idea配置pyspark
默认python已经配好,并已经导入idea,只剩下pyspark的安装
1、解压spark-2.1.0-bin-hadoop2.7放入磁盘目录
D:\spark-2.1.0-bin-hadoop2.7
2、将D:\spark-2.1.0-bin-hadoop2.7\python\pyspark拷贝到目录Python的Lib\site-packages
3、在idea中配置spark环境变量
(1)

(2)
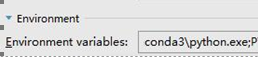
(3)

其中,需要配置的是SPARK_HOME。
如果系统中有多个版本的python,或者系统找不到python的位置,则需要配置PYSPARK_PYTHON ,我这里使用的是conda的python, E:\Program Files\Anaconda3\python.exe
(4) 安装py4j
pip install py4j
4、创建session需要注意的地方
from pyspark.sql import SparkSession
# appName中的内容不能有空格,否则报错
spark = SparkSession.builder.master("local[*]").appName("WordCount").getOrCreate() #获取上下文
sc = spark.sparkContext
带有空格报错情况如下:

5、创建上下文,两种方式
#第一种
conf = SparkConf().setAppName('test').setMaster('local')
sc = SparkContext(conf=conf)
#第二种
sc=SparkContext('local','test')
6、实例(读取文件并打印)
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName('test').setMaster('local')
sc = SparkContext(conf=conf)
rdd = sc.textFile('d:/scala/log.txt')
print(rdd.collect())
结果:

注意:还有一种错误如下所示
Java.util.NoSuchElementException: key not found: _PYSPARK_DRIVER_CALLBACK_HOST
这是因为版本的问题,可能pyspark的版本与spark不匹配
例如:
spark是2.1.0
所以当使用pip安装pyspark时需要带上版本号:
pip install pyspark==2.1.;
皆为2.1版本
idea配置pyspark的更多相关文章
- win10下Anaconda3在虚拟环境python_version=3.5.3 中配置pyspark
1. 序经过了一天的修炼,深深被恶心了,在虚拟环境中配置pyspark花式报错,由于本人实在是不想卸载3.6版的python,所以硬刚了一天,终于摸清了配置方法,并且配置成功,不抱怨了,开讲: 2. ...
- Anaconda中配置Pyspark的Spark开发环境
1.windows下载并安装Anaconda集成环境 URL:https://www.continuum.io/downloads 2.在控制台中测试ipython是否启动正常 3.安装JDK 3.1 ...
- 如何在windows下安装配置pyspark notebook
第一步:安装anaconda anaconda自带一系列科学计算包 下载链接:http://pan.baidu.com/s/1b4jWlg 密码:fqq3 接着配置环境变量:如我安装在D盘下 试一 ...
- (1)安装----anaconda3下配置pyspark【单机】
1.确保已经安装jdk和anaconda3.[我安装的jdk为1.8,anaconda的python为3.6] 2.安装spark,到官网 http://spark.apache.org/downlo ...
- pycharm中配置pyspark
1 下载官网spark-2.1.1-bin-hadoop2.7.tgz(版本自己选择),解压将文件放在了指定路径下,这个文件夹里面有python文件,python文件下还有两个压缩包py4j-some ...
- Ubuntu下导入PySpark到Shell和Pycharm中(未整理)
实习后面需要用到spark,虽然之前跟了edX的spark的课程以及用spark进行machine learning,但那个环境是官方已经搭建好的,但要在自己的系统里将PySpark导入shell(或 ...
- 大数据高可用集群环境安装与配置(09)——安装Spark高可用集群
1. 获取spark下载链接 登录官网:http://spark.apache.org/downloads.html 选择要下载的版本 2. 执行命令下载并安装 cd /usr/local/src/ ...
- Spark 的 python 编程环境
Spark 可以独立安装使用,也可以和 Hadoop 一起安装使用.在安装 Spark 之前,首先确保你的电脑上已经安装了 Java 8 或者更高的版本. Spark 安装 访问Spark 下载页面, ...
- windows下安装spark-python
首先需要安装Java 下载安装并配置Spark 从官方网站Download Apache Spark™下载相应版本的spark,因为spark是基于hadoop的,需要下载对应版本的hadoop才行, ...
随机推荐
- 关于字符串的格式化----format与%
格式化字符串一般有两种方法 1.%(d整数,s字符,f浮点数) 2.format 用处极为广泛且限制不多 注意:第一种对于数组的传递会报TypeError,所以必须传递数组 a = (1, 2, 3) ...
- 如何从 ASH 找到消耗 PGA 和 临时表空间 较多的 Top SQL_ID (Doc ID 2610646.1)
如何从 ASH 找到消耗 PGA 和 临时表空间 较多的 Top SQL_ID (Doc ID 2610646.1) 适用于: Oracle Database - Enterprise Edition ...
- [洛谷P1169][题解][ZJOI2007]午餐
这是题目吗? 显然的DP,讲几个重要的地方 1.贪心:让吃饭时间长的先排队(证明从略) 2.状态: f[i][j][k]代表前i个人,一号时间j,二号时间k显然MLE 所以压缩成f[i][j]代表前i ...
- VUE中 $on, $emit, v-on三者关系
VUE中 $on, $emit, v-on三者关系 每个vue实例都实现了事件借口 使用$on(eventName)监听事件 使用$emit(eventName)触发事件 若把vue看成家庭(相当于一 ...
- 【Java】导入项目时,出现The project cannot be built until build path errors are resolved错误解决方法
先检查jar包,jar包的地址如果不一样需要remove后重新导入的,右键项目→Build Path. 看额外的jar包有没有×,地址正不正确,要是不正确,remove错误jar包,再点击Add Ex ...
- jQuery-跨域问题的处理
调用登录接口时,后端一般会在调用登录接口成功后,在response中设置cookie,之后前端的每次请求都会自动地在请求头上加上后端设置好的cookie,这对前端来说是透明的. 当登录接口与登录后调用 ...
- 如何在动态链接库dll/so中导出自定义的模板类template class | how to implement a template class with c++ and export in dll/so
本文首发于个人博客https://kezunlin.me/post/4ec4ae49/,欢迎阅读最新内容! how to implement a template class with c++ and ...
- 前端之HTML介绍及使用
一.HTML介绍 1.1 web本质 在pycharm写入一下代码,然后在浏览器地址栏输入地址和端口127.0.0.1:8080,回车,回来运行代码,直接访问客户端发送的内容conn.send(b'& ...
- 通过修改VAD属性破除锁页机制
Windows内核分析索引目录:https://www.cnblogs.com/onetrainee/p/11675224.html 技术学习来源:火哥(QQ:471194425) 注释:因为自己的知 ...
- 中间件1--dubbo
DUBBO是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,是阿里巴巴SOA服务化治理方案的核心框架,每天为2,000+个服务提供3,000,000,000+次访问量支持,并被广 ...