pandas用法之二
1,函数应用
①map()
将函数作用于一个Series的每一个函数(不能是DataFrame)
类似于Python的高阶函数map()
函数可以是Numpy中的通用函数,也可以是自定义函数
优点:代码简介,效率高,不用循环
import pandas as pd
import numpy as np
l = range(10)
ser = pd.Series(l)
ser
>>>
ser
Out[46]:
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int64 ser.map(np.sqrt) >>>> Out[47]:
0 0.000000
1 1.000000
2 1.414214
3 1.732051
4 2.000000
5 2.236068
6 2.449490
7 2.645751
8 2.828427
9 3.000000
dtype: float64
# 自定义函数
ser.map(lambda x: x**2 + 1)
Out[48]:
0 1
1 2
2 5
3 10
4 17
5 26
6 37
7 50
8 65
9 82
dtype: int64
def func(x):
x1 = x**3
x2 = x1 +2 +7
return x2 ser.map(func) >>> Out[50]:
0 9
1 10
2 17
3 36
4 73
5 134
6 225
7 352
8 521
9 738
dtype: int64
自定义函数传的是函数名
②apply和applymap
通过apply()将函数应用到行或者列上面
在DataFrame上操作时注意需要指定轴的方向,默认axis=0

通过applymap()将函数应用到每一个数据上,和apply()是有区别的,applymap()只能作用于DataFrame

举个例子:
df = pd.DataFrame(np.arange(10).reshape(5, 2), columns=['col_1', 'col_2'])
df >>>
Out[54]:
col_1 col_2
0 0 1
1 2 3
2 4 5
3 6 7
4 8 9 df.apply(np.sum) >>>
Out[55]:
col_1 20
col_2 25
dtype: int64
这个地方容易混,横向是移动到下一个横向计算
df.apply(np.sum, axis=1) >>> Out[56]:
0 1
1 5
2 9
3 13
4 17
dtype: int64
df.applymap(np.sqrt)
>>> Out[57]:
col_1 col_2
0 0.000000 1.000000
1 1.414214 1.732051
2 2.000000 2.236068
3 2.449490 2.645751
4 2.828427 3.000000
2,层级索引
我们知道设置索引列是用set_index('data')
那设置多个索引列:set_index(['a', 'b'], inplace=True) 需要注意a和b的先后顺序;这样要先访问a后访问b才可以得到数据
选取子集:
外层选取 loc['outer_index']
内层选取 loc['out_index', ‘inner_index’]
交换层级顺序swaplevel()(类似于将b提到a前面)
层级索引的排序sort_index(level=)(level可以加也可以不加,不加的话默认是先排序外侧,再排内侧)
常用语分组操作、透视表的生成
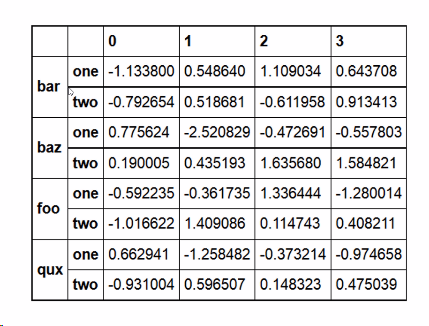
如上图:外层索引是bar,内层索引是one,two
如果直接访问bar的话,就会拿到2行
3,pandas的分组与聚合
分组:对数据集进行分组,然后对每一组进行统计分析
pandas能够使用groupby进行更加复杂的分组统计
分组的运算过程 split--》apply--》combine
拆分:进行分组的根据
应用:每一个分组运行的计算规则
合并:把每个分组的计算结果合并起来
聚合:数组产生标量的过程,如mean()、count()等
常用于对分组之后的数据进行计算
内置的聚合函数:sum(), mean(),max(),min(),count()
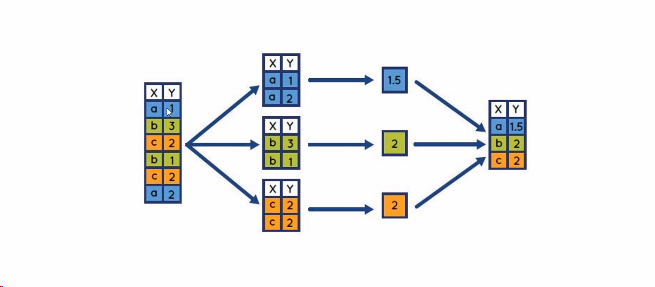
按照单列分组,obj.groupby('label')
按照多列分组,obj.groupby(['label'],['label2'])--》多层DataFrame(先按照label1分组,再按照label2分组)
groupby()操作后产生GroupBy对象:DataFrameGroupBy,SeriesGroupBy
GroupBy对象没有实际运算,只是包含分组的中间数据
对GroupBy对象进行分组聚合操作
常见的聚合操作:mean(),sum(),size(),count()
对非数值数据不进行分组运算
4,自定义分组和自定义聚合操作
(1) 自定义分组:
①groupby()支持传入自定义的函数进行分组,操作针对的是索引,所以要设置set_index
②可以通过自定义函数构造一个分组列,然后根据分组列进行groupby
(2) 自定义聚合操作:
①使用agg()函数
②传入包含多个函数的列表,可同时完成多个聚合操作
③可通过字典为每个列指定不同的操作方法
④传入自定义函数
# 自定义的分组规则
def get_score_group(score):
if score <=4:
score_group = 'low'
elif score<=6:
score_group = 'middle'
else:
score_group = 'high'
return score_group
# 方法1:传入自定义函数进行分组按照单列分组
data2 = data.set_index('Happiness Score') # 先要设置为索引
data2.groupby(get_score_group).size() # 方法2:
data2.groupby('Region').apply(get_score_group)
# 传入包含多个函数的列表
data2.groupby('Region').['Happiness Score'].agg([np.max, np.min])
# 通过字典为每一个列指定不同的操作方式
data2.groupby('Region').agg({'Happiness Score': np.mean, 'Happiness Rank': np.min})
def max_min_diff(x): # x是每个 分组的数据
return x.max()-x.min() data.groupby('Region')['Happiness Rank'].agg(max_min_diff)
5,透视表
简介:
是将‘扁平’的表转换为‘立体’表的过程
扁平?只包括行和列
立体包含行,列和值

透视表(pivot table)操作
①df.pivot_table(values, index,columns,aggfunc, margins)
②values:透视表中的元素值(根据聚合函数得出的)
③index:透视表中的行索引(列名)
④columns:透视表的列索引(列名)
⑤aggfunc:聚合函数,可以指定多个(默认是求均值)
⑥margins:表示是否对所有数据进行统计(默认是求均值)
df.pivot_table(values='Score', index='Semester', columns='Subject')
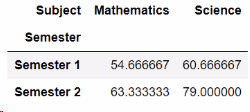
df.pivot_table(values='Score', index='Semester', columns='Subject', aggfunc=np.mean)

结果是一样的
df.pivot_table(values='Score', index='Semester', columns='Subject', margin=True)
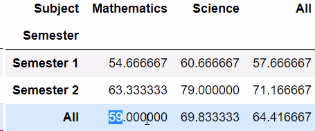
要注意的是aggfunc是什么操作,那么margin=True参数就是代表什么
df.pivot_table(values='Score', index='Semester', columns='Subject', aggfunc=['mean', 'max', 'min'])

当然透视表也是支持层级索引的
5,数据规整
(一)数据合并concat
①按照指定的轴方向对多个数据对象进行数据合并
②pd.concat(objs, axis)
1, objs:多个数据对象,如包含DataFrame的列表
2,axis:0按照索引方向(纵向), 1按列方向(横向)
③注意,默认使用outer join进行合并

对应的
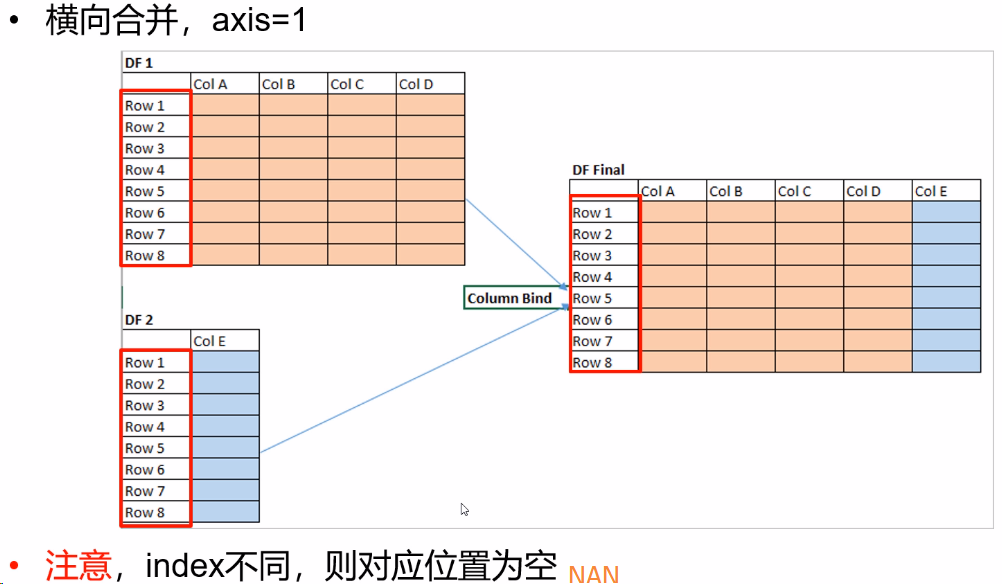
(二)数据合并merge
①根据单个或多个键将不同DataFrame的行连接起来(这个键就是列名)
②默认将重叠列的列名作为外键进行连接
1,on显示指定外键
2,left_on,左侧数据的外键
3,right_on,右侧数据的外键
③连接方式:
1,参数how指定连接方式
1):外连接(outer)结果中的键是并集
2):左链接(left)
3):右连接(right)
2,处理重复列名
suffixes, 默认为_x,_y(suffixes=['_x','_y'])
处理重复列名,当指定了外键后,不同的DataFrame中仍然存在列名相同的列,默认情况 下,相同列名的列会分别自动添加后缀_x,_y,也可以自定义设置后缀
3,按索引连接
left_index=True或right_index=True

例子:
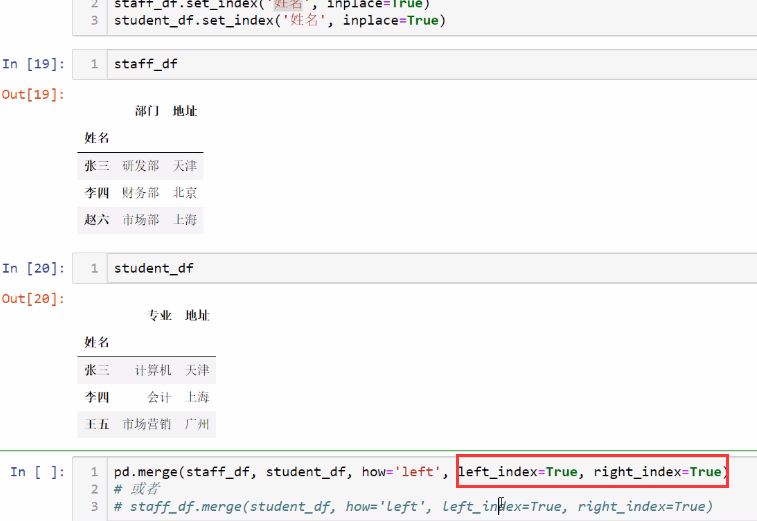
pd.merge(staff_df, student_df, how='outer', on='姓名')
# 左边为staff_df,右边为student_df,指定为外连接也就是取并集,默认会取相同列,但是这里我们指定on参数
也可以写成
staff_df.merge(student_df,how='outer', on='姓名')
这就是看个人喜好了
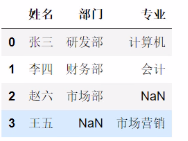
如果两个数据集没有相同的列名
用 left_on='姓名', right_on='学生姓名' 指定
pd.merge(staff_df, student_df, how='left', left_on='姓名', right_on='学生姓名')

如果对应的列是索引的时候:
按索引进行连接,left_index=True或right_index=True
(三)数据重构stack、unstack
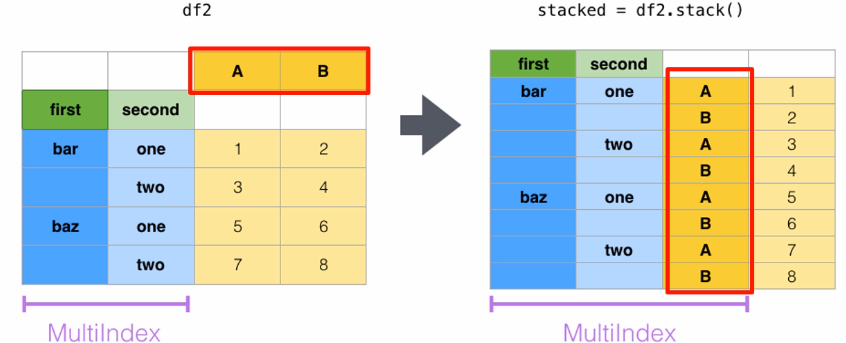
stack()和unstack()适用于层级索引对象,仅是对数据显示的转换,并不对数据本身产生聚合操作。
stack():将数据的列旋转为行
参数level:索引的层级。默认为-1,表示 最里面的一层,和列表的索引方式是一致的
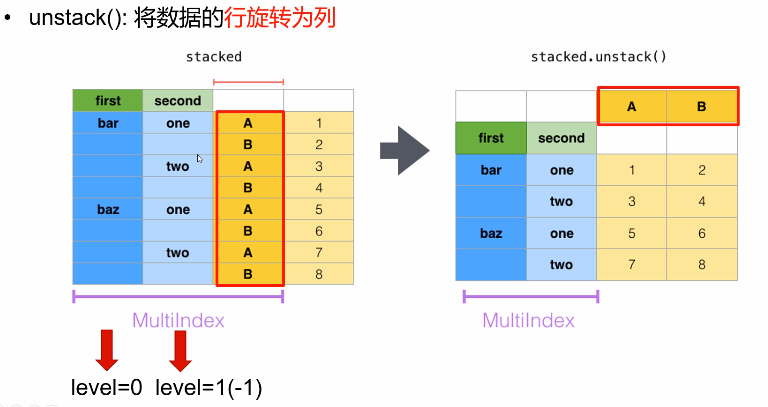
将行旋转为列就是unstack():将数据的行旋转为列
pandas用法之二的更多相关文章
- pandas用法大全
pandas用法大全 一.生成数据表 1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as np import pandas as pd12 2. ...
- pandas用法小结
前言 个人感觉网上对pandas的总结感觉不够详尽细致,在这里我对pandas做个相对细致的小结吧,在数据分析与人工智能方面会有所涉及到的东西在这里都说说吧,也是对自己学习的一种小结! pandas用 ...
- python之pandas用法大全
python之pandas用法大全 更新时间:2018年03月13日 15:02:28 投稿:wdc 我要评论 本文讲解了python的pandas基本用法,大家可以参考下 一.生成数据表1.首先导入 ...
- Python3 pandas用法大全
Python3 pandas用法大全 一.生成数据表 1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as np import pandas as ...
- pandas用法总结
pandas用法总结 2018年06月07日 10:49:03 一夜了 阅读数 38705更多 分类专栏: 杂项 一.生成数据表 1.首先导入pandas库,一般都会用到numpy库,所以我们先导 ...
- Pandas系列(二)- DataFrame数据框
一.初识DataFrame dataFrame 是一个带有索引的二维数据结构,每列可以有自己的名字,并且可以有不同的数据类型.你可以把它想象成一个 excel 表格或者数据库中的一张表DataFram ...
- SystemParametersinfo用法(二)
SystemParametersinfo用法(二) SPI_SETDOUBLECLKHEGHT:将ulParam参数的值设为双击矩形区域的高度.双击矩形区域是指双击中的第2次点击时鼠标指针必须落在的区 ...
- Pandas学习(二)——双色球开奖数据分析
学习笔记汇总 Pandas学习(一)–数据的导入 pandas学习(二)–双色球数据分析 pandas学习(三)–NAB球员薪资分析 pandas学习(四)–数据的归一化 pandas学习(五)–pa ...
- 前置机器学习(四):一文掌握Pandas用法
Pandas提供快速,灵活和富于表现力的数据结构,是强大的数据分析Python库. 本文收录于机器学习前置教程系列. 一.Series和DataFrame Pandas建立在NumPy之上,更多Num ...
随机推荐
- 获取cpu和内存使用情况
public class SystemInfo { [DllImport("kernel32")] public static extern void GetSystemDirec ...
- .net core2.1 配置
ASPNETCORE_ENVIRONMENT Development(开发)Staging(预演)Production(生产) var builder = new ConfigurationBuild ...
- Java中的static修饰int值做全局变量与static修饰词初始化顺序
先看一道题 public class HasStatic{ private static int x=100; public static void main(String args[]){ HasS ...
- 地下产链——创建安装包捆绑软件(Bundled software)
Bundled_Software 首先,因为个人知识不足的情况下,无法进行EXE文件捆绑机的制作说明,所以有需要请转至http://www.cnblogs.com/qintangtao/archive ...
- kubernetes学习笔记之十四:helm入门
1.Helm的简介 Helm是Kubernetes的一个包管理工具,用来简化Kubernetes应用的部署和管理.可以把Helm比作CentOS的yum工具. Helm有如下几个基本概念: Chart ...
- springCloud 服务注册启动报错<com.sun.jersey.api.client.ClientHandlerException: java.net.ConnectException: Connection refused: connect>
报错:com.sun.jersey.api.client.ClientHandlerException: java.net.ConnectException: Connection refused: ...
- python列表中的pop函数
再python的列表中,有许多的内置方法,而在这里我主要向大家介绍一下pop函数. pop函数主要是用于删除列表中的数据.而其删除值时会返回删除的值.如果没有参数传入时, 则会默认认为删除列表的最后一 ...
- 魔力Python——对象
Python之中,一切皆对象. 本文分为4部分: 1. 面向对象:初识 2. 面向对象:进阶 3. 面向对象:三大特性----继承,多态,封装 4. 面向对象:反射 0. 楔子 面向过程和面向对象的是 ...
- 使用 nodeJs 开发微信公众号(上传图片)
在给用户发送消息中涉及到的素材(图片.视频.音频.文章等)需要事先传到微信服务器,然后获得媒体id(media_id),然后把 media_id 传递给用户 上传分上传临时素材(只保存三天)和上传永久 ...
- 记一次Monolog的BufferHandler使用
laravel中可以设置自定义的日记channel(config/logging中设置),按照laravel-china的一篇文章,把log按一定格式并且以批量的方式写入日志文件: https://l ...