Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
前言
今天上午被 Flink 的一个算子困惑了下,具体问题是什么呢?
我有这么个需求:有不同种类型的告警数据流(包含恢复数据),然后我要将这些数据流做一个拆分,拆分后的话,每种告警里面的数据又想将告警数据和恢复数据拆分出来。
结果,这个需求用 Flink 的 Split 运算符出现了问题。
分析
需求如下图所示:
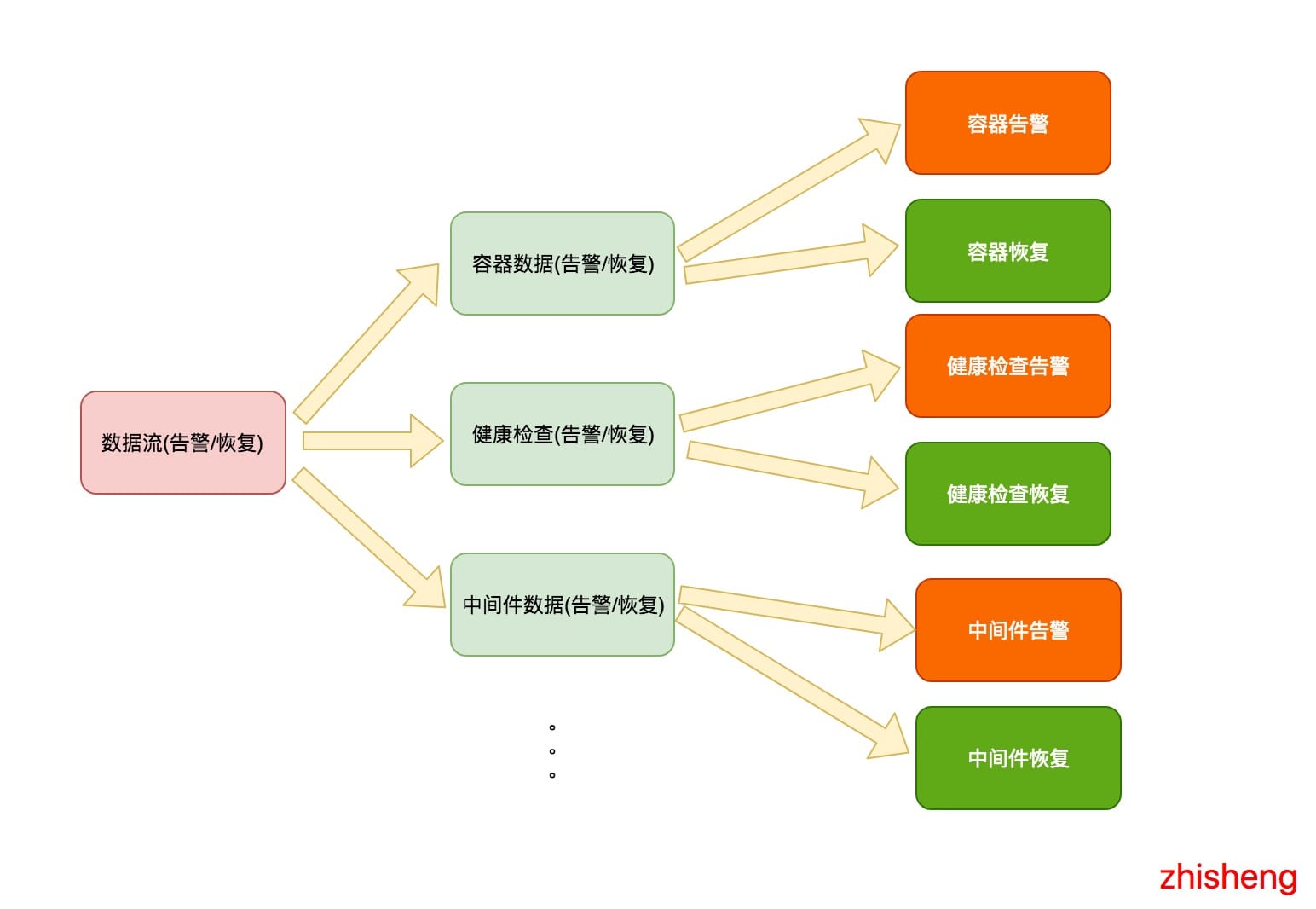
我是期望如上这样将数据流进行拆分的,最后将每种告警和恢复用不同的消息模版做一个渲染,渲染后再通过各种其他的方式(钉钉群
邮件、短信)进行告警通知。
于是我的代码大概的结构如下代码所示:
//dataStream 是总的数据流
//split 是拆分后的数据流
SplitStream<AlertEvent> split = dataStream.split(new OutputSelector<AlertEvent>() {
@Override
public Iterable<String> select(AlertEvent value) {
List<String> tags = new ArrayList<>();
switch (value.getType()) {
case MIDDLEWARE:
tags.add(MIDDLEWARE);
break;
case HEALTH_CHECK:
tags.add(HEALTH_CHECK);
break;
case DOCKER:
tags.add(DOCKER);
break;
//...
//当然这里还可以很多种类型
}
return tags;
}
});
//然后你想获取每种不同的数据类型,你可以使用 select
DataStream<AlertEvent> middleware = split.select(MIDDLEWARE); //选出中间件的数据流
//然后你又要将中间件的数据流分流成告警和恢复
SplitStream<AlertEvent> middlewareSplit = middleware.split(new OutputSelector<AlertEvent>() {
@Override
public Iterable<String> select(AlertEvent value) {
List<String> tags = new ArrayList<>();
if(value.isRecover()) {
tags.add(RECOVER)
} else {
tags.add(ALERT)
}
return tags;
}
});
middlewareSplit.select(ALERT).print();
DataStream<AlertEvent> healthCheck = split.select(HEALTH_CHECK); //选出健康检查的数据流
//然后你又要将健康检查的数据流分流成告警和恢复
SplitStream<AlertEvent> healthCheckSplit = healthCheck.split(new OutputSelector<AlertEvent>() {
@Override
public Iterable<String> select(AlertEvent value) {
List<String> tags = new ArrayList<>();
if(value.isRecover()) {
tags.add(RECOVER)
} else {
tags.add(ALERT)
}
return tags;
}
});
healthCheckSplit.select(ALERT).print();
DataStream<AlertEvent> docekr = split.select(DOCKER); //选出容器的数据流
//然后你又要将容器的数据流分流成告警和恢复
SplitStream<AlertEvent> dockerSplit = docekr.split(new OutputSelector<AlertEvent>() {
@Override
public Iterable<String> select(AlertEvent value) {
List<String> tags = new ArrayList<>();
if(value.isRecover()) {
tags.add(RECOVER)
} else {
tags.add(ALERT)
}
return tags;
}
});
dockerSplit.select(ALERT).print();
结构我抽象后大概就长上面这样,然后我先本地测试的时候只把容器的数据那块代码打开了,其他种告警的分流代码注释掉了,一运行,发现竟然容器告警的数据怎么还掺杂着健康检查的数据也一起打印出来了,一开始我以为自己出了啥问题,就再起码运行了三遍 IDEA 才发现结果一直都是这样的。
于是,我只好在第二步分流前将 docekr 数据流打印出来,发现是没什么问题,打印出来的数据都是容器相关的,没有掺杂着其他种的数据啊。这会儿遍陷入了沉思,懵逼发呆了一会。
解决问题
于是还是开始面向 Google 编程:


发现第一条就找到答案了,简直不要太快,点进去可以看到他也有这样的需求:
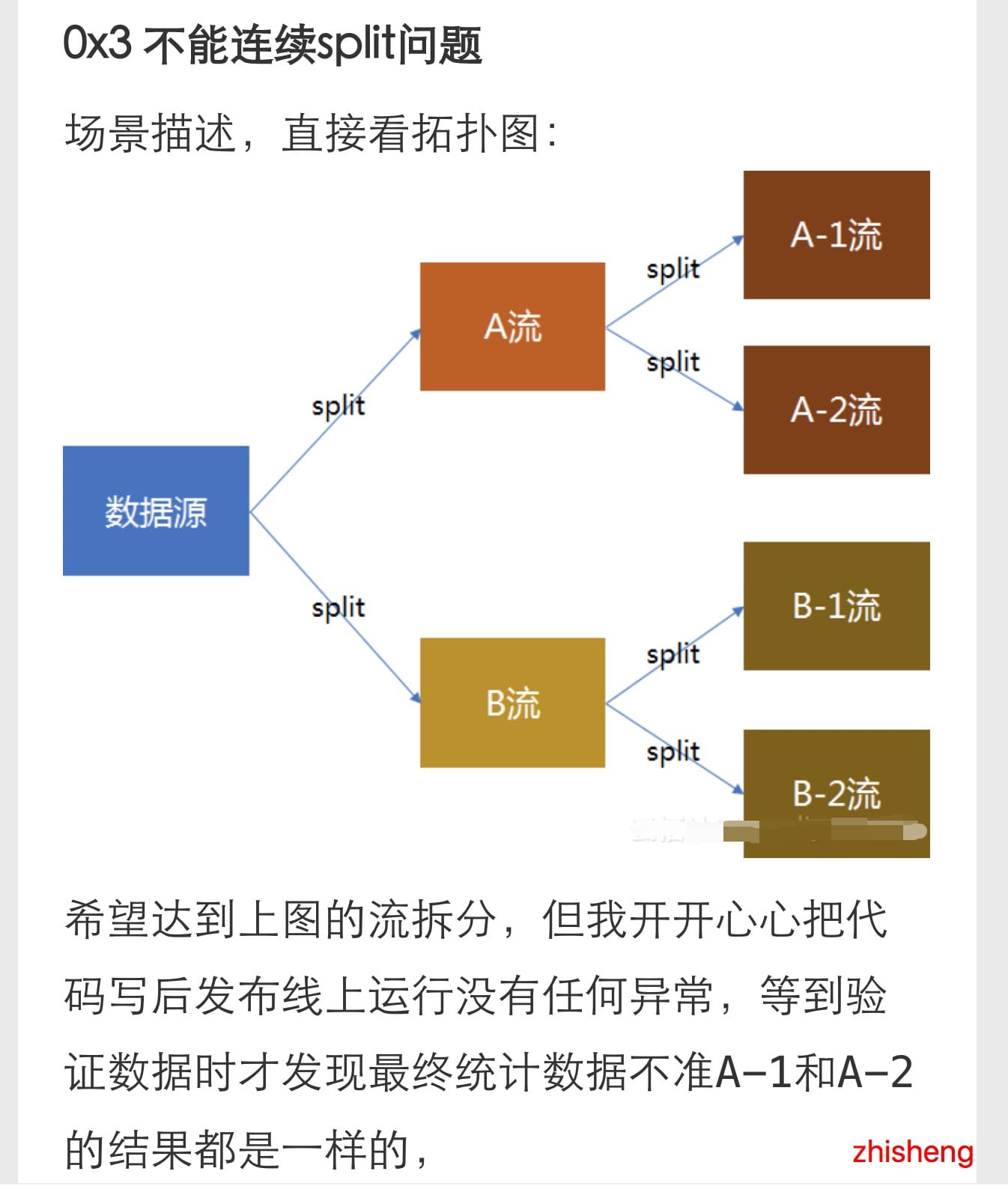
然后这个小伙伴还挣扎了下用不同的方法(虽然结果更惨):

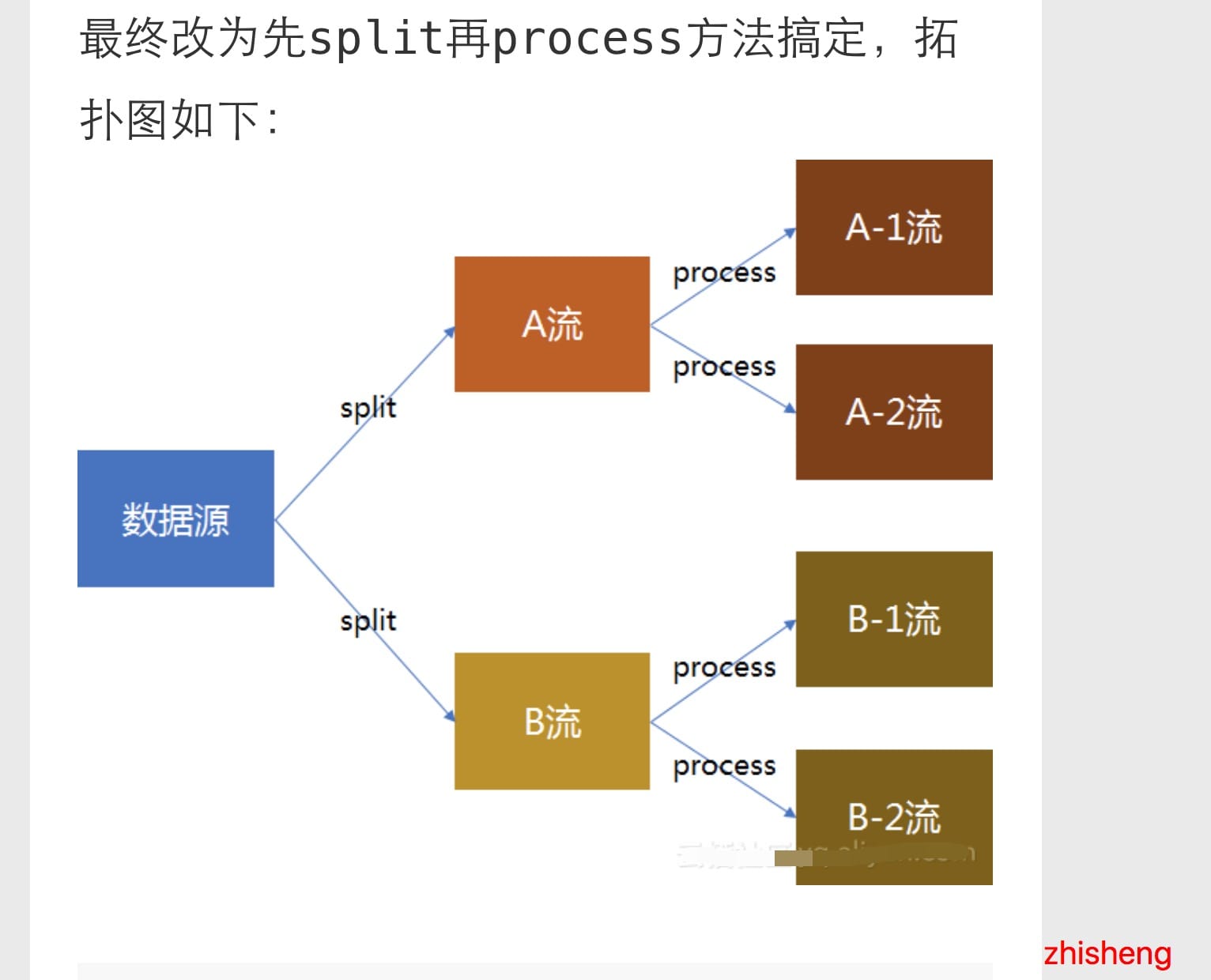
最后换了个姿势就好了(果然小伙子会的姿势挺多的):
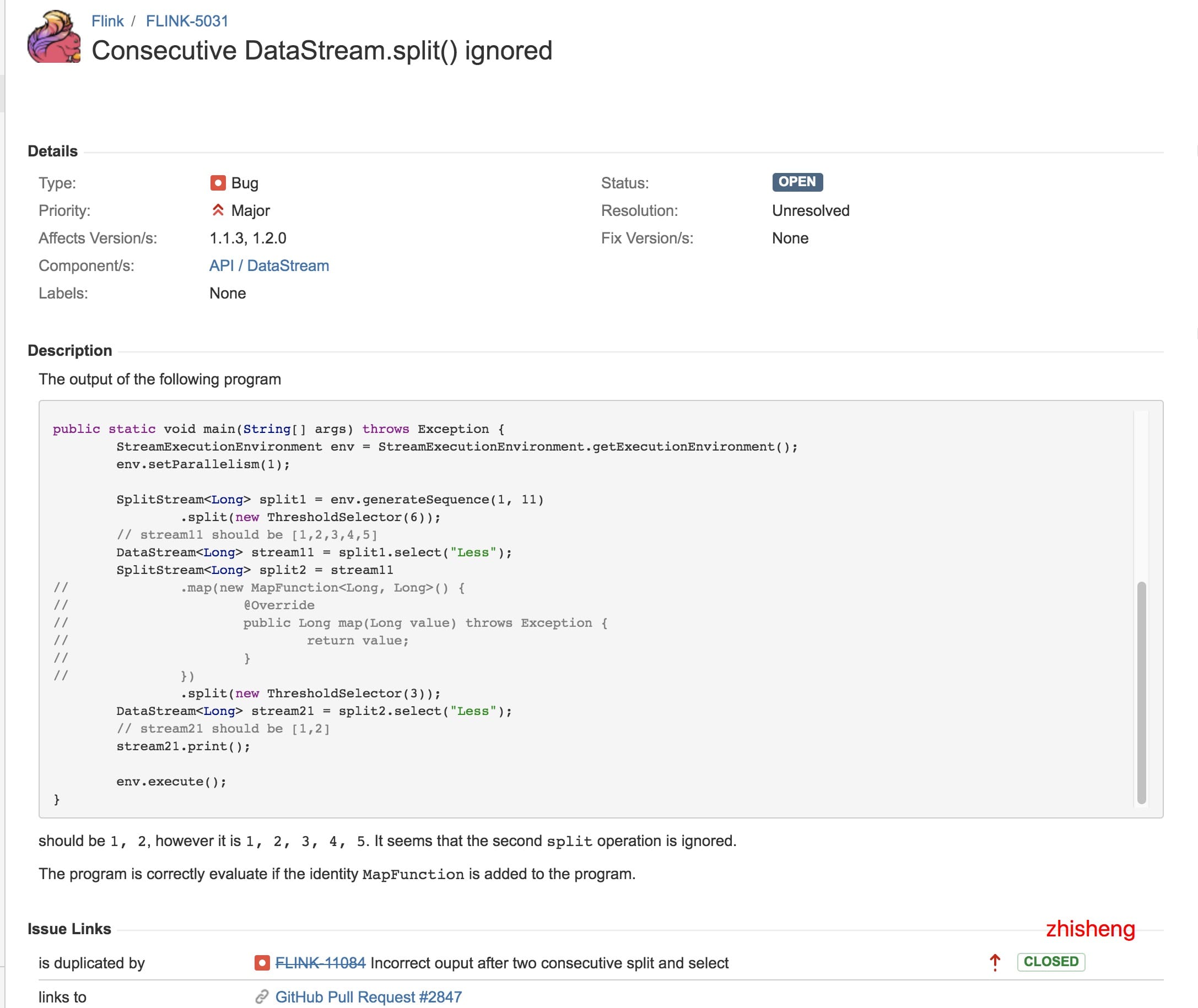
但从这篇文章中,我找到了关联到的两个 Flink Issue,分别是:
1、https://issues.apache.org/jira/browse/FLINK-5031
2、https://issues.apache.org/jira/browse/FLINK-11084
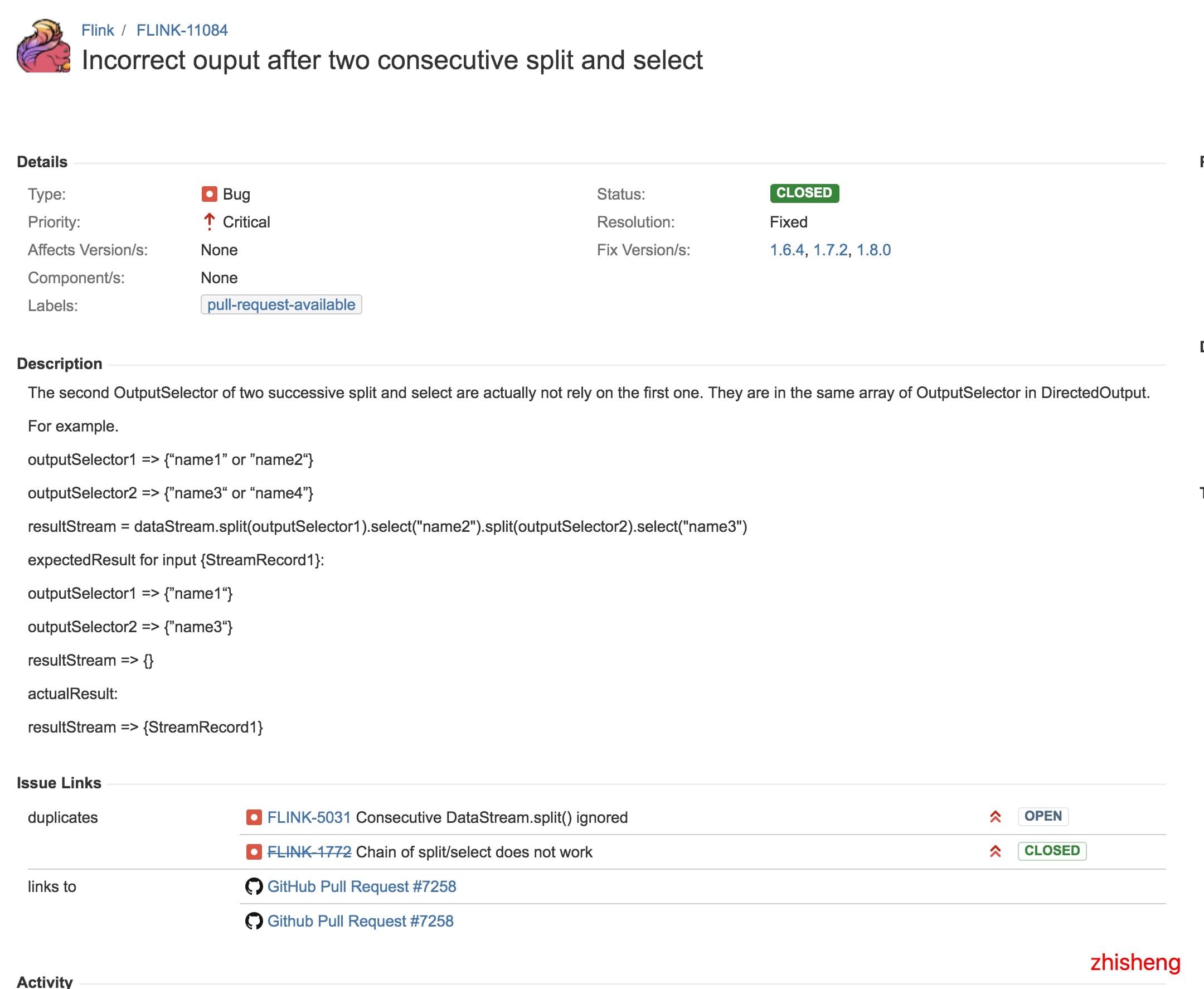
然后呢,从第二个 Issue 的讨论中我发现了一些很有趣的讨论:
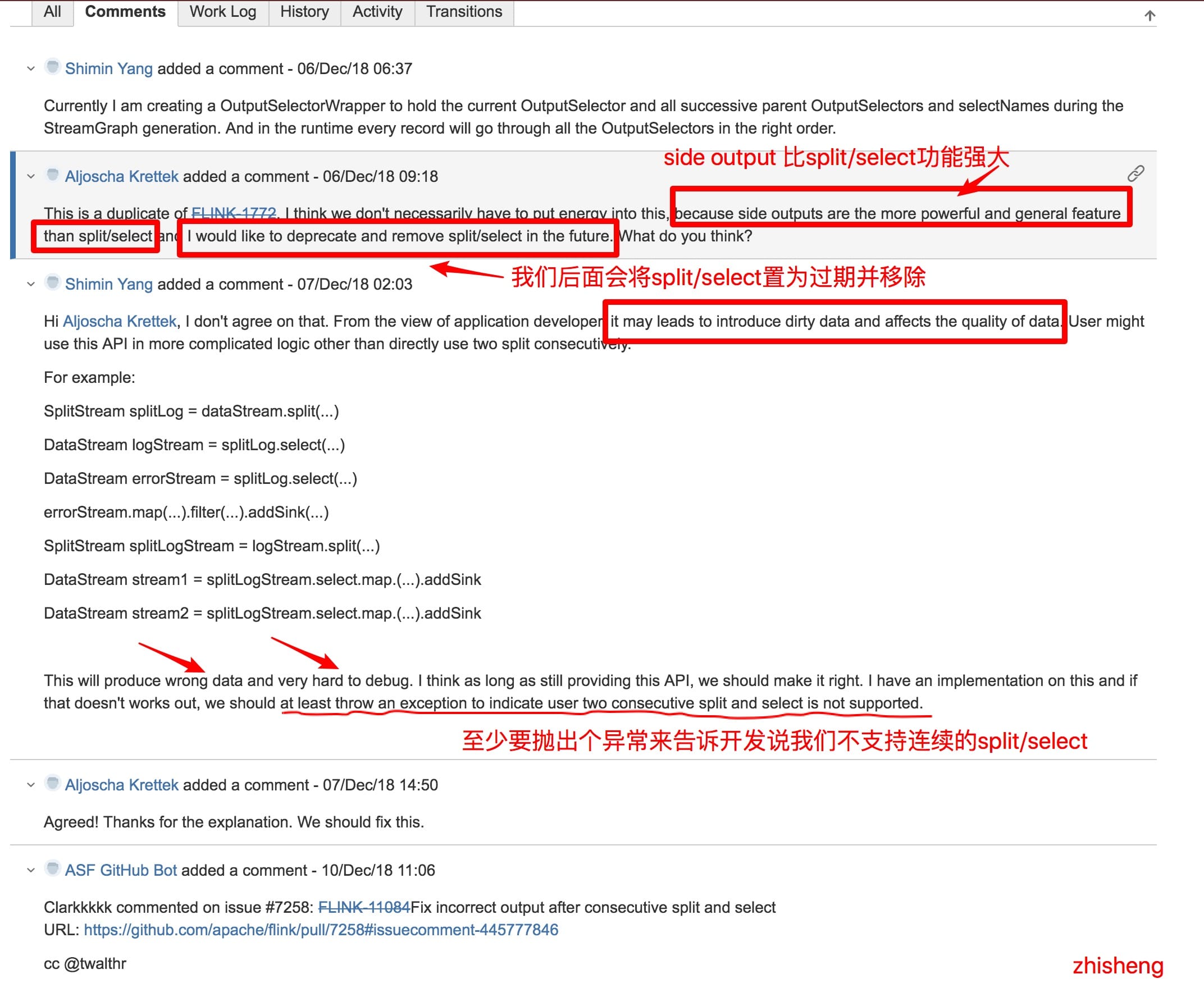
对话很有趣,但是我突然想到之前我的知识星球里面一位很细心的小伙伴问的一个问题了:
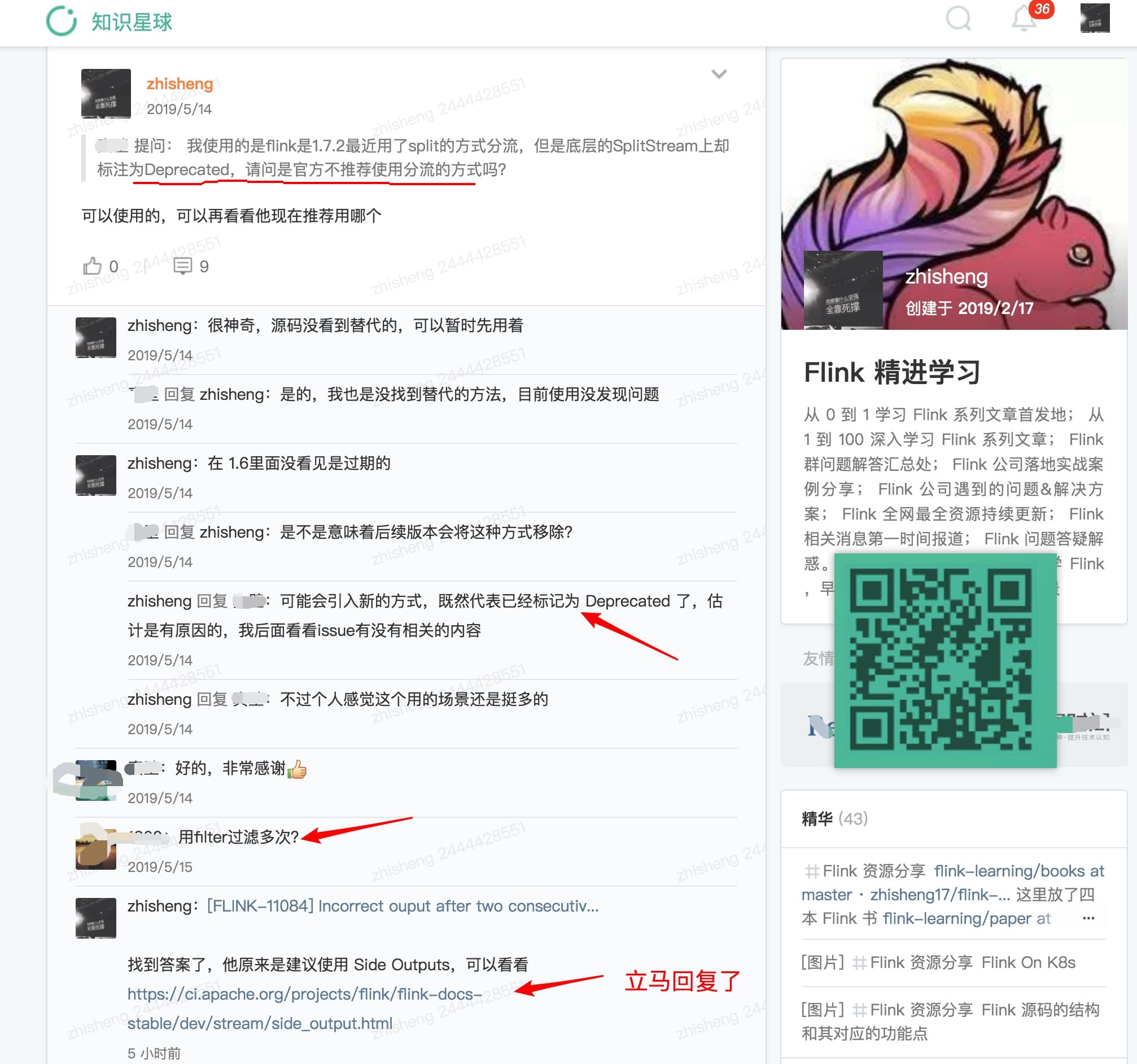
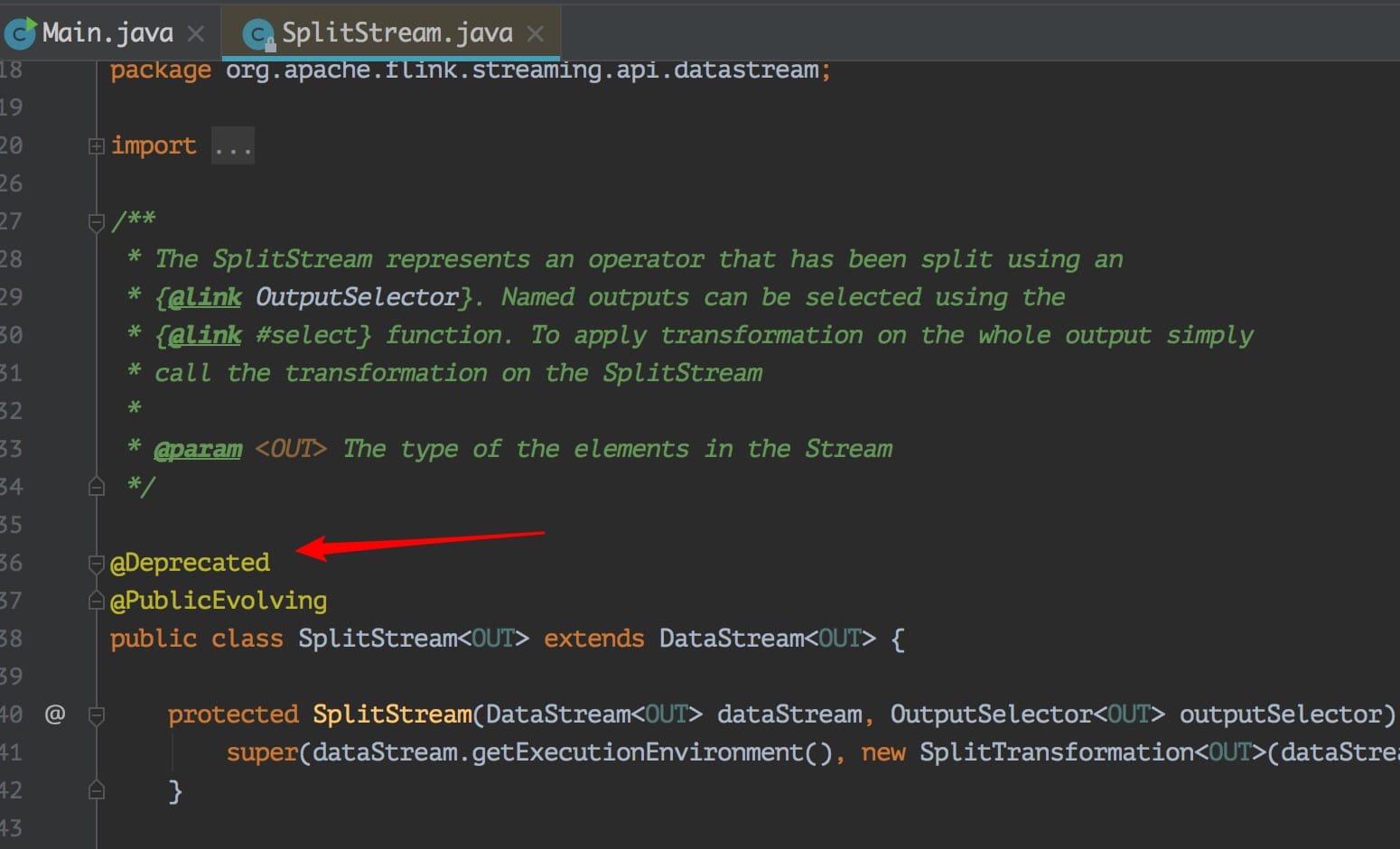
可以发现代码上确实是标明了过期了,但是注释里面没写清楚推荐用啥,幸好我看到了这个 Issue,不然脑子里面估计这个问题一直会存着呢。
那么这个问题解决方法是不是意味着就可以利用 Side Outputs 来解决呢?当然可以啦,官方都推荐了,还不能都话,那么不是打脸啪啪啪的响吗?不过这里还是卖个关子将 Side Outputs 后面专门用一篇文章来讲,感兴趣的可以先看看官网介绍:https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/side_output.html
另外其实也可以通过 split + filter 组合来解决这个问题,反正关键就是不要连续的用 split 来分流。
用 split + filter 的方案代码大概如下:
DataStream<AlertEvent> docekr = split.select(DOCKER); //选出容器的数据流
//容器告警的数据流
docekr.filter(new FilterFunction<AlertEvent>() {
@Override
public boolean filter(AlertEvent value) throws Exception {
return !value.isRecover();
}
})
.print();
//容器恢复的数据流
docekr.filter(new FilterFunction<AlertEvent>() {
@Override
public boolean filter(AlertEvent value) throws Exception {
return value.isRecover();
}
})
.print();
上面这种就是多次 filter 也可以满足需求,但是就是代码有点啰嗦。
总结
Flink 中不支持连续的 Split/Select 分流操作,要实现连续分流也可以通过其他的方式(split + filter 或者 side output)来实现
本篇文章连接是:http://www.54tianzhisheng.cn/2019/06/12/flink-split/
关注我
微信公众号:zhisheng
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号了。你可以加我的微信:zhisheng_tian,然后回复关键字:Flink 即可无条件获取到。

更多私密资料请加入知识星球!

Github 代码仓库
https://github.com/zhisheng17/flink-learning/
以后这个项目的所有代码都将放在这个仓库里,包含了自己学习 flink 的一些 demo 和博客。
Flink 实战
1、Flink 从0到1学习—— Apache Flink 介绍
2、Flink 从0到1学习—— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
4、Flink 从0到1学习—— Data Source 介绍
5、Flink 从0到1学习—— 如何自定义 Data Source ?
7、Flink 从0到1学习—— 如何自定义 Data Sink ?
8、Flink 从0到1学习—— Flink Data transformation(转换)
9、Flink 从0到1学习—— 介绍Flink中的Stream Windows
10、Flink 从0到1学习—— Flink 中的几种 Time 详解
11、Flink 从0到1学习—— Flink 写入数据到 ElasticSearch
12、Flink 从0到1学习—— Flink 项目如何运行?
13、Flink 从0到1学习—— Flink 写入数据到 Kafka
14、Flink 从0到1学习—— Flink JobManager 高可用性配置
15、Flink 从0到1学习—— Flink parallelism 和 Slot 介绍
16、Flink 从0到1学习—— Flink 读取 Kafka 数据批量写入到 MySQL
17、Flink 从0到1学习—— Flink 读取 Kafka 数据写入到 RabbitMQ
18、Flink 从0到1学习》—— 你上传的 jar 包藏到哪里去了?
19、Flink 从0到1学习 —— Flink 中如何管理配置?
源码解析
4、Flink 源码解析 —— standalonesession 模式启动流程
5、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动
6、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动
7、Flink 源码解析 —— 分析 Batch WordCount 程序的执行过程
8、Flink 源码解析 —— 分析 Streaming WordCount 程序的执行过程
9、Flink 源码解析 —— 如何获取 JobGraph?
10、Flink 源码解析 —— 如何获取 StreamGraph?
11、Flink 源码解析 —— Flink JobManager 有什么作用?
12、Flink 源码解析 —— Flink TaskManager 有什么作用?
13、Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
14、Flink 源码解析 —— TaskManager 处理 SubmitJob 的过程
15、Flink 源码解析 —— 深度解析 Flink Checkpoint 机制
16、Flink 源码解析 —— 深度解析 Flink 序列化机制
17、Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?原文出处:zhisheng的博客,欢迎关注我的公众号:zhisheng
Flink 从0到1学习—— Flink 不可以连续 Split(分流)?的更多相关文章
- Flink 从0到1学习 —— Flink 中如何管理配置?
前言 如果你了解 Apache Flink 的话,那么你应该熟悉该如何像 Flink 发送数据或者如何从 Flink 获取数据.但是在某些情况下,我们需要将配置数据发送到 Flink 集群并从中接收一 ...
- Flink 从 0 到 1 学习 —— Flink 配置文件详解
前面文章我们已经知道 Flink 是什么东西了,安装好 Flink 后,我们再来看下安装路径下的配置文件吧. 安装目录下主要有 flink-conf.yaml 配置.日志的配置文件.zk 配置.Fli ...
- Flink 从 0 到 1 学习 —— Flink Data transformation(转换)
toc: true title: Flink 从 0 到 1 学习 -- Flink Data transformation(转换) date: 2018-11-04 tags: Flink 大数据 ...
- Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
前言 之前也分享了不少自己的文章,但是对于 Flink 来说,还是有不少新入门的朋友,这里给大家分享点 Flink 相关的资料(国外数据 pdf 和流处理相关的 Paper),期望可以帮你更好的理解 ...
- Flink 从 0 到 1 学习 —— 如何自定义 Data Sink ?
前言 前篇文章 <从0到1学习Flink>-- Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢 ...
- Flink 从 0 到 1 学习 —— 如何自定义 Data Source ?
前言 在 <从0到1学习Flink>-- Data Source 介绍 文章中,我给大家介绍了 Flink Data Source 以及简短的介绍了一下自定义 Data Source,这篇 ...
- 《从0到1学习Flink》—— Flink 写入数据到 Kafka
前言 之前文章 <从0到1学习Flink>-- Flink 写入数据到 ElasticSearch 写了如何将 Kafka 中的数据存储到 ElasticSearch 中,里面其实就已经用 ...
- 《从0到1学习Flink》—— Flink 项目如何运行?
前言 之前写了不少 Flink 文章了,也有不少 demo,但是文章写的时候都是在本地直接运行 Main 类的 main 方法,其实 Flink 是支持在 UI 上上传 Flink Job 的 jar ...
- 《从0到1学习Flink》—— Flink 写入数据到 ElasticSearch
前言 前面 FLink 的文章中我们已经介绍了说 Flink 已经有很多自带的 Connector. 1.<从0到1学习Flink>-- Data Source 介绍 2.<从0到1 ...
随机推荐
- VS2010下编译配置Boost_1.53
一.准备工作 1.下载最新版本的boost库.所在地址:boost_1_53_0.zip.官方推荐7z压缩格式的,因为其压缩效率更好,相应包的大小也比较小. 2.解压缩到指定目录,如C:\boost_ ...
- Qt Style Sheet实践(二):组合框QComboBox的定制(24K纯开源)——非常漂亮
组合框是一个重要且应用广泛的组件,一般由两个子组件组成:文本下拉单部分和按钮部分.在许多既需要用户选择.又需要用户手动输入的应用场景下,组合框能够很好的满足我们的需求.如我们经常使用的聊天软件QQ登录 ...
- C++ 王者归来:对编程语言的需求总结为四个:效率,灵活,抽象,生产率(C++玩的是前三个,Java和C#玩的是后两个)
Why C++ ? 王者归来(转载) 因为又有人邀请我去Quora的C2C网站去回答问题去了,这回是 关于 @laiyonghao 的这篇有点争议的博文<2012 不宜进入的三个技术点>A ...
- Codility---MaxProductOfThree
Task description A non-empty zero-indexed array A consisting of N integers is given. Theproduct of t ...
- [2017.02.21-22] 《Haskell趣学指南 —— Learning You a Haskell for Great Good!》
{- 2017.02.21-22 <Haskell趣学指南 -- Learning You a Haskell for Great Good!> 学习了Haskell的基本语法,并实现了一 ...
- Tido c++线段树知识讲解(转载)
线段树知识讲解 定义.建树.单点修改.区间查询 特别声明:如上的讲解说的是区间最大值 如果想要查询区间和 只需要改变一下建树和查询的代码就行了,如下 其他根据自己的需要进行修改即可
- What?Tomcat-竟然也算中间件?
关于 MyCat 的铺垫文章已经写了两篇了: MySQL 只能做小项目?松哥要说几句公道话! 北冥有 Data,其名为鲲,鲲之大,一个 MySQL 放不下! 今天是最后一次铺垫,后面就可以迎接大 Bo ...
- 【Dubbo】Dubbo+ZK基础入门以及简单demo
参考文档: 官方文档:http://dubbo.io/ duboo中文:https://dubbo.gitbooks.io/dubbo-user-book/content/preface/backgr ...
- CI控制器
当控制器要继承自定义的控制器的时候,有特定的定义: application/core/MY_Controller <?php class MY_Controller extends CI_Con ...
- .NetCore中三种注入方式的思考
该篇内容由个人博客点击跳转同步更新!转载请注明出处! .NetCore彻底诠释了"万物皆可注入"这句话的含义,在.NetCore中到处可见注入的使用.因此core中也提供了三种注入 ...