 ...
- hive 数据导出三种方式
今天我们再谈谈Hive中的三种不同的数据导出方式.根据导出的地方不一样,将这些方式分为三种:(1).导出到本地文件系统:(2).导出到HDFS中:(3).导出到Hive的另一个表中.为了避免单纯的文字 ...
- Jquery中each的三种遍历方法
Jquery中each的三种遍历方法 $.post("urladdr", { "data" : "data" }, function(dat ...
随机推荐
- VisualVM远程连接Tomcat
最近项目已经要提测了,有时间来考虑一些性能上的事儿了.之前拜读过<深入理解java虚拟机>,只可惜当时功力尚浅,有些东西还是不太懂,而且应用场景也没有,所以借这次机会看看.当然了,这次并不 ...
- Java BIO、NIO、AIO
同步与异步 同步与异步的概念, 关注的是 消息通信机制 同步是指发出一个请求, 在没有得到结果之前该请求就不返回结果, 请求返回时, 也就得到结果了. 比如洗衣服, 把衣服放在洗衣机里, 没有洗好之前 ...
- CAS 无锁式同步机制
计算机系统中,CPU 和内存之间是通过总线进行通信的,当某个线程占有 CPU 执行指令的时候,会尽可能的将一些需要从内存中访问的变量缓存在自己的高速缓存区中,而修改也不会立即映射到内存. 而此时,其他 ...
- 机器学习中数据清洗&预处理
数据预处理是建立机器学习模型的第一步,对最终结果有决定性的作用:如果你的数据集没有完成数据清洗和预处理,那么你的模型很可能也不会有效 第一步,导入数据 进行学习的第一步,我们需要将数据导入程序以进行下 ...
- TCP首部
TCP的首部格式 字段解释 源端口和目的端口 用于多路复用/分解来自或送到上层应用的数据 数据偏移 TCP中数据的开始处距离TCP报文段的起始位置有多远 == TCP报文段的首部长度 表示长度以32位 ...
- SpringBoot学习(四)-->SpringBoot快速入门,开山篇
Spring Boot简介 Spring Boot的目的在于创建和启动新的基于Spring框架的项目.Spring Boot会选择最适合的Spring子项目和第三方开源库进行整合.大部分Spring ...
- npm ERR! Cannot read property 'path' of null
npm错误: 错误信息如下: $ sudo npm install -g bean-sdk sudo: npm: command not found $ npm install -g bean-sdk ...
- WarShall算法
1.引言 图的连通性问题是图论研究的重要问题之一,在实际中有着广泛的应用.例如在通信网络的联通问题中,运输路线的规划问题等等都涉及图的连通性.因此传递闭包的计算需要一个高效率的算法,一个著名的算法就是 ...
- Java高并发--消息队列
Java高并发--消息队列 主要是学习慕课网实战视频<Java并发编程入门与高并发面试>的笔记 举个例子:在购物商城下单后,希望购买者能收到短信或者邮件通知.有一种做法时在下单逻辑执行后调 ...
- window 服务器的Tomcat 控制台日志保存到日志文件.
在Linux系统中,Tomcat 启动后默认将很多信息都写入到 catalina.out 文件中,我们可以通过tail -f catalina.out 来跟踪Tomcat 和相关应用运行的情况. ...