SolrCloud 高可用集群搭建
1.1 什么是SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
1.1.1 zookeeper是个什么玩意?
顾名思义zookeeper就是动物园管理员,他是用来管hadoop(大象)、Hive(蜜蜂)、pig(小猪)的管理员, Apache Hbase和 Apache Solr 的分布式集群都用到了zookeeper;Zookeeper:是一个分布式的、开源的程序协调服务,是hadoop项目下的一个子项目。
1.1.2 Zookeeper可以干哪些事情
1、配置管理
在我们的应用中除了代码外,还有一些就是各种配置。比如数据库连接等。一般我们都是使用配置文件的方式,在代码中引入这些配置文件。但是当我们只有一种配置,只有一台服务器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多,有很多服务器都需要这个配置,而且还可能是动态的话使用配置文件就不是个好主意了。这个时候往往需要寻找一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的都可以获得变更。比如我们可以把配置放在数据库里,然后所有需要配置的服务都去这个数据库读取配置。但是,因为很多服务的正常运行都非常依赖这个配置,所以需要这个集中提供配置服务的服务具备很高的可靠性。一般我们可以用一个集群来提供这个配置服务,但是用集群提升可靠性,那如何保证配置在集群中的一致性呢? 这个时候就需要使用一种实现了一致性协议的服务了。Zookeeper就是这种服务,它使用Zab这种一致性协议来提供一致性。现在有很多开源项目使用Zookeeper来维护配置,比如在HBase中,客户端就是连接一个Zookeeper,获得必要的HBase集群的配置信息,然后才可以进一步操作。还有在开源的消息队列Kafka中,也使用Zookeeper来维护broker的信息。在Alibaba开源的SOA框架Dubbo中也广泛的使用Zookeeper管理一些配置来实现服务治理。
2、名字服务
名字服务这个就很好理解了。比如为了通过网络访问一个系统,我们得知道对方的IP地址,但是IP地址对人非常不友好,这个时候我们就需要使用域名来访问。但是计算机是不能是别域名的。怎么办呢?如果我们每台机器里都备有一份域名到IP地址的映射,这个倒是能解决一部分问题,但是如果域名对应的IP发生变化了又该怎么办呢?于是我们有了DNS这个东西。我们只需要访问一个大家熟知的(known)的点,它就会告诉你这个域名对应的IP是什么。在我们的应用中也会存在很多这类问题,特别是在我们的服务特别多的时候,如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都熟知的访问点,这里提供统一的入口,那么维护起来将方便得多了。
3、分布式锁
其实在第一篇文章中已经介绍了Zookeeper是一个分布式协调服务。这样我们就可以利用Zookeeper来协调多个分布式进程之间的活动。比如在一个分布式环境中,为了提高可靠性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服务器都进行的话,那相互之间就要协调,编程起来将非常复杂。而如果我们只让一个服务进行操作,那又存在单点。通常还有一种做法就是使用分布式锁,在某个时刻只让一个服务去干活,当这台服务出问题的时候锁释放,立即fail over到另外的服务。这在很多分布式系统中都是这么做,这种设计有一个更好听的名字叫Leader Election(leader选举)。比如HBase的Master就是采用这种机制。但要注意的是分布式锁跟同一个进程的锁还是有区别的,所以使用的时候要比同一个进程里的锁更谨慎的使用。
4、集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中其他机器需要感知到这种变化,然后根据这种变化做出对应的决策。比如我们是一个分布式存储系统,有一个中央控制节点负责存储的分配,当有新的存储进来的时候我们要根据现在集群目前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。还有,比如一个分布式的SOA架构中,服务是一个集群提供的,当消费者访问某个服务时,就需要采用某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,比如Alibaba开源的SOA框架Dubbo就采用了Zookeeper作为服务发现的底层机制)。还有开源的Kafka队列就采用了Zookeeper作为Cosnumer的上下线管理。
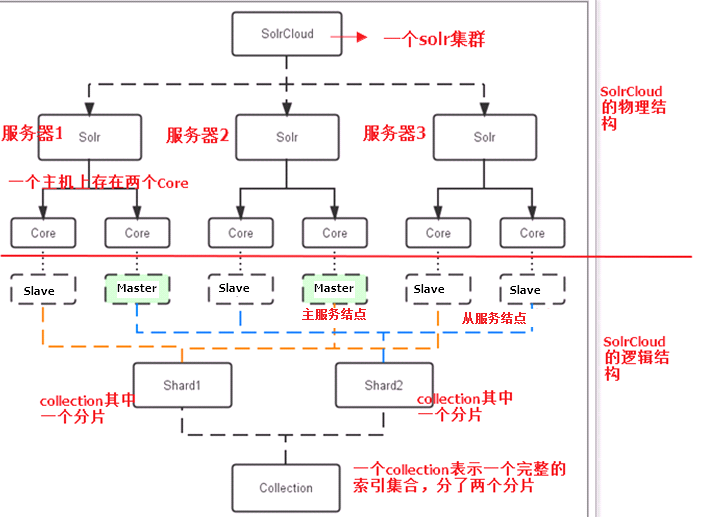
1.2 Solr集群的结构
1.3 Solr集群的搭建
本教程的这套安装是单机版的安装,所以采用伪集群的方式进行安装,如果是真正的生产环境,将伪集群的ip改下就可以了,步骤是一样的。
SolrCloud结构图如下:

需要三个zookeeper节点
四个solr节点。
使用伪分布式实现solr集群。需要三个zookeeper实例,4个tomcat实例,可以在一台虚拟机上模拟。建议虚拟机1G以上内存。
1.4 Zookeeper集群的搭建
1.4.1 前台条件
三个zookeeper实例。Zookeeper也是java开发的所以需要安装jdk。
1、Linux系统
2、Jdk环境。
3、Zookeeper。
1.4.2 Zookeeper的安装步骤
准备安装包:
链接:https://pan.baidu.com/s/1DnjSW-4mpdkPCR5v3UN7mw
提取码:8ilt
第一步:把zookeeper的安装包上传到服务器
第二步:解压缩。
[root@bogon ~]# tar -zxf zookeeper-3.4.6.tar.gz
[root@bogon ~]#
第三步:在/usr/local/目录下创建一个solrcloud目录。把zookeeper解压后的文件夹复制到此目录下三份。分别命名为zookeeper1、2、3
[root@bogon ~]# mkdir /usr/local/solrcloud
[root@bogon ~]# mv zookeeper-3.4.6 /usr/local/solrcloud/zookeeper1
[root@bogon ~]# cd /usr/local/solrcloud
[root@bogon solrcloud]# ll
total 4
drwxr-xr-x. 10 1000 1000 4096 Feb 20 2014 zookeeper1
[root@bogon solrcloud]# cp -r zookeeper1/ zookeeper2
[root@bogon solrcloud]# cp -r zookeeper1/ zookeeper3
[root@bogon solrcloud]#
第四步:配置zookeeper。
1、在每个zookeeper文件夹下创建一个data目录。
2、在data文件夹下创建一个文件名称为myid,文件的内容就是此zookeeper的编号1、2、3
[root@bogon data]# echo 1 >> myid
[root@bogon data]# ll
total 4
-rw-r--r--. 1 root root 2 Sep 17 23:43 myid
[root@bogon data]# cat myid
1
[root@bogon data]#
在zookeeper2、3文件夹下分别创建data目录和myid文件
[root@bogon solrcloud]# mkdir zookeeper2/data
[root@bogon solrcloud]# echo 2 >> zookeeper2/data/myid
[root@bogon solrcloud]# ll zookeeper2/data
total 4
-rw-r--r--. 1 root root 2 Sep 17 23:44 myid
[root@bogon solrcloud]# cat zookeeper2/data/myid
2
[root@bogon solrcloud]# mkdir zookeeper3/data
[root@bogon solrcloud]# echo 3 >> zookeeper3/data/myid
[root@bogon solrcloud]#
3、把zookeeper1下conf目录下的zoo_sample.cfg文件复制一份改名为zoo.cfg
[root@bogon conf]# cp zoo_sample.cfg zoo.cfg
4、修改zoo.cfg的配置
vim zoo.cfg

对zookeeper2、3中的设置做第二步至第四步修改。
zookeeper2:
myid内容为2
dataDir=/usr/local/solrcloud/zookeeper2/data
clientPort=2182
Zookeeper3:
的myid内容为3
dataDir=/usr/local/solrcloud/zookeeper3/data
clientPort=2183
第五步:
启动三个zookeeper
/usr/local/solrcloud/zookeeper1/bin/zkServer.sh start
/usr/local/solrcloud/zookeeper2/bin/zkServer.sh start
/usr/local/solrcloud/zookeeper3/bin/zkServer.sh start
查看集群状态:
/usr/local/solrcloud/zookeeper1/bin/zkServer.sh status
/usr/local/solrcloud/zookeeper2/bin/zkServer.sh status
/usr/local/solrcloud/zookeeper3/bin/zkServer.sh status
状态信息如下:
[root@bogon solrcloud]# /usr/local/solrcloud/zookeeper1/bin/zkServer.sh status
JMX enabled by default
Using config: /usr/local/solrcloud/zookeeper1/bin/../conf/zoo.cfg
Mode: follower
[root@bogon solrcloud]# /usr/local/solrcloud/zookeeper2/bin/zkServer.sh status
JMX enabled by default
Using config: /usr/local/solrcloud/zookeeper2/bin/../conf/zoo.cfg
Mode: leader
[root@bogon solrcloud]# /usr/local/solrcloud/zookeeper3/bin/zkServer.sh status
JMX enabled by default
Using config: /usr/local/solrcloud/zookeeper3/bin/../conf/zoo.cfg
Mode: follower
[root@bogon solrcloud]#
1.5 Solr实例的搭建
第一步:将apache-tomcat-7.0.47.tar.gz解压
tar -zxvf apache-tomcat-7.0.47.tar.gz
第二步:把解压后的tomcat复制到/usr/local/solrcloud/目录下复制四份。
cp apache-tomcat-7.0.47 /usr/local/solrcloud/tomcat1 -r
cp apache-tomcat-7.0.47 /usr/local/solrcloud/tomcat2 -r
cp apache-tomcat-7.0.47 /usr/local/solrcloud/tomcat3 -r
cp apache-tomcat-7.0.47 /usr/local/solrcloud/tomcat4 -r
第三步:修改tomcat的server.xml
vim tomcat2/conf/server.xml,把其中的端口后都加一。保证两个tomcat可以正常运行不发生端口冲突。
第四步:解压solr-4.10.3.tar.gz压缩包。复制solr.war到tomcat。
cd solr-4.10.3/dist
cp solr-4.10.3.war /usr/local/solrcloud/tomcat1/webapps/solr.war
cp solr-4.10.3.war /usr/local/solrcloud/tomcat2/webapps/solr.war
cp solr-4.10.3.war /usr/local/solrcloud/tomcat3/webapps/solr.war
cp solr-4.10.3.war /usr/local/solrcloud/tomcat4/webapps/solr.war
第五步:启动tomcat解压war包。把solr-4.10.3目录下example目录下的关于日志相关的jar包添加到solr工程中(可参考上一篇solr单机版的文章https://www.cnblogs.com/hxun/p/11159031.html)。
这里直接拷贝上篇文章搭建 配置好的solr文件
cd solr/tomcat/webapps/
cp solr -r ../../../solrcloud/tomcat1/webapps/
cp solr -r ../../../solrcloud/tomcat2/webapps/
cp solr -r ../../../solrcloud/tomcat3/webapps/
cp solr -r ../../../solrcloud/tomcat4/webapps/
第六步:拷贝单机版的solrhome。修改每个web.xml指定solrhome的位置。
cd /usr/local/solr/
cp -r solrhome/ ../solrcloud/solrhome1
cp -r solrhome/ ../solrcloud/solrhome2
cp -r solrhome/ ../solrcloud/solrhome3
cp -r solrhome/ ../solrcloud/solrhome4
vim tomcat1/webapps/solr/WEB-INF/web.xml
vim tomcat2/webapps/solr/WEB-INF/web.xml
vim tomcat3/webapps/solr/WEB-INF/web.xml
vim tomcat4/webapps/solr/WEB-INF/web.xml
分别修改路径为
/usr/local/solrcloud/solrhome1
/usr/local/solrcloud/solrhome2
/usr/local/solrcloud/solrhome3
/usr/local/solrcloud/solrhome4
1.6 solr集群的搭建
1.6.1 第一步
把solrhome中的配置文件上传到zookeeper集群。使用zookeeper的客户端上传。
进入客户端命令位置:cd /root/solr-4.10.3/example/scripts/cloud-scripts
|
./zkcli.sh -zkhost 192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183 -cmd upconfig -confdir /usr/local/solrcloud/solrhome1/collection1/conf -confname myconf |
查看配置文件是否上传成功:
[root@bogon bin]# cd /usr/local/solrcloud/zookeeper1/bin/
[root@bogon bin]# ./zkCli.sh
Connecting to localhost:2181
[zk: localhost:2181(CONNECTED) 0] ls /
[configs, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /configs
[myconf]
[zk: localhost:2181(CONNECTED) 2] ls /configs/myconf
[admin-extra.menu-top.html, currency.xml, protwords.txt, mapping-FoldToASCII.txt, _schema_analysis_synonyms_english.json, _rest_managed.json, solrconfig.xml, _schema_analysis_stopwords_english.json, stopwords.txt, lang, spellings.txt, mapping-ISOLatin1Accent.txt, admin-extra.html, xslt, synonyms.txt, scripts.conf, update-script.js, velocity, elevate.xml, admin-extra.menu-bottom.html, clustering, schema.xml]
[zk: localhost:2181(CONNECTED) 3]
1.6.2 第二步
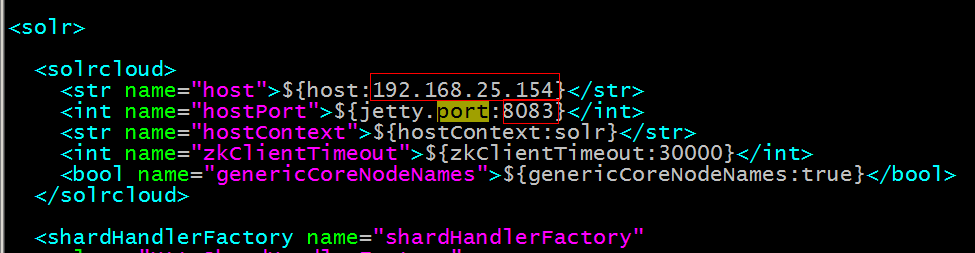
修改solrhome下的solr.xml文件,指定当前实例运行的ip地址及端口号。
vim /usr/local/solrcloud/solrhome1/solr.xml
vim /usr/local/solrcloud/solrhome2/solr.xml
vim /usr/local/solrcloud/solrhome3/solr.xml
vim /usr/local/solrcloud/solrhome4/solr.xml
修改host和prot从8080到8083
1.6.3 第三步
修改每一台solr的tomcat 的 bin目录下catalina.sh文件中加入DzkHost指定zookeeper服务器地址:
vim /usr/local/solrcloud/tomcat1/bin/catalina.sh
vim /usr/local/solrcloud/tomcat2/bin/catalina.sh
vim /usr/local/solrcloud/tomcat3/bin/catalina.sh
vim /usr/local/solrcloud/tomcat4/bin/catalina.sh
JAVA_OPTS="-DzkHost=192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183"
(可以使用vim的查找功能查找到JAVA_OPTS的定义的位置,然后添加)
1.6.4 第四步
重新启动tomcat。
如果觉得一个个启动tomcat麻烦可以编写脚本一键启动 如下:
vim /usr/local/solrcloud/startall.sh
编辑内容(先启动zookeeper,注意前面启动过了启动会报错,可以无视):
/usr/local/solrcloud/zookeeper1/bin/zkServer.sh start
/usr/local/solrcloud/zookeeper2/bin/zkServer.sh start
/usr/local/solrcloud/zookeeper3/bin/zkServer.sh start
/usr/local/solrcloud/tomcat1/bin/startup.sh
/usr/local/solrcloud/tomcat2/bin/startup.sh
/usr/local/solrcloud/tomcat3/bin/startup.sh
/usr/local/solrcloud/tomcat4/bin/startup.sh
加权限:chmod +x /usr/local/solrcloud/startall.sh
执行脚本:/usr/local/solrcloud/startupall.sh
关闭脚本:
vim /usr/local/solrcloud/shutdownall.sh
编辑内容:
/usr/local/solrcloud/zookeeper1/bin/zkServer.sh stop
/usr/local/solrcloud/zookeeper2/bin/zkServer.sh stop
/usr/local/solrcloud/zookeeper3/bin/zkServer.sh stop
/usr/local/solrcloud/tomcat1/bin/shutdown.sh
/usr/local/solrcloud/tomcat2/bin/shutdown.sh
/usr/local/solrcloud/tomcat3/bin/shutdown.sh
/usr/local/solrcloud/tomcat4/bin/shutdown.sh
加权限:chmod +x /usr/local/solrcloud/shutdownall.sh
启动成功后,访问
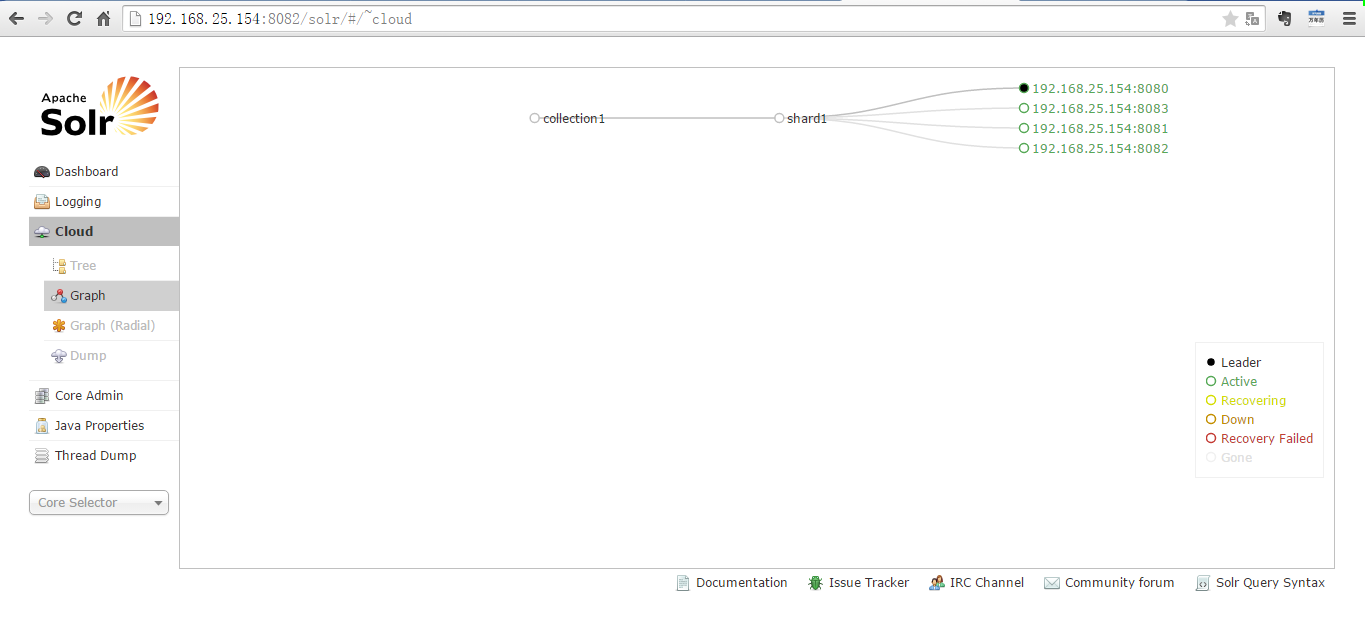
一个主节点多个备份节点,集群只有一片。
1.6.5 第五步
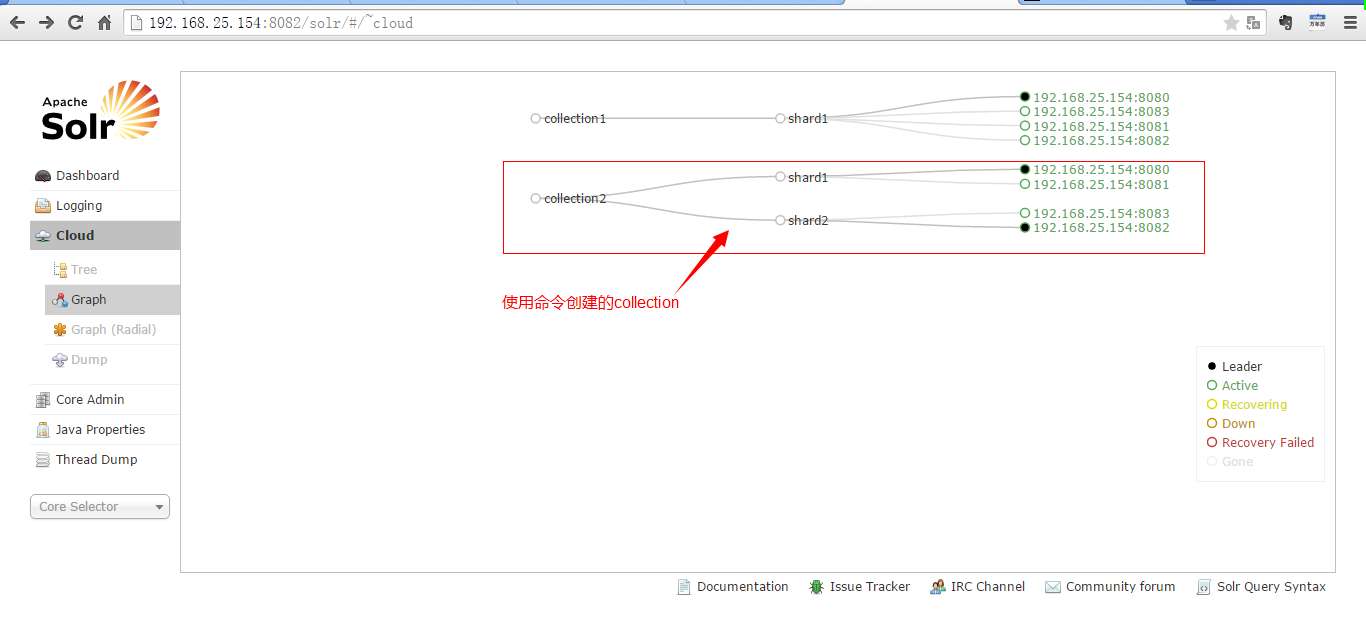
创建一个两片的collection,每片是一主一备。
在浏览器地址栏使用以下命令创建:
http://192.168.25.154:8080/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2
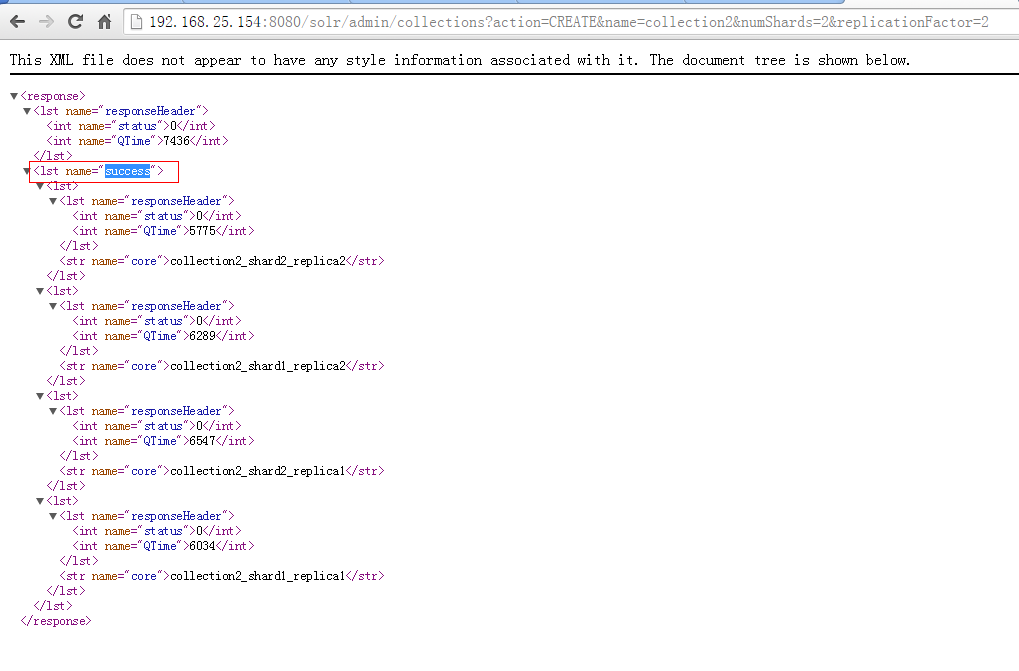
1.6.6 第六步
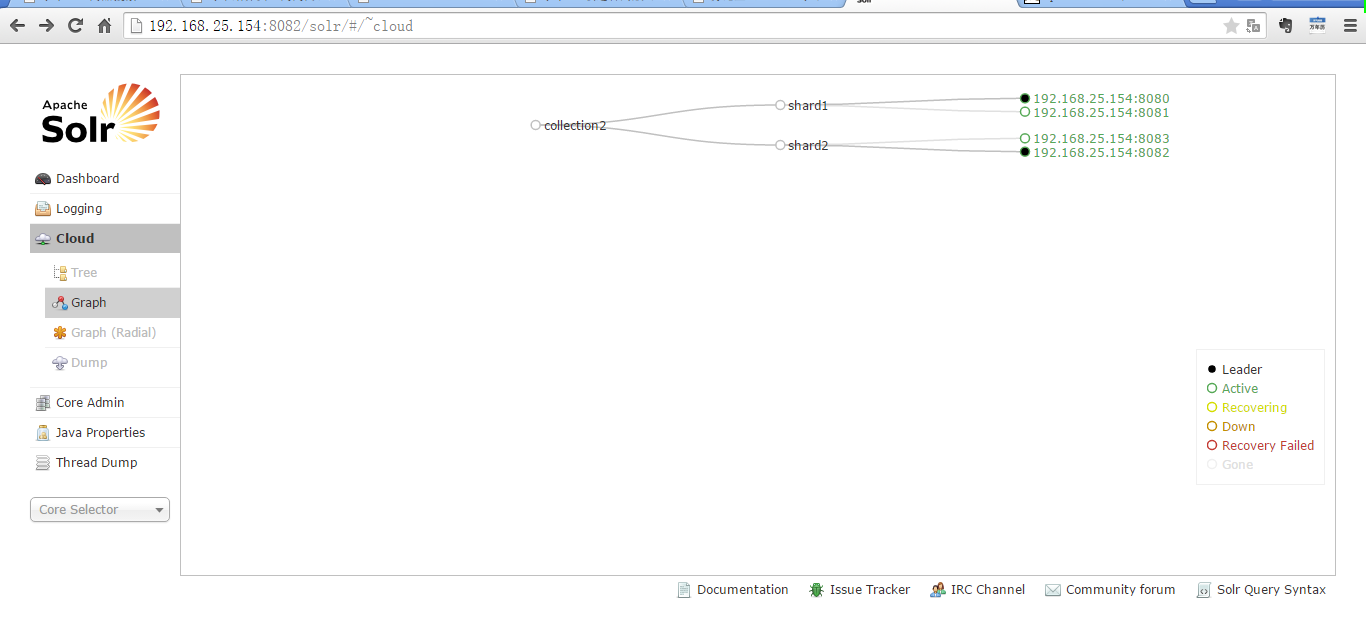
删除collection1.
http://192.168.25.154:8080/solr/admin/collections?action=DELETE&name=collection1

2 Solr集群的使用
使用solrj操作集群环境的索引库。
2.1 Solrj测试
|
public class SolrCloudTest { @Test public void testAddDocument() throws Exception { //创建一个和solr集群的连接 //参数就是zookeeper的地址列表,使用逗号分隔 String zkHost = "192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183"; CloudSolrServer solrServer = new CloudSolrServer(zkHost); //设置默认的collection solrServer.setDefaultCollection("collection2"); //创建一个文档对象 SolrInputDocument document = new SolrInputDocument(); //向文档中添加域 document.addField("id", "test001"); document.addField("item_title", "测试商品"); //把文档添加到索引库 solrServer.add(document); //提交 solrServer.commit(); } @Test public void deleteDocument() throws SolrServerException, IOException { //创建一个和solr集群的连接 //参数就是zookeeper的地址列表,使用逗号分隔 String zkHost = "192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183"; CloudSolrServer solrServer = new CloudSolrServer(zkHost); //设置默认的collection solrServer.setDefaultCollection("collection2"); solrServer.deleteByQuery("*:*"); solrServer.commit(); } } |
2.2 Solrj和spring集成
修改spring的配置文件,添加集群版的配置:
|
<!-- 集群版 --> <bean id="cloudSolrServer" class="org.apache.solr.client.solrj.impl.CloudSolrServer"> <constructor-arg name="zkHost" value="192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183"></constructor-arg> <property name="defaultCollection" value="collection2"></property> </bean> |
SolrCloud 高可用集群搭建的更多相关文章
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- MongoDB高可用集群搭建(主从、分片、路由、安全验证)
目录 一.环境准备 1.部署图 2.模块介绍 3.服务器准备 二.环境变量 1.准备三台集群 2.安装解压 3.配置环境变量 三.集群搭建 1.新建配置目录 2.修改配置文件 3.分发其他节点 4.批 ...
- RabbitMQ高级指南:从配置、使用到高可用集群搭建
本文大纲: 1. RabbitMQ简介 2. RabbitMQ安装与配置 3. C# 如何使用RabbitMQ 4. 几种Exchange模式 5. RPC 远程过程调用 6. RabbitMQ高可用 ...
- spring cloud 服务注册中心eureka高可用集群搭建
spring cloud 服务注册中心eureka高可用集群搭建 一,准备工作 eureka可以类比zookeeper,本文用三台机器搭建集群,也就是说要启动三个eureka注册中心 1 本文三台eu ...
- MongoDB 3.4 高可用集群搭建(二)replica set 副本集
转自:http://www.lanceyan.com/tech/mongodb/mongodb_repset1.html 在上一篇文章<MongoDB 3.4 高可用集群搭建(一):主从模式&g ...
- Hbase 完全分布式 高可用 集群搭建
1.准备 Hadoop 版本:2.7.7 ZooKeeper 版本:3.4.14 Hbase 版本:2.0.5 四台主机: s0, s1, s2, s3 搭建目标如下: HMaster:s0,s1(备 ...
随机推荐
- 学习go语言第二天-变量、常量
编写测试程序 源码文件以_test结尾;例如:xxx_test.go 测试方法名以Test开头;例如:func TestXXXXX(t *testing.T){} 实现斐波那且数列 package f ...
- HDU3247 Resource Archiver (AC自动机+spfa+状压DP)
Great! Your new software is almost finished! The only thing left to do is archiving all your n resou ...
- 矩阵解压,网络流UESTC-1962天才钱vs学霸周2
天才钱vs学霸周2 Time Limit: 500 MS Memory Limit: 128 MB Submit Status 由于上次的游戏中学霸周输了,因此学霸周想出个问题为难天才钱,问题 ...
- ARTS-S centos查看端口被哪个进程占用
netstat -tunlp | grep 80 或者 lsof -i:80
- DENEBOLA (See3CAM_CX3RDK) - CX3 Reference Design
Denebola (See3CAM_CX3RDK) is a USB3.0 USB video class (UVC) reference design kit (RDK) developed by ...
- Day 05 作业
目录 作业 输入姑娘的年龄后,进行以下判断: 复习while循环,打印1-100之间的奇数和 复习while循环,猜年龄游戏升级版,有以下三点要求: 作业 输入姑娘的年龄后,进行以下判断: 如果姑娘小 ...
- JS基础-this
this this的指向有哪几种情况? this代表函数调用相关联的对象,通常页称之为执行上下文. 作为函数直接调用,非严格模式下,this指向window,严格模式下,this指向undefined ...
- TOMCAT_server.xml
该文件描述了如何启动Tomcat Server <Server> <Listener /> <GlobaNamingResources> < ...
- python基础知识第七篇(练习)
# a. 获取内容相同的元素列表 l1 = [11,22,33] l2 = [22,33,44] for l in l1: if l in l2: print(l) # b. 获取 l1 中有, l2 ...
- 添加junit和spring-test还是用不了@Test和@RunWith(SpringJUnit4ClassRunner.class)注解
pom.xml依赖如下 <!-- spring 单元测试组件包 --> <dependency> <groupId>org.springframework</ ...