爬虫——xpath
1.什么是xpath?
Xpath,全称XML Path Language,即XML路径语言。它是一门在XML之后查找信息的语言,也同样适用于HTML文档的搜索。在做爬虫的时候,我们用XPath语言来做相应的信息抽取。
2.为什么要学习xpath?
- xpath可用于xml和html
- xpath比正则表达式更加简单和强大
- scrapy也支持xpath语法
3.节点
- 父节点
- 子节点
- 后代节点
- 兄弟节点
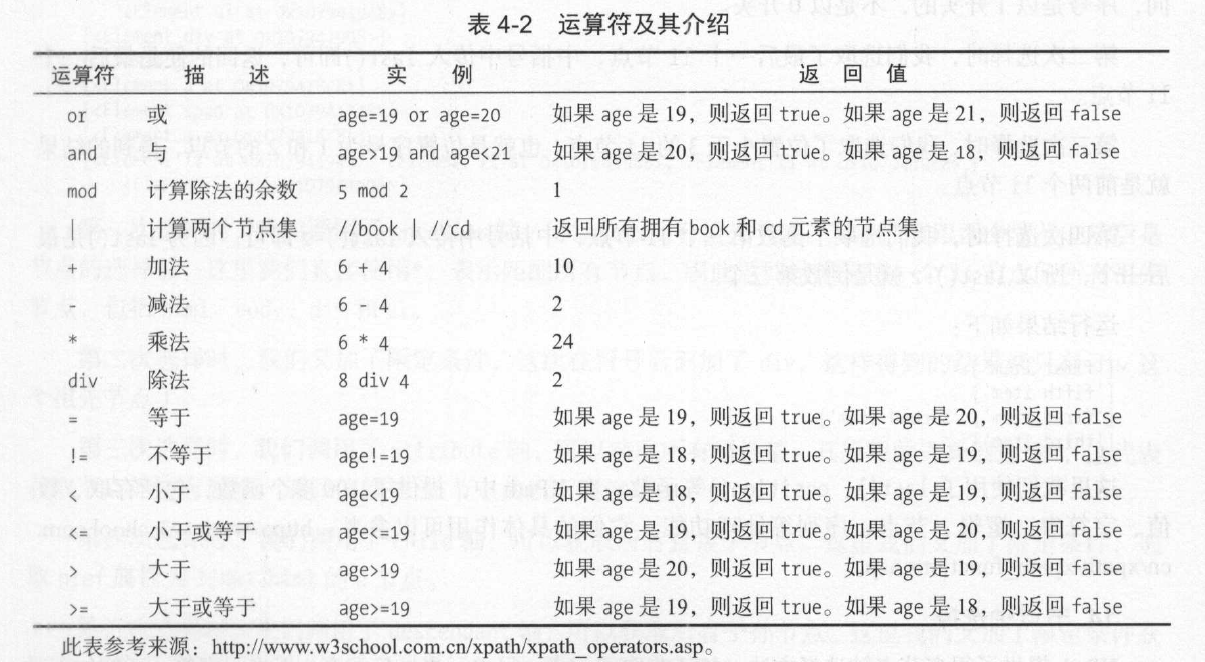
4.常用规则

实例如下: //title[@lang='eng'] ,这个表达式的意思是选择所有名称为titile,同时属性为eng的节点。
5.demo
#对html2文本的读取
from lxml import etree #从lxml库导入etree模块,lxml是python的一个解析库,支持HTML和XML的解析,而且效率非常高。
text = '''
<div>
<ul>
<li class ="item-0"><a href="link1.html">first item</a></li>
<li class ="item-1"><a href="link2.html">second item</a></li>
<li class ="item-inactive"><a href="link3.html">third item</a></li>
<li class ="item-1"><a href="link4.html">fourth item</a></li>
<li class ="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text) #对文本进行初始化,构造出一个XPath解析对象,etree模块可以对不完整的代码进行补全修正。
result = etree.tostring(html) #Xpath解析对象是bytes类型,用toString方法转换成string类型
print(result.decode('utf-8')) 运行结果:
C:\Users\Mr.Su\PycharmProjects\KUGOU\venv\Scripts\python.exe C:/Users/Mr.Su/PycharmProjects/KUGOU/venv/test1.py
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>
Process finished with exit code 0
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser()) #构造Xpath解析对象
result = etree.tostring(html) #将byte类型转换成String类型
print(result.decode('utf-8')) #以utf-8字符格式打印
运行结果:
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd">
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div></body></html>
#获取所有节点
from lxml import etree html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//*') #*表示匹配所有节点
print(result) 运行结果:
[<Element html at 0x1b7f972ce48>, <Element body at 0x1b7f972cf48>, <Element div at 0x1b7f972cf88>,
<Element ul at 0x1b7f972cfc8>, <Element li at 0x1b7f973c048>, <Element a at 0x1b7f973c0c8>,
<Element li at 0x1b7f973c108>, <Element a at 0x1b7f973c148>, <Element li at 0x1b7f973c188>,
<Element a at 0x1b7f973c088>, <Element li at 0x1b7f973c1c8>, <Element a at 0x1b7f973c208>, <Element li at 0x1b7f973c248>, <Element a at 0x1b7f973c288>]
#可以看到,返回形式是一个列表,每个元素都是Element类型,后面格式节点的名称:html、body、li等等。
#匹配所有的li节点
from lxml import etree html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li') #匹配所有的li节点
print(result)
print(result[0]) #获取列表中的第一个li元素 运行结果:[<Element li at 0x267c93acf48>, <Element li at 0x267c93acf88>, <Element li at 0x267c93acfc8>,
<Element li at 0x267c93bc048>, <Element li at 0x267c93bc088>]
<Element li at 0x267c93acf48>
#匹配li元素的子节点
from lxml import etree html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li/a') #匹配所有的li节点的直接a子节点
# result = html.xpath('//li//a') #匹配所有的li节点的子孙a节点
print(result) print(result[]) 运行结果:
[<Element a at 0x26fa694cf08>, <Element a at 0x26fa694cf48>, <Element a at 0x26fa694cf88>, <Element a at 0x26fa694cfc8>, <Element a at 0x26fa695c048>]
<Element a at 0x26fa694cf08>
总结: / 用于获取直接子节点,//用于获取所有子孙节点
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//ul/a') #匹配所有的ul节点的a直接子节点
print(result)
print(result[0])
运行结果:
Traceback (most recent call last):
File "C:/Users/Mr.Su/PycharmProjects/KUGOU/venv/test2.py", line 6, in <module>
print(result[0])
IndexError: list index out of range
#显然无法获取到,因为a节点是ul的子孙节点,而不是直接子节点。将路径表达式改为'//ul/a'即可。
#父节点的获取:获取href为link4.html的a节点,在获取其父节点的class属性
<div>
<ul>
<li class ="item-0"><a href="link1.html">first item</a></li>
<li class ="item-1"><a href="link2.html">second item</a></li>
<li class ="item-inactive"><a href="link3.html">third item</a></li>
<li class ="item-1"><a href="link4.html">fourth item</a></li>
<li class ="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())#构造xpath解析对象
result = html.xpath('//a[@href="link4.html"]/../@class')
#result = html.xpath('//a[@href="link4.html"]/parent::*/@class') 也可以使用parent::来获取
print(result) 运行结果:['item-1']
#属性匹配:匹配class ='item-inactive' 的li节点的直接节点的内容
from lxml import etree html = etree.parse('./test.html',etree.HTMLParser()) #构造XPath解析对象
result = html.xpath('//li[@class="item-inactive"]/a')
print(result[].text)
运行结果:third item
#用text()方法获取节点中的文本
from lxml import etree html = etree.parse('./test.html',etree.HTMLParser())
resulet = html.xpath('//li[@class="item-0"]/a/text()')
print(resulet)
运行结果:['first item', 'fifth item']
#属性获取:获取li元素的所有直接a节点的href属性
from lxml import etree html = etree.parse('./test.html',etree.HTMLParser())
resulet = html.xpath('//li/a/@href')
print(resulet)
运行结果:['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
#属性多值匹配
from lxml import etree text = '''
<li class = "li li-first"><a href = "link.html">first item</a></li>
'''
html = etree.HTML(text)
resulet = html.xpath('//li[@class="li"]/a/text()')
print(resulet) 运行结果: []
#在这个案例中,li元素的class属性有多个值,只用其中的一个值来匹配是无法匹配到的。
#遇到这样的情况需要用contains函数来匹配: contains(属性名称,属性值)
resulet = html.xpath('//li[contains(@class,"li")]/a/text()')
运行结果:['first item']
#多属性匹配
'''
当我们需要根据多个属性来确定一个节点时就可以用一些运算符来连接多个属性。
from lxml import etree text = '''
<li class = "li li-first" name="item"><a href = "link.html">first item</a></li>
'''
html = etree.HTML(text)
resulet = html.xpath('//li[contains(@class,"li")and @name="item"]/a/text()')
print(resulet)
#按序选择节点
from lxml import etree text = '''
<div>
<ul>
<li class ="item-0"><a href="link1.html">first item</a></li>
<li class ="item-1"><a href="link2.html">second item</a></li>
<li class ="item-inactive"><a href="link3.html">third item</a></li>
<li class ="item-1"><a href="link4.html">fourth item</a></li>
<li class ="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
resulet = html.xpath('//li[1]/a/text()') #特别注意,这里的序号是从1开始而不是0
print(resulet)
resulet = html.xpath('//li[last()]/a/text()') #选取最后一个节点
print(resulet)
resulet = html.xpath('//li[position()<3]/a/text()') #选取序号小于3的节点
print(resulet)
resulet = html.xpath('//li[last()-2]/a/text()') #选取倒数第三个
print(resulet) 运行节点:
['first item']
['fifth item']
['first item', 'second item']
['third item']
#用节点轴获取节点
from lxml import etree text = '''
<div>
<ul>
<li class ="item-0"><a href="link1.html">first item</a></li>
<li class ="item-1"><a href="link2.html">second item</a></li>
<li class ="item-inactive"><a href="link3.html">third item</a></li>
<li class ="item-1"><a href="link4.html">fourth item</a></li>
<li class ="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
resulet = html.xpath('//li[1]/ancestor::*') #调用了ancestor::轴获取祖先节点,*表示匹配所有祖先节点。
print(resulet)
resulet = html.xpath('//li[1]/ancestor::div') # 获取所有div祖先节点
print(resulet)
resulet = html.xpath('//li[1]/attribute::*') #调用attribute::轴获取属性值,attribute表示所有的属性值
print(resulet)
resulet = html.xpath('//li[1]/child::a[@href="link1.html"]') #调用child::轴获取直接子节点,a[@href="link1.html"]表示href属性等于link1.html的a节点
print(resulet)
result = html.xpath('//li[1]/descendant::span') #调用descendant::轴获取子孙节点。
print(resulet)
resulet = html.xpath('//li[1]/following::*[2]') #调用following::轴获取当前节点之后的所有节点,*[]表示获取所有节点的第二个后续节点。
print(result)
resulet = html.xpath('//li[1]/following-sibling::*') #调用following-sibling::节点获取当前节点之后的所有同级节点。
print(resulet) 运行结果:
[<Element html at 0x152b7c99208>, <Element body at 0x152b7c99188>, <Element div at 0x152b7c99148>, <Element ul at 0x152b7c99248>]
[<Element div at 0x152b7c99148>]
['item-0']
[<Element a at 0x152b7c99248>]
[<Element a at 0x152b7c99248>]
[]
[<Element li at 0x152b7c99148>, <Element li at 0x152b7c99288>, <Element li at 0x152b7c992c8>, <Element li at 0x152b7c99308>]
爬虫——xpath的更多相关文章
- 笔记-爬虫-XPATH
笔记-爬虫-XPATH 1. xpath XPath是W3C的一个标准.它最主要的目的是为了在XML1.0或XML1.1文档节点树中定位节点所设计.目前有XPath1.0和XPath2.0两 ...
- python爬虫xpath
又是一个大晴天,因为马上要召开十九大,北京地铁就额外的拥挤,人贴人到爆炸,还好我常年挤地铁早已练成了轻功水上漂,挤地铁早已经不在话下. 励志成为一名高级测试工程师的我,目前还只是个菜鸟,难得有机会,公 ...
- python爬虫xpath的语法
有朋友问我正则,,okey,其实我的正则也不好,但是python下xpath是相对较简单的 简单了解一下xpath: XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML ...
- Python网络爬虫-xpath模块
一.正解解析 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [0-9] \D : 非数字 \w :数字.字母.下划线.中文 \W : 非\ ...
- [Python 练习爬虫] XPATH基础语法
XPATH语法: // 定位根标签 / 往下层寻找 /text() 提取文本内容 /@xxx 提取属性内容 Sample: import requests from lxml import etree ...
- 爬虫 - xpath 匹配
例题 import lxml.html test_data = """ <div> <ul> <li class="item-0& ...
- 爬虫--XPATH解析
今天说一下关于爬取数据解析的方式---->XPATH,XPATH是解析方式中最重要的一种方式 1.安装:pip install lxml 2.原理 1. 获取页面源码数据 2.实例化一个etr ...
- 爬虫 xpath
xpath简介 1.xpath使用路径表达式在xml和html中进行导航 2.xpath包含标准函数库 3.xpath是一个w3c的标准 xpath节点关系 1.父节点 2.字节点 3.同胞节点 4. ...
- 爬虫 xpath 获取方式
回顾 bs4 实例化bs对象,将页面源码数据加载到该对象中 定位标签:find('name',class_='xxx') findall() select() 将标签中的文本内容获取 string t ...
随机推荐
- win10安装nodejs遇到提示错误代码2503怎么办
我们在安装某个软件的时候,最闹心的就是遇到提示安装失败或错误,比如win10系统在安装nodejs遇到提示错误代码2503,遇见这个问题也不要慌张,今天小编就来告诉大家怎么解决这个问题. 1.打开智能 ...
- 我的第一个SolidWorks图
1. 学习到的知识点 2. 完成的工程图 3. 感受 学习是一种快乐,学到新的知识要学会分享,只要坚持,就有那么一点点的成就. 4. 参考 SolidWorks帮助文档
- Eclipse使用过程中的经验总结
1.Eclipse中如何配置JDK的Documents和Sources? "Windows"-> "Preferences"-> "Jav ...
- MySQL高级知识(十三)——表锁
前言:锁是计算机协调多个进程或线程并发访问某一资源的机制.在数据库中,除传统的计算机资源(如CPU.RAM.I/O等)的争用外,数据也是一种供许多用户共享的资源.如何保证数据并发访问的一致性.有效性是 ...
- 转://Oracle Golden Gate 概念和原理
引言:Oracle Golden Gate是Oracle旗下一款支持异构平台之间高级复制技术,是Oracle力推一种HA高可用产品,简称“OGG”,可以实现Active-Active 双业务中心架构 ...
- 小a的排列
链接:https://ac.nowcoder.com/acm/contest/317/G来源:牛客网 小a有一个长度为nn的排列.定义一段区间是"萌"的,当且仅当把区间中各个数排序 ...
- 二、Oracle 数据库基本操作
一.oracle常用数据类型数字:number(p,s) p表示数字的长度包括小数点后的位数,s表示小数点后的位数固定长度字符:char(n):n表示最大长度,n即是最大也是固定的长度,当数据不满长度 ...
- 吴恩达课后作业学习1-week4-homework-two-hidden-layer -1
参考:https://blog.csdn.net/u013733326/article/details/79767169 希望大家直接到上面的网址去查看代码,下面是本人的笔记 两层神经网络,和吴恩达课 ...
- js同步-异步-回调
出处:https://blog.csdn.net/u010297791/article/details/71158212(1)上面主要讲了同步和回调执行顺序的问题,接着我就举一个包含同步.异步.回调的 ...
- Redo丢失的4种情况及处理方法
这篇文章重点讨论Redo丢失的几种情况,及每种情况的处理方法. 一.说明:1.以下所说的当前日志指日志状态为CURRENT,ACTIVE,非当前日志指日志状态为INACTIVE2.不用考虑归档和非归档 ...