机器学习(1)——K近邻算法
KNN的函数写法
import numpy as np
from math import sqrt
from collections import Counter
def KNN_classify(k,X_train,y_train,x):
assert 1<=k<X_train.shape[0],"k must be valid"
assert X_train.shape[0] == y_train.shape[0],\
"the size of X_train must equal to the size of y_train"
assert X_train.shape[1] == x.shape[0],\
"the feature number of x must be equal to X_train"
distances=[sqrt(np.sum((x_train-x)**2)) for x_train in X_train]
nearest=np.argsort(distances)
topK_y=[y_train[i] for i in nearest[:k]]
votes=Counter(topK_y)
return votes.most_common(1)[0][0] #返回类型
使用scikit-learn中的KNN
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
KNN_classifier=KNeighborsClassifier(n_neighbors=6) #传入k的值
#这里我随便搞的训练数据
x_train=np.arange(0,100).reshape(-1,2) #x是矩阵
y_train=np.random.randint(0,2,50) #y是数组
KNN_classifier.fit(x_train,y_train) #传入训练数据集
x=np.array([1,3]) #测试数据
x=x.reshape(1,-1) #测试数据只能传矩阵为参数
y=KNN_classifier.predict(x)[0] #因为我只测试了一组数据,所以取[0]即可
KNN的类写法
KNN.py
import numpy as np
from math import sqrt
from collections import Counter
from K近邻算法包.metrics import accuracy_score
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None #私有变量
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def __repr__(self): #自我描述,在创建对象时打印
return "KNN(k=%d)" % self.k
测试算法正确率
model_selection.py:
import numpy as np
def train_test_split(X, y, test_ratio=0.2, seed=None):
"""将数据 X 和 y 按照test_ratio分割成X_train, X_test, y_train, y_test"""
assert X.shape[0] == y.shape[0], \
"the size of X must be equal to the size of y"
assert 0.0 <= test_ratio <= 1.0, \
"test_ration must be valid"
if seed: #固定随机种子,好调试
np.random.seed(seed)
shuffled_indexes = np.random.permutation(len(X)) #len(矩阵)是行数
test_size = int(len(X) * test_ratio)
test_indexes = shuffled_indexes[:test_size]
train_indexes = shuffled_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, X_test, y_train, y_test
可以在jupyter notebook中调用一下试试:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X=iris.data
y=iris.target
%run F:/python3玩转机器学习/K近邻算法/model_selection.py
X_train, X_test, y_train, y_test=train_test_split(X,y,test_ratio=0.2)
%run F:/python3玩转机器学习/K近邻算法/KNN.py
my_knn_clf.fit(X_train,y_train)
y_predict=my_knn_clf.predict(X_test)
sum(y_predict==y_test)/len(y_test)
scikit-learn中的model_selection:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(X,y,test_size=0.2,random_state=666)
分类准确度
自己编写一个包
编写metrics.py:
import numpy as np
def accuracy_score(y_true, y_predict):
'''计算y_true和y_predict之间的准确率'''
assert y_true.shape[0] == y_predict.shape[0], \
"the size of y_true must be equal to the size of y_predict"
return sum(y_true == y_predict) / len(y_true)
在KNN.py中调用:
import numpy as np
from math import sqrt
from collections import Counter
from K近邻算法包.metrics import accuracy_score
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None #私有变量
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return accuracy_score(y_test, y_predict)
def __repr__(self): #自我描述,在创建对象时打印
return "KNN(k=%d)" % self.k
用sklearn测试准确度
data=datasets.load_digits()
X=data.data
y=data.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
from sklearn.neighbors import KNeighborsClassifier
KNN_clf=KNeighborsClassifier(n_neighbors=3)
KNN_clf.fit(X_train,y_train)
y_predict=KNN_clf.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_predict) ,也可以这样:KNN_clf.score(X_test,y_test)
超参数
超参数:在算法运行前需要决定的参数
模型参数:算法过程中运行的参数
KNN没有模型参数,KNN中的k是典型的超参数
根据上面的手写数字的数据集,暴力查找最好的k:
best_score=0.0
best_k=-1
for k in range(1,11):
knn_clf=KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train,y_train)
score=knn_clf.score(X_test,y_test)
if score>best_score:
best_k=k
best_score=score
print("best_k=",best_k)
print("best_score=",best_score)
有时候,距离的权重可能有影响,比如: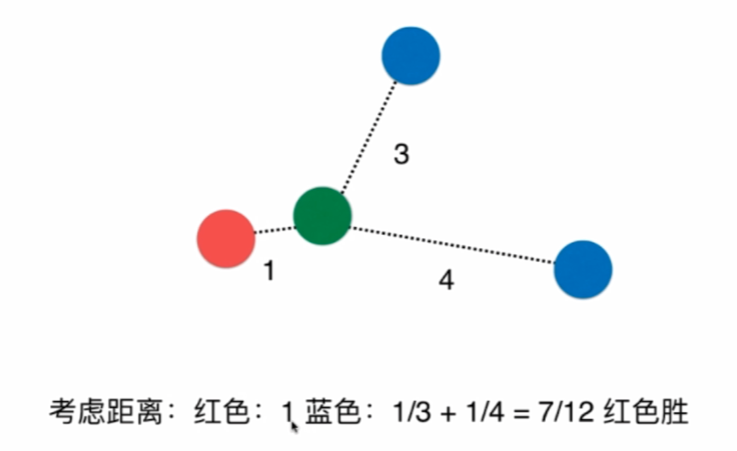
最近的是红色,那么我们按权重来比就是对距离取倒数求和。
明科夫斯基距离: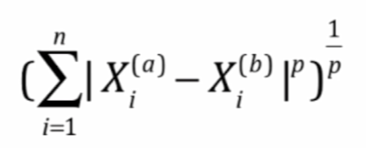
获得了一个超参数p
查找最好的p和k(网格搜索):
%%time
best_p=-1
best_score=0.0
best_k=-1
for k in range(1,11):
for p in range(1,6):
knn_clf=KNeighborsClassifier(n_neighbors=k,weights="distance")
knn_clf.fit(X_train,y_train)
score=knn_clf.score(X_test,y_test)
if score > best_score :
best_k=k
best_p=p
best_score=score
print("best_p=",best_p)
print("best_k=",best_k)
print("best_score=",best_score)
使用scikit-learn中的网格搜索:
定义网格参数:
param_grid =[
{
'weights':['uniform'],
'n_neighbors':[i for i in range(1,11)],
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1,11)],
'p':[i for i in range(1,6)]
}
]
初始化一个分类器对象:
knn_clf=KNeighborsClassifier()
导入网格搜索:
from sklearn.model_selection import GridSearchCV
实例化:
grid_search = GridSearchCV(knn_clf,param_grid)
拟合:
%%time
grid_search.fit(X_train,y_train)
最优分类器:
grid_search.best_estimator_
grid_search.best_score_
grid_search.best_params_
将knn_clf赋为最优参数的分类器:
knn_clf=grid_search.best_estimator_
knn_clf.score(X_test,y_test)
加速、显示具体信息:
grid_search=GridSearchCV(knn_clf,param_grid,n_jobs=-1,verbose=2)#-1是将所有核并行 verbose是输出信息的详细情况
%%time
grid_search.fit(X_train,y_train)
数据归一化
将所有数据映射到同一尺度
最值归一化(normalization)
把所有数据映射到0~1之间
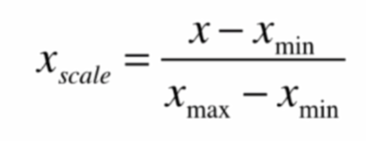
适用于分布有明显边界的情况,受outlier影响
对向量:
x1=np.random.randint(0,100,size=100)
(x1-np.min(x1))/(np.max(x1)-np.min(x1))
对矩阵:
X=np.random.randint(0,100,(50,2))
X=np.array(X,dtype=float)
对每一列特征值归一化:
X[:,0]=(X[:,0]-np.min(X[:,0]))/(np.max(X[:,0])-np.min(X[:,0]))
X[:,1]=(X[:,1]-np.min(X[:,1]))/(np.max(X[:,1])-np.min(X[:,1]))
绘制散点图:
plt.scatter(X[:,0],X[:,1])
plt.show()
均值方差归一化(standardization)
把所有数据归一到均值为0,方差为1的分布
适用于数据没有明显的边界,不受极端值影响
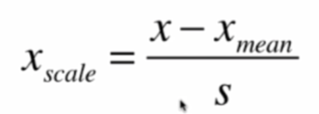
S是标准差。
实例:
x2=np.random.randint(0,100,(50,2))
x2=np.array(x2,dtype=float)
x2[:,0]=(x2[:,0]-np.mean(x2[:,0]))/np.std(x2[:,0])
x2[:,1]=(x2[:,1]-np.mean(x2[:,1]))/np.std(x2[:,1])
plt.scatter(x2[:,0],x2[:,1])
plt.show()
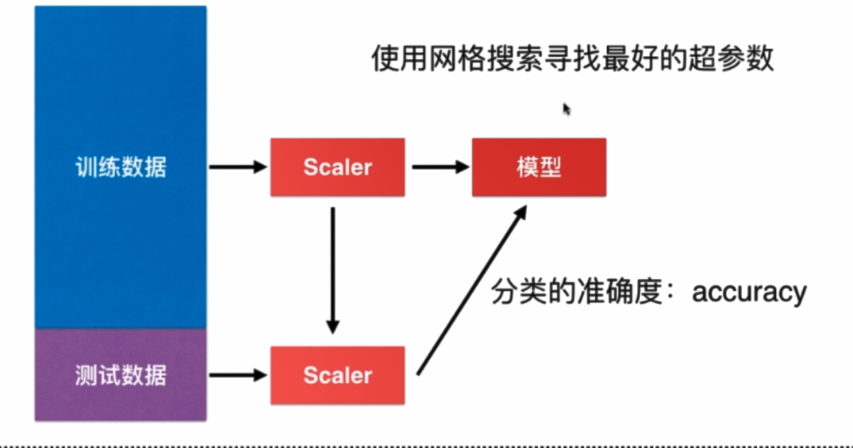
对测试数据集如何归一化?
不能简单的只对测试数据集归一化,应该用(x_test-x_mean_train)/std_train
使用scikit-learn归一化
from sklearn import datasets
import numpy
iris=datasets.load_iris()
X=iris.data
y=iris.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=666)
from sklearn.preprocessing import StandardScaler
standardScaler=StandardScaler()
standardScaler.fit(X_train)
standardScaler.mean_ #均值
standardScaler.scale_ #标准差,std已经不能再用
X_train=standardScaler.transform(X_train) #返回归一化的矩阵
X_test_standard=standardScaler.transform(X_test) #测试数据集要用训练数据集来归一化
测试归一化后的准确率:
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train,y_train) #用归一化的训练数据X训练
knn_clf.score(X_test_standard,y_test) #用归一化的测试数据X测试
返回1.0,因为鸢尾花的数据比较少,准确高也是自然地。
sklearn.preprocessing中还有MinMaxScaler(最值归一化),用法类似。
自己写StandardScaler类
preprocessing.py:
import numpy as np
class StandardScaler:
def __init__(self):
self.mean_ = None
self.scale_ = None
def fit(self, X):
"""根据训练数据集X获得数据的均值和方差"""
assert X.ndim == 2, "The dimension of X must be 2"
self.mean_ = np.array([np.mean(X[:,i]) for i in range(X.shape[1])])
self.scale_ = np.array([np.std(X[:,i]) for i in range(X.shape[1])])
return self
def transform(self, X):
"""将X根据这个StandardScaler进行均值方差归一化处理"""
assert X.ndim == 2, "The dimension of X must be 2"
assert self.mean_ is not None and self.scale_ is not None, \
"must fit before transform!"
assert X.shape[1] == len(self.mean_), \
"the feature number of X must be equal to mean_ and std_"
resX = np.empty(shape=X.shape, dtype=float)
for col in range(X.shape[1]):
resX[:,col] = (X[:,col] - self.mean_[col]) / self.scale_[col]
return resX
关于K近邻算法
最大的缺点:效率低下
如果训练集有m个样本,n个特征,那么每预测一个数据,要O(m*n)
可以使用KD-Tree、Ball-Tree优化,但依然低效
缺点2:高度数据相关
缺点3:预测结果不具有可解释性
维数灾难:随着维度的增加,“看似相近的两个点之间的距离会越来越大”
解决方法:降维,如PCA
机器学习流程:
机器学习(1)——K近邻算法的更多相关文章
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- 机器学习之K近邻算法
K 近邻 (K-nearest neighbor, KNN) 算法直接作用于带标记的样本,属于有监督的算法.它的核心思想基本上就是 近朱者赤,近墨者黑. 它与其他分类算法最大的不同是,它是一种&quo ...
- 机器学习实战-k近邻算法
写在开头,打算耐心啃完机器学习实战这本书,所用版本为2013年6月第1版 在P19页的实施kNN算法时,有很多地方不懂,遂仔细研究,记录如下: 字典按值进行排序 首先仔细读完kNN算法之后,了解其是用 ...
- 【机器学习】K近邻算法——多分类问题
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该类输入实例分为这个类. KNN是通过测量不同特征值之间的距离进行分类.它的的思路是:如 ...
- 机器学习2—K近邻算法学习笔记
Python3.6.3下修改代码中def classify0(inX,dataSet,labels,k)函数的classCount.iteritems()为classCount.items(),另外p ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- [机器学习] k近邻算法
算是机器学习中最简单的算法了,顾名思义是看k个近邻的类别,测试点的类别判断为k近邻里某一类点最多的,少数服从多数,要点摘录: 1. 关键参数:k值 && 距离计算方式 &&am ...
- 机器学习:k-NN算法(也叫k近邻算法)
一.kNN算法基础 # kNN:k-Nearest Neighboors # 多用于解决分裂问题 1)特点: 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集 ...
随机推荐
- swoole如何使php永久运行
有需要学习交流的友人请加入交流群的咱们一起,有问题一起交流,一起进步!前提是你是学技术的.感谢阅读! 点此加入该群jq.qq.com soole可以通过开启守护进程使PHP永久运行. 守护进程化.设 ...
- Jmeter性能测试分布式技术
一.什么是分布式测试 分布式测试是指通过局域网和Internet,把分布于不同地点.独立完成特定功能的测试计算机连接起来,以达到测试资源共享.分散操作.集中管理.协同工作.负载均衡.测试过程监控等目的 ...
- Java开发之使用websocket实现web客户端与服务器之间的实时通讯
使用websocket实现web客户端与服务器之间的实时通讯.以下是个简单的demo. 前端页面 <%@ page language="java" contentType=& ...
- 阿里云服务器搭建web项目小结
前言 最近恰好有时间,自己搞了个云服务器试着搭建了个网站,遇到了一些问题,通过踩坑也涨了一些经验,遂记录一二,与后来者分享. 正文 1.博主用的阿里云服务器,为什么用它呢?一个是恰逢双十一,有优惠:另 ...
- Serverless 实战——使用 Rendertron 搭建 Headless Chrome 渲染解决方案
为什么需要 Rendertron? 传统的 Web 页面,通常是服务端渲染的,而随着 SPA(Single-Page Application) 尤其是 React.Vue.Angular 为代表的前端 ...
- Ajax简单应用之个人简历页面搭建
1.搭建HTTP静态Web服务器. 代码实现: # 1.导入socket模块 import socket import threading # 创建服务器类 class HttpServerSocke ...
- Linux - CentOS 7 安装 .Net Core 运行环境
阿里云的CentOS 7.7 64位,所需要的环境:MySql 5.7,.Net Core 2.2 ,Nginx 我这里用的 Xshell 工具,首先用root进入系统 版本信息 打开终端输入命令: ...
- About learn《The C programming Language,Second Edition》
Today,My last week buy C language book arrived. Today,I week earnest study. No matter what difficult ...
- java核心API
---恢复内容开始--- Javase01 day01 关于String: String是不可变对象,java.lang.String使用了final修饰,不能被继承: 字符串一旦创建永远无法改变,但 ...
- Android五大布局详解——GridLayout(网格布局)
GridLayout 本章以一个小的实现示例讲述: 实现效果如图: 代码实现: <?xml version="1.0" encoding="utf-8"? ...