G1 collector 介绍
背景:由于CMS算法产生空间碎片和其它一系列的问题缺陷,HotSpot提供了另外一种垃圾回收策略,G1(也就是Garbage First)算法,该算法在JDK7u4版本被正式推出,官网对此描述如下:
- Can operate concurrently with applications threads like the CMS collector.
- Compact free space without lengthy GC induced pause times.
- Need more predictable GC pause durations.
- Do not want to sacrifice a lot of throughput performance.
- Do not require a much larger Java heap.
G1 is planned as the long term replacement for the Concurrent Mark-Sweep Collector (CMS). Comparing G1 with CMS, there are differences that make G1 a better solution. One difference is that G1 is a compacting collector. G1 compacts sufficiently to completely avoid the use of fine-grained free lists for allocation, and instead relies on regions. This considerably simplifies parts of the collector, and mostly eliminates potential fragmentation issues. Also, G1 offers more predictable garbage collection pauses than the CMS collector, and allows users to specify desired pause targets.
G1 Collector 是一种server风格的垃圾回收器,针对具有大内存、多cpu的机器。它在满足高吞吐量的同时,又尽可能的实现较低的GC时间,G1 Collector 主要针对以下场景:
- 像CMS一样,垃圾回收线程和应用线程并发执行
- 压缩空闲内存,避免GC导致长时间的暂停
- 能够对GC暂停时间有更好的预测
- 不希望牺牲太多的吞吐性能
- 希望可以尽可能的控制堆的大小(G1本身就是针对大堆的,一般认为4-6G以上为大堆,所以这里的大小我个人理解为在此基础上)
对于之前的garbage collectors来说(比如最早的serial、后来的parallel、CMS),它们都将堆划分成了三个部分:新生代,老年代,永久代(元空间)
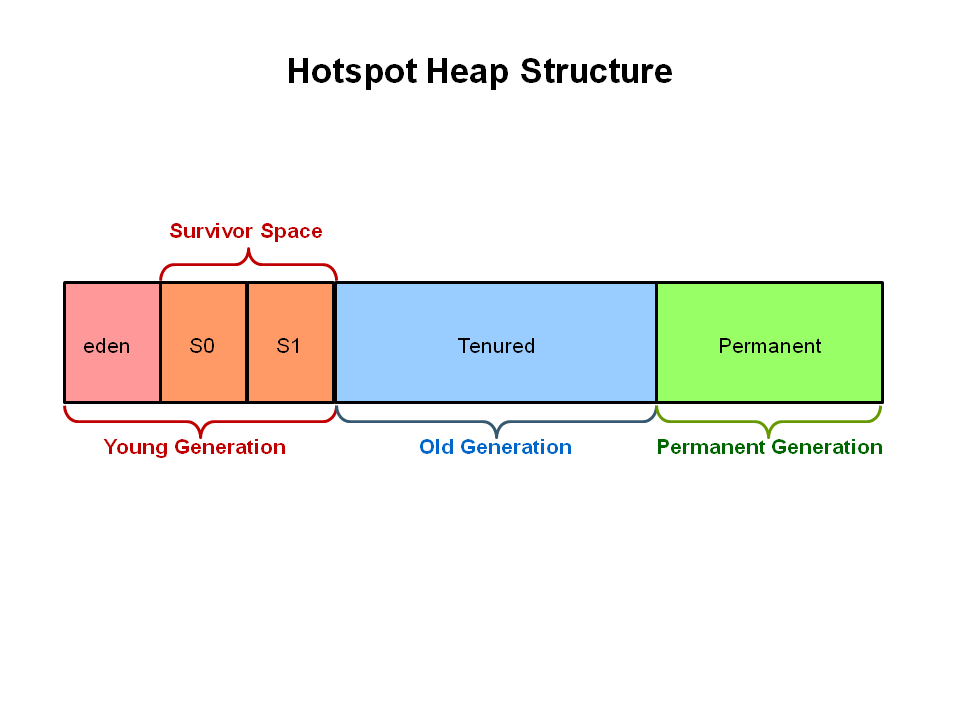
G1不同,G1算法将堆划分为若干个Region,它仍然是划分代的。并且默认情况下是将堆内存划分2048份,每个region的大小也就是heap size/2048,但是region的大小只能为1M、2M、4M、8M、16M和32M,总之是2的幂次方,一般会生成2000左右个region
1. G1 Heap Structure

2. G1 Heap Allocation

如上图所示,这些region被定义为eden、survivor、old generation 逻辑上为连续的内存空间。其中eden、survivor、old generation跟以往的GC收集器一样,此外还有一个Humongous区是以往算法所没有的, 如果一个对象占用的空间超过了区域容量50%以上,G1收集器就认为这是一个巨型对象。这些巨型对象,默认直接会被分配在年老代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。
3. Young Generation in G1
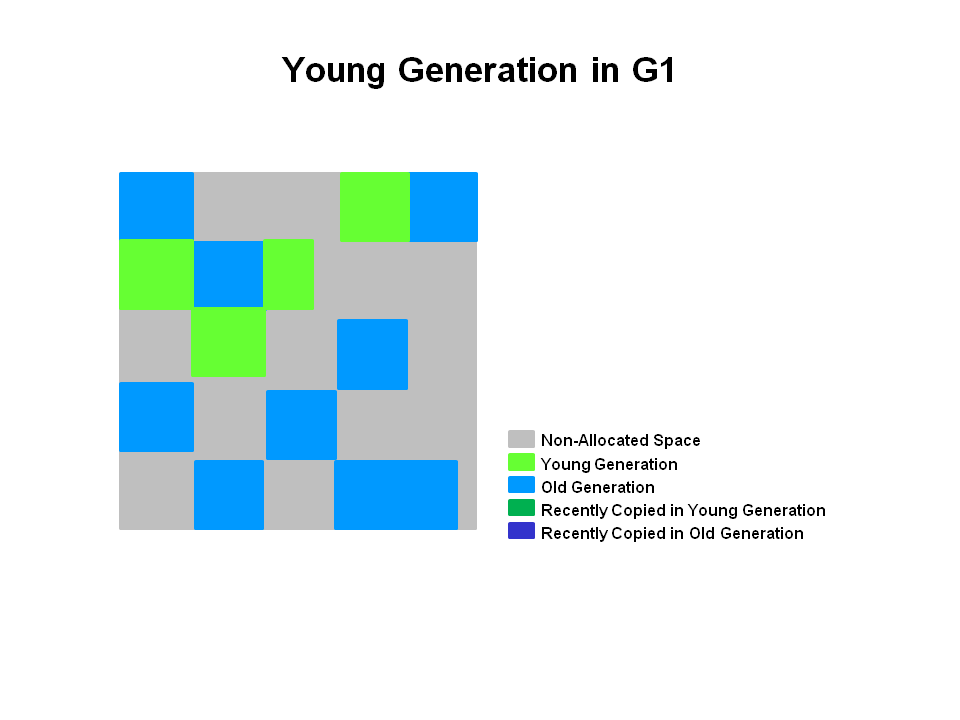
4. A Young GC in G1
存活的对象被拷贝到一个或多个survivor region中,如果某些对象的age达到了晋升老年代要求的阀值,就会晋升到老年代。(跟之前的算法差不多),G1 young gc属于stop the world (STW)性质,并且在此期间,eden region的数量和survivor region的数量会通过新一轮的计算(也就是region的数量是在动态变化的),以适应下一轮的GC更好的达到期望的暂停时间。

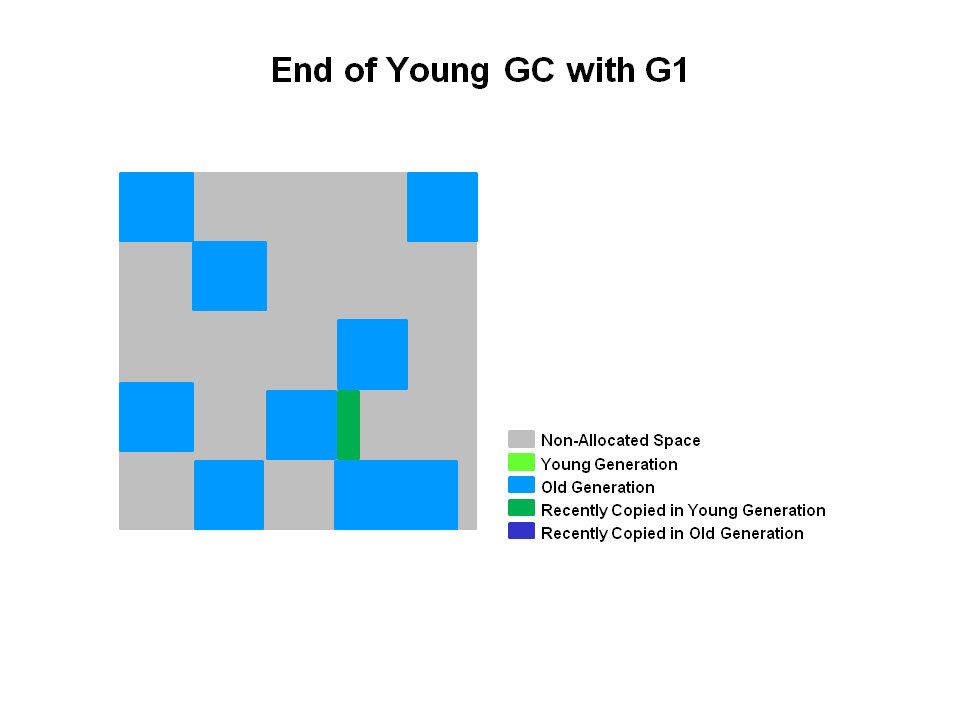
5. End of a Young GC with G1
存活的对象被疏散到survivor region中或者old generation region,晋升的对象由下图中暗色部分表示,蓝色的代表Survivor regions
Old Generation Collection with G1
当越来越多的对象晋升到老年代old region时,为了避免堆内存被耗尽,会触发Old Generation Collection(也可称为mixed gc),G1的old gc跟以前算法的old gc不太一样,G1 old gc是在回收整个young region的同时,还会回收一部分的old region,这里需要注意,是一部分old region,而不是全部,G1算法选择部分old region进行回收,从而可以对垃圾回收的耗时时间进行控制。触发条件:-XX:InitiatingHeapOccupancyPercent=n 当老年代大小占整个堆大小百分比达到该阈值时,会触发一次old gc
old gc执行流程:
1. initial mark: 整个过程STW,标记了从GC Root可达的对象
2. concurrent marking: 并发标记过程,整个过程gc collector线程与应用线程并行执行,找出整个堆中的存活对象
3. remark: 整个过程STW,最终标记,使用snapshot-at-the-beginning (SATB)算法(much faster than CMS use)标记出那些在并发标记过程中遗漏的,
或者内部引用发生变化的对象
4. clean up: 该过程部分是STW处理,部分是并行处理
1.统计存活对象和完全空闲的region(STW)
2.清空Remembered Sets(STW)
3.将空region加入到空闲列表中(并发)
5.Copying:整个过程STW,拷贝存活对象到新的region中
Full GC
- 并发模式失败
- 晋升失败或者疏散失败
- 增加 -XX:G1ReservePercent 选项的值(并相应增加总的堆大小),为“目标空间”增加预留内存量。
- 通过减少 -XX:InitiatingHeapOccupancyPercent 提前启动标记周期。
- 也可以通过增加 -XX:ConcGCThreads 选项的值来增加并行标记线程的数目。
- 巨型对象分配失败
G1 collector 介绍的更多相关文章
- The The Garbage-First (G1) collector since Oracle JDK 7 update 4 and later releases
Refer to http://www.oracle.com/technetwork/tutorials/tutorials-1876574.html for detail. 一些内容复制到这儿 Th ...
- CMS Collector and G1 Collector
Understanding the CMS Collector CMS has three basic operations: CMS collects the young generation (s ...
- Java Hotspot G1 GC的一些关键技术
G1 GC,全称Garbage-First Garbage Collector,通过-XX:+UseG1GC参数来启用,作为体验版随着JDK 6u14版本面世,在JDK 7u4版本发行时被正式推出,相 ...
- java GC垃圾回收机制G1、CMS
CMS(Concurrent Mark-Sweep)是以牺牲吞吐量为代价来获得最短回收停顿时间.对于要求服务器响应速度的应用上,这种垃圾回收器非常适合.在启动JVM参数加上-XX:+UseConcMa ...
- 弄明白CMS和G1,就靠这一篇了
目录 1 CMS收集器 安全点(Safepoint) 安全区域 2 G1收集器 卡表(Card Table) 3 总结 4 参考 在开始介绍CMS和G1前,我们可以剧透几点: 根据不同分代的特点,收集 ...
- G1垃圾收集器官方文档透彻解读【官方解读】
在前几次中已经对G1的理论进行了一个比较详细的了解了,对于G1垃圾收集器最权威的解读肯定得上官网,当咱们将官网的理解透了,那基本上网上对于G1的说明其实最终都是来自于官网,所以接下来会详细来解读Ora ...
- 提交并发量的方法:Java GC tuning :Garbage collector
三色算法,高效率垃圾回收,jvm调优 Garbage collector:垃圾回收器 What garbage? 没有任何引用指向它的对象 JVM GC回收算法: 引用计数法(ReferenceCou ...
- Garbage Collectors – Serial vs. Parallel vs. CMS vs. G1 (and what’s new in Java 8)
转自:http://blog.takipi.com/garbage-collectors-serial-vs-parallel-vs-cms-vs-the-g1-and-whats-new-in-ja ...
- Garbage Collectors - Serial vs. Parallel vs. CMS vs. G1 (and what's new in Java 8)--转
The 4 Java Garbage Collectors - How the Wrong Choice Dramatically Impacts Performance The year is 20 ...
随机推荐
- MyEclipse2014破解版
百度云:链接:http://pan.baidu.com/s/1c3jKMa 密码:yss0 等版本)后,不要打开软件. 二.解压破解文件压缩包,得到一下文件列表: 三.双击run.bat,即可运行cr ...
- ubuntu root用户 默认密码
ubuntu安装好后,root初始密码(默认密码)不知道,需要设置. 1.先用安装时候的用户登录进入系统 2.输入:sudo passwd 按回车 3.输入新密码,重复输入密码,最后提示passwd ...
- 小白学python-day04-运算符、while循环相关
今天是day04.以下是学习总结. 但行努力,莫问前程. ----------------------------------------------------------------------- ...
- 物联网时代 跟着Thingsboard学IOT架构-CoAP设备协议
thingsboard官网: https://thingsboard.io/ thingsboard GitHub: https://github.com/thingsboard/thingsboar ...
- “$Bitmap 有标记已使用的未用簇”
前几天在电脑上用 DiskGenius 给移动硬盘分区的时候出现了这个错误,如下图所示: 解决方法: 在 cmd 命令行窗口中输入如下代码: chkdsk /f /x c: PS: 其中 " ...
- 一道看似简单的go程序的深入分析
先上代码: func main() { var a [10]int for i := 0; i < 10; i++ { go func(i int) { for { a[i]++ } }(i) ...
- nginx lua集成kafka
NGINX lua集成kafka 第一步:进入opresty目录 [root@node03 openresty]# cd /export/servers/openresty/ [root@node03 ...
- 浅入深出Vue:自动化路由
在软件开发的过程中,"自动化"这个词出现的频率是比较高的.自动化测试,自动化数据映射以及各式的代码生成器.这些词语的背后,也说明了在软件开发的过程中,对于那些重复.千篇一律的事情. ...
- win7 python pdf2image入坑经历
Python开发菜鸟入坑 项目要求pdf转成图片,网上较多的方案对于windows极其不友好,wand,Pythonmagick(win下载地址:www.lfd.uci.edu/~gohlke/pyt ...
- 7、数组中添加元素(test5.java)
前文提到了系统函数,arraycopy(),这是一个强大的函数,根据它的特性便可以看出由于他的特殊性质,加以利用的话,就在数组中添加元素,但这样的方式会造成的结果就是,添加n个元素,那么原数组中倒数n ...