Python 情人节超强技能 导出微信聊天记录生成词云
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: Python实用宝典
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef


瞧 这是不是一个有声音、有画面的小爱心~
今天 我们采集情侣们之间的聊天日常
用此制作一份只属于你们的小浪漫!
第一步,我们需要导出自己和对象的数据~
微信的备份功能并不能直接给你导出文本格式,它导出来其实是一种叫sqlite的数据库。如果说用网上流传的方法提取文本数据,iOS则需要下载itunes备份整机,安卓则需要本机的root权限,无论是哪种都非常麻烦,在这里给大家介绍一种不需要整机备份和本机root权限,只导出和对象的聊天数据的方法。
那就是使用安卓模拟器导出,这样既能ios/安卓通用,又能够避免对本机造成不良影响,首先需要用电脑版的微信备份你和你对象的聊天记录。以windows系统为例:
下载夜神模拟器
在夜神模拟器中下载微信
使用windows客户端版的微信进行备份,如图左下角
点击备份聊天记录至电脑

手机端选择备份的对象
点击进入下方的选择聊天记录,然后选择和你对象的记录就可以啦

导出完毕后打开模拟器,登录模拟器的微信
登录成功后返回电脑版微信登录,打开备份与恢复,选择恢复聊天记录到手机
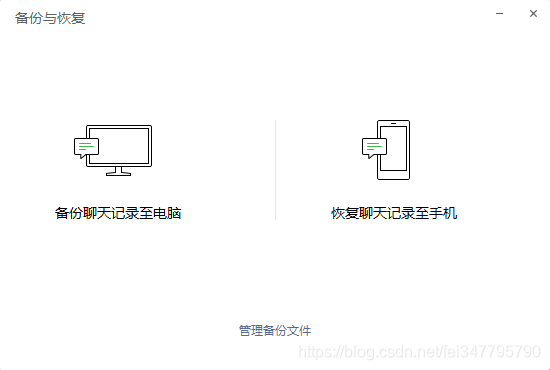
勾选我们刚刚导出的聊天记录,并在手机上点击开始恢复

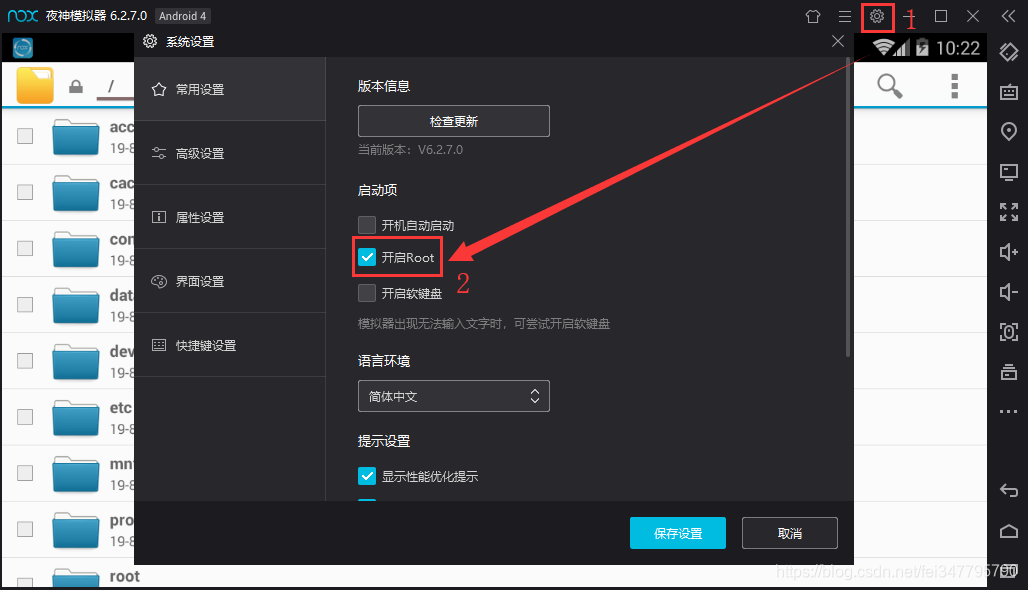
打开夜神模拟器的root权限
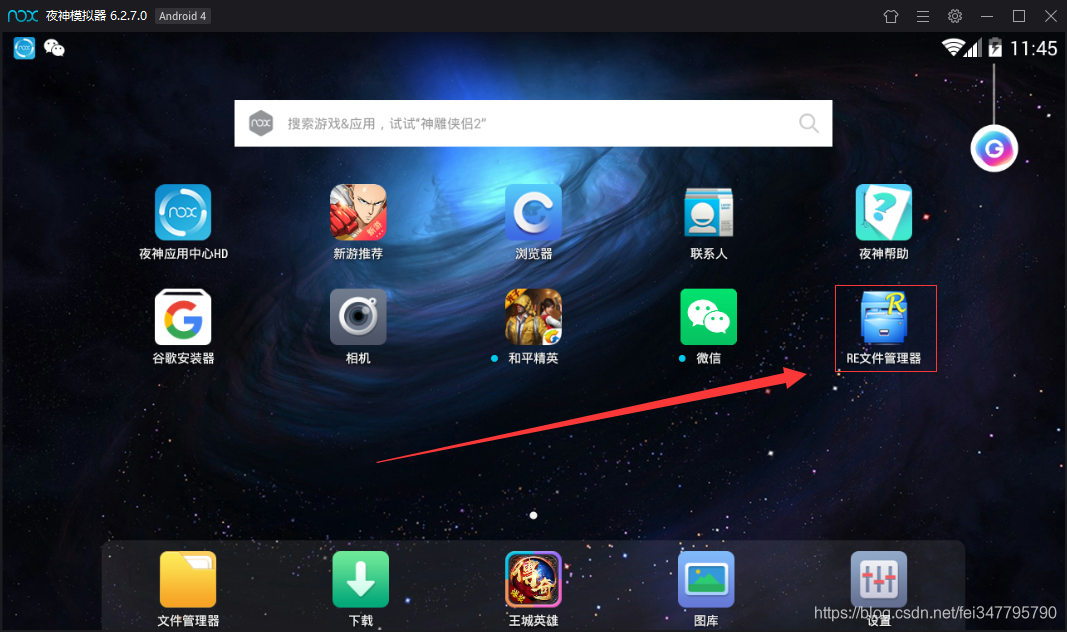
用模拟器的浏览器百度搜索RE文件管理器,下载(图一)安装后打开,会弹出对话框让你给予root权限,选择永久给予,打开RE文件管理器(图二),进入以下文件夹(图三), 这是应用存放数据的地方。
/data/data/com.tencent.mm/MicroMsg

然后进入一个由数字和字母组合而成的文件夹,如上 图三 的 4262333387ddefc95fee35aa68003cc5
找到该文件夹下的EnMicroMsg.db文件,将其复制到夜神模拟器的共享文件夹(图四)。共享文件夹的位置为 /mnt/shell/emulated/0/others ( 图五 ),现在访问windows的 C:\Users\你的用户名\Nox_share\OtherShare 获取该数据库文件( EnMicroMsg.db )
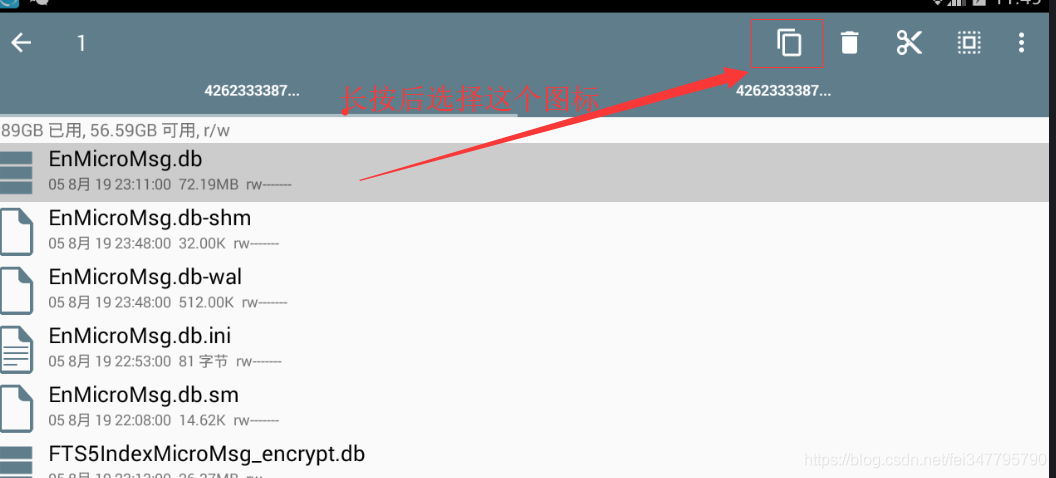

导出该数据库后,使用一款叫 sqlcipher 的软件读取数据 将该字符串进行MD5计算后的前七位便是该数据库的密码,如 "355757010761231 857456862" 实际上中间没有空格,然后放入MD5计算取前面七位数字,后续会详细介绍。
哇,真是“简单易懂”啊,没关系,接下来告诉大家IMEI和UIN怎么获得。
首先是IMEI,在模拟器右上角的系统设置 —— 属性设置里就可以找得到啦,如图所示。
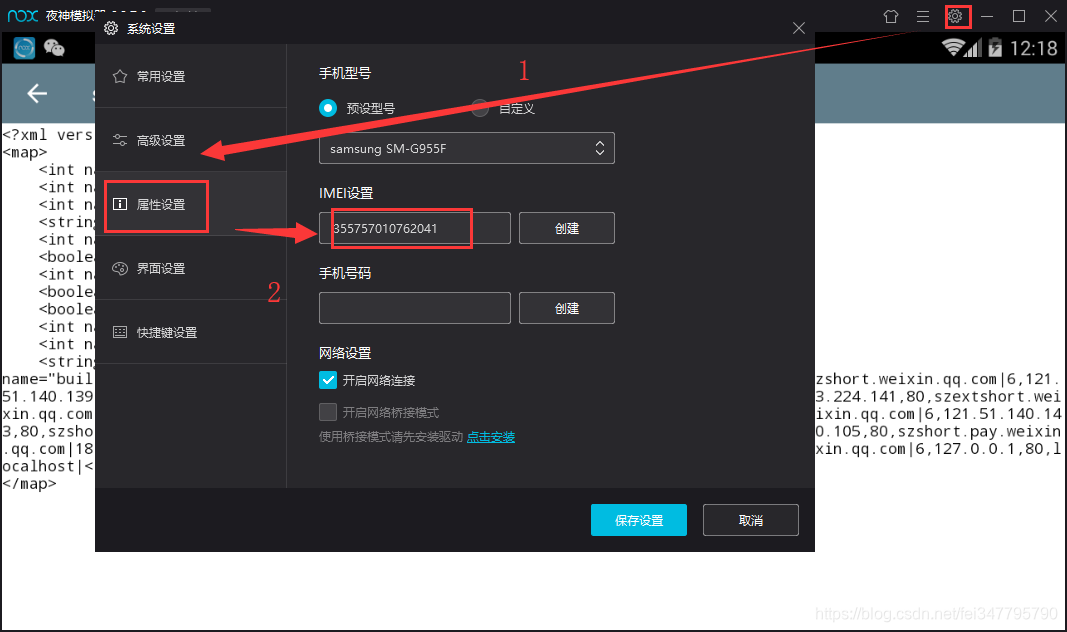
现在我们获得了IMEI号,那UIN号呢?
同样地,用RE文件管理器打开这个文件
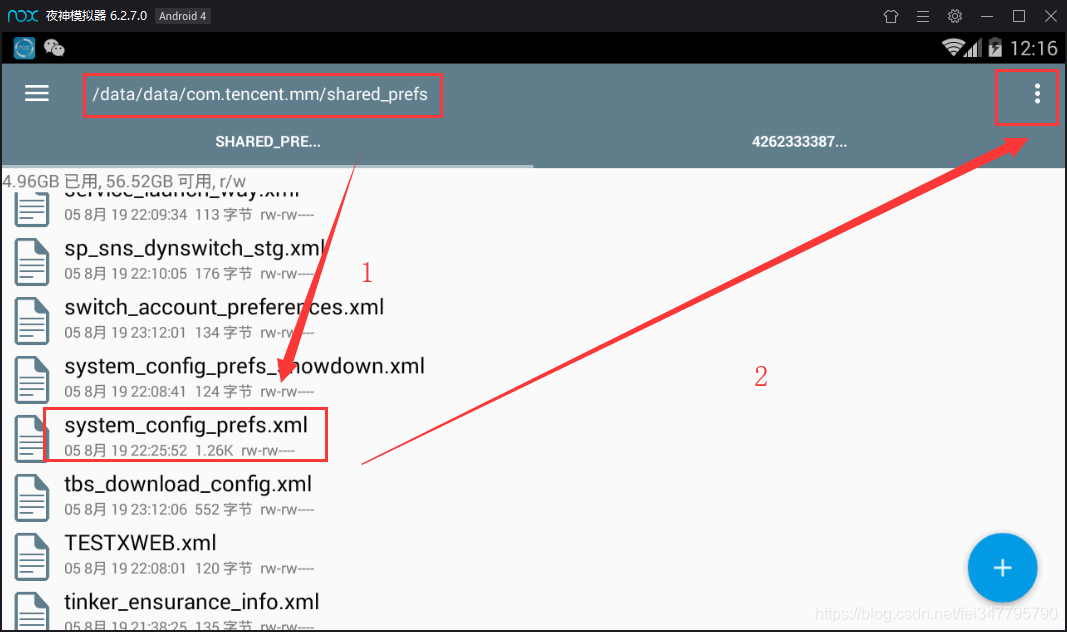
长按改文件,点击右上角的三个点—选择打开方式—文本浏览器,找到default_uin,后面的数字就是了 !
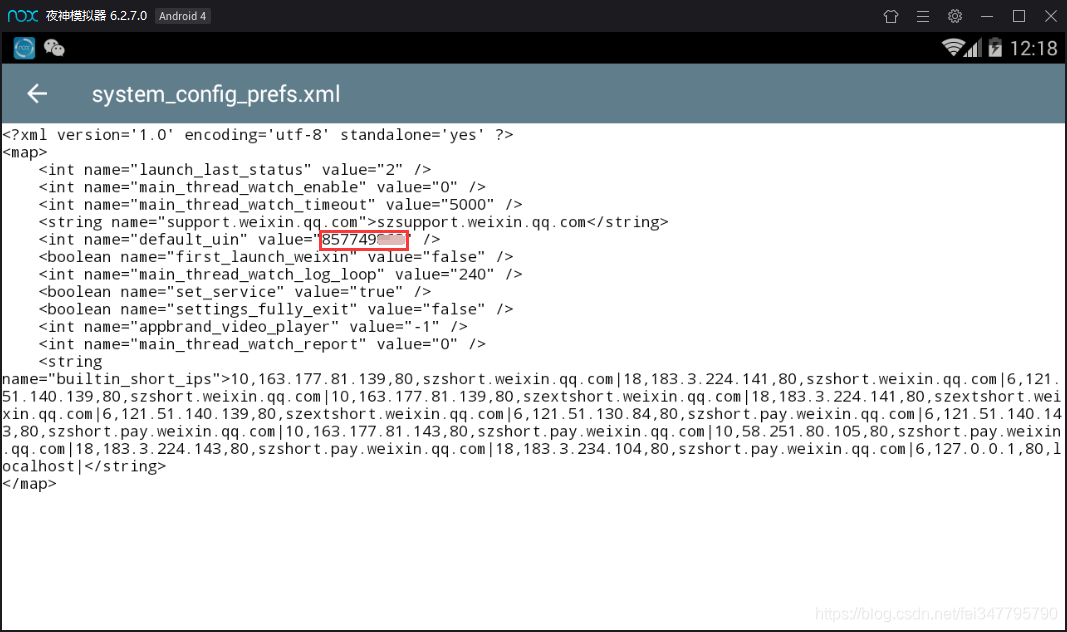
得到这两串数字后,就可以开始计算密码啦,如果我的IMEI是355757010762041,Uin是857749862,那么合起来就是355757010762041857749862,将这串数字放入免费MD5在线计算
得到的数字的前七位就是我们的密码了,像这一串就是 6782538.
然后我们就可以进入我们的核心环节:使用 sqlcipher 导出聊天文本数据!
点击 File - open database - 选择我们刚刚的数据库文件,会弹出框框让你输入密码,我们输入刚刚得到的七位密码,就可以进入到数据库了,选择message表格,这就是你与你的对象的聊天记录! 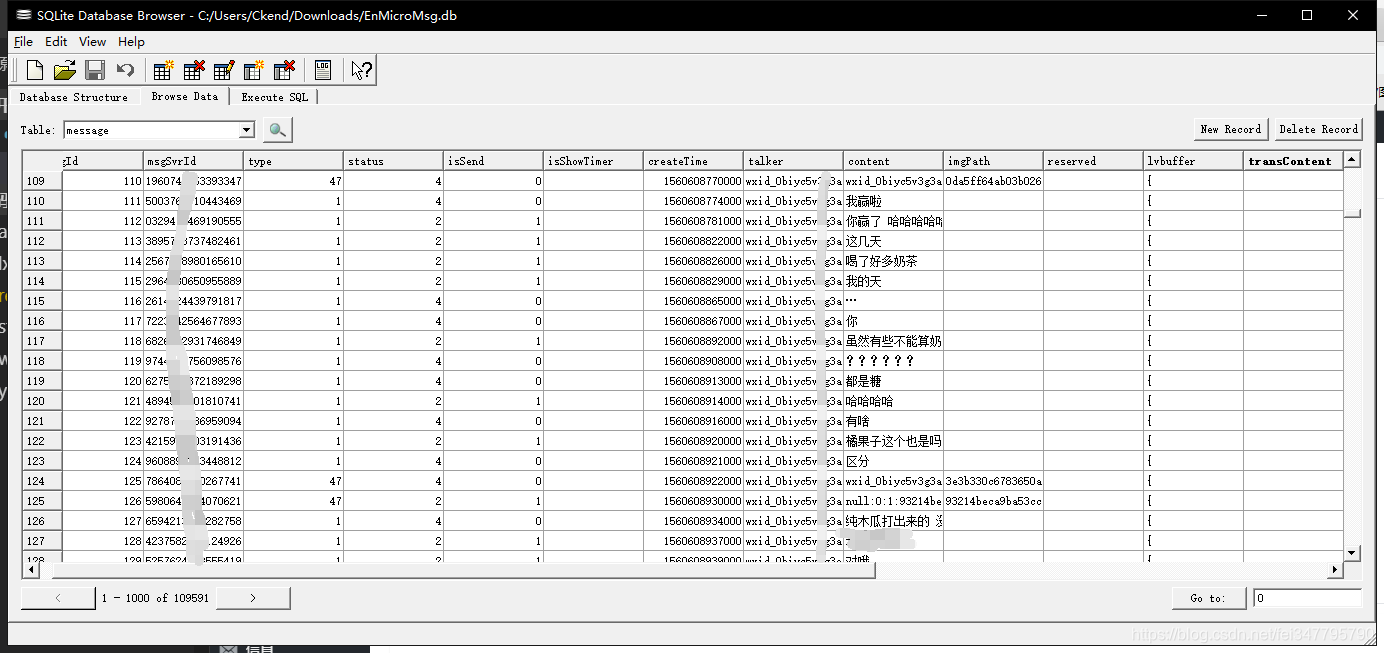
我们可以将它导出成csv文件:File - export - table as csv.
接下来,我们将使用Python代码,将里面真正的聊天内容:content信息提取出来,如下所示。虽然这个软件也允许select,但是它select后不允许导出,非常不好用,因此还不如我们自己写一个:
import pandas
import csv, sqlite3
conn= sqlite3.connect('chat_log.db')
# 新建数据库为 chat_log.db
df = pandas.read_csv('chat_logs.csv', sep=",")
# 读取我们上一步提取出来的csv文件,这里要改成你自己的文件名
df.to_sql('my_chat', conn, if_exists='append', index=False)
# 存入my_chat表中 conn = sqlite3.connect('chat_log.db')
# 连接数据库
cursor = conn.cursor()
# 获得游标
cursor.execute('select content from my_chat where length(content)<30')
# 将content长度限定30以下,因为content中有时候会有微信发过来的东西
value=cursor.fetchall()
# fetchall返回筛选结果 data=open("聊天记录.txt",'w+',encoding='utf-8')
for i in value:
data.write(i[0]+'\n')
# 将筛选结果写入 聊天记录.txt data.close()
cursor.close()
conn.close()
# 关闭连接
记得把csv文件的编码格式转换成utf-8哦,不然可能会运行不下去: 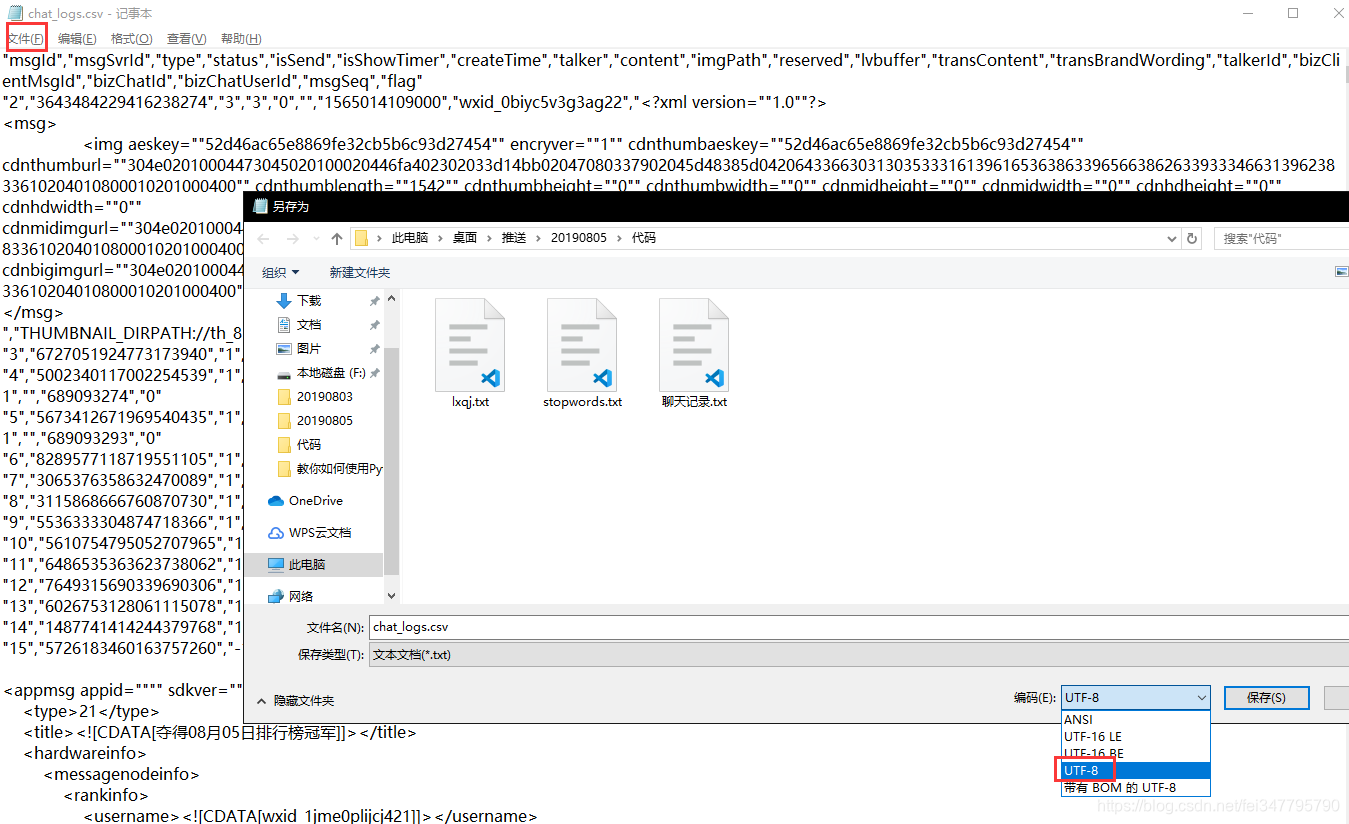
第二步,根据第一步得到的聊天数据生成词云
. 导入我们的聊天记录,并对每一行进行分词
聊天记录是一行一行的句子,我们需要使用分词工具把这一行行句子分解成由词语组成的数组,这时候我们就需要用到结巴分词了。
分词后我们还需要去除词语里一些语气词、标点符号等等(停用词),然后还要自定义一些词典,比如说你们之间恩恩爱爱的话,一般结巴分词是无法识别出来的,需要你自行定义,比如说:小傻瓜别感冒了,一般分词结果是
小/傻瓜/别/感冒/了
如果你把“小傻瓜”加入到自定义词典里(我们下面的例子里是mywords.txt),则分词结果则会是
小傻瓜/别/感冒/了
下面对我们的聊天记录进行分词:
import jieba
import codecs
def load_file_segment():
# 读取文本文件并分词
jieba.load_userdict("mywords.txt")
# 加载我们自己的词典
f = codecs.open(u"聊天记录.txt",'r',encoding='utf-8')
# 打开文件
content = f.read()
# 读取文件到content中
f.close()
# 关闭文件
segment=[]
# 保存分词结果
segs=jieba.cut(content)
# 对整体进行分词
for seg in segs:
if len(seg) > 1 and seg != '\r\n':
# 如果说分词得到的结果非单字,且不是换行符,则加入到数组中
segment.append(seg)
return segment
print(load_file_segment())
计算分词后的词语对应的频数
为了方便计算,我们需要引入一个叫pandas的包,然后为了计算每个词的个数,我们还要引入一个叫numpy的包,cmd/terminal中输入以下命令安装pandas和numpy:
pip install pandas
pip install numpy
import pandas
import numpy
def get_words_count_dict():
segment = load_file_segment()
# 获得分词结果
df = pandas.DataFrame({'segment':segment})
# 将分词数组转化为pandas数据结构
stopwords = pandas.read_csv("stopwords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'],encoding="utf-8")
# 加载停用词
df = df[~df.segment.isin(stopwords.stopword)]
# 如果不是在停用词中
words_count = df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
# 按词分组,计算每个词的个数
words_count = words_count.reset_index().sort_values(by="计数",ascending=False)
# reset_index是为了保留segment字段,排序,数字大的在前面
return words_count
print(get_words_count_dict())
完整代码,wordCloud.py 如下,附有详细的解析:
import jieba
import numpy
import codecs
import pandas
import matplotlib.pyplot as plt
from scipy.misc import imread
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
from wordcloud import WordCloud def load_file_segment():
# 读取文本文件并分词
jieba.load_userdict("mywords.txt")
# 加载我们自己的词典
f = codecs.open(u"聊天记录.txt",'r',encoding='utf-8')
# 打开文件
content = f.read()
# 读取文件到content中
f.close()
# 关闭文件
segment=[]
# 保存分词结果
segs=jieba.cut(content)
# 对整体进行分词
for seg in segs:
if len(seg) > 1 and seg != '\r\n':
# 如果说分词得到的结果非单字,且不是换行符,则加入到数组中
segment.append(seg)
return segment def get_words_count_dict():
segment = load_file_segment()
# 获得分词结果
df = pandas.DataFrame({'segment':segment})
# 将分词数组转化为pandas数据结构
stopwords = pandas.read_csv("stopwords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'],encoding="utf-8")
# 加载停用词
df = df[~df.segment.isin(stopwords.stopword)]
# 如果不是在停用词中
words_count = df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
# 按词分组,计算每个词的个数
words_count = words_count.reset_index().sort_values(by="计数",ascending=False)
# reset_index是为了保留segment字段,排序,数字大的在前面
return words_count words_count = get_words_count_dict()
# 获得词语和频数 bimg = imread('ai.jpg')
# 读取我们想要生成词云的模板图片
wordcloud = WordCloud(background_color='white', mask=bimg, font_path='simhei.ttf')
# 获得词云对象,设定词云背景颜色及其图片和字体 # 如果你的背景色是透明的,请用这两条语句替换上面两条
# bimg = imread('ai.png')
# wordcloud = WordCloud(background_color=None, mode='RGBA', mask=bimg, font_path='simhei.ttf') words = words_count.set_index("segment").to_dict()
# 将词语和频率转为字典
wordcloud = wordcloud.fit_words(words["计数"])
# 将词语及频率映射到词云对象上
bimgColors = ImageColorGenerator(bimg)
# 生成颜色
plt.axis("off")
# 关闭坐标轴
plt.imshow(wordcloud.recolor(color_func=bimgColors))
# 绘色
plt.show()
Python 情人节超强技能 导出微信聊天记录生成词云的更多相关文章
- 谁说程序员不浪漫?Python导出微信聊天记录生成爱的词云图
明天又双叒叕是一年一度的七夕恋爱节了! 又是一波绝好的机会!恩爱秀起来! 购物车清空!礼物送起来!朋友圈晒起来! 等等! 什么?! 你还没准备好七夕礼物么? 但其实你不知道要送啥? 原来又双叒叕要 ...
- python爬取豆瓣流浪地球影评,生成词云
代码很简单,一看就懂. (没有模拟点击,所以都是未展开的) 地址: https://movie.douban.com/subject/26266893/reviews?rating=&star ...
- python 爬取腾讯微博并生成词云
本文以延参法师的腾讯微博为例进行爬取并分析 ,话不多说 直接附上源代码.其中有比较详细的注释. 需要用到的包有 BeautifulSoup WordCloud jieba # coding:utf-8 ...
- iphone如何导出微信聊天记录到电脑?
有个小美眉买了个iphone,但发现自己就是一小白,很多功能都不会用,微信倒是用得挺上手的,可以晚上聊到三四点,流量直接飙升500MB.最近她说手机太卡了,问ytkah帮她整一下.拿起她的IPhone ...
- 如何使用iTunes与iTools导出微信聊天记录
.tocblock .tocblock .tocblock { margin-left: 2.25em; } .madoko .toc>.tocblock .tocblock { margin- ...
- 【python】itchat登录微信获取好友签名并生成词云
在知乎上看到一篇关于如何使用itchat统计微信好友男女比例并使用plt生成柱状图以及获取微信好友签名并生成词云的文章https://zhuanlan.zhihu.com/p/36361397,感觉挺 ...
- python 基于 wordcloud + jieba + matplotlib 生成词云
词云 词云是啥?词云突出一个数据可视化,酷炫.以前以为很复杂,不想python已经有成熟的工具来做词云.而我们要做的就是准备关键词数据,挑一款字体,挑一张模板图片,非常非常无脑.准备好了吗,快跟我一起 ...
- 从CentOS安装完成到生成词云python学习日记
欢迎访问我的个人博客:原文链接 前言 人生苦短,我用python.学习python怎么能不搞一下词云呢是不是(ง •̀_•́)ง 于是便有了这篇边实践边记录的笔记. 环境:VMware 12pro + ...
- 用Python生成词云
词云以词语为基本单元,根据词语在文本中出现的频率设计不同大小的形状以形成视觉上的不同效果,从而使读者只要“一瞥“即可领略文本的主旨.以下是一个词云的简单示例: import jieba from wo ...
随机推荐
- 【Git教程】如何清除git仓库的所有提交记录,成为一个新的干净仓库
一.引言 马三也算Github的忠实用户了,经常会把一些练手的项目传到Github上面进行备份.其中有一个名为ColaFramework的Unity框架项目,马三开发了一年多了,期间提交代码的时候在L ...
- 压测 swoole_websocket_server 性能
概述 这是关于 Swoole 入门学习的第十篇文章:压测 swoole_websocket_server 性能. 第九篇:Swoole Redis 连接池的实现 第八篇:Swoole MySQL 连接 ...
- 工作笔记 之 Linux服务搭建
No.1 linux环境下安装nginx步骤 Nginx (engine x) 是一款轻量级的Web 服务器.反向代理服务器.电子邮件(IMAP/POP3)代理服务器,在BSD-like 协议下发行. ...
- PHPStorm 配置本地 WebServer 运行 PHP
目标:PHPStorm 2018.2 通过配置运行 PHP 代码无需安装其它 Web Server File -> Settings菜单找到PHP,设置 CLI Interpreter PHP的 ...
- Android 在Fragment中修改Activity中的控件
在当前的Fragment中调用getActivity方法获取依附着的那个Activity,然后再用获取到的Activity去findViewById拿到你需要的控件对其操作就行了.
- Selenium(一):原理与安装、简单的使用
1. selenium原理 1.1 selenium介绍 Selenium是一个Web应用的自动化框架. 通过它,我们可以写出自动化程序,像人一样在浏览器里操作web界面. 比如点击界面按钮,在文本框 ...
- Java基础专题
Java后端知识点汇总——Java基础专题 全套Java知识点汇总目录,见https://www.cnblogs.com/autism-dong/p/11831922.html 1.解释下什么是面向对 ...
- 通俗易懂,什么是.NET/.NET Framework/.NET Core/.Net Standard?
什么是.NET?什么是.NET Framework?本文将从上往下,循序渐进的介绍一系列相关.NET的概念,先从类型系统开始讲起,我将通过跨语言操作这个例子来逐渐引入一系列.NET的相关概念,这主要包 ...
- textarea中文本高亮选中
最近在实现原文/译文句段高亮对比显示,和有道翻译类似,如下图所示: 最初的解决方案是采用富文本编辑器,把所有句段信息都用HTML标签包裹,操作空间比较大,页面上需要的功能几乎都可以实现,但是由此带来了 ...
- 移动端H5页面遇到的问题总结(转载请注明出处)
最近刚做完一个移动端的项目,产品之无敌,过程之艰辛,我就不多说了,记录下在这个项目中遇到的问题,以防万一,虽然这些可能都是已经被N多前辈解决掉了的问题,也放在这里,算是为自己漫漫前端路铺了一颗小石子儿 ...